将 PDF 文件转换为文本#
Converting a PDF file to text
大多数 PDF 文件看起来像是包含结构良好的文本。但实际上,PDF 文件并不包含类似段落、句子甚至单词的结构化文本。对于文本内容而言,PDF 文件只知道字符及其在页面上的位置。
这使得从 PDF 文件中提取有意义的文本变得困难。组成段落的字符与组成表格、页脚或图例描述的字符没有本质区别。与 .txt 文件或 Word 文档等其他文档格式不同,PDF 格式并不包含连续的文本流。
一个 PDF 文档由多个对象组成,这些对象共同描述一个或多个页面的外观,并可能包含额外的交互元素和高级应用数据。PDF 文件包含构成 PDF 文档的对象,以及相关的结构信息,并以一个完整的、自包含的字节序列表示。 [1]
Most PDF files look like they contain well-structured text. But the reality is that a PDF file does not contain anything that resembles paragraphs, sentences or even words. When it comes to text, a PDF file is only aware of the characters and their placement.
This makes extracting meaningful pieces of text from PDF files difficult. The characters that compose a paragraph are no different from those that compose the table, the page footer or the description of a figure. Unlike other document formats, like a .txt file or a word document, the PDF format does not contain a stream of text.
A PDF document consists of a collection of objects that together describe the appearance of one or more pages, possibly accompanied by additional interactive elements and higher-level application data. A PDF file contains the objects making up a PDF document along with associated structural information, all represented as a single self-contained sequence of bytes. [2]
布局分析算法#
Layout analysis algorithm
PDFMiner 试图通过对字符定位使用启发式方法来重建部分结构。对于句子和段落来说,这种方法效果良好,因为可以将相邻的字符组合成有意义的群组。
版面分析由三个不同的阶段组成:首先将字符组合成单词和行,然后将行组合成文本框,最后按层次结构组织文本框。这些阶段将在接下来的章节中讨论。版面分析的最终输出是 PDF 页面上布局对象的有序层次结构。
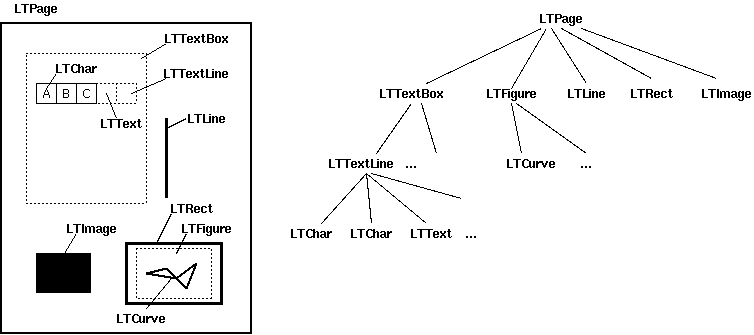
版面分析的输出是一个布局对象的层次结构。#
版面分析的输出在很大程度上取决于多个参数。这些参数都属于 LAParams 类的一部分。
PDFMiner attempts to reconstruct some of those structures by using heuristics on the positioning of characters. This works well for sentences and paragraphs because meaningful groups of nearby characters can be made.
The layout analysis consists of three different stages: it groups characters into words and lines, then it groups lines into boxes and finally it groups textboxes hierarchically. These stages are discussed in the following sections. The resulting output of the layout analysis is an ordered hierarchy of layout objects on a PDF page.
The output of the layout analysis is a hierarchy of layout objects.#
The output of the layout analysis heavily depends on a couple of parameters. All these parameters are part of the LAParams class.
将字符分组为单词和行#
Grouping characters into words and lines
从字符转换为文本的第一步是以有意义的方式对字符进行分组。每个字符都有一个 x 坐标和 y 坐标,分别表示其左下角和右上角的位置,即其边界框。Pdfminer.six 使用这些边界框来决定哪些字符属于同一组。
彼此在水平方向和垂直方向上都足够接近的字符将被分组成一行。字符之间的接近程度由 char_margin (图中的 M)和 line_overlap (图中未标示)参数决定。两个字符的边界框之间的水平 距离 应小于 char_margin,垂直 重叠 应大于 line_overlap。
| → | ← M | |||
Q u i |
c k |
b r o w n |
||
| → | ← W | |||
char_margin 和 line_overlap 的取值是相对于字符边界框大小的。char_margin 相对于两个边界框中最大宽度的字符,而 line_overlap 则相对于最小高度的字符。
由于 PDF 格式没有空格字符的概念,因此需要在字符之间插入空格。如果字符之间的间距大于 word_margin (图中的 W),则会插入一个空格。 word_margin 相对于新字符的最大宽度或高度。如果 word_margin 取值较小,则生成的单词间隔较小。需要注意的是, word_margin 至少应小于 char_margin,否则所有字符之间都不会插入空格。
这一阶段的结果是一个由多个行组成的列表。每一行包含一系列字符。这些字符可能是 PDF 文件中的原始 LTChar 字符,也可能是用于表示单词间空格或行末换行符的插入 LTAnno 字符。
The first step in going from characters to text is to group characters in a meaningful way. Each character has an x-coordinate and a y-coordinate for its bottom-left corner and upper-right corner, i.e. its bounding box. Pdfminer.six uses these bounding boxes to decide which characters belong together.
Characters that are both horizontally and vertically close are grouped onto one line. How close they should be is determined by the char_margin (M in the figure) and the line_overlap (not in figure) parameter. The horizontal distance between the bounding boxes of two characters should be smaller than the char_margin and the vertical overlap between the bounding boxes should be larger than the line_overlap.
| → | ← M | |||
Q u i |
c k |
b r o w n |
||
| → | ← W | |||
The values of char_margin and line_overlap are relative to the size of the bounding boxes of the characters. The char_margin is relative to the maximum width of either one of the bounding boxes, and the line_overlap is relative to the minimum height of either one of the bounding boxes.
Spaces need to be inserted between characters because the PDF format has no notion of the space character. A space is inserted if the characters are further apart than the word_margin (W in the figure). The word_margin is relative to the maximum width or height of the new character. Having a smaller word_margin creates smaller words. Note that the word_margin should at least be smaller than the char_margin otherwise none of the characters will be separated by a space.
The result of this stage is a list of lines. Each line consists of a list of characters. These characters are either original LTChar characters that originate from the PDF file or inserted LTAnno characters that represent spaces between words or newlines at the end of each line.
将行分组为框#
Grouping lines into boxes
第二步是以有意义的方式对行进行分组。每一行的边界框由其包含的字符的边界框决定。与字符分组类似,pdfminer.six 也使用边界框来对行进行分组。
彼此在水平方向上有重叠且在垂直方向上足够接近的行将被分组。行之间的垂直接近程度由 line_margin 参数决定。该参数是相对于边界框高度指定的。如果两个行的边界框顶部之间的间隙(见图中的 L 1 )或底部之间的间隙(见图中的 L 2 )小于 line_margin 乘以边界框高度的绝对值,则认为它们是接近的。
| ↓ | |||
Q u i c k b r o w
n |
↓ | ||
| L1 | |||
f o x
|
↑ | L2 | |
| ↑ | |||
这一阶段的结果是一个由文本框组成的列表。每个文本框包含一个由多行组成的列表。
The second step is grouping lines in a meaningful way. Each line has a bounding box that is determined by the bounding boxes of the characters that it contains. Like grouping characters, pdfminer.six uses the bounding boxes to group the lines.
Lines that are both horizontally overlapping and vertically close are grouped. How vertically close the lines should be is determined by the line_margin. This margin is specified relative to the height of the bounding box. Lines are close if the gap between the tops (see L 1 in the figure) and bottoms (see L 2) in the figure) of the bounding boxes are closer together than the absolute line margin, i.e. the line_margin multiplied by the height of the bounding box.
| ↓ | |||
Q u i c k b r o w
n |
↓ | ||
| L1 | |||
f o x
|
↑ | L2 | |
| ↑ | |||
The result of this stage is a list of text boxes. Each box consists of a list of lines.
按层次对文本框进行分组#
Grouping textboxes hierarchically
最后一步是以有意义的方式对文本框进行分组。该步骤会重复合并彼此最接近的两个文本框。
文本框之间的接近程度是通过计算它们之间的区域(图中的蓝色区域)来确定的。换句话说,它是包含两个文本框的边界框的面积,减去单个文本框的边界框面积之和。
Q u i c k b r o w n
|
|||
j u m p s ... |
|||
The last step is to group the text boxes in a meaningful way. This step repeatedly merges the two text boxes that are closest to each other.
The closeness of bounding boxes is computed as the area that is between the two text boxes (the blue area in the figure). In other words, it is the area of the bounding box that surrounds both lines, minus the area of the bounding boxes of the individual lines.
Q u i c k b r o w n
|
|||
j u m p s ... |
|||
处理旋转字符#
Working with rotated characters
上述算法假设所有字符的方向相同。然而,在 PDF 中,任何书写方向都是可能的。 为了适应这种情况,pdfminer.six 允许使用 detect_vertical 参数检测竖排文本。 如果启用该参数,所有分组步骤都会按照 PDF 旋转 90 度(或 270 度)的方式进行处理。
The algorithm described above assumes that all characters have the same orientation. However, any writing direction is possible in a PDF. To accommodate for this, pdfminer.six allows detecting vertical writing with the detect_vertical parameter. This will apply all the grouping steps as if the pdf was rotated 90 (or 270) degrees
参考文献#
References