FastAPI 最佳实践¶
我们在创业时使用的并且自以为是的最佳实践和惯例列表。
在过去 1.5 年的生产中, 我们一直在做出好的和坏的决定,这些决定极大地影响了我们的开发人员体验。 其中一些值得分享。
Opinionated list of best practices and conventions we used at our startup.
For the last 1.5 years in production, we have been making good and bad decisions that impacted our developer experience dramatically. Some of them are worth sharing.
1. 项目结构。 一致且可预测¶
1. Project Structure. Consistent & predictable
构建项目的方法有很多种,但最好的结构是一致、直接且没有意外的结构。
- 如果查看项目结构不能让您了解项目的内容,那么结构可能不清楚。
- 如果您必须打开包才能了解其中包含哪些模块,那么您的结构就不清楚了。
- 如果文件的重复率和位置感觉是随机的,那么您的项目结构很糟糕。
- 如果查看模块的位置及其名称不能让您了解其中的内容,那么您的结构非常糟糕。
@tiangolo 提供的项目结构(我们按文件类型(例如 api、crud、模型、模式)分隔文件)适用于微服务或范围较小的项目,但我们无法将它放入我们具有大量域和模块的整体中。
我发现更具可扩展性和可演化性的结构是受 Netflix 的 Dispatch 启发并稍作修改。
fastapi-project
├── alembic/
├── src
│ ├── auth
│ │ ├── router.py
│ │ ├── schemas.py # pydantic 模型
│ │ ├── models.py # db 模型
│ │ ├── dependencies.py
│ │ ├── config.py # 本地配置
│ │ ├── constants.py
│ │ ├── exceptions.py
│ │ ├── service.py
│ │ └── utils.py
│ ├── aws
│ │ ├── client.py # 外部服务通信的客户端模型
│ │ ├── schemas.py
│ │ ├── config.py
│ │ ├── constants.py
│ │ ├── exceptions.py
│ │ └── utils.py
│ └── posts
│ │ ├── router.py
│ │ ├── schemas.py
│ │ ├── models.py
│ │ ├── dependencies.py
│ │ ├── constants.py
│ │ ├── exceptions.py
│ │ ├── service.py
│ │ └── utils.py
│ ├── config.py # 全局配置
│ ├── models.py # 全局模型
│ ├── exceptions.py # 全局异常
│ ├── pagination.py # 全局模块 例如. pagination 分页
│ ├── database.py # 数据库连接相关的东西
│ └── main.py
├── tests/
│ ├── auth
│ ├── aws
│ └── posts
├── templates/
│ └── index.html
├── requirements
│ ├── base.txt
│ ├── dev.txt
│ └── prod.txt
├── .env
├── .gitignore
├── logging.ini
└── alembic.ini
- 将所有域目录存储在
src文件夹中src/- 应用程序的最高级别,包含通用模型、配置和常量等。src/main.py- 项目的根目录,用于启动 FastAPI 应用程序
- 每个包都有自己的 router, schemas, models, 等。
router.py- 每个模块的核心,是所有路由接口的入口。schemas.py- 每个模块的 pydantic的模型models.py- 每个模块的数据库模型service.py- 模块特有的业务逻辑dependencies.py- 路由依赖(Depends)constants.py- 模块特有的常量和错误码定义config.py- 例如,环境变量utils.py- 非业务逻辑功能, 例如. 响应规范化、数据丰富等。exceptions- 模块特有的一场,例如.PostNotFound,InvalidUserData
- 当包需要来自其他包的服务或依赖项或常量时 - 使用显式模块名称导入它们
from src.auth import constants as auth_constants
from src.notifications import service as notification_service
from src.posts.constants import ErrorCode as PostsErrorCode # 如果我们在每个包的常量模块中都有标准错误代码
There are many ways to structure the project, but the best structure is a structure that is consistent, straightforward, and has no surprises.
- If looking at the project structure doesn't give you an idea of what the project is about, then the structure might be unclear.
- If you have to open packages to understand what modules are located in them, then your structure is unclear.
- If the frequency and location of the files feels random, then your project structure is bad.
- If looking at the module's location and its name doesn't give you an idea of what's inside it, then your structure is very bad.
Although the project structure, where we separate files by their type (e.g. api, crud, models, schemas) presented by @tiangolo is good for microservices or projects with fewer scopes, we couldn't fit it into our monolith with a lot of domains and modules. Structure that I found more scalable and evolvable is inspired by Netflix's Dispatch with some little modifications.
fastapi-project
├── alembic/
├── src
│ ├── auth
│ │ ├── router.py
│ │ ├── schemas.py # pydantic models
│ │ ├── models.py # db models
│ │ ├── dependencies.py
│ │ ├── config.py # local configs
│ │ ├── constants.py
│ │ ├── exceptions.py
│ │ ├── service.py
│ │ └── utils.py
│ ├── aws
│ │ ├── client.py # client model for external service communication
│ │ ├── schemas.py
│ │ ├── config.py
│ │ ├── constants.py
│ │ ├── exceptions.py
│ │ └── utils.py
│ └── posts
│ │ ├── router.py
│ │ ├── schemas.py
│ │ ├── models.py
│ │ ├── dependencies.py
│ │ ├── constants.py
│ │ ├── exceptions.py
│ │ ├── service.py
│ │ └── utils.py
│ ├── config.py # global configs
│ ├── models.py # global models
│ ├── exceptions.py # global exceptions
│ ├── pagination.py # global module e.g. pagination
│ ├── database.py # db connection related stuff
│ └── main.py
├── tests/
│ ├── auth
│ ├── aws
│ └── posts
├── templates/
│ └── index.html
├── requirements
│ ├── base.txt
│ ├── dev.txt
│ └── prod.txt
├── .env
├── .gitignore
├── logging.ini
└── alembic.ini
- Store all domain directories inside
srcfolder src/- highest level of an app, contains common models, configs, and constants, etc.src/main.py- root of the project, which inits the FastAPI app- Each package has its own router, schemas, models, etc.
router.py- is a core of each module with all the endpointsschemas.py- for pydantic modelsmodels.py- for db modelsservice.py- module specific business logicdependencies.py- router dependenciesconstants.py- module specific constants and error codesconfig.py- e.g. env varsutils.py- non-business logic functions, e.g. response normalization, data enrichment, etc.exceptions- module specific exceptions, e.g.PostNotFound,InvalidUserData- When package requires services or dependencies or constants from other packages - import them with an explicit module name
from src.auth import constants as auth_constants
from src.notifications import service as notification_service
from src.posts.constants import ErrorCode as PostsErrorCode # in case we have Standard ErrorCode in constants module of each package
2. 尽可能的使用 Pydantic 进行数据验证¶
Excessively use Pydantic for data validation
Pydantic 具有一组丰富的功能来验证和转换数据。
除了具有默认值的必填和非必填字段等常规功能外,
Pydantic 内置了全面的数据处理工具,如正则表达式、有限允许选项的枚举、长度验证、电子邮件验证等。
from enum import Enum
from pydantic import AnyUrl, BaseModel, EmailStr, Field, constr
class MusicBand(str, Enum):
AEROSMITH = "AEROSMITH"
QUEEN = "QUEEN"
ACDC = "AC/DC"
class UserBase(BaseModel):
first_name: str = Field(min_length=1, max_length=128)
username: constr(regex="^[A-Za-z0-9-_]+$", to_lower=True, strip_whitespace=True)
email: EmailStr
age: int = Field(ge=18, default=None) # must be greater or equal to 18
favorite_band: MusicBand = None # only "AEROSMITH", "QUEEN", "AC/DC" values are allowed to be inputted
website: AnyUrl = None
Pydantic has a rich set of features to validate and transform data.
In addition to regular features like required & non-required fields with default values, Pydantic has built-in comprehensive data processing tools like regex, enums for limited allowed options, length validation, email validation, etc.
from enum import Enum
from pydantic import AnyUrl, BaseModel, EmailStr, Field, constr
class MusicBand(str, Enum):
AEROSMITH = "AEROSMITH"
QUEEN = "QUEEN"
ACDC = "AC/DC"
class UserBase(BaseModel):
first_name: str = Field(min_length=1, max_length=128)
username: constr(regex="^[A-Za-z0-9-_]+$", to_lower=True, strip_whitespace=True)
email: EmailStr
age: int = Field(ge=18, default=None) # must be greater or equal to 18
favorite_band: MusicBand = None # only "AEROSMITH", "QUEEN", "AC/DC" values are allowed to be inputted
website: AnyUrl = None
3. 使用Depends(依赖)进行与数据库有关的数据验证¶
Use dependencies for data validation vs DB
Pydantic 可以只验证来自客户端输入的值。
使用依赖项根据数据库约束验证数据,例如电子邮件已存在、未找到用户等。
# dependencies.py
async def valid_post_id(post_id: UUID4) -> Mapping:
post = await service.get_by_id(post_id)
if not post:
raise PostNotFound()
return post
# router.py
@router.get("/posts/{post_id}", response_model=PostResponse)
async def get_post_by_id(post: Mapping = Depends(valid_post_id)):
return post
@router.put("/posts/{post_id}", response_model=PostResponse)
async def update_post(
update_data: PostUpdate,
post: Mapping = Depends(valid_post_id),
):
updated_post: Mapping = await service.update(id=post["id"], data=update_data)
return updated_post
@router.get("/posts/{post_id}/reviews", response_model=list[ReviewsResponse])
async def get_post_reviews(post: Mapping = Depends(valid_post_id)):
post_reviews: list[Mapping] = await reviews_service.get_by_post_id(post["id"])
return post_reviews
如果我们不将数据验证放在依赖项中,我们将不得不为每个接口添加 post_id 验证并为每个接口编写相同的测试。
Pydantic can only validate the values from client input. Use dependencies to validate data against database constraints like email already exists, user not found, etc.
# dependencies.py
async def valid_post_id(post_id: UUID4) -> Mapping:
post = await service.get_by_id(post_id)
if not post:
raise PostNotFound()
return post
# router.py
@router.get("/posts/{post_id}", response_model=PostResponse)
async def get_post_by_id(post: Mapping = Depends(valid_post_id)):
return post
@router.put("/posts/{post_id}", response_model=PostResponse)
async def update_post(
update_data: PostUpdate,
post: Mapping = Depends(valid_post_id),
):
updated_post: Mapping = await service.update(id=post["id"], data=update_data)
return updated_post
@router.get("/posts/{post_id}/reviews", response_model=list[ReviewsResponse])
async def get_post_reviews(post: Mapping = Depends(valid_post_id)):
post_reviews: list[Mapping] = await reviews_service.get_by_post_id(post["id"])
return post_reviews
If we didn't put data validation to dependency, we would have to add post_id validation for every endpoint and write the same tests for each of them.
4. 依赖(Dependency)链¶
Chain dependencies
依赖可以使用其他依赖,避免类似逻辑的代码重复。
# dependencies.py
from fastapi.security import OAuth2PasswordBearer
from jose import JWTError, jwt
async def valid_post_id(post_id: UUID4) -> Mapping:
post = await service.get_by_id(post_id)
if not post:
raise PostNotFound()
return post
async def parse_jwt_data(
token: str = Depends(OAuth2PasswordBearer(tokenUrl="/auth/token"))
) -> dict:
try:
payload = jwt.decode(token, "JWT_SECRET", algorithms=["HS256"])
except JWTError:
raise InvalidCredentials()
return {"user_id": payload["id"]}
async def valid_owned_post(
post: Mapping = Depends(valid_post_id),
token_data: dict = Depends(parse_jwt_data),
) -> Mapping:
if post["creator_id"] != token_data["user_id"]:
raise UserNotOwner()
return post
# router.py
@router.get("/users/{user_id}/posts/{post_id}", response_model=PostResponse)
async def get_user_post(post: Mapping = Depends(valid_owned_post)):
return post
Dependencies can use other dependencies and avoid code repetition for similar logic.
# dependencies.py
from fastapi.security import OAuth2PasswordBearer
from jose import JWTError, jwt
async def valid_post_id(post_id: UUID4) -> Mapping:
post = await service.get_by_id(post_id)
if not post:
raise PostNotFound()
return post
async def parse_jwt_data(
token: str = Depends(OAuth2PasswordBearer(tokenUrl="/auth/token"))
) -> dict:
try:
payload = jwt.decode(token, "JWT_SECRET", algorithms=["HS256"])
except JWTError:
raise InvalidCredentials()
return {"user_id": payload["id"]}
async def valid_owned_post(
post: Mapping = Depends(valid_post_id),
token_data: dict = Depends(parse_jwt_data),
) -> Mapping:
if post["creator_id"] != token_data["user_id"]:
raise UserNotOwner()
return post
# router.py
@router.get("/users/{user_id}/posts/{post_id}", response_model=PostResponse)
async def get_user_post(post: Mapping = Depends(valid_owned_post)):
return post
5. 解耦和重用依赖关系。 缓存依赖(Dependency)调用结果¶
Decouple & Reuse dependencies. Dependency calls are cached
依赖项可以多次重用,并且不会重新计算 - 默认情况下,FastAPI 将依赖项的结果缓存在请求的范围内。
例如:如果我们有一个调用服务 get_post_by_id 的依赖项,我们将不会在每次调用该依赖项时都访问数据库 - 只有第一次函数调用时会用到。
知道了这一点,我们可以轻松地将依赖关系解耦到多个较小的函数上,这些函数在较小的域上运行并且更容易在其他路由中重用。
例如,在下面的代码中,我们使用了 3 次 parse_jwt_data:
valid_owned_postvalid_active_creatorget_user_post
但是 parse_jwt_data 在第一次调用时只被调用一次。
# dependencies.py
from fastapi import BackgroundTasks
from fastapi.security import OAuth2PasswordBearer
from jose import JWTError, jwt
async def valid_post_id(post_id: UUID4) -> Mapping:
post = await service.get_by_id(post_id)
if not post:
raise PostNotFound()
return post
async def parse_jwt_data(
token: str = Depends(OAuth2PasswordBearer(tokenUrl="/auth/token"))
) -> dict:
try:
payload = jwt.decode(token, "JWT_SECRET", algorithms=["HS256"])
except JWTError:
raise InvalidCredentials()
return {"user_id": payload["id"]}
async def valid_owned_post(
post: Mapping = Depends(valid_post_id),
token_data: dict = Depends(parse_jwt_data),
) -> Mapping:
if post["creator_id"] != token_data["user_id"]:
raise UserNotOwner()
return post
async def valid_active_creator(
token_data: dict = Depends(parse_jwt_data),
):
user = await users_service.get_by_id(token_data["user_id"])
if not user["is_active"]:
raise UserIsBanned()
if not user["is_creator"]:
raise UserNotCreator()
return user
# router.py
@router.get("/users/{user_id}/posts/{post_id}", response_model=PostResponse)
async def get_user_post(
worker: BackgroundTasks,
post: Mapping = Depends(valid_owned_post),
user: Mapping = Depends(valid_active_creator),
):
"""Get post that belong the active user."""
worker.add_task(notifications_service.send_email, user["id"])
return post
Dependencies can be reused multiple times, and they won't be recalculated - FastAPI caches dependency's result within a request's scope by default,
i.e. if we have a dependency that calls service get_post_by_id, we won't be visiting DB each time we call this dependency - only the first function call.
Knowing this, we can easily decouple dependencies onto multiple smaller functions that operate on a smaller domain and are easier to reuse in other routes.
For example, in the code below we are using parse_jwt_data three times:
valid_owned_postvalid_active_creatorget_user_post,
but parse_jwt_data is called only once, in the very first call.
# dependencies.py
from fastapi import BackgroundTasks
from fastapi.security import OAuth2PasswordBearer
from jose import JWTError, jwt
async def valid_post_id(post_id: UUID4) -> Mapping:
post = await service.get_by_id(post_id)
if not post:
raise PostNotFound()
return post
async def parse_jwt_data(
token: str = Depends(OAuth2PasswordBearer(tokenUrl="/auth/token"))
) -> dict:
try:
payload = jwt.decode(token, "JWT_SECRET", algorithms=["HS256"])
except JWTError:
raise InvalidCredentials()
return {"user_id": payload["id"]}
async def valid_owned_post(
post: Mapping = Depends(valid_post_id),
token_data: dict = Depends(parse_jwt_data),
) -> Mapping:
if post["creator_id"] != token_data["user_id"]:
raise UserNotOwner()
return post
async def valid_active_creator(
token_data: dict = Depends(parse_jwt_data),
):
user = await users_service.get_by_id(token_data["user_id"])
if not user["is_active"]:
raise UserIsBanned()
if not user["is_creator"]:
raise UserNotCreator()
return user
# router.py
@router.get("/users/{user_id}/posts/{post_id}", response_model=PostResponse)
async def get_user_post(
worker: BackgroundTasks,
post: Mapping = Depends(valid_owned_post),
user: Mapping = Depends(valid_active_creator),
):
"""Get post that belong the active user."""
worker.add_task(notifications_service.send_email, user["id"])
return post
6. 遵循 REST 规范¶
Follow the REST
译者注 - REST API 设计规范
参考 阮一峰老师的 - RESTful API 设计指南 和 RESTful API 最佳实践
开发 RESTful API 可以更轻松地在如下路由中重用依赖项:
GET /courses/:course_idGET /courses/:course_id/chapters/:chapter_id/lessonsGET /chapters/:chapter_id
唯一需要注意的是在路径中使用相同的变量名:
- 如果你有两个接口
GET /profiles/:profile_id和GET /creators/:creator_id两者都验证给定的profile_id是否存在,但是GET /creators/:creator_id还检查配置文件是否是创建者,那么最好将creator_id路径变量重命名为profile_id并将这两个依赖项链接起来。
# src.profiles.dependencies
async def valid_profile_id(profile_id: UUID4) -> Mapping:
profile = await service.get_by_id(post_id)
if not profile:
raise ProfileNotFound()
return profile
# src.creators.dependencies
async def valid_creator_id(
profile: Mapping = Depends(valid_profile_id)
) -> Mapping:
if not profile["is_creator"]:
raise ProfileNotCreator()
return profile
# src.profiles.router.py
@router.get("/profiles/{profile_id}", response_model=ProfileResponse)
async def get_user_profile_by_id(profile: Mapping = Depends(valid_profile_id)):
"""Get profile by id."""
return profile
# src.creators.router.py
@router.get("/creators/{profile_id}", response_model=ProfileResponse)
async def get_user_profile_by_id(
creator_profile: Mapping = Depends(valid_creator_id)
):
"""Get creator's profile by id."""
return creator_profile
使用 /me 路由定义来返回当前用户资源 (例如. GET /profiles/me, GET /users/me/posts)
- 无需检查用户ID是否存在 - 因为auth校验早已校验了其是否存在。
- 无需检查用户ID是否属于请求者
Developing RESTful API makes it easier to reuse dependencies in routes like these:
GET /courses/:course_idGET /courses/:course_id/chapters/:chapter_id/lessonsGET /chapters/:chapter_id
The only caveat is to use the same variable names in the path:
- If you have two endpoints
GET /profiles/:profile_idandGET /creators/:creator_idthat both validate whether the givenprofile_idexists, butGET /creators/:creator_idalso checks if the profile is creator, then it's better to renamecreator_idpath variable toprofile_idand chain those two dependencies.
# src.profiles.dependencies
async def valid_profile_id(profile_id: UUID4) -> Mapping:
profile = await service.get_by_id(post_id)
if not profile:
raise ProfileNotFound()
return profile
# src.creators.dependencies
async def valid_creator_id(profile: Mapping = Depends(valid_profile_id)) -> Mapping:
if not profile["is_creator"]:
raise ProfileNotCreator()
return profile
# src.profiles.router.py
@router.get("/profiles/{profile_id}", response_model=ProfileResponse)
async def get_user_profile_by_id(profile: Mapping = Depends(valid_profile_id)):
"""Get profile by id."""
return profile
# src.creators.router.py
@router.get("/creators/{profile_id}", response_model=ProfileResponse)
async def get_user_profile_by_id(
creator_profile: Mapping = Depends(valid_creator_id)
):
"""Get creator's profile by id."""
return creator_profile
Use /me endpoints for users resources (e.g. GET /profiles/me, GET /users/me/posts)
- No need to validate that user id exists - it's already checked via auth method
- No need to check whether the user id belongs to the requester
7. 如果你的路由只有阻塞的 I/O 操作, 不要让你的路由异步¶
Don't make your routes async, if you have only blocking I/O operations
在底层,FastAPI 可以有效地处理 异步和同步 I/O 操作。
- FastAPI 在线程池 中运行
sync(同步)路由,阻塞 I/O 操作不会阻止[事件循环](https://docs.python.org/3/library/asyncio-eventloop.html)执行任务。 - 否则,如果路由被定义为
async,那么它会通过await定期调用,并且 FastAPI 相信您只会执行非阻塞 I/O 操作。
需要注意的是,如果您未能信任并在异步路由中执行阻塞操作,事件循环将无法运行下一个任务,直到该阻塞操作完成。
import asyncio
import time
@router.get("/terrible-ping")
async def terrible_catastrophic_ping():
time.sleep(10) # I/O阻塞操作10秒
pong = service.get_pong() # 从 DB 获取 pong 的 I/O 阻塞操作
return {"pong": pong}
@router.get("/good-ping")
def good_ping():
time.sleep(10) # I/O 阻塞操作 10 秒,但在另一个线程中
pong = service.get_pong() # 从数据库中获取 pong 的 I/O 阻塞操作,但在另一个线程中
return {"pong": pong}
@router.get("/perfect-ping")
async def perfect_ping():
await asyncio.sleep(10) # 异步阻塞 I/O 操作
pong = await service.async_get_pong() # 异步阻塞 I/O 数据库调用
return {"pong": pong}
当我们调用时会发生什么
- FastAPI 服务器收到一个请求并开始处理它
- 服务器的事件循环和队列中的所有任务将等待直到
time.sleep()完成- 服务器认为
time.sleep()不是一个 I/O 任务, 所以会一直等待并直到它完成。 - 在等待期间服务器不会接受任何新的请求。
- 服务器认为
- 然后, 事件循环和所有任务会在队列中一起等待,直到
service.get_pong执行完毕。- 服务器认为
service.get_pong()不是一个 I/O 任务, 所以他会一直等待,直到它完成。 - 服务器在等待期间不会接受任何新的的请求。
- 服务器认为
- 服务器返回响应。
- 响应之后, 服务器开始接受新的请求。
- FastAPI 服务器收到一个请求并开始处理它
- FastAPI 将整个路由
good_ping分配到线程池中, 池中有工作线程负责运行该路由绑定的函数。 - 在
good_ping执行其间, 事件循环会从队列中选择下一个任务和工作线程给他们, (比如. 接受新请求, 调用数据库)- 工作线程独立于主线程 (比如. 我们的 FastAPI 应用程序), 它将等待
time.sleep完成,然后等待service.get_pong完成。 - Sync(同步)操作只会阻塞子线程,不会阻塞主线程。
- 工作线程独立于主线程 (比如. 我们的 FastAPI 应用程序), 它将等待
- 然后
good_ping完成他的工作, 服务器返回一个响应给客户端。
- FastAPI 服务器收到一个请求并开始处理它
- FastAPI 异步等待
asyncio.sleep(10) - 事件循环从队列中选择下一个任务并处理它们 (比如. 接受新请求, 调用数据库)
- 当
asyncio.sleep(10)完成时, 服务器转到下一行并等待service.async_get_pong完成。 - 事件循环从队列中选择下一个任务并处理它们 (比如. 接受新请求, 调用数据库)
- 当
service.async_get_pong完成, 服务器返回一个响应给客户端。
第二个需要强调的是,non-blocking awaitables (非阻塞等待)或者发送到线程池的操作必须是I/O密集型任务(比如: 打开文件、数据库调用、外部API调用等等)。
- 等待CPU密集型任务 (比如. 负责的计算, 数据处理, 视频转码) 是没有价值的,因为CPU必须工作才能完成计算任务, 而I/O操作是外部的,服务器在等待该操作完成时什么都不做,因此它可以去做下一个任务。
- 由于 GIL,在其他线程中运行 CPU 密集型任务也不是有效的。 简而言之,GIL 一次只允许一个线程工作,这使得它对 CPU密集型任务毫无用处。
- 如果你想优化 CPU 密集型任务,你应该将它们发送给另一个进程中进行工作。
StackOverflow上困惑用户的相关问题:
- https://stackoverflow.com/questions/62976648/architecture-flask-vs-fastapi/70309597#70309597 - 同样可以看看 我的回答
- https://stackoverflow.com/questions/65342833/fastapi-uploadfile-is-slow-compared-to-flask
- https://stackoverflow.com/questions/71516140/fastapi-runs-api-calls-in-serial-instead-of-parallel-fashion
Under the hood, FastAPI can effectively handle both async and sync I/O operations.
- FastAPI runs
syncroutes in the threadpool and blocking I/O operations won't stop the event loop from executing the tasks. - Otherwise, if the route is defined
asyncthen it's called regularly viaawaitand FastAPI trusts you to do only non-blocking I/O operations.
The caveat is if you fail that trust and execute blocking operations within async routes, the event loop will not be able to run the next tasks until that blocking operation is done.
import asyncio
import time
@router.get("/terrible-ping")
async def terrible_catastrophic_ping():
time.sleep(10) # I/O blocking operation for 10 seconds
pong = service.get_pong() # I/O blocking operation to get pong from DB
return {"pong": pong}
@router.get("/good-ping")
def good_ping():
time.sleep(10) # I/O blocking operation for 10 seconds, but in another thread
pong = service.get_pong() # I/O blocking operation to get pong from DB, but in another thread
return {"pong": pong}
@router.get("/perfect-ping")
async def perfect_ping():
await asyncio.sleep(10) # non-blocking I/O operation
pong = await service.async_get_pong() # non-blocking I/O db call
return {"pong": pong}
What happens when we call:
GET /terrible-ping- FastAPI server receives a request and starts handling it
- Server's event loop and all the tasks in the queue will be waiting until
time.sleep()is finished- Server thinks
time.sleep()is not an I/O task, so it waits until it is finished - Server won't accept any new requests while waiting
- Server thinks
- Then, event loop and all the tasks in the queue will be waiting until
service.get_pongis finished- Server thinks
service.get_pong()is not an I/O task, so it waits until it is finished - Server won't accept any new requests while waiting
- Server thinks
- Server returns the response.
- After a response, server starts accepting new requests
GET /good-ping- FastAPI server receives a request and starts handling it
- FastAPI sends the whole route
good_pingto the threadpool, where a worker thread will run the function - While
good_pingis being executed, event loop selects next tasks from the queue and works on them (e.g. accept new request, call db)- Independently of main thread (i.e. our FastAPI app),
worker thread will be waiting for
time.sleepto finish and then forservice.get_pongto finish - Sync operation blocks only the side thread, not the main one.
- Independently of main thread (i.e. our FastAPI app),
worker thread will be waiting for
- When
good_pingfinishes its work, server returns a response to the client GET /perfect-ping- FastAPI server receives a request and starts handling it
- FastAPI awaits
asyncio.sleep(10) - Event loop selects next tasks from the queue and works on them (e.g. accept new request, call db)
- When
asyncio.sleep(10)is done, servers goes to the next lines and awaitsservice.async_get_pong - Event loop selects next tasks from the queue and works on them (e.g. accept new request, call db)
- When
service.async_get_pongis done, server returns a response to the client
The second caveat is that operations that are non-blocking awaitables or are sent to the thread pool must be I/O intensive tasks (e.g. open file, db call, external API call).
- Awaiting CPU-intensive tasks (e.g. heavy calculations, data processing, video transcoding) is worthless since the CPU has to work to finish the tasks, while I/O operations are external and server does nothing while waiting for that operations to finish, thus it can go to the next tasks.
- Running CPU-intensive tasks in other threads also isn't effective, because of GIL. In short, GIL allows only one thread to work at a time, which makes it useless for CPU tasks.
- If you want to optimize CPU intensive tasks you should send them to workers in another process.
Related StackOverflow questions of confused users
- https://stackoverflow.com/questions/62976648/architecture-flask-vs-fastapi/70309597#70309597
- Here you can also check my answer
- https://stackoverflow.com/questions/65342833/fastapi-uploadfile-is-slow-compared-to-flask
- https://stackoverflow.com/questions/71516140/fastapi-runs-api-calls-in-serial-instead-of-parallel-fashion
8. 从第 0 天开始的自定义基础模型¶
Custom base model from day 0
拥有可控的全局基础模型使我们能够自定义应用程序中的所有模型。
例如,我们可以有一个标准的日期时间格式或为基础模型的所有子类添加一个超级方法。
from datetime import datetime
from zoneinfo import ZoneInfo
import orjson
from fastapi.encoders import jsonable_encoder
from pydantic import BaseModel, root_validator
def orjson_dumps(v, *, default):
# orjson.dumps 返回字节,为了匹配标准的 json.dumps, 我们需要解码。
return orjson.dumps(v, default=default).decode()
def convert_datetime_to_gmt(dt: datetime) -> str:
if not dt.tzinfo:
dt = dt.replace(tzinfo=ZoneInfo("UTC"))
return dt.strftime("%Y-%m-%dT%H:%M:%S%z")
class ORJSONModel(BaseModel):
class Config:
json_loads = orjson.loads
json_dumps = orjson_dumps
json_encoders = {datetime: convert_datetime_to_gmt} # 日期时间字段的自定义 JSON 编码方法
@root_validator()
def set_null_microseconds(cls, data: dict) -> dict:
"""在所有日期时间字段值中删除微秒。"""
datetime_fields = {
k: v.replace(microsecond=0)
for k, v in data.items()
if isinstance(k, datetime)
}
return {**data, **datetime_fields}
def serializable_dict(self, **kwargs):
"""返回一个只包含可序列化字段的字典。"""
default_dict = super().dict(**kwargs)
return jsonable_encoder(default_dict)
在上面的示例中,我们决定制作一个全局基础模型:
- 使用 orjson 用于数据的序列化
- 在所有日期格式中将微秒降为 0
- 将所有日期时间字段序列化为具有显式时区的标准格式
Having a controllable global base model allows us to customize all the models within the app. For example, we could have a standard datetime format or add a super method for all subclasses of the base model.
from datetime import datetime
from zoneinfo import ZoneInfo
import orjson
from fastapi.encoders import jsonable_encoder
from pydantic import BaseModel, root_validator
def orjson_dumps(v, *, default):
# orjson.dumps returns bytes, to match standard json.dumps we need to decode
return orjson.dumps(v, default=default).decode()
def convert_datetime_to_gmt(dt: datetime) -> str:
if not dt.tzinfo:
dt = dt.replace(tzinfo=ZoneInfo("UTC"))
return dt.strftime("%Y-%m-%dT%H:%M:%S%z")
class ORJSONModel(BaseModel):
class Config:
json_loads = orjson.loads
json_dumps = orjson_dumps
json_encoders = {datetime: convert_datetime_to_gmt} # method for customer JSON encoding of datetime fields
@root_validator()
def set_null_microseconds(cls, data: dict) -> dict:
"""Drops microseconds in all the datetime field values."""
datetime_fields = {
k: v.replace(microsecond=0)
for k, v in data.items()
if isinstance(k, datetime)
}
return {**data, **datetime_fields}
def serializable_dict(self, **kwargs):
"""Return a dict which contains only serializable fields."""
default_dict = super().dict(**kwargs)
return jsonable_encoder(default_dict)
In the example above we have decided to make a global base model which:
- uses orjson to serialize data
- drops microseconds to 0 in all date formats
- serializes all datetime fields to standard format with explicit timezone
9. 文档(Docs)¶
Docs
-
除非您的 API 是公开的,否则默认情况下隐藏文档。 仅在选定的环境中明确显示它。
from fastapi import FastAPI from starlette.config import Config config = Config(".env") # 解析 .env 文件中的环境变量 ENVIRONMENT = config("ENVIRONMENT") # 获取当前环境名称 SHOW_DOCS_ENVIRONMENT = ("local", "staging") # 允许显示文档的环境名称列表 app_configs = {"title": "My Cool API"} if ENVIRONMENT not in SHOW_DOCS_ENVIRONMENT: app_configs["openapi_url"] = None # 将文档的 url 设置为 null app = FastAPI(**app_configs) -
帮助FastAPI生成通俗易懂的文档
- 设置
response_model,status_code,description, 等字段. - 如果响应模型和状态不同,使用
responses路由属性为不同的响应添加文档
from fastapi import APIRouter, status
router = APIRouter()
@router.post(
"/endpoints",
response_model=DefaultResponseModel, # 默认响应的 pydantic 模型
status_code=status.HTTP_201_CREATED, # 默认状态码
description="文档接口的清晰描述",
tags=["Endpoint Category"], # 接口分类
summary="Summary of the Endpoint", # 接口概要
responses={
status.HTTP_200_OK: {
"model": OkResponse, # 自定义 pydantic 模型,用于 200 响应
"description": "Ok Response",
},
status.HTTP_201_CREATED: {
"model": CreatedResponse, # 自定义 pydantic 模型,用于 201 响应
"description": "Creates something from user request ",
},
status.HTTP_202_ACCEPTED: {
"model": AcceptedResponse, # 自定义 pydantic 模型,用于 202 响应
"description": "Accepts request and handles it later",
},
},
)
async def documented_route():
pass
即生成的文档就像这样: 
- Unless your API is public, hide docs by default. Show it explicitly on the selected envs only.
from fastapi import FastAPI
from starlette.config import Config
config = Config(".env") # parse .env file for env variables
ENVIRONMENT = config("ENVIRONMENT") # get current env name
SHOW_DOCS_ENVIRONMENT = ("local", "staging") # explicit list of allowed envs
app_configs = {"title": "My Cool API"}
if ENVIRONMENT not in SHOW_DOCS_ENVIRONMENT:
app_configs["openapi_url"] = None # set url for docs as null
app = FastAPI(**app_configs)
- Help FastAPI to generate an easy-to-understand docs
- Set
response_model,status_code,description, etc. - If models and statuses vary, use
responsesroute attribute to add docs for different responses
from fastapi import APIRouter, status
router = APIRouter()
@router.post(
"/endpoints",
response_model=DefaultResponseModel, # default response pydantic model
status_code=status.HTTP_201_CREATED, # default status code
description="Description of the well documented endpoint",
tags=["Endpoint Category"],
summary="Summary of the Endpoint",
responses={
status.HTTP_200_OK: {
"model": OkResponse, # custom pydantic model for 200 response
"description": "Ok Response",
},
status.HTTP_201_CREATED: {
"model": CreatedResponse, # custom pydantic model for 201 response
"description": "Creates something from user request ",
},
status.HTTP_202_ACCEPTED: {
"model": AcceptedResponse, # custom pydantic model for 202 response
"description": "Accepts request and handles it later",
},
},
)
async def documented_route():
pass
Will generate docs like this:
10. 使用 Pydantic 的 BaseSettings 进行配置¶
Use Pydantic's BaseSettings for configs
Pydantic 提供了一个强大的工具 来解析环境变量并使用其验证器处理它们。
from pydantic import AnyUrl, BaseSettings, PostgresDsn
class AppSettings(BaseSettings):
class Config:
env_file = ".env"
env_file_encoding = "utf-8"
env_prefix = "app_"
DATABASE_URL: PostgresDsn
IS_GOOD_ENV: bool = True
ALLOWED_CORS_ORIGINS: set[AnyUrl]
Pydantic gives a powerful tool to parse environment variables and process them with its validators.
from pydantic import AnyUrl, BaseSettings, PostgresDsn
class AppSettings(BaseSettings):
class Config:
env_file = ".env"
env_file_encoding = "utf-8"
env_prefix = "app_"
DATABASE_URL: PostgresDsn
IS_GOOD_ENV: bool = True
ALLOWED_CORS_ORIGINS: set[AnyUrl]
11. SQLAlchemy: 设置数据库键命名约定¶
SQLAlchemy: Set DB keys naming convention
根据您的数据库约定明确设置索引的命名优于 sqlalchemy 自动命名。
from sqlalchemy import MetaData
POSTGRES_INDEXES_NAMING_CONVENTION = {
"ix": "%(column_0_label)s_idx",
"uq": "%(table_name)s_%(column_0_name)s_key",
"ck": "%(table_name)s_%(constraint_name)s_check",
"fk": "%(table_name)s_%(column_0_name)s_fkey",
"pk": "%(table_name)s_pkey",
}
metadata = MetaData(naming_convention=POSTGRES_INDEXES_NAMING_CONVENTION)
Explicitly setting the indexes' namings according to your database's convention is preferable over sqlalchemy's.
from sqlalchemy import MetaData
POSTGRES_INDEXES_NAMING_CONVENTION = {
"ix": "%(column_0_label)s_idx",
"uq": "%(table_name)s_%(column_0_name)s_key",
"ck": "%(table_name)s_%(constraint_name)s_check",
"fk": "%(table_name)s_%(column_0_name)s_fkey",
"pk": "%(table_name)s_pkey",
}
metadata = MetaData(naming_convention=POSTGRES_INDEXES_NAMING_CONVENTION)
12. 迁移: Alembic¶
Migrations. Alembic
- 迁移必须是静态的和可恢复的。 如果您的迁移依赖于动态生成的数据,那么请确保唯一动态的是数据本身,而不是其结构。
- 生成具有描述性名称和 slug 的迁移。 Slug 是必需的,应该解释这些变化。
- 为新迁移设置人类可读的文件模板。 我们使用
*date*_*slug*.py模式,例如2022-08-24_post_content_idx.py
# alembic.ini
file_template = %%(year)d-%%(month).2d-%%(day).2d_%%(slug)s
- Migrations must be static and revertable. If your migrations depend on dynamically generated data, then make sure the only thing that is dynamic is the data itself, not its structure.
- Generate migrations with descriptive names & slugs. Slug is required and should explain the changes.
- Set human-readable file template for new migrations. We use
*date*_*slug*.pypattern, e.g.2022-08-24_post_content_idx.py
# alembic.ini
file_template = %%(year)d-%%(month).2d-%%(day).2d_%%(slug)s
13. 设置数据库(表/字典)命名约定¶
Set DB naming convention
命名保持一致很重要。 我们遵循的一些规则:
- lower_case_snake (小写驼峰命名)
- 单数形式 (例如.
post,post_like,user_playlist) - 使用模块前缀对相似表进行分组, 例如.
payment_account,payment_bill,post,post_like - 跨表命名保持一致,但具体的命名是可以的, 例如.
- 在所有表中使用
profile_id,但如果其中一些只需要作为创建者的配置文件,请使用creator_id - 在所有抽象表,形如
post_like、post_view中使用post_id,但在相关模块中使用具体命名,如chapters.course_id中的course_id。 _at作为datetime类型的后缀_date作为date类型的后缀
Being consistent with names is important. Some rules we followed:
- lower_case_snake
- singular form (e.g.
post,post_like,user_playlist) - group similar tables with module prefix, e.g.
payment_account,payment_bill,post,post_like - stay consistent across tables, but concrete namings are ok, e.g.
- use
profile_idin all tables, but if some of them need only profiles that are creators, usecreator_id - use
post_idfor all abstract tables likepost_like,post_view, but use concrete naming in relevant modules likecourse_idinchapters.course_id _atsuffix for datetime_datesuffix for date
14. 从第0天开始写基于异步的测试¶
Set tests client async from day 0
基于DB写集成测试很有可能导致在将来出现基于事件循环的错误。
立即开始基于异步测试客户端的测试, 例如. async_asgi_testclient 或 httpx
import pytest
from async_asgi_testclient import TestClient
from src.main import app # inited FastAPI app
@pytest.fixture
async def client():
host, port = "127.0.0.1", "5555"
scope = {"client": (host, port)}
async with TestClient(
app, scope=scope, headers={"X-User-Fingerprint": "Test"}
) as client:
yield client
@pytest.mark.asyncio
async def test_create_post(client: TestClient):
resp = await client.post("/posts")
assert resp.status_code == 201
除非你有同步到数据库连接(打扰了?)或者不打算编写集成测试。
Writing integration tests with DB will most likely lead to messed up event loop errors in the future. Set the async test client immediately, e.g. async_asgi_testclient or httpx
import pytest
from async_asgi_testclient import TestClient
from src.main import app # inited FastAPI app
@pytest.fixture
async def client():
host, port = "127.0.0.1", "5555"
scope = {"client": (host, port)}
async with TestClient(
app, scope=scope, headers={"X-User-Fingerprint": "Test"}
) as client:
yield client
@pytest.mark.asyncio
async def test_create_post(client: TestClient):
resp = await client.post("/posts")
assert resp.status_code == 201
Unless you have sync db connections (excuse me?) or aren't planning to write integration tests.
15. 后台任务使用 asyncio.create_task¶
BackgroundTasks > asyncio.create_task
BackgroundTasks 可以 有效运行
所有的阻塞和非阻塞I/O操作, 就像FastAPI 处理阻塞路由一样。 (sync(同步)任务在线程池中运行, 而 async(异步) 人物则等待中稍后运行。)
- 不要欺骗工作例程以及将阻塞的I/O操作标记为
async(异步).(这样做的话,会阻塞事件调用循环,导致影响其他的异步任务调用) - 不要将它用于繁重的CPU密集型任务。
from fastapi import APIRouter, BackgroundTasks
from pydantic import UUID4
from src.notifications import service as notifications_service
router = APIRouter()
@router.post("/users/{user_id}/email")
async def send_user_email(worker: BackgroundTasks, user_id: UUID4):
"""Send email to user"""
worker.add_task(notifications_service.send_email, user_id) # send email after responding client
return {"status": "ok"}
BackgroundTasks can effectively run
both blocking and non-blocking I/O operations the same way FastAPI handles blocking routes (sync tasks are run in a threadpool, while async tasks are awaited later)
- Don't lie to the worker and don't mark blocking I/O operations as
async - Don't use it for heavy CPU intensive tasks.
from fastapi import APIRouter, BackgroundTasks
from pydantic import UUID4
from src.notifications import service as notifications_service
router = APIRouter()
@router.post("/users/{user_id}/email")
async def send_user_email(worker: BackgroundTasks, user_id: UUID4):
"""Send email to user"""
worker.add_task(notifications_service.send_email, user_id) # send email after responding client
return {"status": "ok"}
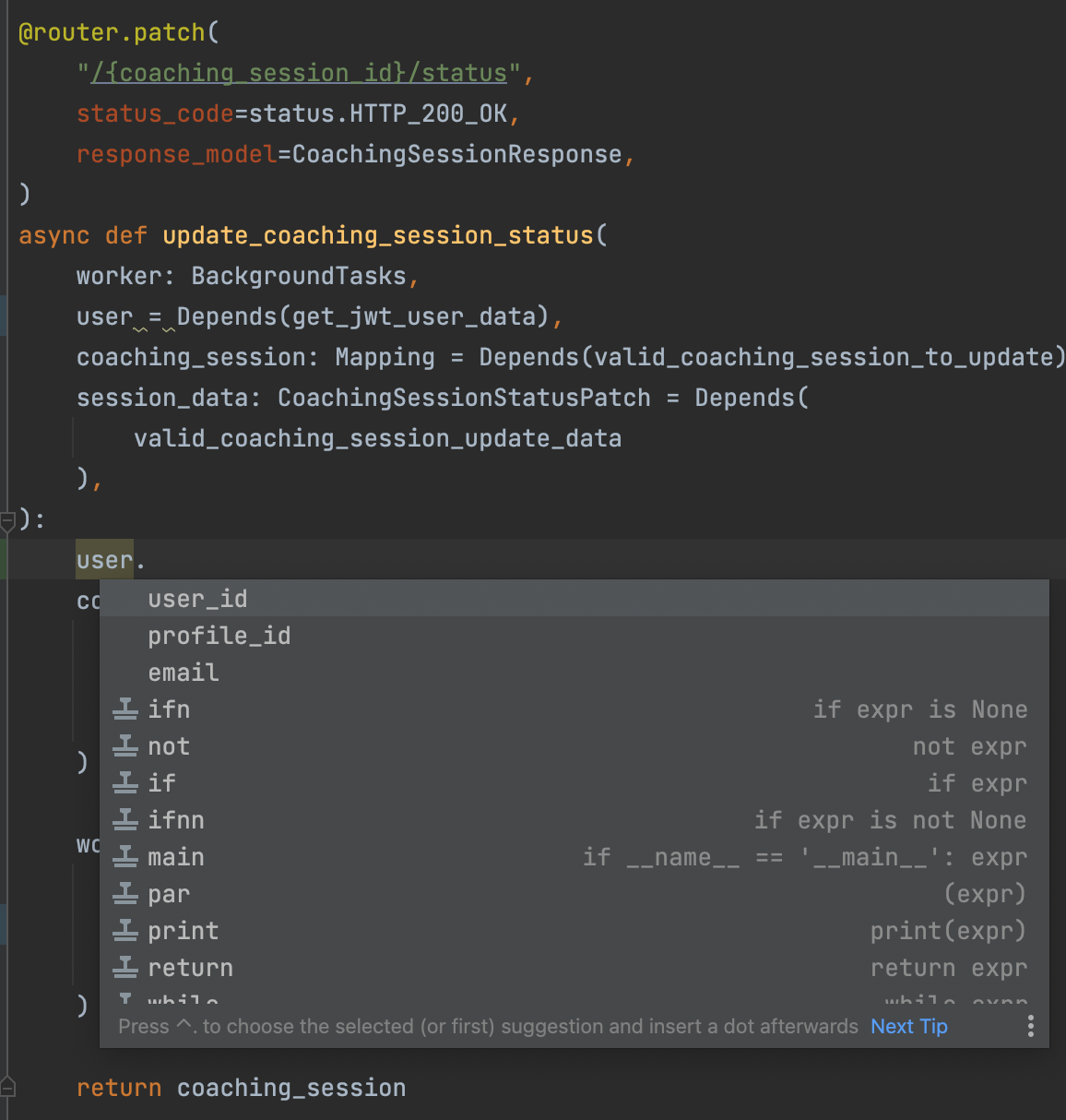
16. 类型注解很重要¶
Typing is important
FastAPI, Pydantic, 以及现代的 IDE 鼓励使用类型提示。
没有类型提示:

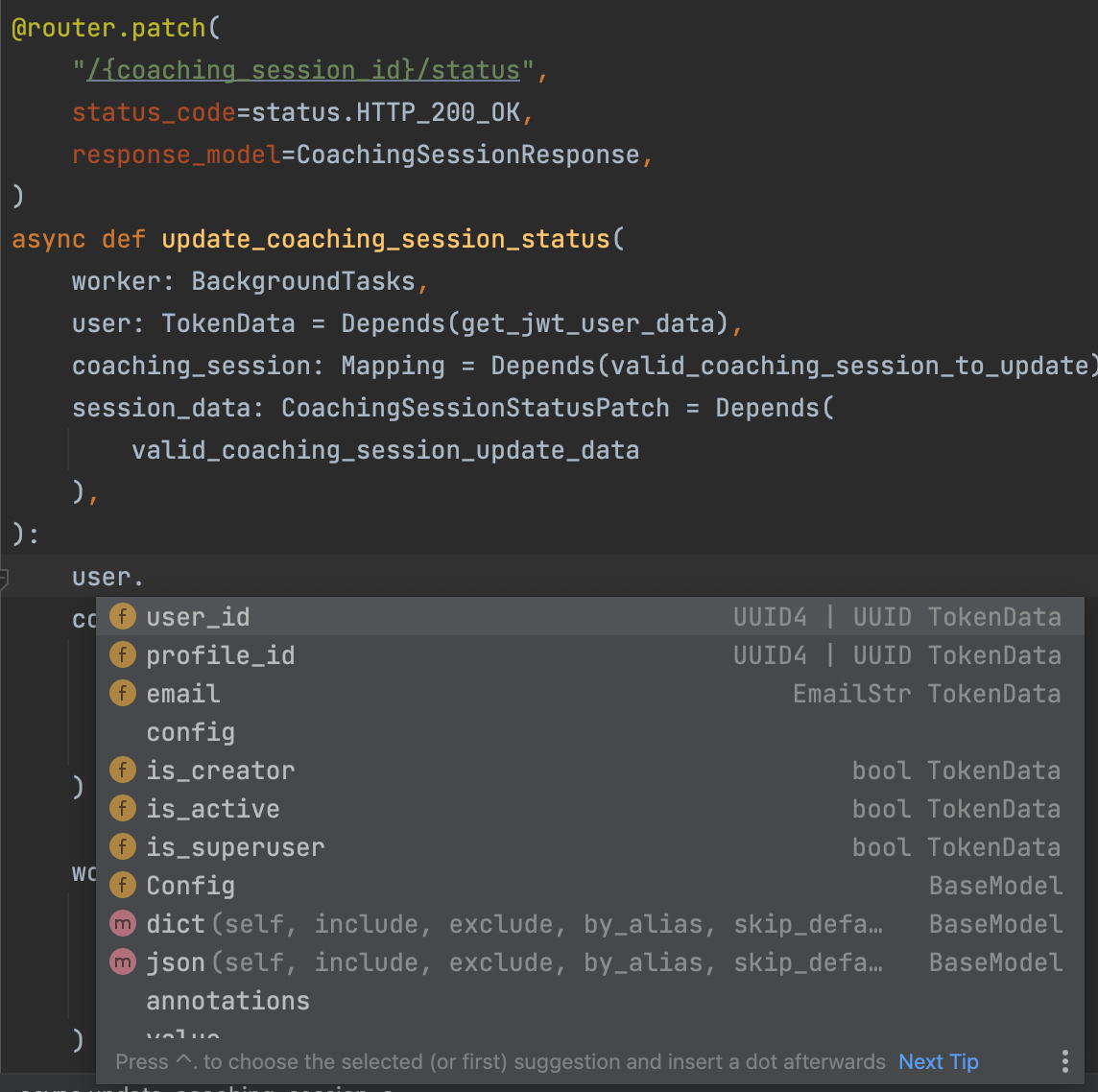
有类型提示:

FastAPI, Pydantic, and modern IDEs encourage to take use of type hints.
Without Type Hints
With Type Hints
17. 以chunks(块)的形式保存文件¶
Save files in chunks
不要期望您的客户端发送小文件。
import aiofiles
from fastapi import UploadFile
DEFAULT_CHUNK_SIZE = 1024 * 1024 * 50 # 50 megabytes MB(兆字节)
async def save_video(video_file: UploadFile):
async with aiofiles.open("/file/path/name.mp4", "wb") as f:
while chunk := await video_file.read(DEFAULT_CHUNK_SIZE):
await f.write(chunk)
Don't hope your clients will send small files.
import aiofiles
from fastapi import UploadFile
DEFAULT_CHUNK_SIZE = 1024 * 1024 * 50 # 50 megabytes
async def save_video(video_file: UploadFile):
async with aiofiles.open("/file/path/name.mp4", "wb") as f:
while chunk := await video_file.read(DEFAULT_CHUNK_SIZE):
await f.write(chunk)
18. 小心pydantic的动态字段¶
Be careful with dynamic pydantic fields
如果你有一个可以接受联合类型(Union)的 pydantic 字段,请确保验证器明确知道这些类型之间的区别。
from pydantic import BaseModel
class Article(BaseModel):
text: str | None
extra: str | None
class Video(BaseModel):
video_id: int
text: str | None
extra: str | None
class Post(BaseModel):
content: Article | Video
post = Post(content={"video_id": 1, "text": "text"})
print(type(post.content))
# OUTPUT: Article
# Article 非常包容,所有字段都是可选的,允许任何字典生效
解决方案:
-
验证输入只允许有效字段并在提供未知数时引发错误
from pydantic import BaseModel, Extra class Article(BaseModel): text: str | None extra: str | None class Config: extra = Extra.forbid class Video(BaseModel): video_id: int text: str | None extra: str | None class Config: extra = Extra.forbid class Post(BaseModel): content: Article | Video -
如果字段很简单,请使用 Pydantic 的 Smart Union (>v1.9)
如果字段很简单,如
int或bool,这是一个很好的解决方案,但它不适用于类等复杂字段。没有 Smart Union :
from pydantic import BaseModel class Post(BaseModel): field_1: bool | int field_2: int | str content: Article | Video p = Post(field_1=1, field_2="1", content={"video_id": 1}) print(p.field_1) # OUTPUT: True print(type(p.field_2)) # OUTPUT: int print(type(p.content)) # OUTPUT: Article有 Smart Union :
class Post(BaseModel): field_1: bool | int field_2: int | str content: Article | Video class Config: smart_union = True p = Post(field_1=1, field_2="1", content={"video_id": 1}) print(p.field_1) # OUTPUT: 1 print(type(p.field_2)) # OUTPUT: str print(type(p.content)) # OUTPUT: Article, 因为 smart_union 不适用于像类这样的复杂字段 -
快速解决方法
正确排序字段类型: 从最严格的到宽松的校验。
class Post(BaseModel): content: Video | Article
If you have a pydantic field that can accept a union of types, be sure the validator explicitly knows the difference between those types.
from pydantic import BaseModel
class Article(BaseModel):
text: str | None
extra: str | None
class Video(BaseModel):
video_id: int
text: str | None
extra: str | None
class Post(BaseModel):
content: Article | Video
post = Post(content={"video_id": 1, "text": "text"})
print(type(post.content))
# OUTPUT: Article
# Article is very inclusive and all fields are optional, allowing any dict to become valid
Solutions:
- Validate input has only allowed valid fields and raise error if unknowns are provided
from pydantic import BaseModel, Extra
class Article(BaseModel):
text: str | None
extra: str | None
class Config:
extra = Extra.forbid
class Video(BaseModel):
video_id: int
text: str | None
extra: str | None
class Config:
extra = Extra.forbid
class Post(BaseModel):
content: Article | Video
- Use Pydantic's Smart Union (>v1.9) if fields are simple
It's a good solution if the fields are simple like int or bool,
but it doesn't work for complex fields like classes.
Without Smart Union
from pydantic import BaseModel
class Post(BaseModel):
field_1: bool | int
field_2: int | str
content: Article | Video
p = Post(field_1=1, field_2="1", content={"video_id": 1})
print(p.field_1)
# OUTPUT: True
print(type(p.field_2))
# OUTPUT: int
print(type(p.content))
# OUTPUT: Article
With Smart Union
class Post(BaseModel):
field_1: bool | int
field_2: int | str
content: Article | Video
class Config:
smart_union = True
p = Post(field_1=1, field_2="1", content={"video_id": 1})
print(p.field_1)
# OUTPUT: 1
print(type(p.field_2))
# OUTPUT: str
print(type(p.content))
# OUTPUT: Article, because smart_union doesn't work for complex fields like classes
- Fast Workaround
Order field types properly: from the most strict ones to loose ones.
class Post(BaseModel):
content: Video | Article
19. SQL-第一, Pydantic-第二¶
SQL-first, Pydantic-second
- 通常,数据库处理数据的速度比 CPython 更快、更干净。
- 最好使用 SQL 执行所有复杂的连接和简单的数据操作。
- 最好在数据库中聚合 JSON 以响应嵌套对象。
# src.posts.service
from typing import Mapping
from pydantic import UUID4
from sqlalchemy import desc, func, select, text
from sqlalchemy.sql.functions import coalesce
from src.database import database, posts, profiles, post_review, products
async def get_posts(
creator_id: UUID4, *, limit: int = 10, offset: int = 0
) -> list[Mapping]:
select_query = (
select(
(
posts.c.id,
posts.c.type,
posts.c.slug,
posts.c.title,
func.json_build_object(
text("'id', profiles.id"),
text("'first_name', profiles.first_name"),
text("'last_name', profiles.last_name"),
text("'username', profiles.username"),
).label("creator"),
)
)
.select_from(posts.join(profiles, posts.c.owner_id == profiles.c.id))
.where(posts.c.owner_id == creator_id)
.limit(limit)
.offset(offset)
.group_by(
posts.c.id,
posts.c.type,
posts.c.slug,
posts.c.title,
profiles.c.id,
profiles.c.first_name,
profiles.c.last_name,
profiles.c.username,
profiles.c.avatar,
)
.order_by(
desc(coalesce(posts.c.updated_at, posts.c.published_at, posts.c.created_at))
)
)
return await database.fetch_all(select_query)
# src.posts.schemas
import orjson
from enum import Enum
from pydantic import BaseModel, UUID4, validator
class PostType(str, Enum):
ARTICLE = "ARTICLE"
COURSE = "COURSE"
class Creator(BaseModel):
id: UUID4
first_name: str
last_name: str
username: str
class Post(BaseModel):
id: UUID4
type: PostType
slug: str
title: str
creator: Creator
@validator("creator", pre=True) # before default validation
def parse_json(cls, creator: str | dict | Creator) -> dict | Creator:
if isinstance(creator, str): # i.e. json
return orjson.loads(creator)
return creator
# src.posts.router
from fastapi import APIRouter, Depends
router = APIRouter()
@router.get("/creators/{creator_id}/posts", response_model=list[Post])
async def get_creator_posts(creator: Mapping = Depends(valid_creator_id)):
posts = await service.get_posts(creator["id"])
return posts
如果聚合数据表单 DB 是一个简单的 JSON,那么看看 Pydantic 的Json字段类型,它将首先加载原始 JSON。
from pydantic import BaseModel, Json
class A(BaseModel):
numbers: Json[list[int]]
dicts: Json[dict[str, int]]
valid_a = A(numbers="[1, 2, 3]", dicts='{"key": 1000}') # becomes A(numbers=[1,2,3], dicts={"key": 1000})
invalid_a = A(numbers='["a", "b", "c"]', dicts='{"key": "str instead of int"}') # raises ValueError
- Usually, database handles data processing much faster and cleaner than CPython will ever do.
- It's preferable to do all the complex joins and simple data manipulations with SQL.
- It's preferable to aggregate JSONs in DB for responses with nested objects.
# src.posts.service
from typing import Mapping
from pydantic import UUID4
from sqlalchemy import desc, func, select, text
from sqlalchemy.sql.functions import coalesce
from src.database import database, posts, profiles, post_review, products
async def get_posts(
creator_id: UUID4, *, limit: int = 10, offset: int = 0
) -> list[Mapping]:
select_query = (
select(
(
posts.c.id,
posts.c.type,
posts.c.slug,
posts.c.title,
func.json_build_object(
text("'id', profiles.id"),
text("'first_name', profiles.first_name"),
text("'last_name', profiles.last_name"),
text("'username', profiles.username"),
).label("creator"),
)
)
.select_from(posts.join(profiles, posts.c.owner_id == profiles.c.id))
.where(posts.c.owner_id == creator_id)
.limit(limit)
.offset(offset)
.group_by(
posts.c.id,
posts.c.type,
posts.c.slug,
posts.c.title,
profiles.c.id,
profiles.c.first_name,
profiles.c.last_name,
profiles.c.username,
profiles.c.avatar,
)
.order_by(
desc(coalesce(posts.c.updated_at, posts.c.published_at, posts.c.created_at))
)
)
return await database.fetch_all(select_query)
# src.posts.schemas
import orjson
from enum import Enum
from pydantic import BaseModel, UUID4, validator
class PostType(str, Enum):
ARTICLE = "ARTICLE"
COURSE = "COURSE"
class Creator(BaseModel):
id: UUID4
first_name: str
last_name: str
username: str
class Post(BaseModel):
id: UUID4
type: PostType
slug: str
title: str
creator: Creator
@validator("creator", pre=True) # before default validation
def parse_json(cls, creator: str | dict | Creator) -> dict | Creator:
if isinstance(creator, str): # i.e. json
return orjson.loads(creator)
return creator
# src.posts.router
from fastapi import APIRouter, Depends
router = APIRouter()
@router.get("/creators/{creator_id}/posts", response_model=list[Post])
async def get_creator_posts(creator: Mapping = Depends(valid_creator_id)):
posts = await service.get_posts(creator["id"])
return posts
If an aggregated data form DB is a simple JSON, then take a look at Pydantic's Json field type,
which will load raw JSON first.
from pydantic import BaseModel, Json
class A(BaseModel):
numbers: Json[list[int]]
dicts: Json[dict[str, int]]
valid_a = A(numbers="[1, 2, 3]", dicts='{"key": 1000}') # becomes A(numbers=[1,2,3], dicts={"key": 1000})
invalid_a = A(numbers='["a", "b", "c"]', dicts='{"key": "str instead of int"}') # raises ValueError
20. 验证host,如果用户可以发送公开可用的 URL¶
Validate hosts, if users can send publicly available URLs
例如,我们有一个特定的入口:
- 接受来自用户的媒体文件,
- 为此文件生成唯一的 url,
- 返回 url 给用户,
- 他们将在其他入口使用它们,例如
PUT /profiles/me,POST /posts - 这些端点只接受来自白名单主机的文件
- 使用此名称和匹配的 URL 将文件上传到 AWS。
如果我们不将 URL 主机列入白名单,那么不良用户就有机会上传危险链接。
from pydantic import AnyUrl, BaseModel
ALLOWED_MEDIA_URLS = {"mysite.com", "mysite.org"}
class CompanyMediaUrl(AnyUrl):
@classmethod
def validate_host(cls, parts: dict) -> tuple[str, str, str, bool]:
"""将 pydantic 的 AnyUrl 验证扩展到白名单 URL 主机。"""
host, tld, host_type, rebuild = super().validate_host(parts)
if host not in ALLOWED_MEDIA_URLS:
raise ValueError(
"Forbidden host url. Upload files only to internal services."
)
return host, tld, host_type, rebuild
class Profile(BaseModel):
avatar_url: CompanyMediaUrl # only whitelisted urls for avatar
For example, we have a specific endpoint which:
- accepts media file from the user,
- generates unique url for this file,
- returns url to user,
- which they will use in other endpoints like
PUT /profiles/me,POST /posts - these endpoints accept files only from whitelisted hosts
- uploads file to AWS with this name and matching URL.
If we don't whitelist URL hosts, then bad users will have a chance to upload dangerous links.
from pydantic import AnyUrl, BaseModel
ALLOWED_MEDIA_URLS = {"mysite.com", "mysite.org"}
class CompanyMediaUrl(AnyUrl):
@classmethod
def validate_host(cls, parts: dict) -> tuple[str, str, str, bool]:
"""Extend pydantic's AnyUrl validation to whitelist URL hosts."""
host, tld, host_type, rebuild = super().validate_host(parts)
if host not in ALLOWED_MEDIA_URLS:
raise ValueError(
"Forbidden host url. Upload files only to internal services."
)
return host, tld, host_type, rebuild
class Profile(BaseModel):
avatar_url: CompanyMediaUrl # only whitelisted urls for avatar
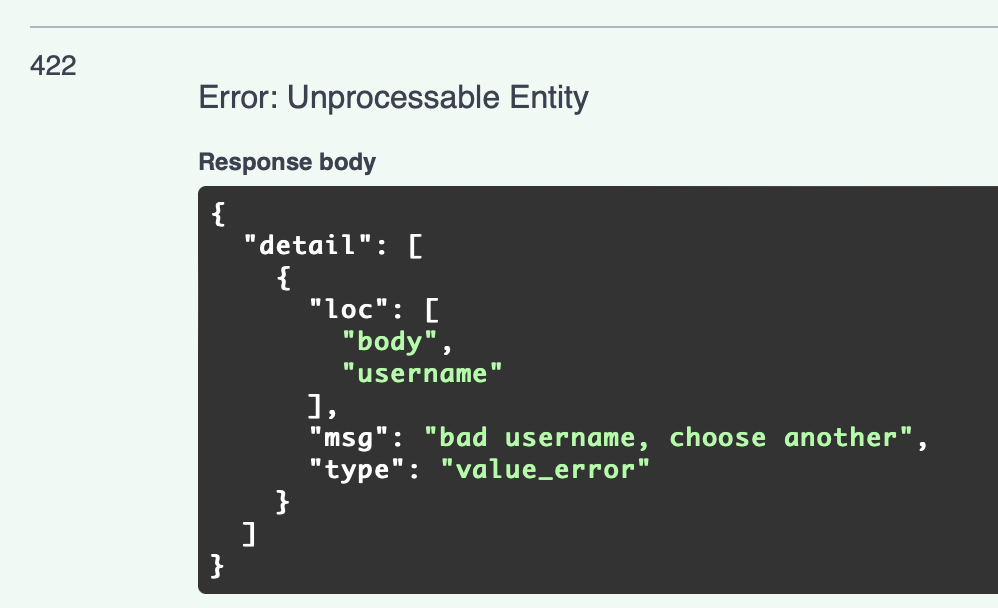
21. 如果schema直接面向客户端,在pydantic的自定义校验中抛出ValueError¶
Raise a ValueError in custom pydantic validators, if schema directly faces the client
它将向用户返回一个很好的详细响应。
# src.profiles.schemas
from pydantic import BaseModel, validator
class ProfileCreate(BaseModel):
username: str
@validator("username")
def validate_bad_words(cls, username: str):
if username == "me":
raise ValueError("bad username, choose another")
return username
# src.profiles.routes
from fastapi import APIRouter
router = APIRouter()
@router.post("/profiles")
async def get_creator_posts(profile_data: ProfileCreate):
pass
Response 例子:

It will return a nice detailed response to users.
# src.profiles.schemas
from pydantic import BaseModel, validator
class ProfileCreate(BaseModel):
username: str
@validator("username")
def validate_bad_words(cls, username: str):
if username == "me":
raise ValueError("bad username, choose another")
return username
# src.profiles.routes
from fastapi import APIRouter
router = APIRouter()
@router.post("/profiles")
async def get_creator_posts(profile_data: ProfileCreate):
pass
Response Example:
22. 不要忘记 FastAPI 将 Response 的 Pydantic 对象转换为 Dict,然后转换为 ResponseModel 的实例,然后转换为 Dict,然后转换为 JSON¶
Don't forget FastAPI converts Response Pydantic Object to Dict then to an instance of ResponseModel then to Dict then to JSON
from fastapi import FastAPI
from pydantic import BaseModel, root_validator
app = FastAPI()
class ProfileResponse(BaseModel):
@root_validator
def debug_usage(cls, data: dict):
print("created pydantic model")
return data
def dict(self, *args, **kwargs):
print("called dict")
return super().dict(*args, **kwargs)
@app.get("/", response_model=ProfileResponse)
async def root():
return ProfileResponse()
日志输出:
[INFO] [2022-08-28 12:00:00.000000] created pydantic model
[INFO] [2022-08-28 12:00:00.000010] called dict
[INFO] [2022-08-28 12:00:00.000020] created pydantic model
[INFO] [2022-08-28 12:00:00.000030] called dict
from fastapi import FastAPI
from pydantic import BaseModel, root_validator
app = FastAPI()
class ProfileResponse(BaseModel):
@root_validator
def debug_usage(cls, data: dict):
print("created pydantic model")
return data
def dict(self, *args, **kwargs):
print("called dict")
return super().dict(*args, **kwargs)
@app.get("/", response_model=ProfileResponse)
async def root():
return ProfileResponse()
Logs Output:
[INFO] [2022-08-28 12:00:00.000000] created pydantic model
[INFO] [2022-08-28 12:00:00.000010] called dict
[INFO] [2022-08-28 12:00:00.000020] created pydantic model
[INFO] [2022-08-28 12:00:00.000030] called dict
23. 如果你必须使用sync(同步) SDK, 请在线程池中运行¶
If you must use sync SDK, then run it in a thread pool
如果您必须使用库与外部服务交互,并且它不支持async(异步),则在外部工作线程中进行 HTTP 调用。
举个简单的例子,我们可以使用来自 starlette 的著名的run_in_threadpool。
from fastapi import FastAPI
from fastapi.concurrency import run_in_threadpool
from my_sync_library import SyncAPIClient
app = FastAPI()
@app.get("/")
async def call_my_sync_library():
my_data = await service.get_my_data()
client = SyncAPIClient()
await run_in_threadpool(client.make_request, data=my_data)
If you must use a library to interact with external services, and it's not async,
then make the HTTP calls in an external worker thread.
For a simple example, we could use our well-known run_in_threadpool from starlette.
from fastapi import FastAPI
from fastapi.concurrency import run_in_threadpool
from my_sync_library import SyncAPIClient
app = FastAPI()
@app.get("/")
async def call_my_sync_library():
my_data = await service.get_my_data()
client = SyncAPIClient()
await run_in_threadpool(client.make_request, data=my_data)
24. 使用 linters (black, isort, autoflake)¶
Use linters (black, isort, autoflake)
使用 linters, 您可以忘记格式化代码并专注于编写业务逻辑。
Black 是一个毫不妥协的代码格式化程序,它消除了您在开发过程中必须做出的许多小决定。 其他 linter 可帮助您编写更清晰的代码并遵循 PEP8。
使用pre-commit hook(预提交钩子)是一种流行的良好做法,但仅使用脚本对我们来说就可以了。
#!/bin/sh -e
set -x
autoflake --remove-all-unused-imports --recursive --remove-unused-variables --in-place src tests --exclude=__init__.py
isort src tests --profile black
black src tests
With linters, you can forget about formatting the code and focus on writing the business logic.
Black is the uncompromising code formatter that eliminates so many small decisions you have to make during development. Other linters help you write cleaner code and follow the PEP8.
It's a popular good practice to use pre-commit hooks, but just using the script was ok for us.
#!/bin/sh -e
set -x
autoflake --remove-all-unused-imports --recursive --remove-unused-variables --in-place src tests --exclude=__init__.py
isort src tests --profile black
black src tests
惊喜部分¶
Bonus Section
一些非常善良的人分享了他们自己的经验和最佳实践,绝对值得一读。
在项目的 issues 部分查看它们。
例如,lowercase00 详细描述了他们使用权限和授权、基于类的服务和视图、任务队列的最佳实践, 自定义响应序列化程序,使用 dynaconf 进行配置等。
如果您有任何关于使用 FastAPI 的经验要分享,无论是好是坏,都非常欢迎您创建一个新问题。 阅读它是我们的荣幸。
Some very kind people shared their own experience and best practices that are definitely worth reading. Check them out at issues section of the project.
For instance, lowercase00 has described in details their best practices working with permissions & auth, class-based services & views, task queues, custom response serializers, configuration with dynaconf, etc.
If you have something to share about your experience working with FastAPI, whether it's good or bad, you are very welcome to create a new issue. It is our pleasure to read it.
创建日期: 2024年9月5日