基础用法#
The Basics
打开文件#
Opening a File
要打开文件,请执行以下操作:
import pymupdf
doc = pymupdf.open("a.pdf") # open a document
To open a file, do the following:
import pymupdf
doc = pymupdf.open("a.pdf") # open a document
备注
Taking it further
See the list of supported file types and The How to Guide on Opening Files for more advanced options.
从 PDF 中提取文本#
Extract text from a PDF
要从 PDF 文件中提取所有文本,请执行以下操作:
import pymupdf
doc = pymupdf.open("a.pdf") # 打开 PDF 文档
out = open("output.txt", "wb") # 创建文本输出文件
for page in doc: # 遍历文档页面
text = page.get_text().encode("utf8") # 获取纯文本(UTF-8 编码)
out.write(text) # 写入页面文本
out.write(bytes((12,))) # 写入页面分隔符(换页符 0x0C)
out.close()
当然,不仅仅是 PDF 可以提取文本,所有 支持的文档文件格式,如 MOBI、 EPUB、 TXT,都可以提取文本。
备注
进一步提升
如果您的文档包含基于图像的文本内容,可以对页面使用 OCR 进行文本提取:
tp = page.get_textpage_ocr()
text = page.get_text(textpage=tp)
还有许多示例讲解了如何从特定区域提取文本,或者如何从文档中提取表格。请参考 文本处理指南。
现在,您还可以 以 Markdown 格式提取文本。
API 参考
To extract all the text from a PDF file, do the following:
import pymupdf
doc = pymupdf.open("a.pdf") # open a document
out = open("output.txt", "wb") # create a text output
for page in doc: # iterate the document pages
text = page.get_text().encode("utf8") # get plain text (is in UTF-8)
out.write(text) # write text of page
out.write(bytes((12,))) # write page delimiter (form feed 0x0C)
out.close()
Of course it is not just PDF which can have text extracted - all the supported document file formats such as MOBI, EPUB, TXT can have their text extracted.
备注
Taking it further
If your document contains image based text content the use OCR on the page for subsequent text extraction:
tp = page.get_textpage_ocr()
text = page.get_text(textpage=tp)
There are many more examples which explain how to extract text from specific areas or how to extract tables from documents. Please refer to the How to Guide for Text.
You can now also extract text in Markdown format.
API reference
从 PDF 中提取图像#
Extract images from a PDF
要从 PDF 文件中提取所有图像,请执行以下操作:
import pymupdf
doc = pymupdf.open("test.pdf") # 打开 PDF 文档
for page_index in range(len(doc)): # 遍历 PDF 页面
page = doc[page_index] # 获取页面
image_list = page.get_images()
# 输出当前页面找到的图像数量
if image_list:
print(f"在第 {page_index} 页找到 {len(image_list)} 张图片")
else:
print(f"第 {page_index} 页未找到图片")
for image_index, img in enumerate(image_list, start=1): # 遍历图像列表
xref = img[0] # 获取图像的 XREF
pix = pymupdf.Pixmap(doc, xref) # 创建 Pixmap 对象
if pix.n - pix.alpha > 3: # 如果是 CMYK 模式,则先转换为 RGB
pix = pymupdf.Pixmap(pymupdf.csRGB, pix)
pix.save("page_%s-image_%s.png" % (page_index, image_index)) # 以 PNG 格式保存图片
pix = None
To extract all the images from a PDF file, do the following:
import pymupdf
doc = pymupdf.open("test.pdf") # open a document
for page_index in range(len(doc)): # iterate over pdf pages
page = doc[page_index] # get the page
image_list = page.get_images()
# print the number of images found on the page
if image_list:
print(f"Found {len(image_list)} images on page {page_index}")
else:
print("No images found on page", page_index)
for image_index, img in enumerate(image_list, start=1): # enumerate the image list
xref = img[0] # get the XREF of the image
pix = pymupdf.Pixmap(doc, xref) # create a Pixmap
if pix.n - pix.alpha > 3: # CMYK: convert to RGB first
pix = pymupdf.Pixmap(pymupdf.csRGB, pix)
pix.save("page_%s-image_%s.png" % (page_index, image_index)) # save the image as png
pix = None
备注
Taking it further
There are many more examples which explain how to extract text from specific areas or how to extract tables from documents. Please refer to the How to Guide for Text.
API reference
提取矢量图形#
Extract vector graphics
要从文档页面中提取所有矢量图形,请执行以下操作:
doc = pymupdf.open("some.file")
page = doc[0]
paths = page.get_drawings()
这将返回一个包含页面上所有矢量绘图路径的字典。
To extract all the vector graphics from a document page, do the following:
doc = pymupdf.open("some.file")
page = doc[0]
paths = page.get_drawings()
This will return a dictionary of paths for any vector drawings found on the page.
合并 PDF 文件#
Merging PDF files
要合并 PDF 文件,请执行以下操作:
import pymupdf
doc_a = pymupdf.open("a.pdf") # 打开第一个文档
doc_b = pymupdf.open("b.pdf") # 打开第二个文档
doc_a.insert_pdf(doc_b) # 合并文档
doc_a.save("a+b.pdf") # 以新文件名保存合并后的文档
To merge PDF files, do the following:
import pymupdf
doc_a = pymupdf.open("a.pdf") # open the 1st document
doc_b = pymupdf.open("b.pdf") # open the 2nd document
doc_a.insert_pdf(doc_b) # merge the docs
doc_a.save("a+b.pdf") # save the merged document with a new filename
将 PDF 文件与其他类型的文件合并#
Merging PDF files with other types of file
使用 Document.insert_file(),您可以调用该方法将 支持的文件 与 PDF 合并。例如:
import pymupdf
doc_a = pymupdf.open("a.pdf") # 打开第一个文档
doc_b = pymupdf.open("b.svg") # 打开第二个文档
doc_a.insert_file(doc_b) # 合并文档
doc_a.save("a+b.pdf") # 以新文件名保存合并后的文档
备注
深入探索
使用 Document.insert_pdf() 和 Document.insert_file() 轻松合并 PDF。对于已打开的 PDF 文档,您可以将一个文档中的页面范围复制到另一个文档中。您可以选择插入位置、翻转页面顺序以及更改页面旋转角度。
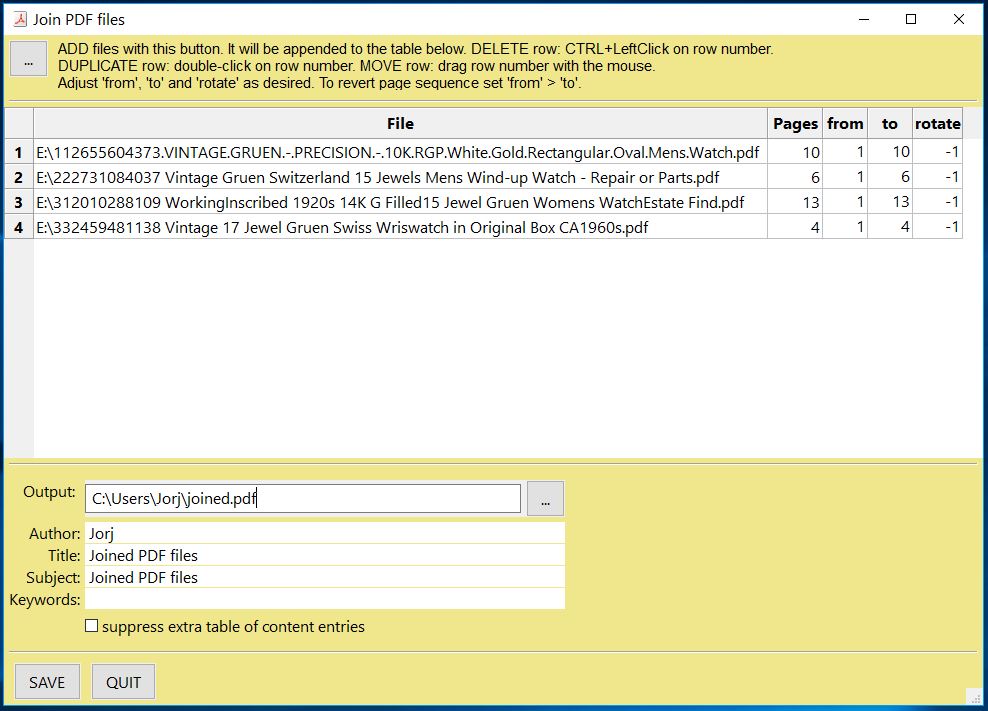
GUI 脚本 join.py 采用此方法合并文件列表,并同时合并相应的目录结构。界面如下所示:
- scale:
60
API 参考
With Document.insert_file() you can invoke the method to merge supported files with PDF. For example:
import pymupdf
doc_a = pymupdf.open("a.pdf") # open the 1st document
doc_b = pymupdf.open("b.svg") # open the 2nd document
doc_a.insert_file(doc_b) # merge the docs
doc_a.save("a+b.pdf") # save the merged document with a new filename
备注
Taking it further
It is easy to join PDFs with Document.insert_pdf() & Document.insert_file(). Given open PDF documents, you can copy page ranges from one to the other. You can select the point where the copied pages should be placed, you can revert the page sequence and also change page rotation.
The GUI script join.py uses this method to join a list of files while also joining the respective table of contents segments. It looks like this:
- scale:
60
API reference
使用坐标#
Working with Coordinates
在使用 PyMuPDF 时,有一个 数学术语 您需要熟悉—— “坐标” 。请快速浏览 坐标 部分,以了解坐标系统。这将帮助您准确定位对象,并更好地理解您的文档空间。
There is one mathematical term that you should feel comfortable with when using PyMuPDF - “coordinates”. Please have a quick look at the 坐标 section to understand the coordinate system to help you with positioning objects and understand your document space.
向 PDF 添加水印#
Adding a watermark to a PDF
要向 PDF 文件添加水印,请执行以下操作:
import pymupdf
doc = pymupdf.open("document.pdf") # 打开 PDF 文档
for page_index in range(len(doc)): # 遍历 PDF 页
page = doc[page_index] # 获取页面
# 从文件插入图像水印,使其适应页面边界
page.insert_image(page.bound(), filename="watermark.png", overlay=False)
doc.save("watermarked-document.pdf") # 以新文件名保存水印后的文档
备注
更进一步
添加水印的本质就是在每个 PDF 页面底部添加一个图像。您应该确保该图像具有所需的不透明度和纵横比,以使其呈现符合需求的效果。
在上面的示例中,每次引用文件时都会创建一个新的图像。但为了提高性能(减少内存占用和文件大小),应仅引用一次此图像数据。请参考 Page.insert_image() 的代码示例和解释,了解具体实现方式。
API 参考
To add a watermark to a PDF file, do the following:
import pymupdf
doc = pymupdf.open("document.pdf") # open a document
for page_index in range(len(doc)): # iterate over pdf pages
page = doc[page_index] # get the page
# insert an image watermark from a file name to fit the page bounds
page.insert_image(page.bound(),filename="watermark.png", overlay=False)
doc.save("watermarked-document.pdf") # save the document with a new filename
备注
Taking it further
Adding watermarks is essentially as simple as adding an image at the base of each PDF page. You should ensure that the image has the required opacity and aspect ratio to make it look the way you need it to.
In the example above a new image is created from each file reference, but to be more performant (by saving memory and file size) this image data should be referenced only once - see the code example and explanation on Page.insert_image() for the implementation.
API reference
向 PDF 添加图像#
Adding an image to a PDF
要向 PDF 文件添加图像(例如 Logo),请执行以下操作:
import pymupdf
doc = pymupdf.open("document.pdf") # 打开 PDF 文档
for page_index in range(len(doc)): # 遍历 PDF 页
page = doc[page_index] # 获取页面
# 从文件插入 Logo 图像,放置在文档左上角
page.insert_image(pymupdf.Rect(0,0,50,50), filename="my-logo.png")
doc.save("logo-document.pdf") # 以新文件名保存文档
To add an image to a PDF file, for example a logo, do the following:
import pymupdf
doc = pymupdf.open("document.pdf") # open a document
for page_index in range(len(doc)): # iterate over pdf pages
page = doc[page_index] # get the page
# insert an image logo from a file name at the top left of the document
page.insert_image(pymupdf.Rect(0,0,50,50),filename="my-logo.png")
doc.save("logo-document.pdf") # save the document with a new filename
备注
Taking it further
As with the watermark example you should ensure to be more performant by only referencing the image once if possible - see the code example and explanation on Page.insert_image().
API reference
旋转 PDF#
Rotating a PDF
要旋转 PDF 页面,请执行以下操作:
import pymupdf
doc = pymupdf.open("test.pdf") # 打开 PDF 文档
page = doc[0] # 获取文档的第一页
page.set_rotation(90) # 旋转页面 90 度
doc.save("rotated-page-1.pdf") # 以新文件名保存文档
To add a rotation to a page, do the following:
import pymupdf
doc = pymupdf.open("test.pdf") # open document
page = doc[0] # get the 1st page of the document
page.set_rotation(90) # rotate the page
doc.save("rotated-page-1.pdf")
裁剪 PDF#
Cropping a PDF
要裁剪 PDF 页面到指定的 Rect 区域,请执行以下操作:
import pymupdf
doc = pymupdf.open("test.pdf") # 打开 PDF 文档
page = doc[0] # 获取文档的第一页
page.set_cropbox(pymupdf.Rect(100, 100, 400, 400)) # 设置裁剪区域
doc.save("cropped-page-1.pdf") # 以新文件名保存裁剪后的文档
备注
API 参考
:
To crop a page to a defined Rect, do the following:
import pymupdf
doc = pymupdf.open("test.pdf") # open document
page = doc[0] # get the 1st page of the document
page.set_cropbox(pymupdf.Rect(100, 100, 400, 400)) # set a cropbox for the page
doc.save("cropped-page-1.pdf")
附加文件#
Attaching Files
要将另一个文件附加到页面中,请执行以下操作:
import pymupdf
doc = pymupdf.open("test.pdf") # 打开主文档
attachment = pymupdf.open("my-attachment.pdf") # 打开要附加的文档
page = doc[0] # 获取文档的第一页
point = pymupdf.Point(100, 100) # 创建添加附件的位置
attachment_data = attachment.tobytes() # 获取文档的字节数据作为缓冲区
# 添加文件注释,指定位置、数据和文件名
file_annotation = page.add_file_annot(point, attachment_data, "attachment.pdf")
doc.save("document-with-attachment.pdf") # 保存包含附件的文档
备注
进一步操作
在使用 Page.add_file_annot() 添加文件时,注意 filename 的第三个参数应包含实际的文件扩展名。没有扩展名,附件可能无法被识别为可打开的文件。例如,如果 filename 只是 “attachment”,在查看结果 PDF 并尝试打开附件时,可能会收到错误。但如果是 “attachment.pdf”,PDF 查看器就能识别并成功打开附件。
附件的默认图标是 “推针”,但可以通过设置 icon 参数来更改它。
API 参考
To attach another file to a page, do the following:
import pymupdf
doc = pymupdf.open("test.pdf") # open main document
attachment = pymupdf.open("my-attachment.pdf") # open document you want to attach
page = doc[0] # get the 1st page of the document
point = pymupdf.Point(100, 100) # create the point where you want to add the attachment
attachment_data = attachment.tobytes() # get the document byte data as a buffer
# add the file annotation with the point, data and the file name
file_annotation = page.add_file_annot(point, attachment_data, "attachment.pdf")
doc.save("document-with-attachment.pdf") # save the document
备注
Taking it further
When adding the file with Page.add_file_annot() note that the third parameter for the filename should include the actual file extension. Without this the attachment possibly will not be able to be recognized as being something which can be opened. For example, if the filename is just “attachment” when view the resulting PDF and attempting to open the attachment you may well get an error. However, with “attachment.pdf” this can be recognized and opened by PDF viewers as a valid file type.
The default icon for the attachment is by default a “push pin”, however you can change this by setting the icon parameter.
API reference
嵌入文件#
Embedding Files
要将文件嵌入到文档中,请执行以下操作:
import pymupdf
doc = pymupdf.open("test.pdf") # 打开主文档
embedded_doc = pymupdf.open("my-embed.pdf") # 打开要嵌入的文档
embedded_data = embedded_doc.tobytes() # 获取文档的字节数据作为缓冲区
# 使用文件名和数据进行嵌入
doc.embfile_add("my-embedded_file.pdf", embedded_data)
doc.save("document-with-embed.pdf") # 保存包含嵌入文件的文档
To embed a file to a document, do the following:
import pymupdf
doc = pymupdf.open("test.pdf") # open main document
embedded_doc = pymupdf.open("my-embed.pdf") # open document you want to embed
embedded_data = embedded_doc.tobytes() # get the document byte data as a buffer
# embed with the file name and the data
doc.embfile_add("my-embedded_file.pdf", embedded_data)
doc.save("document-with-embed.pdf") # save the document
备注
Taking it further
As with attaching files, when adding the file with Document.embfile_add() note that the first parameter for the filename should include the actual file extension.
API reference
删除页面#
Deleting Pages
要从文档中删除页面,请执行以下操作:
import pymupdf
doc = pymupdf.open("test.pdf") # 打开文档
doc.delete_page(0) # 删除文档中的第1页
doc.save("test-deleted-page-one.pdf") # 保存文档
要从文档中删除多个页面,请执行以下操作:
import pymupdf
doc = pymupdf.open("test.pdf") # 打开文档
doc.delete_pages(from_page=9, to_page=14) # 删除文档中的页面范围
doc.save("test-deleted-pages.pdf") # 保存文档
To delete a page from a document, do the following:
import pymupdf
doc = pymupdf.open("test.pdf") # open a document
doc.delete_page(0) # delete the 1st page of the document
doc.save("test-deleted-page-one.pdf") # save the document
To delete a multiple pages from a document, do the following:
import pymupdf
doc = pymupdf.open("test.pdf") # open a document
doc.delete_pages(from_page=9, to_page=14) # delete a page range from the document
doc.save("test-deleted-pages.pdf") # save the document
如果我删除书签或超链接引用的页面会发生什么?#
What happens if I delete a page referred to by bookmarks or hyperlinks?
书签(目录中的条目)将变为无效,并且将不再导航到任何页面。
超链接将从包含它的页面中删除。该页面上的可见内容将不会以其他方式更改。
备注
进一步操作
页面索引是从零开始的,因此要删除文档中的第10页,您可以执行以下操作 doc.delete_page(9)。
同样,doc.delete_pages(from_page=9, to_page=14) 将删除第10到第15页(包括这两页)。
API参考
A bookmark (entry in the Table of Contents) will become inactive and will no longer navigate to any page.
A hyperlink will be removed from the page that contains it. The visible content on that page will not otherwise be changed in any way.
备注
Taking it further
The page index is zero-based, so to delete page 10 of a document you would do the following doc.delete_page(9).
Similarly, doc.delete_pages(from_page=9, to_page=14) will delete pages 10 - 15 inclusive.
API reference
重新排列页面#
Re-Arranging Pages
要更改页面的顺序,即重新排列页面,可以执行以下操作:
import pymupdf
doc = pymupdf.open("test.pdf") # 打开文档
doc.move_page(1,0) # 将文档中的第2页移到文档的开头
doc.save("test-page-moved.pdf") # 保存文档
To change the sequence of pages, i.e. re-arrange pages, do the following:
import pymupdf
doc = pymupdf.open("test.pdf") # open a document
doc.move_page(1,0) # move the 2nd page of the document to the start of the document
doc.save("test-page-moved.pdf") # save the document
复制页面#
Copying Pages
要复制页面,可以执行以下操作:
import pymupdf
doc = pymupdf.open("test.pdf") # 打开文档
doc.copy_page(0) # 复制第1页并将其放置在文档的末尾
doc.save("test-page-copied.pdf") # 保存文档
To copy pages, do the following:
import pymupdf
doc = pymupdf.open("test.pdf") # open a document
doc.copy_page(0) # copy the 1st page and puts it at the end of the document
doc.save("test-page-copied.pdf") # save the document
选择页面#
Selecting Pages
要选择页面,可以执行以下操作:
import pymupdf
doc = pymupdf.open("test.pdf") # 打开文档
doc.select([0, 1]) # 选择文档的第1页和第2页
doc.save("just-page-one-and-two.pdf") # 保存文档
备注
进一步说明
使用 PyMuPDF,您可以轻松地复制、移动、删除或重新排列 PDF 的页面。直观的方法允许您按页面级别进行操作,如 Document.copy_page() 方法。
或者,您可以准备一个包含您想要的页面顺序的完整新页面布局,并按所需的顺序和次数重复每个页面。以下示例说明了使用 Document.select() 可以做什么:
doc.select([1, 1, 1, 5, 4, 9, 9, 9, 0, 2, 2, 2])
现在让我们为双面打印(在不直接支持此功能的打印机上)准备一个 PDF:
页数由 len(doc) (等于 doc.page_count)给出。以下分别表示偶数页和奇数页的页码:
p_even = [p in range(doc.page_count) if p % 2 == 0]
p_odd = [p in range(doc.page_count) if p % 2 == 1]
这个代码片段创建了相应的子文档,然后可以用于打印文档:
doc.select(p_even) # 仅保留偶数页
doc.save("even.pdf") # 保存“偶数”PDF
doc.close() # 回收文件
doc = pymupdf.open(doc.name) # 重新打开
doc.select(p_odd) # 对奇数页执行相同操作
doc.save("odd.pdf")
有关更多信息,请查看此 Wiki 文章。
以下示例将反转所有页面的顺序(非常快速:在 756 页的 Adobe PDF 参考 上不到一秒钟):
lastPage = doc.page_count - 1
for i in range(lastPage):
doc.move_page(lastPage, i) # 将当前最后一页移到前面
这个代码片段将 PDF 自身复制,以便它将包含页面 0, 1, …, n, 0, 1, …, n (非常快速且几乎不增加文件大小!):
page_count = len(doc)
for i in range(page_count):
doc.copy_page(i) # 将此页面复制到最后一页后面
API参考
To select pages, do the following:
import pymupdf
doc = pymupdf.open("test.pdf") # open a document
doc.select([0, 1]) # select the 1st & 2nd page of the document
doc.save("just-page-one-and-two.pdf") # save the document
备注
Taking it further
With PyMuPDF you have all options to copy, move, delete or re-arrange the pages of a PDF. Intuitive methods exist that allow you to do this on a page-by-page level, like the Document.copy_page() method.
Or you alternatively prepare a complete new page layout in form of a Python sequence, that contains the page numbers you want, in the sequence you want, and as many times as you want each page. The following may illustrate what can be done with Document.select()
doc.select([1, 1, 1, 5, 4, 9, 9, 9, 0, 2, 2, 2])
Now let’s prepare a PDF for double-sided printing (on a printer not directly supporting this):
The number of pages is given by len(doc) (equal to doc.page_count). The following lists represent the even and the odd page numbers, respectively:
p_even = [p in range(doc.page_count) if p % 2 == 0]
p_odd = [p in range(doc.page_count) if p % 2 == 1]
This snippet creates the respective sub documents which can then be used to print the document:
doc.select(p_even) # only the even pages left over
doc.save("even.pdf") # save the "even" PDF
doc.close() # recycle the file
doc = pymupdf.open(doc.name) # re-open
doc.select(p_odd) # and do the same with the odd pages
doc.save("odd.pdf")
For more information also have a look at this Wiki article.
The following example will reverse the order of all pages (extremely fast: sub-second time for the 756 pages of the Adobe PDF 参考):
lastPage = doc.page_count - 1
for i in range(lastPage):
doc.move_page(lastPage, i) # move current last page to the front
This snippet duplicates the PDF with itself so that it will contain the pages 0, 1, …, n, 0, 1, …, n (extremely fast and without noticeably increasing the file size!):
page_count = len(doc)
for i in range(page_count):
doc.copy_page(i) # copy this page to after last page
API reference
添加空白页#
Adding Blank Pages
要添加一个空白页,可以执行以下操作:
import pymupdf
doc = pymupdf.open(...) # 打开一个新的或现有的PDF文档
page = doc.new_page(-1, # 插入点:文档末尾
width = 595, # 页面尺寸:A4纵向
height = 842)
doc.save("doc-with-new-blank-page.pdf") # 保存文档
备注
进一步说明
使用此方法创建页面时,可以选择其他预定义的纸张格式:
w, h = pymupdf.paper_size("letter-l") # 'Letter'横向
page = doc.new_page(width = w, height = h)
方便的函数 paper_size() 支持选择超过40种行业标准的纸张格式。要查看它们,请检查字典 paperSizes。将所需的字典键传递给 paper_size() 以获取纸张尺寸。支持大小写。如果在格式名称后附加 “-L”,则返回横向版本。
这是一个创建包含一个空白页的 PDF 的三行代码。其文件大小为460字节:
doc = pymupdf.open()
doc.new_page()
doc.save("A4.pdf")
API参考
paperSizes
To add a blank page, do the following:
import pymupdf
doc = pymupdf.open(...) # some new or existing PDF document
page = doc.new_page(-1, # insertion point: end of document
width = 595, # page dimension: A4 portrait
height = 842)
doc.save("doc-with-new-blank-page.pdf") # save the document
备注
Taking it further
Use this to create the page with another pre-defined paper format:
w, h = pymupdf.paper_size("letter-l") # 'Letter' landscape
page = doc.new_page(width = w, height = h)
The convenience function paper_size() knows over 40 industry standard paper formats to choose from. To see them, inspect dictionary paperSizes. Pass the desired dictionary key to paper_size() to retrieve the paper dimensions. Upper and lower case is supported. If you append “-L” to the format name, the landscape version is returned.
Here is a 3-liner that creates a PDF: with one empty page. Its file size is 460 bytes:
doc = pymupdf.open()
doc.new_page()
doc.save("A4.pdf")
API reference
paperSizes
插入带有文本内容的页面#
Inserting Pages with Text Content
使用 Document.insert_page() 方法也可以插入一个新页面,并接受相同的 width 和 height 参数。此方法还允许在新页面中插入任意文本,并返回插入的行数。
import pymupdf
doc = pymupdf.open(...) # 打开一个新的或现有的PDF文档
n = doc.insert_page(-1, # 默认插入位置
text = "The quick brown fox jumped over the lazy dog",
fontsize = 11,
width = 595,
height = 842,
fontname = "Helvetica", # 默认字体
fontfile = None, # 可选的字体文件名
color = (0, 0, 0)) # 文字颜色 (RGB)
Using the Document.insert_page() method also inserts a new page and accepts the same width and height parameters. But it lets you also insert arbitrary text into the new page and returns the number of inserted lines.
import pymupdf
doc = pymupdf.open(...) # some new or existing PDF document
n = doc.insert_page(-1, # default insertion point
text = "The quick brown fox jumped over the lazy dog",
fontsize = 11,
width = 595,
height = 842,
fontname = "Helvetica", # default font
fontfile = None, # any font file name
color = (0, 0, 0)) # text color (RGB)
备注
Taking it further
The text parameter can be a (sequence of) string (assuming UTF-8 encoding). Insertion will start at Point (50, 72), which is one inch below top of page and 50 points from the left. The number of inserted text lines is returned.
API reference
拆分单页#
Splitting Single Pages
这涉及到将 PDF 页分割成任意的多个部分。例如,您可能有一个 PDF 文件,页面格式为 Letter,并希望以四倍放大因子打印:每一页分割成四个部分,每个部分将单独成为一个新的 PDF 页,格式仍为 Letter。
import pymupdf
src = pymupdf.open("test.pdf")
doc = pymupdf.open() # 创建一个空的输出PDF
for spage in src: # 遍历输入文档中的每一页
r = spage.rect # 输入页面的矩形区域
d = pymupdf.Rect(spage.cropbox_position, # 如果有裁剪框偏移,使用该偏移量
spage.cropbox_position) # 从 (0, 0) 开始
#--------------------------------------------------------------------------
# 示例:将输入页面切割成 2 x 2 的部分
#--------------------------------------------------------------------------
r1 = r / 2 # 左上矩形区域
r2 = r1 + (r1.width, 0, r1.width, 0) # 右上矩形区域
r3 = r1 + (0, r1.height, 0, r1.height) # 左下矩形区域
r4 = pymupdf.Rect(r1.br, r.br) # 右下矩形区域
rect_list = [r1, r2, r3, r4] # 将它们放入列表中
for rx in rect_list: # 遍历矩形列表
rx += d # 加上裁剪框偏移
page = doc.new_page(-1, # 使用 rx 尺寸创建新的输出页面
width = rx.width,
height = rx.height)
page.show_pdf_page(
page.rect, # 填充整个新页面
src, # 输入文档
spage.number, # 输入页面的页码
clip = rx, # 使用输入页面的哪部分
)
# 完成后保存输出文件
doc.save("poster-" + src.name,
garbage=3, # 去除重复对象
deflate=True, # 尽可能压缩文件
)
示例:

This deals with splitting up pages of a PDF in arbitrary pieces. For example, you may have a PDF with Letter format pages which you want to print with a magnification factor of four: each page is split up in 4 pieces which each going to a separate PDF page in Letter format again.
import pymupdf
src = pymupdf.open("test.pdf")
doc = pymupdf.open() # empty output PDF
for spage in src: # for each page in input
r = spage.rect # input page rectangle
d = pymupdf.Rect(spage.cropbox_position, # CropBox displacement if not
spage.cropbox_position) # starting at (0, 0)
#--------------------------------------------------------------------------
# example: cut input page into 2 x 2 parts
#--------------------------------------------------------------------------
r1 = r / 2 # top left rect
r2 = r1 + (r1.width, 0, r1.width, 0) # top right rect
r3 = r1 + (0, r1.height, 0, r1.height) # bottom left rect
r4 = pymupdf.Rect(r1.br, r.br) # bottom right rect
rect_list = [r1, r2, r3, r4] # put them in a list
for rx in rect_list: # run thru rect list
rx += d # add the CropBox displacement
page = doc.new_page(-1, # new output page with rx dimensions
width = rx.width,
height = rx.height)
page.show_pdf_page(
page.rect, # fill all new page with the image
src, # input document
spage.number, # input page number
clip = rx, # which part to use of input page
)
# that's it, save output file
doc.save("poster-" + src.name,
garbage=3, # eliminate duplicate objects
deflate=True, # compress stuff where possible
)
Example:
合并单页#
Combining Single Pages
这涉及到将 PDF 页面合并形成一个新的 PDF,其中每一页合并了两个或四个原始页面(也叫“2-up”,“4-up”等)。这可以用于创建小册子或缩略图式的概览。
import pymupdf
src = pymupdf.open("test.pdf")
doc = pymupdf.open() # 创建一个空的输出PDF
width, height = pymupdf.paper_size("a4") # A4 竖版输出页面格式
r = pymupdf.Rect(0, 0, width, height)
# 定义每页的 4 个矩形区域
r1 = r / 2 # 左上矩形区域
r2 = r1 + (r1.width, 0, r1.width, 0) # 右上矩形区域
r3 = r1 + (0, r1.height, 0, r1.height) # 左下矩形区域
r4 = pymupdf.Rect(r1.br, r.br) # 右下矩形区域
# 将它们放入一个列表中
r_tab = [r1, r2, r3, r4]
# 现在将输入页面复制到输出文档
for spage in src:
if spage.number % 4 == 0: # 创建新的输出页面
page = doc.new_page(-1,
width = width,
height = height)
# 将输入页面插入到正确的矩形区域
page.show_pdf_page(r_tab[spage.number % 4], # 选择输出矩形
src, # 输入文档
spage.number) # 输入页面的页码
# 使用垃圾回收和压缩保存新文件
doc.save("4up.pdf", garbage=3, deflate=True)
示例:

This deals with joining PDF pages to form a new PDF with pages each combining two or four original ones (also called “2-up”, “4-up”, etc.). This could be used to create booklets or thumbnail-like overviews.
import pymupdf
src = pymupdf.open("test.pdf")
doc = pymupdf.open() # empty output PDF
width, height = pymupdf.paper_size("a4") # A4 portrait output page format
r = pymupdf.Rect(0, 0, width, height)
# define the 4 rectangles per page
r1 = r / 2 # top left rect
r2 = r1 + (r1.width, 0, r1.width, 0) # top right
r3 = r1 + (0, r1.height, 0, r1.height) # bottom left
r4 = pymupdf.Rect(r1.br, r.br) # bottom right
# put them in a list
r_tab = [r1, r2, r3, r4]
# now copy input pages to output
for spage in src:
if spage.number % 4 == 0: # create new output page
page = doc.new_page(-1,
width = width,
height = height)
# insert input page into the correct rectangle
page.show_pdf_page(r_tab[spage.number % 4], # select output rect
src, # input document
spage.number) # input page number
# by all means, save new file using garbage collection and compression
doc.save("4up.pdf", garbage=3, deflate=True)
Example:
PDF 加密和解密#
PDF Encryption & Decryption
从版本 1.16.0 开始, PDF 解密和加密(使用密码)得到了完全支持。您可以执行以下操作:
检查文档是否受密码保护 /(仍然)加密 (
Document.needs_pass,Document.is_encrypted)。获取对文档的访问授权 (
Document.authenticate())。使用
Document.save()或Document.write()设置 PDF 文件的加密详情:解密或加密内容
设置密码
设置加密方法
设置权限详情
备注
一个 PDF 文档可能有两个不同的密码:
所有者密码 提供完全访问权限,包括更改密码、加密方法或权限详情。
用户密码 提供根据已设置的权限详情访问文档内容。如果存在,在查看器中打开 PDF 时需要提供该密码。
方法 Document.authenticate() 将自动根据使用的密码建立访问权限。
以下代码片段创建一个新的 PDF 并使用不同的用户和所有者密码进行加密。权限被授予打印、复制和注释,但使用用户密码的人员无法进行更改。
import pymupdf
text = "some secret information" # 保持该数据为秘密
perm = int(
pymupdf.PDF_PERM_ACCESSIBILITY # 始终使用此选项
| pymupdf.PDF_PERM_PRINT # 允许打印
| pymupdf.PDF_PERM_COPY # 允许复制
| pymupdf.PDF_PERM_ANNOTATE # 允许注释
)
owner_pass = "owner" # 所有者密码
user_pass = "user" # 用户密码
encrypt_meth = pymupdf.PDF_ENCRYPT_AES_256 # 最强加密算法
doc = pymupdf.open() # 空的 PDF
page = doc.new_page() # 空白页面
page.insert_text((50, 72), text) # 插入数据
doc.save(
"secret.pdf",
encryption=encrypt_meth, # 设置加密方法
owner_pw=owner_pass, # 设置所有者密码
user_pw=user_pass, # 设置用户密码
permissions=perm, # 设置权限
)
备注
进一步说明
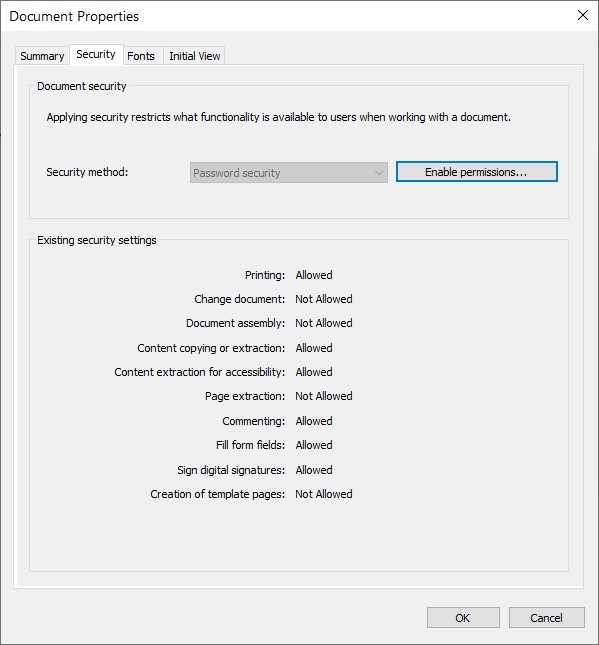
使用某些查看器(如 Nitro Reader 5)打开此文档将反映这些设置:
解密 将在保存时自动发生,如之前一样,如果没有提供加密参数。
要 保持 PDF 的加密方法,请使用 encryption=pymupdf.PDF_ENCRYPT_KEEP 来保存。如果 doc.can_save_incrementally() == True,也可以进行增量保存。
要 更改加密方法,请指定上述选项的完整范围(encryption、owner_pw、user_pw、permissions)。在这种情况下,不可能进行增量保存。
API 参考
Starting with version 1.16.0, PDF decryption and encryption (using passwords) are fully supported. You can do the following:
Check whether a document is password protected / (still) encrypted (
Document.needs_pass,Document.is_encrypted).Gain access authorization to a document (
Document.authenticate()).Set encryption details for PDF files using
Document.save()orDocument.write()anddecrypt or encrypt the content
set password(s)
set the encryption method
set permission details
备注
A PDF document may have two different passwords:
The owner password provides full access rights, including changing passwords, encryption method, or permission detail.
The user password provides access to document content according to the established permission details. If present, opening the PDF in a viewer will require providing it.
Method Document.authenticate() will automatically establish access rights according to the password used.
The following snippet creates a new PDF and encrypts it with separate user and owner passwords. Permissions are granted to print, copy and annotate, but no changes are allowed to someone authenticating with the user password.
import pymupdf
text = "some secret information" # keep this data secret
perm = int(
pymupdf.PDF_PERM_ACCESSIBILITY # always use this
| pymupdf.PDF_PERM_PRINT # permit printing
| pymupdf.PDF_PERM_COPY # permit copying
| pymupdf.PDF_PERM_ANNOTATE # permit annotations
)
owner_pass = "owner" # owner password
user_pass = "user" # user password
encrypt_meth = pymupdf.PDF_ENCRYPT_AES_256 # strongest algorithm
doc = pymupdf.open() # empty pdf
page = doc.new_page() # empty page
page.insert_text((50, 72), text) # insert the data
doc.save(
"secret.pdf",
encryption=encrypt_meth, # set the encryption method
owner_pw=owner_pass, # set the owner password
user_pw=user_pass, # set the user password
permissions=perm, # set permissions
)
备注
Taking it further
Opening this document with some viewer (Nitro Reader 5) reflects these settings:
Decrypting will automatically happen on save as before when no encryption parameters are provided.
To keep the encryption method of a PDF save it using encryption=pymupdf.PDF_ENCRYPT_KEEP. If doc.can_save_incrementally() == True, an incremental save is also possible.
To change the encryption method specify the full range of options above (encryption, owner_pw, user_pw, permissions). An incremental save is not possible in this case.
API reference
从 页面 中提取表格#
Extracting Tables from a Page
可以从任何文档 Page 中查找和提取表格。
import pymupdf
from pprint import pprint
doc = pymupdf.open("test.pdf") # 打开文档
page = doc[0] # 获取文档的第一页
tabs = page.find_tables() # 定位并提取页面上的表格
print(f"{len(tabs.tables)} found on {page}") # 显示找到的表格数量
if tabs.tables: # 至少找到一个表格?
pprint(tabs[0].extract()) # 打印第一个表格的内容
重要
还有 pdf2docx extract tables method,如果你更喜欢的话,它也可以提取表格。
Tables can be found and extracted from any document Page.
import pymupdf
from pprint import pprint
doc = pymupdf.open("test.pdf") # open document
page = doc[0] # get the 1st page of the document
tabs = page.find_tables() # locate and extract any tables on page
print(f"{len(tabs.tables)} found on {page}") # display number of found tables
if tabs.tables: # at least one table found?
pprint(tabs[0].extract()) # print content of first table
重要
There is also the pdf2docx extract tables method which is capable of table extraction if you prefer.
获取页面链接#
Getting Page Links
import pymupdf
for page in doc: # 遍历文档页面
link = page.first_link # 一个 `Link` 对象或 `None`
while link: # 遍历页面上的链接
# 对链接进行操作,然后:
link = link.next # 获取下一个链接,最后一个链接的 `next` 为 `None`
Links can be extracted from a Page to return Link objects.
import pymupdf
for page in doc: # iterate the document pages
link = page.first_link # a `Link` object or `None`
while link: # iterate over the links on page
# do something with the link, then:
link = link.next # get next link, last one has `None` in its `next`
从文档中获取所有注释#
Getting All Annotations from a Document
页面上的注释 (Annot) 可以通过 page.annots() 方法获取。
import pymupdf
for page in doc:
for annot in page.annots():
print(f'页面 {page.number} 上的注释,类型: {annot.type} 和矩形区域: {annot.rect}')
Annotations (Annot) on pages can be retrieved with the page.annots() method.
import pymupdf
for page in doc:
for annot in page.annots():
print(f'Annotation on page: {page.number} with type: {annot.type} and rect: {annot.rect}')
从 PDF 中删除内容#
Redacting content from a PDF
删除标记是特殊类型的注释,可以标记在文档页面上,表示页面中应安全删除的区域。在标记区域后,该区域将被标记为 删除标记 ,一旦删除标记被*应用*,内容将被安全删除。
例如,如果我们想删除文档中所有“Jane Doe”出现的实例,可以按如下方式操作:
import pymupdf
# 打开PDF文档
doc = pymupdf.open('test.pdf')
# 遍历文档中的每一页
for page in doc:
# 查找当前页中所有“Jane Doe”的实例
instances = page.search_for("Jane Doe")
# 删除当前页中每个“Jane Doe”的实例
for inst in instances:
page.add_redact_annot(inst)
# 对当前页应用删除标记
page.apply_redactions()
# 保存修改后的文档
doc.save('redacted_document.pdf')
# 关闭文档
doc.close()
另一个例子是对页面的某个区域进行删除标记,但不删除该区域内的任何线条艺术(即矢量图形),通过设置参数标志,如下所示:
import pymupdf
# 打开PDF文档
doc = pymupdf.open('test.pdf')
# 获取第一页
page = doc[0]
# 添加一个要删除标记的区域
rect = [0,0,200,200]
# 添加删除标记注释,使用红色填充
page.add_redact_annot(rect, fill=(1,0,0))
# 对当前页应用删除标记,但忽略矢量图形
page.apply_redactions(graphics=0)
# 保存修改后的文档
doc.save('redactied_document.pdf')
# 关闭文档
doc.close()
警告
一旦保存了删除标记版本的文档, PDF 中的删除内容将 无法恢复 。因此,文档中的删除区域将完全移除该区域的文本和图形内容。
备注
进一步了解
有几个选项可以在页面上创建和应用删除标记,关于这些选项的完整API详细信息以及控制这些选项的参数,请参考API文档。
API参考
Redactions are special types of annotations which can be marked onto a document page to denote an area on the page which should be securely removed. After marking an area with a rectangle then this area will be marked for redaction, once the redaction is applied then the content is securely removed.
For example if we wanted to redact all instances of the name “Jane Doe” from a document we could do the following:
import pymupdf
# Open the PDF document
doc = pymupdf.open('test.pdf')
# Iterate over each page of the document
for page in doc:
# Find all instances of "Jane Doe" on the current page
instances = page.search_for("Jane Doe")
# Redact each instance of "Jane Doe" on the current page
for inst in instances:
page.add_redact_annot(inst)
# Apply the redactions to the current page
page.apply_redactions()
# Save the modified document
doc.save('redacted_document.pdf')
# Close the document
doc.close()
Another example could be redacting an area of a page, but not to redact any line art (i.e. vector graphics) within the defined area, by setting a parameter flag as follows:
import pymupdf
# Open the PDF document
doc = pymupdf.open('test.pdf')
# Get the first page
page = doc[0]
# Add an area to redact
rect = [0,0,200,200]
# Add a redacction annotation which will have a red fill color
page.add_redact_annot(rect, fill=(1,0,0))
# Apply the redactions to the current page, but ignore vector graphics
page.apply_redactions(graphics=0)
# Save the modified document
doc.save('redactied_document.pdf')
# Close the document
doc.close()
警告
Once a redacted version of a document is saved then the redacted content in the PDF is irretrievable. Thus, a redacted area in a document removes text and graphics completely from that area.
备注
Taking it further
The are a few options for creating and applying redactions to a page, for the full API details to understand the parameters to control these options refer to the API reference.
API reference
转换 PDF 文档#
Converting PDF Documents
我们推荐使用 PyMuPDF 和 python-docx 库的 pdf2docx 库来提供从 PDF 到 DOCX 格式的简单文档转换。
We recommend the pdf2docx library which uses PyMuPDF and the python-docx library to provide simple document conversion from PDF to DOCX format.