文本#
Text
如何提取所有文档文本#
How to Extract all Document Text
此脚本将获取一个文档文件名,并从其所有文本中生成一个文本文件。
该文档可以是任何 受支持的类型。
该脚本作为一个命令行工具运行,期望将文档文件名作为参数提供。它将在脚本目录中生成一个名为 "filename.txt" 的文本文件。页面文本之间使用换页符分隔:
import sys, pathlib, pymupdf
fname = sys.argv[1] # 获取文档文件名
with pymupdf.open(fname) as doc: # 打开文档
text = chr(12).join([page.get_text() for page in doc])
# 以二进制文件写入,以支持非 ASCII 字符
pathlib.Path(fname + ".txt").write_bytes(text.encode())
输出将保持文档中的纯文本编码格式,不会进行美化处理。特别是对于 PDF,这可能意味着输出的文本顺序可能不是通常的阅读顺序,可能会出现意外的换行等问题。
您有多种方法可以修正这些问题 —— 请参阅 附录 2。其中包括:
以 HTML 格式提取文本,并将其存储为 HTML 文档,以便在任何浏览器中查看。
通过 Page.get_text(“blocks”) 提取文本块列表。该列表的每个项目都包含文本的位置信息,可用于建立合理的阅读顺序。
通过 Page.get_text(“words”) 提取单词列表。其项目包含单词及其位置信息,可用于确定给定矩形区域内的文本 —— 请参阅下一节。
请参阅接下来的两个部分,以获取示例和进一步的说明。
This script will take a document filename and generate a text file from all of its text.
The document can be any supported type.
The script works as a command line tool which expects the document filename supplied as a parameter. It generates one text file named “filename.txt” in the script directory. Text of pages is separated by a form feed character:
import sys, pathlib, pymupdf
fname = sys.argv[1] # get document filename
with pymupdf.open(fname) as doc: # open document
text = chr(12).join([page.get_text() for page in doc])
# write as a binary file to support non-ASCII characters
pathlib.Path(fname + ".txt").write_bytes(text.encode())
The output will be plain text as it is coded in the document. No effort is made to prettify in any way. Specifically for PDF, this may mean output not in usual reading order, unexpected line breaks and so forth.
You have many options to rectify this – see chapter 附录 2:嵌入式文件的注意事项. Among them are:
Extract text in HTML format and store it as a HTML document, so it can be viewed in any browser.
Extract text as a list of text blocks via Page.get_text(“blocks”). Each item of this list contains position information for its text, which can be used to establish a convenient reading order.
Extract a list of single words via Page.get_text(“words”). Its items are words with position information. Use it to determine text contained in a given rectangle – see next section.
See the following two sections for examples and further explanations.
如何将文本提取为 Markdown#
How to Extract Text as Markdown
这对于:title:RAG/LLM 环境特别有用 - 请参阅:ref:输出为 Markdown。
This is especially useful for RAG/LLM environments - please see Outputting as Markdown.
如何从页面中提取键值对#
How to Extract Key-Value Pairs from a Page
如果页面的布局在某种程度上是 “可预测的”,那么可以使用一种简单的方法快速、轻松地查找给定关键字对应的值 —— 而无需使用正则表达式。请参阅 此示例脚本。
在此上下文中,“可预测”意味着:
每个关键字后面紧跟其对应的值 —— 它们之间没有其他文本。
该值的边界框底部 不会高于 关键字的底部。
没有其他限制:页面布局可以是固定的,也可以是非固定的,文本也可能存储为一个整体字符串。关键字和值之间可以有任意距离。
例如,以下五组键值对都可以被正确识别:
key1 value1
key2
value2
key3
value3 blah, blah, blah key4 value4 some other text key5 value5 ...
If the layout of a page is “predictable” in some sense, then there is a simple way to find the values for a given set of keywords fast and easily – without using regular expressions. Please see this example script.
“Predictable” in this context means:
Every keyword is followed by its value – no other text is present in between them.
The bottom of the value’s boundary box is not above the one of the keyword.
There are no other restrictions: the page layout may or may not be fixed, and the text may also have been stored as one string. Key and value may have any distance from each other.
For example, the following five key-value pairs will be correctly identified:
key1 value1
key2
value2
key3
value3 blah, blah, blah key4 value4 some other text key5 value5 ...
如何从矩形内提取文本#
How to Extract Text from within a Rectangle
现在 (v1.18.0) 有多种方法可以实现此目的。因此,我们在 PyMuPDF-Utilities 存储库中创建了一个 文件夹 专门处理此主题。
There is now (v1.18.0) more than one way to achieve this. We therefore have created a folder in the PyMuPDF-Utilities repository specifically dealing with this topic.
如何按自然阅读顺序提取文本#
How to Extract Text in Natural Reading Order
PDF 文本提取的一个常见问题是,提取出的文本可能没有特定的阅读顺序。
这取决于 PDF 创建者(软件或人工)。例如,页眉可能是在文档生成后另行插入的。在这种情况下,页眉文本在提取时会出现在页面文本的末尾(尽管 PDF 查看器会正确显示它)。例如,以下代码片段将在现有 PDF 上添加一些页眉和页脚:
doc = pymupdf.open("some.pdf")
header = "Header" # 页眉文本
footer = "Page %i of %i" # 页脚文本
for page in doc:
page.insert_text((50, 50), header) # 插入页眉
page.insert_text( # 在页面底部上方 50 点插入页脚
(50, page.rect.height - 50),
footer % (page.number + 1, doc.page_count),
)
经过这种修改的页面,在提取文本时的顺序可能如下:
原始文本
页眉
页脚
PyMuPDF 提供了几种方法来恢复阅读顺序,甚至重新生成接近原始布局的文本:
使用
Page.get_text()方法的sort参数。该参数会将输出按照从左上角到右下角的顺序排序(对于 XHTML、HTML 和 XML 输出无效)。使用 PyMuPDF 的命令行工具:
python -m pymupdf gettext ...,该工具会生成一个文本文件,并在保留布局的模式下重新排列文本。可以使用多个选项来自定义输出格式。
此外,你还可以根据需要修改 此脚本 来适应不同的需求。
One of the common issues with PDF text extraction is, that text may not appear in any particular reading order.
This is the responsibility of the PDF creator (software or a human). For example, page headers may have been inserted in a separate step – after the document had been produced. In such a case, the header text will appear at the end of a page text extraction (although it will be correctly shown by PDF viewer software). For example, the following snippet will add some header and footer lines to an existing PDF:
doc = pymupdf.open("some.pdf")
header = "Header" # text in header
footer = "Page %i of %i" # text in footer
for page in doc:
page.insert_text((50, 50), header) # insert header
page.insert_text( # insert footer 50 points above page bottom
(50, page.rect.height - 50),
footer % (page.number + 1, doc.page_count),
)
The text sequence extracted from a page modified in this way will look like this:
original text
header line
footer line
PyMuPDF has several means to re-establish some reading sequence or even to re-generate a layout close to the original:
Use
sortparameter ofPage.get_text(). It will sort the output from top-left to bottom-right (ignored for XHTML, HTML and XML output).Use the
pymupdfmodule in CLI:python -m pymupdf gettext ..., which produces a text file where text has been re-arranged in layout-preserving mode. Many options are available to control the output.
You can also use the above mentioned script with your modifications.
如何从文档中 提取表格内容#
How to Extract Table Content from Documents
如果你在文档中看到一张表格,通常它并不是嵌入的 Excel 文件或其他可识别的对象,而只是普通文本,经过格式化后呈现为表格数据的样式。
因此,从这样的页面区域提取表格数据意味着你必须找到一种方法来 识别 表格区域(即其边界框),然后执行以下步骤:
(1) 以图形方式标识表格及其列边界;
(2) 基于这些信息提取文本。
根据具体情况,例如表格是否包含线条、矩形或其他辅助矢量图形,这可能是一项非常复杂的任务。
Page.find_tables() 方法可以自动完成上述步骤,并具有较高的表格检测精度。其主要优点包括:
无需依赖外部库,避免了额外的安装和兼容性问题。
无需使用人工智能或机器学习技术,提升了可用性和执行效率。
内置支持 pandas,可方便地将表格数据转换为 Pandas 数据框进行分析。
你可以参考 Jupyter Notebook 示例,其中涵盖了多种标准情况,如:
同一页上包含多个表格;
将跨页的表格片段合并为完整表格。
If you see a table in a document, you are normally not looking at something like an embedded Excel or other identifiable object. It usually is just normal, standard text, formatted to appear as tabular data.
Extracting tabular data from such a page area therefore means that you must find a way to identify the table area (i.e. its boundary box), then (1) graphically indicate table and column borders, and (2) then extract text based on this information.
This can be a very complex task, depending on details like the presence or absence of lines, rectangles or other supporting vector graphics.
Method Page.find_tables() does all that for you, with a high table detection precision. Its great advantage is that there are no external library dependencies, nor the need to employ artificial intelligence or machine learning technologies. It also provides an integrated interface to the well-known Python package for data analysis pandas.
Please have a look at example Jupyter notebooks, which cover standard situations like multiple tables on one page or joining table fragments across multiple pages.
如何标记提取的文本#
How to Mark Extracted Text
PyMuPDF 提供了一个标准的搜索功能,可用于在页面上搜索任意文本:Page.search_for()。该方法返回一个 Rect 对象列表,每个矩形对象包围着匹配文本的区域。这些矩形可以用于自动插入批注,从而可视化地标记找到的文本。
该方法的优缺点如下:
优点: - 搜索字符串可以包含空格,并且可以跨行匹配 - 不区分大小写 - 可以检测并解析行尾的单词连字符(hyphenation) - 返回值还可以是 Quad 对象列表,以精确定位 非水平或非垂直 的文本 - 如果页面已旋转,建议使用 Quad 以获得准确的位置
然而,你也可以使用其他方法,例如以下代码:
import sys
import pymupdf
def mark_word(page, text):
"""为包含 'text' 的每个单词添加下划线标注"""
found = 0
wlist = page.get_text("words", delimiters=None) # 获取单词列表
for w in wlist: # 遍历页面上的所有单词
if text in w[4]: # w[4] 是单词的文本内容
found += 1 # 计数
r = pymupdf.Rect(w[:4]) # 从单词边界框创建矩形
page.add_underline_annot(r) # 添加下划线标注
return found
fname = sys.argv[1] # 文件名
text = sys.argv[2] # 搜索字符串
doc = pymupdf.open(fname)
print("在文档 '%s' 中查找并标注包含 '%s' 的单词" % (doc.name, text))
new_doc = False # 指示是否有匹配项
for page in doc: # 遍历所有页面
found = mark_word(page, text) # 标注页面中的匹配单词
if found: # 如果找到匹配项
new_doc = True
print("在第 %i 页找到 '%s' %i 次" % (page.number + 1, text, found))
if new_doc:
doc.save("marked-" + doc.name)
该脚本使用 Page.get_text("words") 方法,通过 CLI 参数提供的字符串进行搜索。它将页面文本按空格分割为单词,并按单词进行搜索。以下是一些注意事项:
如果找到匹配项,则标注整个包含该字符串的单词 (添加下划线),而不仅仅是匹配部分。
搜索字符串不能包含单词分隔符,默认的分隔符是空格和不间断空格
chr(0xA0)。如果使用了额外的分隔符(例如page.get_text("words", delimiters="./,")),那么搜索字符串中也不能包含这些字符。区分大小写,但可以在 mark_word 方法中使用 lower() 方法或正则表达式来忽略大小写。
没有上限,所有出现的匹配项都会被检测到。
可以使用不同的标注方式,例如:’Underline’(下划线)、’Highlight’(高亮)、’StrikeThrough’(删除线)或 ‘Square’(矩形)等。
以下示例展示了如何搜索 “MuPDF”,并且所有包含 “MuPDF” 的完整单词都被下划线标注,而不仅仅是 “MuPDF” 本身。
There is a standard search function to search for arbitrary text on a page: Page.search_for(). It returns a list of Rect objects which surround a found occurrence. These rectangles can for example be used to automatically insert annotations which visibly mark the found text.
This method has advantages and drawbacks. Pros are:
The search string can contain blanks and wrap across lines
Upper or lower case characters are treated equal
Word hyphenation at line ends is detected and resolved
Return may also be a list of Quad objects to precisely locate text that is not parallel to either axis – using Quad output is also recommended, when page rotation is not zero.
But you also have other options:
import sys
import pymupdf
def mark_word(page, text):
"""Underline each word that contains 'text'.
"""
found = 0
wlist = page.get_text("words", delimiters=None) # make the word list
for w in wlist: # scan through all words on page
if text in w[4]: # w[4] is the word's string
found += 1 # count
r = pymupdf.Rect(w[:4]) # make rect from word bbox
page.add_underline_annot(r) # underline
return found
fname = sys.argv[1] # filename
text = sys.argv[2] # search string
doc = pymupdf.open(fname)
print("underlining words containing '%s' in document '%s'" % (word, doc.name))
new_doc = False # indicator if anything found at all
for page in doc: # scan through the pages
found = mark_word(page, text) # mark the page's words
if found: # if anything found ...
new_doc = True
print("found '%s' %i times on page %i" % (text, found, page.number + 1))
if new_doc:
doc.save("marked-" + doc.name)
This script uses Page.get_text("words") to look for a string, handed in via cli parameter. This method separates a page’s text into “words” using white spaces as delimiters. Further remarks:
If found, the complete word containing the string is marked (underlined) – not only the search string.
The search string may not contain word delimiters. By default, word delimiters are white spaces and the non-breaking space
chr(0xA0). If you use extra delimiting characters likepage.get_text("words", delimiters="./,")then none of these characters should be included in your search string either.As shown here, upper / lower cases are respected. But this can be changed by using the string method lower() (or even regular expressions) in function mark_word.
There is no upper limit: all occurrences will be detected.
You can use anything to mark the word: ‘Underline’, ‘Highlight’, ‘StrikeThrough’ or ‘Square’ annotations, etc.
Here is an example snippet of a page of this manual, where “MuPDF” has been used as the search string. Note that all strings containing “MuPDF” have been completely underlined (not just the search string).
如何标记搜索到的文本#
How to Mark Searched Text
此脚本用于搜索文本并对其进行标注:
# -*- coding: utf-8 -*-
import pymupdf
# 要标注的文档
doc = pymupdf.open("tilted-text.pdf")
# 需要标记的文本
needle = "¡La práctica hace el campeón!"
# 仅处理第一页
page = doc[0]
# 获取文本位置列表
# 使用 "quads" 而不是矩形,因为文本可能是倾斜的!
rl = page.search_for(needle, quads=True)
# 使用一个批注标记所有找到的文本区域
page.add_squiggly_annot(rl)
# 保存为新的 PDF 文件
doc.save("a-squiggly.pdf")
生成的结果如下:
This script searches for text and marks it:
# -*- coding: utf-8 -*-
import pymupdf
# the document to annotate
doc = pymupdf.open("tilted-text.pdf")
# the text to be marked
needle = "¡La práctica hace el campeón!"
# work with first page only
page = doc[0]
# get list of text locations
# we use "quads", not rectangles because text may be tilted!
rl = page.search_for(needle, quads=True)
# mark all found quads with one annotation
page.add_squiggly_annot(rl)
# save to a new PDF
doc.save("a-squiggly.pdf")
The result looks like this:

如何标记非水平文本#
How to Mark Non-horizontal Text
上一节已经展示了一个通过文本 搜索 检测并标记非水平文本的示例。
但是,使用 Page.get_text() 方法的 “dict” / “rawdict” 选项进行文本 提取 时,也可能会返回相对于 x 轴具有非零角度的文本。这由行字典的 "dir" 键的值指示:它是该角度的 (cosine, sine) 元组。如果 line["dir"] != (1, 0),则该行中所有跨度(span)的文本均按相同的非零角度旋转。
然而,该方法返回的 "bboxes" 仍然只是矩形,而不是四边形(quads)。因此,要正确标记跨度文本,需要从行和跨度字典中恢复其四边形。可以使用以下实用函数(v1.18.9 新增)完成此操作:
span_quad = pymupdf.recover_quad(line["dir"], span)
annot = page.add_highlight_annot(span_quad) # 这将标记整个跨度文本
如果想要 一次性标记整行 或其中某些跨度,可使用以下代码片段(适用于 v1.18.10 及更高版本):
line_quad = pymupdf.recover_line_quad(line, spans=line["spans"][1:-1])
page.add_highlight_annot(line_quad)

上述 spans 参数可以指定 line["spans"] 的任意子列表。在示例中,标记的是从第二个跨度到倒数第二个跨度的文本。如果省略该参数,则默认标记整行文本。
The previous section already shows an example for marking non-horizontal text, that was detected by text searching.
But text extraction with the “dict” / “rawdict” options of Page.get_text() may also return text with a non-zero angle to the x-axis. This is indicated by the value of the line dictionary’s "dir" key: it is the tuple (cosine, sine) for that angle. If line["dir"] != (1, 0), then the text of all its spans is rotated by (the same) angle != 0.
The “bboxes” returned by the method however are rectangles only – not quads. So, to mark span text correctly, its quad must be recovered from the data contained in the line and span dictionary. Do this with the following utility function (new in v1.18.9):
span_quad = pymupdf.recover_quad(line["dir"], span)
annot = page.add_highlight_annot(span_quad) # this will mark the complete span text
If you want to mark the complete line or a subset of its spans in one go, use the following snippet (works for v1.18.10 or later):
line_quad = pymupdf.recover_line_quad(line, spans=line["spans"][1:-1])
page.add_highlight_annot(line_quad)
The spans argument above may specify any sub-list of line["spans"]. In the example above, the second to second-to-last span are marked. If omitted, the complete line is taken.
如何分析字体特征#
How to Analyze Font Characteristics
要分析 PDF 文本的特性,可以使用以下基础脚本作为起点:
import sys
import pymupdf
def flags_decomposer(flags):
"""Make font flags human readable."""
l = []
if flags & 2 ** 0:
l.append("superscript")
if flags & 2 ** 1:
l.append("italic")
if flags & 2 ** 2:
l.append("serifed")
else:
l.append("sans")
if flags & 2 ** 3:
l.append("monospaced")
else:
l.append("proportional")
if flags & 2 ** 4:
l.append("bold")
return ", ".join(l)
doc = pymupdf.open(sys.argv[1])
page = doc[0]
# read page text as a dictionary, suppressing extra spaces in CJK fonts
blocks = page.get_text("dict", flags=11)["blocks"]
for b in blocks: # iterate through the text blocks
for l in b["lines"]: # iterate through the text lines
for s in l["spans"]: # iterate through the text spans
print("")
font_properties = "Font: '%s' (%s), size %g, color #%06x" % (
s["font"], # font name
flags_decomposer(s["flags"]), # readable font flags
s["size"], # font size
s["color"], # font color
)
print("Text: '%s'" % s["text"]) # simple print of text
print(font_properties)
以下是 PDF 页面及脚本的输出:
To analyze the characteristics of text in a PDF use this elementary script as a starting point:
import sys
import pymupdf
def flags_decomposer(flags):
"""Make font flags human readable."""
l = []
if flags & 2 ** 0:
l.append("superscript")
if flags & 2 ** 1:
l.append("italic")
if flags & 2 ** 2:
l.append("serifed")
else:
l.append("sans")
if flags & 2 ** 3:
l.append("monospaced")
else:
l.append("proportional")
if flags & 2 ** 4:
l.append("bold")
return ", ".join(l)
doc = pymupdf.open(sys.argv[1])
page = doc[0]
# read page text as a dictionary, suppressing extra spaces in CJK fonts
blocks = page.get_text("dict", flags=11)["blocks"]
for b in blocks: # iterate through the text blocks
for l in b["lines"]: # iterate through the text lines
for s in l["spans"]: # iterate through the text spans
print("")
font_properties = "Font: '%s' (%s), size %g, color #%06x" % (
s["font"], # font name
flags_decomposer(s["flags"]), # readable font flags
s["size"], # font size
s["color"], # font color
)
print("Text: '%s'" % s["text"]) # simple print of text
print(font_properties)
Here is the PDF page and the script output:

如何插入文本#
How to Insert Text
PyMuPDF 提供了在新建或现有 PDF 页面上插入文本的方法,并具备以下功能:
选择字体,包括内置字体和可用的外部字体文件
选择文本特性,如加粗、斜体、字体大小、字体颜色等
以多种方式定位文本:
以简单的行导向方式,从特定点开始输出文本,
或者将文本适应到指定矩形框内,并可选择文本对齐方式,
选择文本是否叠加在现有内容的前景中,
所有文本都可以进行任意“变形”(morphing),即通过 Matrix 修改外观,以实现缩放、倾斜、镜像等效果,
独立于变形之外,还可以将文本按 90 度的整数倍旋转。
Page.insert_font()—— 为页面安装一个字体,以便后续引用。其结果可通过Document.get_page_fonts()查看。该字体可以是:来自外部字体文件,
通过 Font 提供(使用
Font.buffer),已经存在于 当前或其他 PDF 文件中,
或者是 内置 字体。
Page.insert_text()—— 写入若干行文本。该方法在内部调用Shape.insert_text()。Page.insert_textbox()—— 将文本适应于指定的矩形框。可以选择文本对齐方式(左对齐、右对齐、居中、两端对齐),并控制文本是否能完全适应框内。该方法在内部调用Shape.insert_textbox()。
备注
以上两种文本插入方法会自动安装所需的字体(如必要)。
PyMuPDF provides ways to insert text on new or existing PDF pages with the following features:
choose the font, including built-in fonts and fonts that are available as files
choose text characteristics like bold, italic, font size, font color, etc.
position the text in multiple ways:
either as simple line-oriented output starting at a certain point,
or fitting text in a box provided as a rectangle, in which case text alignment choices are also available,
choose whether text should be put in foreground (overlay existing content),
all text can be arbitrarily “morphed”, i.e. its appearance can be changed via a Matrix, to achieve effects like scaling, shearing or mirroring,
independently from morphing and in addition to that, text can be rotated by integer multiples of 90 degrees.
All of the above is provided by three basic Page, resp. Shape methods:
Page.insert_font()– install a font for the page for later reference. The result is reflected in the output ofDocument.get_page_fonts(). The font can be:provided as a file,
via Font (then use
Font.buffer)already present somewhere in this or another PDF, or
be a built-in font.
Page.insert_text()– write some lines of text. Internally, this usesShape.insert_text().Page.insert_textbox()– fit text in a given rectangle. Here you can choose text alignment features (left, right, centered, justified) and you keep control as to whether text actually fits. Internally, this usesShape.insert_textbox().
备注
Both text insertion methods automatically install the font as necessary.
如何编写文本行#
How to Write Text Lines
在页面上输出一些文本行:
import pymupdf
doc = pymupdf.open(...) # 新建或打开一个 PDF
page = doc.new_page() # 新建或获取现有页面(如 doc[n])
p = pymupdf.Point(50, 72) # 第一行文本的起始点
text = "Some text,\nspread across\nseveral lines."
# 也可以使用列表格式:
# text = ["Some text", "spread across", "several lines."]
rc = page.insert_text(p, # 第一字符的左下角坐标
text, # 文本内容(支持 '\n' 换行)
fontname="helv", # 默认字体
fontsize=11, # 默认字体大小
rotate=0, # 旋转角度(可选:90, 180, 270)
)
print("%i 行文本已插入至页面 %i。" % (rc, page.number))
doc.save("text.pdf")
在此方法中,仅会控制文本行数,确保其不会超出页面高度。多余的行不会被写入,方法返回实际写入的行数。计算过程中,行高由 fontsize 计算,并在页面底部预留 36 点(0.5 英寸)的边距。
行宽不会被检查,超出部分将不可见。
然而,对于内置字体,可以在插入前计算文本的行宽,请参考 get_text_length() 方法。
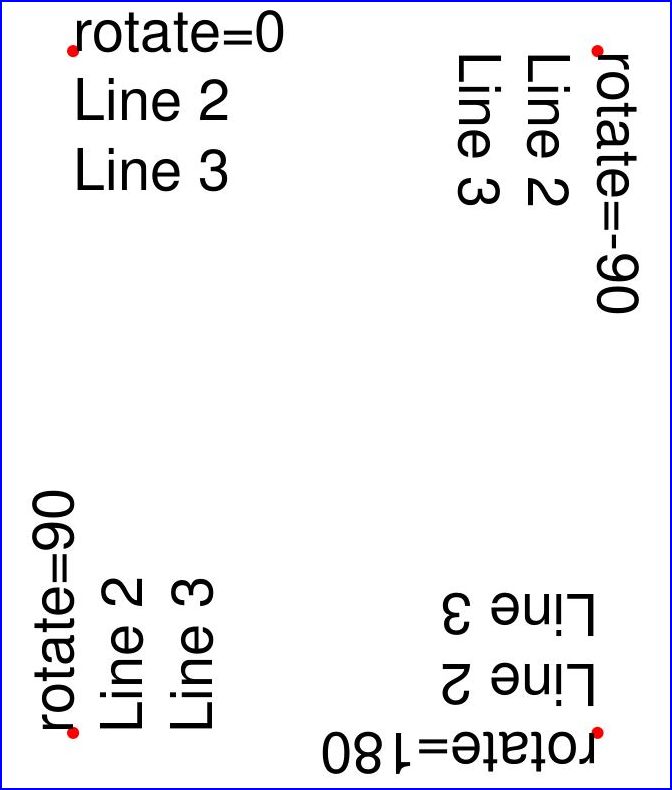
以下是另一个示例,该示例使用四种不同的旋转角度插入 4 段文本,并展示如何选择正确的插入点以获得期望的排版效果:
import pymupdf
doc = pymupdf.open()
page = doc.new_page()
# 文本内容,每个包含 3 行
text1 = "rotate=0\nLine 2\nLine 3"
text2 = "rotate=90\nLine 2\nLine 3"
text3 = "rotate=-90\nLine 2\nLine 3"
text4 = "rotate=180\nLine 2\nLine 3"
red = (1, 0, 0) # 红色点的颜色
# 插入点,距页面角落 25 像素
p1 = pymupdf.Point(25, 25)
p2 = pymupdf.Point(page.rect.width - 25, 25)
p3 = pymupdf.Point(25, page.rect.height - 25)
p4 = pymupdf.Point(page.rect.width - 25, page.rect.height - 25)
# 创建 Shape 进行绘制
shape = page.new_shape()
# 绘制插入点(红色填充的圆点)
shape.draw_circle(p1, 1)
shape.draw_circle(p2, 1)
shape.draw_circle(p3, 1)
shape.draw_circle(p4, 1)
shape.finish(width=0.3, color=red, fill=red)
# 插入文本
shape.insert_text(p1, text1)
shape.insert_text(p3, text2, rotate=90)
shape.insert_text(p2, text3, rotate=-90)
shape.insert_text(p4, text4, rotate=180)
# 提交绘制内容
shape.commit()
doc.save(...)
最终结果如下:
Output some text lines on a page:
import pymupdf
doc = pymupdf.open(...) # new or existing PDF
page = doc.new_page() # new or existing page via doc[n]
p = pymupdf.Point(50, 72) # start point of 1st line
text = "Some text,\nspread across\nseveral lines."
# the same result is achievable by
# text = ["Some text", "spread across", "several lines."]
rc = page.insert_text(p, # bottom-left of 1st char
text, # the text (honors '\n')
fontname = "helv", # the default font
fontsize = 11, # the default font size
rotate = 0, # also available: 90, 180, 270
)
print("%i lines printed on page %i." % (rc, page.number))
doc.save("text.pdf")
With this method, only the number of lines will be controlled to not go beyond page height. Surplus lines will not be written and the number of actual lines will be returned. The calculation uses a line height calculated from the fontsize and 36 points (0.5 inches) as bottom margin.
Line width is ignored. The surplus part of a line will simply be invisible.
However, for built-in fonts there are ways to calculate the line width beforehand - see get_text_length().
Here is another example. It inserts 4 text strings using the four different rotation options, and thereby explains, how the text insertion point must be chosen to achieve the desired result:
import pymupdf
doc = pymupdf.open()
page = doc.new_page()
# the text strings, each having 3 lines
text1 = "rotate=0\nLine 2\nLine 3"
text2 = "rotate=90\nLine 2\nLine 3"
text3 = "rotate=-90\nLine 2\nLine 3"
text4 = "rotate=180\nLine 2\nLine 3"
red = (1, 0, 0) # the color for the red dots
# the insertion points, each with a 25 pix distance from the corners
p1 = pymupdf.Point(25, 25)
p2 = pymupdf.Point(page.rect.width - 25, 25)
p3 = pymupdf.Point(25, page.rect.height - 25)
p4 = pymupdf.Point(page.rect.width - 25, page.rect.height - 25)
# create a Shape to draw on
shape = page.new_shape()
# draw the insertion points as red, filled dots
shape.draw_circle(p1,1)
shape.draw_circle(p2,1)
shape.draw_circle(p3,1)
shape.draw_circle(p4,1)
shape.finish(width=0.3, color=red, fill=red)
# insert the text strings
shape.insert_text(p1, text1)
shape.insert_text(p3, text2, rotate=90)
shape.insert_text(p2, text3, rotate=-90)
shape.insert_text(p4, text4, rotate=180)
# store our work to the page
shape.commit()
doc.save(...)
This is the result:
如何填充文本框#
How to Fill a Text Box
这个脚本填充了 4 个不同的矩形区域,每次选择不同的旋转角度值:
import pymupdf
doc = pymupdf.open() # 新建或打开一个 PDF
page = doc.new_page() # 新页面,或者选择 doc[n]
# 在此区域写入文本
rect = pymupdf.Rect(100, 100, 300, 150)
# 将该区域分成 4 个等大小的子矩形
CELLS = pymupdf.make_table(rect, cols=4, rows=1)
t1 = "text with rotate = 0." # 这些文本将被写入
t2 = "text with rotate = 90."
t3 = "text with rotate = 180."
t4 = "text with rotate = 270."
text = [t1, t2, t3, t4]
red = pymupdf.pdfcolor["red"] # 一些颜色
gold = pymupdf.pdfcolor["gold"]
blue = pymupdf.pdfcolor["blue"]
"""
我们使用 Shape 对象(类似画布)输出文本,并展示其周围的矩形。
"""
shape = page.new_shape() # 创建 Shape
for i in range(len(CELLS[0])):
shape.draw_rect(CELLS[0][i]) # 绘制矩形
shape.insert_textbox(
CELLS[0][i], text[i], fontname="hebo", color=blue, rotate=90 * i
)
shape.finish(width=0.3, color=red, fill=gold)
shape.commit() # 将所有内容写入页面
doc.ez_save(__file__.replace(".py", ".pdf"))
上述代码使用了默认值:字体大小 11 和文本对齐方式为 “left”。运行结果如下所示:
This script fills 4 different rectangles with text, each time choosing a different rotation value:
import pymupdf
doc = pymupdf.open() # new or existing PDF
page = doc.new_page() # new page, or choose doc[n]
# write in this overall area
rect = pymupdf.Rect(100, 100, 300, 150)
# partition the area in 4 equal sub-rectangles
CELLS = pymupdf.make_table(rect, cols=4, rows=1)
t1 = "text with rotate = 0." # these texts we will written
t2 = "text with rotate = 90."
t3 = "text with rotate = 180."
t4 = "text with rotate = 270."
text = [t1, t2, t3, t4]
red = pymupdf.pdfcolor["red"] # some colors
gold = pymupdf.pdfcolor["gold"]
blue = pymupdf.pdfcolor["blue"]
"""
We use a Shape object (something like a canvas) to output the text and
the rectangles surrounding it for demonstration.
"""
shape = page.new_shape() # create Shape
for i in range(len(CELLS[0])):
shape.draw_rect(CELLS[0][i]) # draw rectangle
shape.insert_textbox(
CELLS[0][i], text[i], fontname="hebo", color=blue, rotate=90 * i
)
shape.finish(width=0.3, color=red, fill=gold)
shape.commit() # write all stuff to the page
doc.ez_save(__file__.replace(".py", ".pdf"))
Some default values were used above: font size 11 and text alignment “left”. The result will look like this:

如何用 HTML 文本填充文本框#
How to Fill a Box with HTML Text
方法 Page.insert_htmlbox() 提供了一种 更强大的 插入文本的方式。
与简单的纯文本不同,这个方法接受 HTML 源代码,HTML 源不仅可以包含 HTML 标签,还可以包含样式指令来影响字体、字体加粗(bold)、斜体(italic)、颜色等属性。
此外,还可以混合使用多种字体和语言,输出 HTML 表格,甚至插入图片和 URI 链接。
为了提供更多的样式灵活性,还可以提供额外的 CSS 源。
该方法基于 Story 类。因此,像天城文、尼泊尔语、泰米尔语等复杂的书写系统都得到支持,并且能够正确书写,得益于使用了 HarfBuzz 库,它提供了所谓的 “文本形状” 特性。
任何需要的字体,如果用户提供的字体不包含某些字形,会自动从 Google 的 NOTO 字体库中拉取作为后备。
以下是一个展示此功能的小示例:
import pymupdf
rect = pymupdf.Rect(100, 100, 400, 300)
text = """Lorem ipsum dolor sit amet, consectetur adipisici elit, sed
eiusmod tempor incidunt ut labore et dolore magna aliqua. Ut enim ad
minim veniam, quis nostrud exercitation <b>ullamco <i>laboris</i></b>
nisi ut aliquid ex ea commodi consequat. Quis aute iure
<span style="color: #f00;">reprehenderit</span>
in <span style="color: #0f0;font-weight:bold;">voluptate</span> velit
esse cillum dolore eu fugiat nulla pariatur. Excepteur sint obcaecat
cupiditat non proident, sunt in culpa qui
<a href="https://www.artifex.com">officia</a> deserunt mollit anim id
est laborum."""
doc = pymupdf.Document()
page = doc.new_page()
page.insert_htmlbox(rect, text, css="* {font-family: sans-serif;font-size:14px;}")
doc.ez_save(__file__.replace(".py", ".pdf"))
请注意,”css” 参数被用来全局选择默认的 “sans-serif” 字体和字体大小 14。
运行结果如下所示:
Method Page.insert_htmlbox() offers a much more powerful way to insert text in a rectangle.
Instead of simple, plain text, this method accepts HTML source, which may not only contain HTML tags but also styling instructions to influence things like font, font weight (bold) and style (italic), color and much more.
It is also possible to mix multiple fonts and languages, to output HTML tables and to insert images and URI links.
For even more styling flexibility, an additional CSS source may also be given.
The method is based on the Story class. Therefore, complex script systems like Devanagari, Nepali, Tamil and many are supported and written correctly thanks to using the HarfBuzz library - which provides this so-called “text shaping” feature.
Any required fonts to output characters are automatically pulled in from the Google NOTO font library - as a fallback (when the – optionally supplied – user font(s) do not contain some glyphs).
As a small glimpse into the features offered here, we will output the following HTML-enriched text:
import pymupdf
rect = pymupdf.Rect(100, 100, 400, 300)
text = """Lorem ipsum dolor sit amet, consectetur adipisici elit, sed
eiusmod tempor incidunt ut labore et dolore magna aliqua. Ut enim ad
minim veniam, quis nostrud exercitation <b>ullamco <i>laboris</i></b>
nisi ut aliquid ex ea commodi consequat. Quis aute iure
<span style="color: #f00;">reprehenderit</span>
in <span style="color: #0f0;font-weight:bold;">voluptate</span> velit
esse cillum dolore eu fugiat nulla pariatur. Excepteur sint obcaecat
cupiditat non proident, sunt in culpa qui
<a href="https://www.artifex.com">officia</a> deserunt mollit anim id
est laborum."""
doc = pymupdf.Document()
page = doc.new_page()
page.insert_htmlbox(rect, text, css="* {font-family: sans-serif;font-size:14px;}")
doc.ez_save(__file__.replace(".py", ".pdf"))
Please note how the “css” parameter is used to globally select the default “sans-serif” font and a font size of 14.
The result will look like this:

如何输出 HTML 表格和图像#
How to output HTML tables and images
这里是另一个使用此方法输出表格的示例。这次,我们将所有的样式包含在HTML源代码中。还请注意,如何在表格单元格内包含图片:
import pymupdf
import os
filedir = os.path.dirname(__file__)
text = """
<style>
body {
font-family: sans-serif;
}
td,
th {
border: 1px solid blue;
border-right: none;
border-bottom: none;
padding: 5px;
text-align: center;
}
table {
border-right: 1px solid blue;
border-bottom: 1px solid blue;
border-spacing: 0;
}
</style>
<body>
<p><b>Some Colors</b></p>
<table>
<tr>
<th>Lime</th>
<th>Lemon</th>
<th>Image</th>
<th>Mauve</th>
</tr>
<tr>
<td>Green</td>
<td>Yellow</td>
<td><img src="img-cake.png" width=50></td>
<td>Between<br>Gray and Purple</td>
</tr>
</table>
</body>
"""
doc = pymupdf.Document()
page = doc.new_page()
rect = page.rect + (36, 36, -36, -36)
# 我们必须指定一个归档,因为有图片
page.insert_htmlbox(rect, text, archive=pymupdf.Archive("."))
doc.ez_save(__file__.replace(".py", ".pdf"))
结果将如下所示:
Here is another example that outputs a table with this method. This time, we are including all the styling in the HTML source itself. Please also note, how it works to include an image - even within a table cell:
import pymupdf
import os
filedir = os.path.dirname(__file__)
text = """
<style>
body {
font-family: sans-serif;
}
td,
th {
border: 1px solid blue;
border-right: none;
border-bottom: none;
padding: 5px;
text-align: center;
}
table {
border-right: 1px solid blue;
border-bottom: 1px solid blue;
border-spacing: 0;
}
</style>
<body>
<p><b>Some Colors</b></p>
<table>
<tr>
<th>Lime</th>
<th>Lemon</th>
<th>Image</th>
<th>Mauve</th>
</tr>
<tr>
<td>Green</td>
<td>Yellow</td>
<td><img src="img-cake.png" width=50></td>
<td>Between<br>Gray and Purple</td>
</tr>
</table>
</body>
"""
doc = pymupdf.Document()
page = doc.new_page()
rect = page.rect + (36, 36, -36, -36)
# we must specify an Archive because of the image
page.insert_htmlbox(rect, text, archive=pymupdf.Archive("."))
doc.ez_save(__file__.replace(".py", ".pdf"))
The result will look like this:

如何输出世界语言#
How to Output Languages of the World
我们的第三个示例将演示自动多语言支持。它包括针对复杂脚本系统(如梵文和从右到左的语言)的自动 文本整形:
import pymupdf
greetings = (
"Hello, World!", # english
"Hallo, Welt!", # german
"سلام دنیا!", # persian
"வணக்கம், உலகம்!", # tamil
"สวัสดีชาวโลก!", # thai
"Привіт Світ!", # ucranian
"שלום עולם!", # hebrew
"ওহে বিশ্ব!", # bengali
"你好世界!", # chinese
"こんにちは世界!", # japanese
"안녕하세요, 월드!", # korean
"नमस्कार, विश्व !", # sanskrit
"हैलो वर्ल्ड!", # hindi
)
doc = pymupdf.open()
page = doc.new_page()
rect = (50, 50, 200, 500)
# 将问候语合并为一个文本字符串
text = " ... ".join([t for t in greetings])
# 上面的输出很简单:
page.insert_htmlbox(rect, text)
doc.save(__file__.replace(".py", ".pdf"))
这是输出:
Our third example will demonstrate the automatic multi-language support. It includes automatic text shaping for complex scripting systems like Devanagari and right-to-left languages:
import pymupdf
greetings = (
"Hello, World!", # english
"Hallo, Welt!", # german
"سلام دنیا!", # persian
"வணக்கம், உலகம்!", # tamil
"สวัสดีชาวโลก!", # thai
"Привіт Світ!", # ucranian
"שלום עולם!", # hebrew
"ওহে বিশ্ব!", # bengali
"你好世界!", # chinese
"こんにちは世界!", # japanese
"안녕하세요, 월드!", # korean
"नमस्कार, विश्व !", # sanskrit
"हैलो वर्ल्ड!", # hindi
)
doc = pymupdf.open()
page = doc.new_page()
rect = (50, 50, 200, 500)
# join greetings into one text string
text = " ... ".join([t for t in greetings])
# the output of the above is simple:
page.insert_htmlbox(rect, text)
doc.save(__file__.replace(".py", ".pdf"))
And this is the output:

如何指定自己的字体#
How to Specify your Own Fonts
在CSS语法中定义您的字体文件,使用 @font-face 语句。每个字体的每种组合(如粗体或斜体)都需要单独的 @font-face 定义。以下示例使用了著名的MS Comic Sans字体的四种变体:常规、粗体、斜体和粗斜体。
由于这四个字体文件位于系统的 C:/Windows/Fonts 文件夹中,因此该方法需要一个 Archive 定义,用来指向该文件夹:
"""
如何使用自己的字体与方法 Page.insert_htmlbox()。
"""
import pymupdf
# 示例文本
text = """Lorem ipsum dolor sit amet, consectetur adipisici elit, sed
eiusmod tempor incidunt ut labore et dolore magna aliqua. Ut enim ad
minim veniam, quis nostrud exercitation <b>ullamco <i>laboris</i></b>
nisi ut aliquid ex ea commodi consequat. Quis aute iure
<span style="color: red;">reprehenderit</span>
in <span style="color: green;font-weight:bold;">voluptate</span> velit
esse cillum dolore eu fugiat nulla pariatur. Excepteur sint obcaecat
cupiditat non proident, sunt in culpa qui
<a href="https://www.artifex.com">officia</a> deserunt mollit anim id
est laborum."""
"""
我们需要一个Archive对象来显示字体文件的位置。
我们打算使用字体系列“MS Comic Sans”。
"""
arch = pymupdf.Archive("C:/Windows/Fonts")
# 这些语句定义了常规、粗体、斜体和粗斜体文本使用的字体文件。
# 我们为所有4个字体文件分配了一个任意的通用字体系列。
# Story算法会根据需要选择正确的文件。
# 我们要求在整个文本中使用“comic”。
css = """
@font-face {font-family: comic; src: url(comic.ttf);}
@font-face {font-family: comic; src: url(comicbd.ttf);font-weight: bold;}
@font-face {font-family: comic; src: url(comicz.ttf);font-weight: bold;font-style: italic;}
@font-face {font-family: comic; src: url(comici.ttf);font-style: italic;}
* {font-family: comic;}
"""
doc = pymupdf.Document()
page = doc.new_page(width=150, height=150) # 创建小页面
page.insert_htmlbox(page.rect, text, css=css, archive=arch)
doc.subset_fonts(verbose=True) # 创建子集字体以减小文件大小
doc.ez_save(__file__.replace(".py", ".pdf"))
Define your font files in CSS syntax using the @font-face statement. You need a separate @font-face for every combination of font weight and font style (e.g. bold or italic) you want to be supported. The following example uses the famous MS Comic Sans font in its four variants regular, bold, italic and bold-italic.
As these four font files are located in the system’s folder C:/Windows/Fonts the method needs an Archive definition that points to that folder:
"""
How to use your own fonts with method Page.insert_htmlbox().
"""
import pymupdf
# Example text
text = """Lorem ipsum dolor sit amet, consectetur adipisici elit, sed
eiusmod tempor incidunt ut labore et dolore magna aliqua. Ut enim ad
minim veniam, quis nostrud exercitation <b>ullamco <i>laboris</i></b>
nisi ut aliquid ex ea commodi consequat. Quis aute iure
<span style="color: red;">reprehenderit</span>
in <span style="color: green;font-weight:bold;">voluptate</span> velit
esse cillum dolore eu fugiat nulla pariatur. Excepteur sint obcaecat
cupiditat non proident, sunt in culpa qui
<a href="https://www.artifex.com">officia</a> deserunt mollit anim id
est laborum."""
"""
We need an Archive object to show where font files are located.
We intend to use the font family "MS Comic Sans".
"""
arch = pymupdf.Archive("C:/Windows/Fonts")
# These statements define which font file to use for regular, bold,
# italic and bold-italic text.
# We assign an arbitrary common font-family for all 4 font files.
# The Story algorithm will select the right file as required.
# We request to use "comic" throughout the text.
css = """
@font-face {font-family: comic; src: url(comic.ttf);}
@font-face {font-family: comic; src: url(comicbd.ttf);font-weight: bold;}
@font-face {font-family: comic; src: url(comicz.ttf);font-weight: bold;font-style: italic;}
@font-face {font-family: comic; src: url(comici.ttf);font-style: italic;}
* {font-family: comic;}
"""
doc = pymupdf.Document()
page = doc.new_page(width=150, height=150) # make small page
page.insert_htmlbox(page.rect, text, css=css, archive=arch)
doc.subset_fonts(verbose=True) # build subset fonts to reduce file size
doc.ez_save(__file__.replace(".py", ".pdf"))

如何请求文本对齐#
How to Request Text Alignment
此示例结合了多个要求:
将文本逆时针旋转90度。
使用来自 pymupdf-fonts 包的字体。你会发现,在这种情况下,相应的CSS定义要容易得多。
使用“justify”选项对齐文本。
"""
如何使用pymupdf字体与方法 Page.insert_htmlbox()。
"""
import pymupdf
# 示例文本
text = """Lorem ipsum dolor sit amet, consectetur adipisici elit, sed
eiusmod tempor incidunt ut labore et dolore magna aliqua. Ut enim ad
minim veniam, quis nostrud exercitation <b>ullamco <i>laboris</i></b>
nisi ut aliquid ex ea commodi consequat. Quis aute iure
<span style="color: red;">reprehenderit</span>
in <span style="color: green;font-weight:bold;">voluptate</span> velit
esse cillum dolore eu fugiat nulla pariatur. Excepteur sint obcaecat
cupiditat non proident, sunt in culpa qui
<a href="https://www.artifex.com">officia</a> deserunt mollit anim id
est laborum."""
"""
这类似于字体文件支持。然而,我们可以使用一个便捷函数来创建所需的CSS定义。
我们仍然需要一个Archive来查找字体二进制文件。
"""
arch = pymupdf.Archive()
# 我们请求在整个文本中使用“myfont”字体。
css = pymupdf.css_for_pymupdf_font("ubuntu", archive=arch, name="myfont")
css += "* {font-family: myfont;text-align: justify;}"
doc = pymupdf.Document()
page = doc.new_page(width=150, height=150)
page.insert_htmlbox(page.rect, text, css=css, archive=arch, rotate=90)
doc.subset_fonts(verbose=True)
doc.ez_save(__file__.replace(".py", ".pdf"))
This example combines multiple requirements:
Rotate the text by 90 degrees anti-clockwise.
Use a font from package pymupdf-fonts. You will see that the respective CSS definitions are a lot easier in this case.
Align the text with the “justify” option.
"""
How to use a pymupdf font with method Page.insert_htmlbox().
"""
import pymupdf
# Example text
text = """Lorem ipsum dolor sit amet, consectetur adipisici elit, sed
eiusmod tempor incidunt ut labore et dolore magna aliqua. Ut enim ad
minim veniam, quis nostrud exercitation <b>ullamco <i>laboris</i></b>
nisi ut aliquid ex ea commodi consequat. Quis aute iure
<span style="color: red;">reprehenderit</span>
in <span style="color: green;font-weight:bold;">voluptate</span> velit
esse cillum dolore eu fugiat nulla pariatur. Excepteur sint obcaecat
cupiditat non proident, sunt in culpa qui
<a href="https://www.artifex.com">officia</a> deserunt mollit anim id
est laborum."""
"""
This is similar to font file support. However, we can use a convenience
function for creating required CSS definitions.
We still need an Archive for finding the font binaries.
"""
arch = pymupdf.Archive()
# We request to use "myfont" throughout the text.
css = pymupdf.css_for_pymupdf_font("ubuntu", archive=arch, name="myfont")
css += "* {font-family: myfont;text-align: justify;}"
doc = pymupdf.Document()
page = doc.new_page(width=150, height=150)
page.insert_htmlbox(page.rect, text, css=css, archive=arch, rotate=90)
doc.subset_fonts(verbose=True)
doc.ez_save(__file__.replace(".py", ".pdf"))

如何提取带颜色的文本#
How to Extract Text with Color
遍历您的文本块并找到此信息所需的文本跨度。
Iterate through your text blocks and find the spans of text you need for this information.
for page in doc:
text_blocks = page.get_text("dict", flags=pymupdf.TEXTFLAGS_TEXT)["blocks"]
for block in text_blocks:
for line in block["lines"]:
for span in line["spans"]:
text = span["text"]
color = pymupdf.sRGB_to_rgb(span["color"])
print(f"Text: {text}, Color: {color}")