4.3 并行计算
计算机每一年都会变得越来越快。在 1965 年,英特尔联合创始人戈登·摩尔预测了计算机将如何随时间而变得越来越快。仅仅基于五个数据点,他推测,一个芯片中的晶体管数量每两年将翻一倍。近50年后,他的预测仍惊人地准确,现在称为摩尔定律。
尽管速度在爆炸式增长,计算机还是无法跟上可用数据的规模。根据一些估计,基因测序技术的进步将使可用的基因序列数据比处理器变得更快的速度还要快。换句话说,对于遗传数据,计算机变得越来越不能处理每年需要处理的问题规模,即使计算机本身变得越来越快。
为了规避对单个处理器速度的物理和机械约束,
制造商正在转向另一种解决方案:多处理器。
如果两个,或三个,或更多的处理器是可用的,那么许多程序可以更快地执行。
当一个处理器在做一些计算的一个切面时,其他的可以在另一个切面工作。
所有处理器都可以共享相同的数据,但工作并行执行。
为了能够合作,多个处理器需要能够彼此共享信息。这通过使用共享内存环境来完成。该环境中的变量、对象和数据结构对所有的进程可见。处理器在计算中的作用是执行编程语言的求值和执行规则。在一个共享内存模型中,不同的进程可能执行不同的语句,但任何语句都会影响共享环境。
4.3.1 共享状态的问题
多个进程之间的共享状态具有单一进程环境没有的问题。要理解其原因,让我们看看下面的简单计算:
x = 5
x = square(x)
x = x + 1
x的值是随时间变化的。起初它是 5,一段时间后它是 25,最后它是 26。在单一处理器的环境中,没有时间依赖性的问题。x的值在结束时总是 26。但是如果存在多个进程,就不能这样说了。假设我们并行执行了上面代码的最后两行:一个处理器执行x = square(x)而另一个执行x = x + 1。每一个这些赋值语句都包含查找当前绑定到x的值,然后使用新值更新绑定。让我们假设x是共享的,同一时间只有一个进程读取或写入。即使如此,读和写的顺序可能会有所不同。例如,下面的例子显示了两个进程的每个进程的一系列步骤,P1和P2。每一步都是简要描述的求值过程的一部分,随时间从上到下执行:
P1 P2
read x: 5
read x: 5
calculate 5*5: 25 calculate 5+1: 6
write 25 -> x
write x-> 6
在这个顺序中,x的最终值为 6。如果我们不协调这两个过程,我们可以得到另一个顺序的不同结果:
P1 P2
read x: 5
read x: 5 calculate 5+1: 6
calculate 5*5: 25 write x->6
write 25 -> x
在这个顺序中,x将是 25。事实上存在多种可能性,这取决于进程执行代码行的顺序。x的最终值可能最终为 5,25,或预期值 26。
前面的例子是无价值的。square(x)和x = x + 1是简单快速的计算。我们强迫一条语句跑在另一条的后面,并不会失去太多的时间。但是什么样的情况下,并行化是必不可少的?这种情况的一个例子是银行业。在任何给定的时间,可能有成千上万的人想用他们的银行账户进行交易:他们可能想在商店刷卡,存入支票,转帐,或支付账单。即使一个帐户在同一时间也可能有活跃的多个交易。
让我们看看第二章的make_withdraw函数,下面是修改过的版本,在更新余额之后打印而不是返回它。我们感兴趣的是这个函数将如何并发执行。
>>> def make_withdraw(balance):
def withdraw(amount):
nonlocal balance
if amount > balance:
print('Insufficient funds')
else:
balance = balance - amount
print(balance)
return withdraw
现在想象一下,我们以 10 美元创建一个帐户,让我们想想,如果我们从帐户中提取太多的钱会发生什么。如果我们顺序执行这些交易,我们会收到资金不足的消息。
>>> w = make_withdraw(10)
>>> w(8)
2
>>> w(7)
'Insufficient funds'
但是,在并行中可以有许多不同的结果。下面展示了一种可能性:
P1: w(8) P2: w(7)
read balance: 10
read amount: 8 read balance: 10
8 > 10: False read amount: 7
if False 7 > 10: False
10 - 8: 2 if False
write balance -> 2 10 - 7: 3
read balance: 2 write balance -> 3
print 2 read balance: 3
print 3
这个特殊的例子给出了一个不正确结果 3。就好像w(8)交易从来没有发生过。其他可能的结果是 2,和'Insufficient funds'。这个问题的根源是:如果P2 在P1写入值前读取余额,P2的状态是不一致的(反之亦然)。P2所读取的余额值是过时的,因为P1打算改变它。P2不知道,并且会用不一致的值覆盖它。
这个例子表明,并行化的代码不像把代码行分给多个处理器来执行那样容易。变量读写的顺序相当重要。
一个保证执行正确性的有吸引力的方式是,两个修改共享数据的程序不能同时执行。不幸的是,对于银行业这将意味着,一次只可以进行一个交易,因为所有的交易都修改共享数据。直观地说,我们明白,让 2 个不同的人同时进行完全独立的帐户交易应该没有问题。不知何故,这两个操作不互相干扰,但在同一帐户上的相同方式的同时操作就相互干扰。此外,当进程不读取或写入时,让它们同时运行就没有问题。
4.3.2 并行计算的正确性
并行计算环境中的正确性有两个标准。第一个是,结果应该总是相同。第二个是,结果应该和串行执行的结果一致。
第一个条件表明,我们必须避免在前面的章节中所示的变化,其中在不同的方式下的交叉读写会产生不同的结果。例子中,我们从 10 美元的帐户取出了w(8)和w(7)。这个条件表明,我们必须始终返回相同的答案,独立于P1和P2的指令执行顺序。无论如何,我们必须以这样一种方式来编写我们的程序,无论他们如何相互交叉,他们应该总是产生同样的结果。
第二个条件揭示了许多可能的结果中哪个是正确的。例子中,我们从 10 美元的帐户取出了w(8)和w(7),这个条件表明结果必须总是余额不足,而不是 2 或者 3。
当一个进程在程序的临界区影响另一个进程时,并行计算中就会出现问题。这些都是需要执行的代码部分,它们看似是单一的指令,但实际上由较小的语句组成。一个程序会以一系列原子硬件指令执行,由于处理器的设计,这些是不能被打断或分割为更小单元的指令。为了在并行的情况下表现正确,程序代码的临界区需要具有原子性,保证他们不会被任何其他代码中断。
为了强制程序临界区在并发下的原子性,需要能够在重要的时刻将进程序列化或彼此同步。序列化意味着同一时间只运行一个进程 -- 这一瞬间就好像串行执行一样。同步有两种形式。首先是互斥,进程轮流访问一个变量。其次是条件同步,在满足条件(例如其他进程完成了它们的任务)之前进程一直等待,之后继续执行。这样,当一个程序即将进入临界区时,其他进程可以一直等待到它完成,然后安全地执行。
4.3.3 保护共享状态:锁和信号量
在本节中讨论的所有同步和序列化方法都使用相同的基本思想。它们在共享状态中将变量用作信号,所有过程都会理解并遵守它。这是一个相同的理念,允许分布式系统中的计算机协同工作 -- 它们通过传递消息相互协调,根据每一个参与者都理解和遵守的一个协议。
这些机制不是为了保护共享状态而出现的物理障碍。相反,他们是建立相互理解的基础上。和出现在十字路口的各种方向的车辆能够安全通行一样,是同一种相互理解。这里没有物理的墙壁阻止汽车相撞,只有遵守规则,红色意味着“停止”,绿色意味着“通行”。同样,没有什么可以保护这些共享变量,除非当一个特定的信号表明轮到某个进程了,进程才会访问它们。
锁。 锁,也被称为互斥体(mutex),是共享对象,常用于发射共享状态被读取或修改的信号。不同的编程语言实现锁的方式不同,但是在 Python 中,一个进程可以调用acquire()方法来尝试获得锁的“所有权”,然后在使用完共享变量的时候调用release()释放它。当进程获得了一把锁,任何试图执行acquire()操作的其他进程都会自动等待到锁被释放。这样,同一时间只有一个进程可以获得一把锁。
对于一把保护一组特定的变量的锁,所有的进程都需要编程来遵循一个规则:一个进程不拥有特定的锁就不能访问相应的变量。实际上,所有进程都需要在锁的acquire()和release()语句之间“包装”自己对共享变量的操作。
我们可以把这个概念用于银行余额的例子中。该示例的临界区是从余额读取到写入的一组操作。我们看到,如果一个以上的进程同时执行这个区域,问题就会发生。为了保护临界区,我们需要使用一把锁。我们把这把锁称为balance_lock(虽然我们可以命名为任何我们喜欢的名字)。为了锁定实际保护的部分,我们必须确保试图进入这部分时调用acquire()获取锁,以及之后调用release()释放锁,这样可以轮到别人。
>>> from threading import Lock
>>> def make_withdraw(balance):
balance_lock = Lock()
def withdraw(amount):
nonlocal balance
# try to acquire the lock
balance_lock.acquire()
# once successful, enter the critical section
if amount > balance:
print("Insufficient funds")
else:
balance = balance - amount
print(balance)
# upon exiting the critical section, release the lock
balance_lock.release()
如果我们建立和之前一样的情形:
w = make_withdraw(10)
现在就可以并行执行w(8)和w(7)了:
P1 P2
acquire balance_lock: ok
read balance: 10 acquire balance_lock: wait
read amount: 8 wait
8 > 10: False wait
if False wait
10 - 8: 2 wait
write balance -> 2 wait
read balance: 2 wait
print 2 wait
release balance_lock wait
acquire balance_lock:ok
read balance: 2
read amount: 7
7 > 2: True
if True
print 'Insufficient funds'
release balance_lock
我们看到了,两个进程同时进入临界区是可能的。某个进程实例获取到了balance_lock,另一个就得等待,直到那个进程退出了临界区,它才能开始执行。
要注意程序不会自己终止,除非P1释放了balance_lock。如果它没有释放balance_lock,P2永远不可能获取它,而是一直会等待。忘记释放获得的锁是并行编程中的一个常见错误。
信号量。 信号量是用于维持有限资源访问的信号。它们和锁类似,除了它们可以允许某个限制下的多个访问。它就像电梯一样只能够容纳几个人。一旦达到了限制,想要使用资源的进程就必须等待。其它进程释放了信号量之后,它才可以获得。
例如,假设有许多进程需要读取中心数据库服务器的数据。如果过多的进程同时访问它,它就会崩溃,所以限制连接数量就是个好主意。如果数据库只能同时支持N=2的连接,我们就可以以初始值N=2来创建信号量。
>>> from threading import Semaphore
>>> db_semaphore = Semaphore(2) # set up the semaphore
>>> database = []
>>> def insert(data):
db_semaphore.acquire() # try to acquire the semaphore
database.append(data) # if successful, proceed
db_semaphore.release() # release the semaphore
>>> insert(7)
>>> insert(8)
>>> insert(9)
信号量的工作机制是,所有进程只在获取了信号量之后才可以访问数据库。只有N=2个进程可以获取信号量,其它的进程都需要等到其中一个进程释放了信号量,之后在访问数据库之前尝试获取它。
P1 P2 P3
acquire db_semaphore: ok acquire db_semaphore: wait acquire db_semaphore: ok
read data: 7 wait read data: 9
append 7 to database wait append 9 to database
release db_semaphore: ok acquire db_semaphore: ok release db_semaphore: ok
read data: 8
append 8 to database
release db_semaphore: ok
值为 1 的信号量的行为和锁一样。
4.3.4 保持同步:条件变量
条件变量在并行计算由一系列步骤组成时非常有用。进程可以使用条件变量,来用信号告知它完成了特定的步骤。之后,等待信号的其它进程就会开始它们的任务。一个需要逐步计算的例子就是大规模向量序列的计算。在计算生物学,Web 范围的计算,和图像处理及图形学中,常常需要处理非常大型(百万级元素)的向量和矩阵。想象下面的计算:
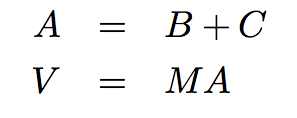
我们可以通过将矩阵和向量按行拆分,并把每一行分配到单独的线程上,来并行处理每一步。作为上面的计算的一个实例,想象下面的简单值:
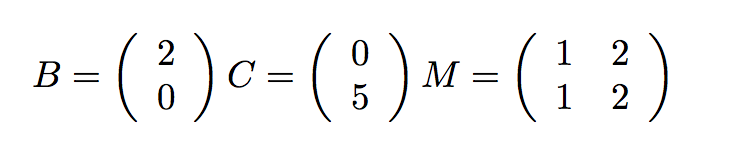
我们将前一半(这里是第一行)分配给一个线程,后一半(第二行)分配给另一个线程:
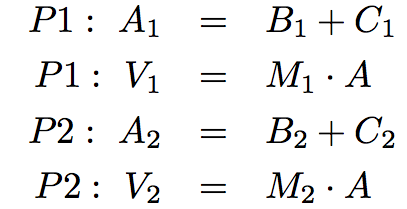
在伪代码中,计算是这样的:
def do_step_1(index):
A[index] = B[index] + C[index]
def do_step_2(index):
V[index] = M[index] . A
进程 1 执行了:
do_step_1(1)
do_step_2(1)
进程 2 执行了:
do_step_1(2)
do_step_2(2)
如果允许不带同步处理,就造成下面的不一致性:
P1 P2
read B1: 2
read C1: 0
calculate 2+0: 2
write 2 -> A1 read B2: 0
read M1: (1 2) read C2: 5
read A: (2 0) calculate 5+0: 5
calculate (1 2).(2 0): 2 write 5 -> A2
write 2 -> V1 read M2: (1 2)
read A: (2 5)
calculate (1 2).(2 5):12
write 12 -> V2
问题就是V直到所有元素计算出来时才会计算出来。但是,P1在A的所有元素计算出来之前,完成A = B+C并且移到V = MA。所以它与M相乘时使用了A的不一致的值。
我们可以使用条件变量来解决这个问题。
条件变量 是表现为信号的对象,信号表示某个条件被满足。它们通常被用于协调进程,这些进程需要在继续执行之前等待一些事情的发生。需要满足一定条件的进程可以等待一个条件变量,直到其它进程修改了条件变量来告诉它们继续执行。
Python 中,任何数量的进程都可以使用condition.wait()方法,用信号告知它们正在等待某个条件。在调用该方法之后,它们会自动等待到其它进程调用了condition.notify()或condition.notifyAll()函数。notify()方法值唤醒一个进程,其它进程仍旧等待。notifyAll()方法唤醒所有等待中的进程。每个方法在不同情形中都很实用。
由于条件变量通常和决定条件是否为真的共享变量相联系,它们也提供了acquire()和release()方法。这些方法应该在修改可能改变条件状态的变量时使用。任何想要用信号告知条件已经改变的进程,必须首先使用acquire()来访问它。
在我们的例子中,在执行第二步之前必须满足的条件是,两个进程都必须完成了第一步。我们可以跟踪已经完成第一步的进程数量,以及条件是否被满足,通过引入下面两个变量:
step1_finished = 0
start_step2 = Condition()
我们在do_step_2的开头插入start_step_2().wait()。每个进程都会在完成步骤 1 之后自增step1_finished,但是我们只会在step_1_finished = 2时发送信号。下面的伪代码展示了它:
step1_finished = 0
start_step2 = Condition()
def do_step_1(index):
A[index] = B[index] + C[index]
# access the shared state that determines the condition status
start_step2.acquire()
step1_finished += 1
if(step1_finished == 2): # if the condition is met
start_step2.notifyAll() # send the signal
#release access to shared state
start_step2.release()
def do_step_2(index):
# wait for the condition
start_step2.wait()
V[index] = M[index] . A
在引入条件变量之后,两个进程会一起进入步骤 2,像下面这样:
P1 P2
read B1: 2
read C1: 0
calculate 2+0: 2
write 2 -> A1 read B2: 0
acquire start_step2: ok read C2: 5
write 1 -> step1_finished calculate 5+0: 5
step1_finished == 2: false write 5-> A2
release start_step2: ok acquire start_step2: ok
start_step2: wait write 2-> step1_finished
wait step1_finished == 2: true
wait notifyAll start_step_2: ok
start_step2: ok start_step2:ok
read M1: (1 2) read M2: (1 2)
read A:(2 5)
calculate (1 2). (2 5): 12 read A:(2 5)
write 12->V1 calculate (1 2). (2 5): 12
write 12->V2
在进入do_step_2的时候,P1需要在start_step_2之前等待,直到P2自增了step1_finished,发现了它等于 2,之后向条件发送信号。
4.3.5 死锁
虽然同步方法对保护共享状态十分有效,但它们也带来了麻烦。因为它们会导致一个进程等待另一个进程,这些进程就有死锁 的风险。死锁是一种情形,其中两个或多个进程被卡住,互相等待对方完成。我们已经提到了忘记释放某个锁如何导致进程无限卡住。但是即使acquire()和release()调用的数量正确,程序仍然会构成死锁。
死锁的来源是循环等待 ,像下面展示的这样。没有进程能够继续执行,因为它们正在等待其它进程,而其它进程也在等待它完成。
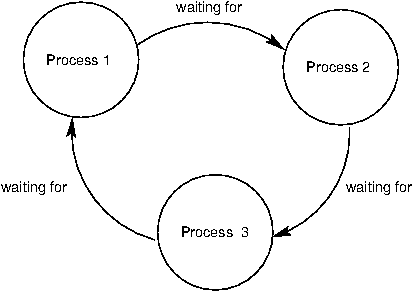
作为一个例子,我们会建立两个进程的死锁。假设有两把锁,x_lock和y_lock,并且它们像这样使用:
>>> x_lock = Lock()
>>> y_lock = Lock()
>>> x = 1
>>> y = 0
>>> def compute():
x_lock.acquire()
y_lock.acquire()
y = x + y
x = x * x
y_lock.release()
x_lock.release()
>>> def anti_compute():
y_lock.acquire()
x_lock.acquire()
y = y - x
x = sqrt(x)
x_lock.release()
y_lock.release()
如果compute()和anti_compute()并行执行,并且恰好像下面这样互相交错:
P1 P2
acquire x_lock: ok acquire y_lock: ok
acquire y_lock: wait acquire x_lock: wait
wait wait
wait wait
wait wait
... ...
所产生的情形就是死锁。P1和P2每个都持有一把锁,但是它们需要两把锁来执行。P1正在等待P2释放y_lock,而P2正在等待P1释放x_lock。所以,没有进程能够继续执行。