函数#
Functions
以下是一些技术细节相对较低的杂项函数和属性。
一些函数提供对 PDF 结构的详细访问。其他函数是其他函数的精简版高性能版本, 可提供更多信息。
还有一些是方便的通用实用程序。
函数 |
简要描述 |
|---|---|
|
仅限 PDF:外观对象的 bbox |
|
仅限 PDF:外观对象的矩阵 |
检查内容是否存在换行 |
|
Adobe 字形列表中定义的字形名称列表 |
|
Adobe 字形列表中定义的 Unicode 列表 |
|
仅限 PDF:清理批注的 |
|
|
仅限 PDF:设置外观对象的 bbox |
|
仅限 PDF:设置外观对象的矩阵 |
返回 get_text 方法的头部字符串 |
|
返回 get_text 方法的尾部字符串 |
|
仅限 PDF:删除 XML 元数据 |
|
仅限 PDF:返回字体的字形宽度列表 |
|
仅限 PDF:创建并返回新的 |
|
仅限 PDF:检查 |
|
仅限 PDF:返回 XML 元数据的 |
|
仅限 PDF:返回 |
|
返回(标准的)空 / 无效矩形 |
|
返回(标准的)空 / 无效四边形 |
|
返回(标准的)空 / 无效矩形 |
|
以 PDF 格式返回当前时间戳 |
|
返回 PDF 兼容字符串 |
|
返回给定字体和 |
|
从字形名称返回 Unicode |
|
返回包含基本图像属性的字典 |
|
返回(唯一存在的)无限矩形 |
|
返回(唯一存在的)无限四边形 |
|
返回(唯一存在的)无限矩形 |
|
将矩形拆分为子矩形 |
|
仅限 PDF:清理页面的 |
|
获取包围文本、绘图或图像对象的矩形列表 |
|
仅限 PDF:返回内容的 |
|
创建页面的显示列表 |
|
以 Python 列表的形式提取文本块 |
|
以 Python 列表的形式提取文本单词 |
|
提供底层文本信息 |
|
仅限 PDF:获取完整的、拼接后的 /Contents 源数据 |
|
通过设备运行页面 |
|
使用堆叠命令包裹内容 |
|
为 pymupdf_fonts 包中的字体创建 CSS 源代码 |
|
返回已知纸张格式的矩形 |
|
返回已知纸张格式的宽度和高度 |
|
预定义纸张格式的字典 |
|
计算映射到 x 轴的矩阵 |
|
计算字符的四边形 (“rawdict”) |
|
计算行跨度子集的四边形 |
|
计算跨度的四边形 (“dict”, “rawdict”) |
|
计算跨度字符子集的四边形 |
|
设置 PyMuPDF 消息的输出位置 |
|
从 sRGB 整数返回 PDF RGB 颜色元组 |
|
从 sRGB 整数返回 (R, G, B) 颜色元组 |
|
从 Unicode 返回字形名称 |
|
定位 Tesseract-OCR 安装的语言支持数据 |
|
返回颜色名称字典. |
|
返回颜色名称字典. |
|
可用的补充字体字典 |
|
PyMuPDF 消息的输出位置 |
|
近 500 种 PDF 格式的 RGB 颜色字典 |
- paper_size(s)#
便捷函数, 用于返回已知纸张格式代码的宽度和高度。这些值以像素为单位, 基于标准分辨率 72 像素 = 1 英寸。
目前定义的格式包括 ‘A0’ 到 ‘A10’, ‘B0’ 到 ‘B10’, ‘C0’ 到 ‘C10’, ‘Card-4x6’, ‘Card-5x7’, ‘Commercial’, ‘Executive’, ‘Invoice’, ‘Ledger’, ‘Legal’, ‘Legal-13’, ‘Letter’, ‘Monarch’ 和 ‘Tabloid-Extra’, 每种格式均可选择纵向(portrait)或横向(landscape)。
需要以字符串形式提供格式名称(不区分大小写), 并可选择性地添加后缀 “-L”(横向)或 “-P”(纵向)。如果没有后缀, 默认采用纵向。
- 参数:
s (str) – 以上任意格式名称, 可使用大写或小写, 例如 “A4” 或 “letter-l”。
- 返回类型:
tuple
- 返回:
纸张格式的 (宽度, 高度)。如果格式未知, 则返回 (-1, -1)。示例:pymupdf.paper_size(“A4”) 返回 (595, 842), pymupdf.paper_size(“letter-l”) 返回 (792, 612)。
- paper_rect(s)#
便捷函数, 用于返回已知纸张格式的 Rect。
- 参数:
s (str) – 任何受
paper_size()支持的格式名称。- 返回类型:
- 返回:
pymupdf.Rect(0, 0, width, height), 其中 width, height=pymupdf.paper_size(s)。
>>> import pymupdf >>> pymupdf.paper_rect("letter-l") pymupdf.Rect(0.0, 0.0, 792.0, 612.0) >>>
- set_messages(*, text=None, fd=None, stream=None, path=None, path_append=None, pylogging=None, pylogging_logger=None, pylogging_level=None, pylogging_name=None)#
设置 PyMuPDF 消息的输出位置, 可以是文件描述符、文件、已有的流或 Python 的日志系统。
通常情况下, 只需设置一个参数, 或者一个或多个
pylogging*参数。- 参数:
text (str) – 目标位置的文本描述;详细信息请参阅环境变量
PYMUPDF_MESSAGE的说明。fd (int) – 写入文件描述符。
stream – 写入已有的流, 该流必须具有
.write(text)和.flush()方法。path (str) – 写入文件。
path_append (str) – 追加写入文件。
pylogging – 写入 Python 的
logging系统。pylogging_logger (logging.Logger) – 使用指定的 Logger 写入 Python 的
logging系统。pylogging_level (int) – 使用指定的日志级别写入 Python 的
logging系统。pylogging_name (str) – 使用指定的日志记录器名称写入 Python 的
logging系统。 仅在pylogging_logger为 None 时使用, 默认值为pymupdf。
如果任何
pylogging*参数不为 None, 则消息将写入 Python 的日志系统。
- sRGB_to_pdf(srgb)#
自 v1.17.4 版本起新增
便捷函数, 将给定的 sRGB 颜色整数转换为 PDF 颜色三元组(red, green, blue)。该格式用于
Page.get_text()返回的 “dict” 和 “rawdict” 结构中。- 参数:
srgb (int) – 形如 RRGGBB 的整数, 每个颜色分量的取值范围为 0-255。
- 返回:
颜色三元组 (red, green, blue), 其中每个值都是 0 <= item <= 1 之间的浮点数, 表示相同颜色。例如
sRGB_to_pdf(0xff0000) = (1, 0, 0)(红色)。
- sRGB_to_rgb(srgb)#
New in v1.17.4
Convenience function returning a color (red, green, blue) for a given sRGB color integer.
- 参数:
srgb (int) – an integer of format RRGGBB, where each color component is an integer in range(255).
- 返回:
a tuple (red, green, blue) with integer items in
range(256)representing the same color. ExamplesRGB_to_pdf(0xff0000) = (255, 0, 0)(red).
- glyph_name_to_unicode(name)#
自 v1.18.0 版本起新增
根据 Adobe Glyph List 返回字形名称对应的 Unicode 编码。
- 参数:
name (str) – 字形名称。本函数基于 Adobe Glyph List。
- 返回类型:
int
- 返回:
对应的 Unicode 编码。如果 name 无效,则返回
0xfffd (65533)。
备注
类似功能也由 fontTools 包的 agl 子包提供。
- unicode_to_glyph_name(ch)#
自 v1.18.0 版本起新增
根据 Adobe Glyph List 返回 Unicode 编码对应的字形名称。
- 参数:
ch (int) –
Unicode 编码,例如
ord("ß")。本函数基于 Adobe Glyph List。- 返回类型:
str
- 返回:
对应的字形名称。例如
pymupdf.unicode_to_glyph_name(ord("Ä"))返回'Adieresis'。
备注
类似功能也由 fontTools 包的 agl 子包提供。
- adobe_glyph_names()#
自 v1.18.0 版本起新增
返回 Adobe Glyph List 中定义的字形名称列表。
- 返回类型:
list
- 返回:
字符串列表。
备注
类似功能也由 fontTools 包的 agl 子包提供。
- adobe_glyph_unicodes()#
自 v1.18.0 版本起新增
返回 Adobe Glyph List 中存在字形名称的 Unicode 编码列表。
- 返回类型:
list
- 返回:
整数列表。
备注
类似功能也由 fontTools 包的 agl 子包提供。
- css_for_pymupdf_font(fontcode, *, CSS=None, archive=None, name=None)#
自 v1.21.0 版本起新增
用于 “Story” 应用的实用函数。
为
pymupdf-fonts中的指定字体代码生成 CSS@font-face规则,并创建一个包含所有匹配字体的font-family定义。在
pymupdf-fonts包中,字体的命名规则为"fontcode<sf>",其中后缀"sf"可以是""(空,表示常规体)、"it"/"i"(斜体)、"bo"/"b"(加粗)或"bi"(加粗斜体)。这些后缀代表该字体系列的不同变体。例如,字体代码
"notos"代表以下字体:"notos"- “Noto Sans Regular”"notosit"- “Noto Sans Italic”"notosbo"- “Noto Sans Bold”"notosbi"- “Noto Sans Bold Italic”
该函数会生成最多四个
@font-face规则,并将它们统一分配给font-family名称"notos"(或者使用name参数指定的名称)。相关字体数据将存储或添加到提供的 Archive 归档对象中。在 Story 的 Python API 中,可以执行
.set_font(fontcode)(或提供的name),以确保根据需要自动选择正确的字重或样式。例如,要用
"notos"字体替换 HTML 标准的"sans-serif"(即 Helvetica),可以执行以下代码。这样,每当使用"sans-serif"(无论是显式还是隐式)时,都会选择 Noto Sans 字体:CSS = pymupdf.css_for_pymupdf_font("notos", name="sans-serif", archive=...)该函数接受并返回 CSS 源码,会在提供的 CSS 源码末尾追加新的
@font-face规则。- 参数:
fontcode (str) – pymupdf-fonts 包中的字体代码,通常代表该字体系列的常规体。
CSS (str) – 现有的 CSS 源码,或
None。函数会将新的@font-face规则追加到此字符串中。 此字符串必须作为user_css传递给 Story。archive – Archive, 必填 。所有找到的字体二进制数据(最多四个变体)将被添加到此归档对象。 此对象必须作为 Archive 传递给 Story。
name (str) – 字体的
font-family名称。如果未提供,则默认使用fontcode。
- 返回类型:
str
- 返回:
修改后的 CSS 代码,其中包含
fontcode对应的@font-face规则。同时,相关字体数据会被添加到 Archive 中。该函数会自动查找最多四种字体变体。pymupdf-fonts中的所有常规字体(非数学或音乐特殊用途字体)均有常规、加粗、斜体和加粗斜体四个变体。可以执行pymupdf.fitz_fontdescriptors.keys()以查看当前可用的字体代码,例如:- dict_keys([‘cascadia’, ‘cascadiai’, ‘cascadiab’, ‘cascadiabi’, ‘figbo’, ‘figo’, ‘figbi’, ‘figit’,
’fimbo’, ‘fimo’, ‘spacembo’, ‘spacembi’, ‘spacemit’, ‘spacemo’, ‘math’, ‘music’, ‘symbol1’, ‘symbol2’, ‘notosbo’, ‘notosbi’, ‘notosit’, ‘notos’, ‘ubuntu’, ‘ubuntubo’, ‘ubuntubi’, ‘ubuntuit’, ‘ubuntm’, ‘ubuntmbo’, ‘ubuntmbi’, ‘ubuntmit’])
以下是完整示例,使用
"Noto Sans"代替"Helvetica":arch = pymupdf.Archive() CSS = pymupdf.css_for_pymupdf_font("notos", name="sans-serif", archive=arch) story = pymupdf.Story(user_css=CSS, archive=arch)
- make_table(rect, cols=1, rows=1)#
自 v1.17.4 版本起新增
该方法用于将一个矩形区域均匀划分为多个子矩形,并返回一个列表,其中每个子列表代表一行,包含
cols个 Rect 对象。每个子矩形可以通过其行索引和列索引进行访问。- 参数:
rect (rect_like) – 需要拆分的矩形区域。
cols (int) – 需要划分的列数。
rows (int) – 需要划分的行数。
- 返回:
一个包含 Rect 对象的列表,这些矩形大小相等,并且它们的并集等于 Rect。以下是使用
cell = pymupdf.make_table(rect, cols=4, rows=3)创建的 3x4 表格的示例布局:

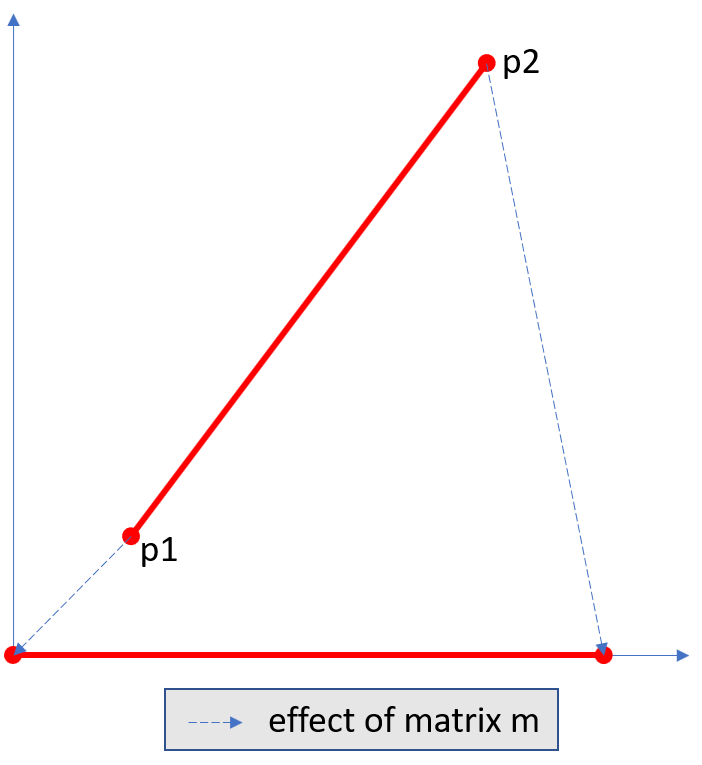
- planish_line(p1, p2)#
自 v1.16.2 版本起新增
计算一个矩阵,该矩阵可将从
p1到p2的直线映射到 x 轴,使得p1变为 (0,0),而p2变为一个与 (0,0) 具有相同距离的点。- 参数:
p1 (point_like) – 线段的起点。
p2 (point_like) – 线段的终点。
- 返回类型:
- 返回:
结合旋转和平移的变换矩阵。例如:
>>> p1 = pymupdf.Point(1, 1) >>> p2 = pymupdf.Point(4, 5) >>> abs(p2 - p1) # 计算点之间的距离 5.0 >>> m = pymupdf.planish_line(p1, p2) >>> p1 * m Point(0.0, 0.0) >>> p2 * m Point(5.0, -5.960464477539063e-08) >>> # 计算变换后的点之间的距离 >>> abs(p2 * m - p1 * m) 5.0
- paper_sizes()#
一个包含预定义纸张格式的字典,作为
paper_size()的基础数据。
- fitz_fontdescriptors#
自 v1.17.5 版本起新增
一个字典,包含 pymupdf-fonts 仓库中的可用字体。键是字体的预留名称,字典的值提供如下信息:
In [2]: pymupdf.fitz_fontdescriptors.keys() Out[2]: dict_keys(['figbo', 'figo', 'figbi', 'figit', 'fimbo', 'fimo', 'spacembo', 'spacembi', 'spacemit', 'spacemo', 'math', 'music', 'symbol1', 'symbol2']) In [3]: pymupdf.fitz_fontdescriptors["fimo"] Out[3]: {'name': 'Fira Mono Regular', 'size': 125712, 'mono': True, 'bold': False, 'italic': False, 'serif': True, 'glyphs': 1485}
如果
pymupdf-fonts未安装,该字典将为空。这些字典键可用于定义 Font,例如:
font = pymupdf.Font("fimo")
这种方式与内置字体(如
"Helvetica")的使用方式相同。
- PYMUPDF_MESSAGE#
如果在 PyMuPDF 导入时
os.environ中包含该变量,则该变量用于设置 PyMuPDF 消息的目标位置。否则,消息将发送到sys.stdout。若值以
fd:开头,则剩余部分应为一个整数文件描述符,消息将被写入该描述符。例如,
PYMUPDF_MESSAGE=fd:2将消息发送到stderr。
若值以
path:开头,则剩余部分应为一个文件路径,消息将被写入该文件。如果文件已存在,则会被清空。若值以
path+:开头,则剩余部分应为一个文件路径,消息将被追加写入该文件(若已存在)。若值以
logging:开头,则消息将被写入 Python 日志系统。剩余部分可以包含逗号分隔的name=value项:level=设置日志级别。name=设置日志器名称(默认为pymupdf)。
其他项将被忽略。
其他前缀将导致错误。
另见
set_messages()。
- pdfcolor#
自 v1.19.6 版本起新增
包含约 500 种 PDF 颜色格式的 RGB 颜色,颜色名称作为键。可以使用
pymupdf.pdfcolor.keys()查看所有可用颜色。示例:
pymupdf.pdfcolor["red"] = (1.0, 0.0, 0.0)pymupdf.pdfcolor["skyblue"] = (0.5294117647058824, 0.807843137254902, 0.9215686274509803)pymupdf.pdfcolor["wheat"] = (0.9607843137254902, 0.8705882352941177, 0.7019607843137254)
- get_pdf_now()#
该方法用于返回当前本地时间戳,并以 PDF 兼容格式表示,例如 D:20170501121525-04’00’ 对应于 2017 年 5 月 1 日 12:15:25(本地时区比 UTC 偏西 4 小时)。
- 返回类型:
str
- 返回:
当前本地 PDF 时间戳。
- get_text_length(text, fontname='helv', fontsize=11, encoding=TEXT_ENCODING_LATIN)#
自 v1.14.7 版本起新增
计算给定 内置 字体、
fontsize和编码情况下,文本的输出长度。- 参数:
text (str) – 需要计算长度的文本字符串。
fontname (str) – 字体名称,必须是 PDF Base 14 字体 或 CJK 字体之一,可通过其“预留”字体名称标识(参见
Page.insert_font())。fontsize (float) –
fontsize,即字体大小。encoding (int) – 要使用的编码。除了 0 = Latin,还支持 1 = Greek 和 2 = Cyrillic(俄语)。仅适用于 Base-14 字体(如 “Helvetica”、”Courier” 和 “Times” 及其变体)。请确保使用与插入文本时相同的编码值。
- 返回类型:
float
- 返回:
计算出的文本长度(单位:点),例如用于
Page.insert_text()。
备注
该函数仅计算长度,不会插入字体或文本。
备注
Font 类提供了类似的方法
Font.text_length(),支持 Base-14 字体以及任何具有字符映射(CMap,Type 0 字体)的字体。警告
若使用该方法来计算 (Page 或 Shape)
insert_textbox方法所需的矩形宽度,需注意它们是按 字符级 计算的。由于四舍五入的影响,以下计算通常会产生稍大的数值:sum([pymupdf.get_text_length(c) for c in text]) > pymupdf.get_text_length(text)
解决方案: (1) 采用相同的逐字符计算方式;或 (2) 使用
pymupdf.get_text_length(text + "'")进行计算,以确保宽度足够。
- get_pdf_str(text)#
生成 PDF 兼容的字符串:如果文本包含 Unicode 代码点 ord(c) > 255,则转换为 UTF-16BE 编码,并作为十六进制字符字符串用 “<>” 括起来,如 <feff…>。否则,返回字符串,并用圆括号 () 括起来,同时将 ASCII 范围外的字符替换为特殊代码。此外,所有
"("、")"和反斜杠""都会被转义为"\"。- 参数:
text (str) – 需要转换的对象。
- 返回类型:
str
- 返回:
以 () 或 <> 括起的 PDF 兼容字符串。
- image_profile(stream)#
自 v1.16.7 版本起新增
v1.19.5 版本变更:如果 EXIF 数据中存在自然图像方向信息,则返回该信息。
v1.22.5 版本变更:错误情况下始终返回
None,而不是空字典。
获取提供的图像的关键属性,避免使用其他 Python 库来确定这些信息。
- 参数:
stream (bytes|bytearray|BytesIO|file) – 传入的图像可以是内存中的数据或 已打开的 文件。内存中的图像可以是
bytes、bytearray或io.BytesIO格式。- 返回类型:
dict
- 返回:
方法不会引发异常,若出错,则返回
None。否则,返回包含以下内容的字典:In [2]: pymupdf.image_profile(open("nur-ruhig.jpg", "rb").read()) Out[2]: {'width': 439, 'height': 501, 'orientation': 0, # 自然方向(来自 EXIF) 'transform': (1.0, 0.0, 0.0, 1.0, 0.0, 0.0), # 方向变换矩阵 'xres': 96, 'yres': 96, 'colorspace': 3, 'bpc': 8, 'ext': 'jpeg', 'cs-name': 'DeviceRGB'}
其中,
orientation及相应的transform变换矩阵与 Exif 信息的对应关系如下(引自 MuPDF 文档, ccw 表示逆时针旋转):未定义
0° 逆时针旋转(Exif = 1)
90° 逆时针旋转(Exif = 8)
180° 逆时针旋转(Exif = 3)
270° 逆时针旋转(Exif = 6)
X 轴翻转(Exif = 2)
X 轴翻转后再 90° 逆时针旋转(Exif = 5)
X 轴翻转后再 180° 逆时针旋转(Exif = 4)
X 轴翻转后再 270° 逆时针旋转(Exif = 7)
备注
对于某些“特殊”图像(如 FAX 编码、RAW 格式等),该方法可能无法使用。但仍可在 PyMuPDF 中处理这些图像,例如使用
Document.extract_image()方法或通过Pixmap(doc, xref)创建像素图。这些方法会自动将特殊图像转换为 PNG 格式后返回结果。可通过
xref获取嵌入在 PDF 文档中的图像属性。在这种情况下,请确保提取原始数据流:pymupdf.image_profile(doc.xref_stream_raw(xref))。通过
Page.get_text()使用"dict"或"rawdict"选项返回的图像数据块也受支持。
- ConversionHeader("text", filename="UNKNOWN")#
返回用于构造有效文档的页文本输出所需的头部字符串。
- 参数:
output (str) – 文档类型。应与 get_text() 方法的输出参数一致。
filename (str) – (可选)在 “json” 和 “xml” 输出类型下使用的任意文件名。
- 返回类型:
str
- ConversionTrailer(output)#
返回用于构造有效文档的页文本输出所需的尾部字符串。示例请参见
Page.get_text()。- 参数:
output (str) – 文档类型。应与 get_text() 方法的输出参数一致。
- 返回类型:
str
- Document.del_xml_metadata()#
删除 PDF 中包含 XML 元数据的对象。(Py-) MuPDF 不支持 XML 格式的元数据。如果希望仅使用传统的元数据字典,请使用此方法。许多第三方 PDF 程序会插入 XML 格式的元数据,这可能会覆盖传统字典中的存储内容。本方法会删除该 XML 参考,并在下次文件垃圾回收时移除相应的 PDF 对象。
- Document.xml_metadata_xref()#
返回 PDF 文件级 XML 元数据的
xref(如果存在)。参考Document.del_xml_metadata()。可以使用Document.xref_stream()获取其内容,并使用 XML 处理工具进行操作。- 返回类型:
int
- 返回:
PDF 文件级 XML 元数据的
xref,若无则返回 0。
- Page.run(dev, transform)#
通过设备处理页面。
- Page.get_bboxlog(layers=False)#
自 v1.19.0 版本起新增
v1.22.0 版本变更:可选地返回适用于边界框的 OCG(可选内容组)名称。
- 返回:
一个矩形列表,表示文本、图像或绘图对象的包围盒。列表中的每个项为一个元组
(type, (x0, y0, x1, y1)),其中第二个元组为矩形坐标,type取以下值之一。如果layers=True,则元组中会包含第三项,即 OCG 名称或None:(type, (x0, y0, x1, y1), None)。"fill-text"—— 普通文本(绘制时不带字符边框)"stroke-text"—— 仅显示字符边框的文本"ignore-text"—— 不应显示的文本(如 OCR 文本层)"fill-path"—— 仅填充颜色的绘图(无边框)"stroke-path"—— 仅绘制边框的绘图(无填充色)"fill-image"—— 显示图像"fill-shade"—— 显示渐变填充
元素的顺序表示 页面渲染这些命令的顺序。因此,如果某个元素的包围盒与前一个元素相交或包含前一个元素,则前一个元素可能会被部分或完全覆盖。
该列表可用于检测此类情况。元素在此列表中的索引等于
Page.get_drawings()和Page.get_texttrace()返回的字典中的"seqno"值。
- Page.get_texttrace()#
自 v1.18.16 版本起新增
v1.19.0 版本变更:新增键
"seqno"。v1.19.1 版本变更:描边和填充颜色现在始终为 RGB 或 GRAY。
v1.19.3 版本变更:当
dir != (1, 0)时,跨度和字符的 bbox 也能正确计算。v1.22.0 版本变更:新增字典键
"layer"。
返回页面的底层文本信息。本方法适用于 所有 文档类型。结果是一个包含以下内容的 Python 字典列表:
{ 'ascender': 0.83251953125, # 字体上升部 (1) 'bbox': (458.14019775390625, # 跨度 bbox x0 (7) 749.4671630859375, # 跨度 bbox y0 467.76458740234375, # 跨度 bbox x1 757.5071411132812), # 跨度 bbox y1 'bidi': 0, # 双向级别 (1) 'chars': ( # 字符信息,tuple[tuple] (45, # Unicode 编码 (4) 16, # 字形 ID(字体相关) (458.14019775390625, # 原点 x 坐标 (1) 755.3758544921875), # 原点 y 坐标 (1) (458.14019775390625, # 字符 bbox x0 (6) 749.4671630859375, # 字符 bbox y0 462.9649963378906, # 字符 bbox x1 757.5071411132812)), # 字符 bbox y1 ( ... ), # 更多字符 ), 'color': (0.0,), # 文本颜色,tuple[float] (1) 'colorspace': 1, # 颜色空间分量数 (1) 'descender': -0.30029296875, # 字体下降部 (1) 'dir': (1.0, 0.0), # 书写方向 (1) 'flags': 12, # 字体标志 (1) 'font': 'CourierNewPSMT', # 字体名称 (1) 'linewidth': 0.4019999980926514, # 当前线宽值 (3) 'opacity': 1.0, # 文本透明度 (5) 'layer': None, # 可选内容组(OCG)名称 (9) 'seqno': 246, # 序列号 (8) 'size': 8.039999961853027, # 字体大小 (1) 'spacewidth': 4.824785133358091, # 空格字符宽度 'type': 0, # 跨度类型 (2) 'wmode': 0 # 书写模式 (1) }
详细信息:
标记为 “(1)” 的信息与 TextPage 解释的含义和数值相同。
请注意,字体
"flags"值不会包含 上标 标志位:上标检测是在 MuPDF TextPage 代码中执行的,而不是字体的固有属性。还要注意,文本 颜色 以
0 <= f <= 1的浮点数元组编码,而不是 sRGB 格式。根据span["type"],解释为填充颜色或描边颜色。
文本跨度类型共有 3 种:
0:填充文本 —— 等同于 PDF 渲染模式 0 (
0 Tr,PDF 默认),仅显示字符内部。1:描边文本 —— 等同于
1 Tr,仅显示字符边框。3:隐藏文本 —— 等同于
3 Tr(隐藏文本)。
线宽对
span["type"] != 0情况较为重要:它决定了字符边框线的厚度。如果文本数据未提供此值,则会生成5%字体大小的默认值 (span["size"] * 0.05)。PDF 中常用2 Tr方式创建 伪加粗 文本,此情况下没有对应的跨度类型,而是生成两个连续跨度,分别对应0和1,需要自行处理。字符 Unicode 提供
chr()以获取字符本身。透明度 (
0 <= opacity <= 1) 影响文本是否可见,0 表示完全透明,1 表示完全不透明。根据span["type"],可解释为填充或描边透明度。(v1.19.0 变更)
bbox值等同或接近"rawdict"中的char["bbox"],高度计算始终假设启用了 小字形高度。(v1.19.0 新增)
seqno枚举页面外观的渲染顺序。较大序列号的对象可能会遮挡较小序列号的文本。(v1.22.0 新增)
"layer"为可选内容组 (OCG) 名称,或None。
与
page.get_text("rawdict")的比较:本方法 提取速度提高约 2 倍 (视文本量而定)。
结果数据 更小,但提供更多信息。
可 检测文本不可见性 (透明度为 0,类型 > 1,或被更高序列号对象遮挡)。
MuPDF 若返回
0xFFFD (65533)作为未识别字符,可根据字形 ID 推测信息。span["chars"]不包含空格,除非文档创建者显式编码;但提供空格宽度,以便计算文本间距。文本不会像 TextPage 组织为块、行、跨度、字符,而是按顺序提取,遇到样式变化即开始新跨度。同一跨度可能包含不同
origin.y值的字符(即处于不同行)。不保证跨度字符排序,需要自行处理,如使用span["dir"]、span["wmode"]等。
连字(Ligature)处理: - MuPDF 处理
"fi","ff","fl","ft","st","ffi","ffl"这些连字(常见前三种)。 - 例如:”fi” 可能存储为两个字符:(102, glyph, (x, y), (x0, y0, x1, y1)) # 'f' 的 bbox (105, -1, (x, y), (x0, y0, x0, y1)) # 'i',bbox 宽度为 0
可替换为单个 Unicode 代码:
"ff"->0xFB00"fi"->0xFB01"fl"->0xFB02"ffi"->0xFB03"ffl"->0xFB04"ft"->0xFB05"st"->0xFB06
例如,将上述示例转换为
(0xFB01, glyph, (x, y), (x0, y0, x1, y1))。
(v1.19.3 变更) 跨度和字符
bbox现在包围字符四边形,可用recover_quad()、recover_char_quad()、recover_span_quad()还原。(v1.21.1 变更)
"layer"字段提供 OCG 名称(如适用)。
- Page.wrap_contents()#
确保页面的所谓图形状态是平衡的,并且新内容能够正确插入。
在 PyMuPDF v1.24.1+ 版本中,此方法得到了改进,并在需要时自动执行,因此您无需再关心此方法。
我们不建议使用
Page.clean_contents()来实现此功能。
- Page.is_wrapped#
指示页面的所谓图形状态是否平衡。如果为
False,则在插入新内容时应执行Page.wrap_contents()(仅在overlay=True模式下相关)。在较新的版本中(1.24.1+),此检查和相应的调整会自动执行,因此您无需再担心此问题。- 返回类型:
bool
- Page.get_text_blocks(flags=None)#
已废弃的
TextPage.extractBLOCKS()的包装器。请改用Page.get_text()并使用"blocks"选项。- 返回类型:
list[tuple]
- Page.get_text_words(flags=None, delimiters=None)#
已废弃的
TextPage.extractWORDS()的包装器。请改用Page.get_text()并使用"words"选项。- 返回类型:
list[tuple]
- Page.get_displaylist()#
将页面传递给列表设备并返回其显示列表。
- 返回类型:
- 返回:
页面的显示列表。
- Page.get_contents()#
仅适用于 PDF:检索页面的
xref列表,表示页面的contents对象。可能为空,或包含多个整数。如果页面已清理(使用Page.clean_contents()),则该列表最多包含一个条目。每个/Contents对象的 “源” 可以通过Document.xref_stream()使用此列表中的项单独读取。与此相对,方法Page.read_contents()会遍历此列表并将相应的源连接成一个bytes对象。- 返回类型:
list[int]
- Page.set_contents(xref)#
仅适用于 PDF: 让页面的
/Contents键指向此 xref。任何先前使用的内容对象将被忽略,并且可以通过垃圾回收删除。
- Page.clean_contents(sanitize=True)#
在 v1.17.6 中更改
仅适用于 PDF:清理并连接与此页面相关的所有
contents对象。”清理” 包括语法修正、标准化和 “美化” 内容流。如果 sanitize 为 true,内容对象中的资源与实际使用的资源之间的差异也将被修正。有关更多详细信息,请参阅Page.get_contents()。在 v1.16.0 版本中,注释不再由此方法隐式清理。请单独使用
Annot.clean_contents()。- 参数:
sanitize (bool) – (在 v1.17.6 中新增) 如果为真,则会同步资源与其在内容对象中的实际使用。例如,如果某个字体没有实际用于页面中的任何文本,则会从
/Resources/Font对象中删除该字体。
警告
这是一个复杂的功能,可能会生成大量的新数据,并使旧数据变得无效。 不推荐 与 增量保存 选项一起使用。还请注意,生成的单例新 /Contents 对象是 未压缩 的。因此,您应该使用选项 “deflate=True, garbage=3” 将其保存到 新文件 中。
不再使用此方法来确保 PDF 页面上正确的插入。自 PyMuPDF v1.24.2 版本起,这一功能已自动处理。
- Page.read_contents()#
在 v1.17.0 中新增。 返回与页面关联的所有
contents对象的连接体 – 不进行清理或其他修改。每当您需要解析整个源而不关心有多少个独立的内容对象时,请使用此方法。- 返回类型:
bytes
- Annot.clean_contents(sanitize=True)#
清理与注释相关的
contents流。这与Page.clean_contents()执行的操作相同,只是此操作仅限于该注释。
- Document.get_char_widths(xref=0, limit=256)#
返回文档中某字体的字符字形及其宽度的列表。必须通过其 PDF 交叉引用号
xref来指定字体。此函数会在Page.insert_text()和Page.insert_textbox()中自动调用,因此您通常无需手动调用。- 参数:
xref (int) – 嵌入 PDF 中的字体的交叉引用号。要查找字体的
xref,可以使用例如 doc.get_page_fonts(pno) 获取页面号 pno 的字体,并取返回列表中的第一个条目。limit (int) – 限制返回的条目数。默认值为 256,适用于仅支持 1 字节字符的字体,所谓的 “简单字体”(通过此方法检查)。所有 PDF Base 14 字体 都是简单字体。
- 返回类型:
list
- 返回:
一个 limit 元组的列表。每个字符 c 在该列表中有一个条目 (g, w),其中 g 是字符的字形 ID(整数), w 是其标准化宽度。对于某些
fontsize,实际宽度可以计算为 w * fontsize。对于简单字体,g 条目可以安全地忽略。在所有其他情况下,g 是图形表示 c 的基础。
该函数计算一个字符串 text 的像素宽度,如下所示:
def pixlen(text, widthlist, fontsize): try: return sum([widthlist[ord(c)] for c in text]) * fontsize except IndexError: raise ValueError:("max. code point found: %i, increase limit" % ord(max(text)))
- Document.is_stream(xref)#
在 v1.14.14 中新增
仅适用于 PDF:检查由
xref表示的对象是否为stream类型。如果不是 PDF 或者该数字超出了有效的 xref 范围,则返回 False。- 参数:
xref (int) –
xref号。- 返回:
如果对象定义后跟有以 stream 和 endstream 关键字对包裹的数据,则返回 True。
- Document.get_new_xref()#
将
xref号增加一个条目并返回该号码。然后可以使用该号码插入一个新的对象。- 返回类型:
int
- 返回:
新的
xref条目的号码。请注意,这仅在 PDF 的交叉引用表中创建一个新条目。此时,还不会与之关联任何 PDF 对象。要使用此号码创建(空的)对象,请使用doc.update_xref(xref, "<<>>")。
- recover_quad(line_dir, span)#
计算通过
Page.get_text()的 “dict” 或 “rawdict” 选项提取的文本跨度的四边形。- 参数:
line_dir (tuple) – 所属行的
line["dir"]。对于从Page.get_texttrace()提取的跨度,请使用None。span (dict) – 跨度。
- 返回:
跨度的 Quad,可用于文本标记注释(例如“高亮”)。
- recover_char_quad(line_dir, span, char)#
计算通过
Page.get_text()的 “rawdict” 选项提取的文本字符的四边形。- 参数:
line_dir (tuple) – 所属行的
line["dir"]。对于从Page.get_texttrace()提取的跨度,请使用None。span (dict) – 跨度。
char (dict) – 字符。
- 返回:
字符的 Quad,可用于文本标记注释(例如“高亮”)。
- recover_span_quad(line_dir, span, chars=None)#
计算通过
Page.get_text()的 “rawdict” 选项提取的一个跨度中子集字符的四边形。- 参数:
line_dir (tuple) – 所属行的
line["dir"]。对于从Page.get_texttrace()提取的跨度,请使用None。span (dict) – 跨度。
chars (list) – 要考虑的字符。如果给定,选择的提取选项必须是 “rawdict”。
- 返回:
所选字符的 Quad,可用于文本标记注释(例如“高亮”)。
- recover_line_quad(line, spans=None)#
计算通过
Page.get_text()的 “dict” 或 “rawdict” 选项提取的文本行的子集跨度的四边形。- 参数:
line (dict) – 该行。
spans (list) –
line["spans"]的子列表。如果省略,将返回完整的行四边形。
- 返回:
所选行跨度的 Quad,可用于文本标记注释(例如“高亮”)。
- get_tessdata(tessdata=None)#
检测 Tesseract 语言支持文件夹。
此函数用于启用 Tesseract 的 OCR,即使语言支持文件夹未直接指定或未在环境变量 TESSDATA_PREFIX 中设置。
如果设置了 <tessdata>,我们将直接返回它。
否则,如果设置了
os.environ['TESSDATA_PREFIX'],则返回它。否则,我们将搜索 Tesseract 安装并返回其语言支持文件夹。
否则,我们会引发异常。
- INFINITE_QUAD()#
- INFINITE_RECT()#
- INFINITE_IRECT()#
返回 (唯一的) 无限矩形
Rect(-2147483648.0, -2147483648.0, 2147483520.0, 2147483520.0),分别是 IRect 和 Quad 对应物。它是可能的最大矩形:所有有效的矩形都包含在其中。
- EMPTY_QUAD()#
- EMPTY_RECT()#
- EMPTY_IRECT()#
返回 “标准” 空和无效矩形
Rect(2147483520.0, 2147483520.0, -2147483648.0, -2147483648.0),分别是四边形。它的左上角和右下角点的值与无限矩形相反。它将用于表示page.get_text("dict")字典中的空 bbox。然而,也有无数空的或无效的矩形。
- colors_pdf_dict()#
返回一个字典,将小写颜色名称映射到
(red, green, blue)元组,其中red、green、blue是范围在 0 到 1 之间的浮点数。
- colors_wx_list()#
返回一个列表,其中包含
(colorname, red, green, blue)元组,其中colorname为大写,red、green、blue是范围在 0 到 255 之间的整数。
The following are miscellaneous functions and attributes on a fairly low-level technical detail.
Some functions provide detail access to PDF structures. Others are stripped-down, high performance versions of other functions which provide more information.
Yet others are handy, general-purpose utilities.
Function |
Short Description |
|---|---|
|
PDF only: bbox of the appearance object |
|
PDF only: the matrix of the appearance object |
check whether contents wrapping is present |
|
list of glyph names defined in Adobe Glyph List |
|
list of unicodes defined in Adobe Glyph List |
|
PDF only: clean the annot’s |
|
|
PDF only: set the bbox of the appearance object |
|
PDF only: set the matrix of the appearance object |
return header string for get_text methods |
|
return trailer string for get_text methods |
|
PDF only: remove XML metadata |
|
PDF only: return a list of glyph widths of a font |
|
PDF only: create and return a new |
|
PDF only: check whether an |
|
PDF only: return XML metadata |
|
PDF only: return length of |
|
return the (standard) empty / invalid rectangle |
|
return the (standard) empty / invalid quad |
|
return the (standard) empty / invalid rectangle |
|
return the current timestamp in PDF format |
|
return PDF-compatible string |
|
return string length for a given font & |
|
return unicode from a glyph name |
|
return a dictionary of basic image properties |
|
return the (only existing) infinite rectangle |
|
return the (only existing) infinite quad |
|
return the (only existing) infinite rectangle |
|
split rectangle in sub-rectangles |
|
PDF only: clean the page’s |
|
list of rectangles that envelop text, drawing or image objects |
|
PDF only: return a list of content |
|
create the page’s display list |
|
extract text blocks as a Python list |
|
extract text words as a Python list |
|
low-level text information |
|
PDF only: get complete, concatenated /Contents source |
|
run a page through a device |
|
wrap contents with stacking commands |
|
create CSS source for a font in package pymupdf_fonts |
|
return rectangle for a known paper format |
|
return width, height for a known paper format |
|
dictionary of pre-defined paper formats |
|
matrix to map a line to the x-axis |
|
compute the quad of a char (“rawdict”) |
|
compute the quad of a subset of line spans |
|
compute the quad of a span (“dict”, “rawdict”) |
|
compute the quad of a subset of span characters |
|
set destination of PyMuPDF messages. |
|
return PDF RGB color tuple from an sRGB integer |
|
return (R, G, B) color tuple from an sRGB integer |
|
return glyph name from a unicode |
|
locates the language support of the Tesseract-OCR installation |
|
return dict of color names. |
|
return list of color names. |
|
dictionary of available supplement fonts |
|
destination of PyMuPDF messages. |
|
dictionary of almost 500 RGB colors in PDF format. |