使用 Python 处理地理空间数据库#
Working with geospatial databases using python
在本节中,我们将基于目前所学的知识编写一个简短的程序来 (i) 创建地理空间数据库、(ii) 从 Shapefile 导入数据、(iii) 对该数据执行空间查询以及 (iv) 以 WKT 格式保存结果。我们将使用本章中探讨的三个数据库编写相同的程序,以便您了解使用每个特定数据库所涉及的差异和问题。
In this section, we will build on what we’ve learned so far by writing a short program to (i) create a geospatial database, (ii) import data from a shapefile, (iii) perform a spatial query on that data, and (iv) save the results in WKT format. We will write the same program using each of the three databases we have explored in this chapter, so that you can see the differences and issues involved with using each particular database.
先决条件#
Prerequisites
在运行这些示例之前,你需要做以下几件事:
如果你还没有安装 MySQL、PostGIS 和 SpatiaLite,请按照本章之前给出的安装说明进行安装。
我们将使用《第4章:地理空间数据源》中的 GSHHS 海岸线数据集。如果你还没有下载此数据集,可以从以下链接下载 shapefile 文件:
从 GSHHS 海岸线数据集中获取低分辨率 (l) 的 shapefile 文件,并将它们放在一个方便的目录中(我们将此目录称为 GSHHS_l,代码示例中会用到这个目录)。
备注
我们将使用低分辨率的 shapefile 文件,以便管理数据量,并避免在 MySQL 中处理大多边形时触发 “Got a packet bigger than max_allowed_packet bytes” 错误。虽然 MySQL 确实支持大多边形(通过增加 max_allowed_packet 设置),但这样做超出了本章的范围。我们将在下一章学习更多关于该设置的内容。
Before you can run these examples, you will need to do the following:
If you haven’t already done so, follow the instructions given earlier in this chapter to install MySQL, PostGIS, and SpatiaLite onto your computer.
We will be working with the GSHHS shoreline dataset from Chapter 4, Sources of Geospatial Data. If you haven’t already downloaded this dataset, you can download the shapefiles from:
Take a copy of the l (low-resolution) shapefiles from the GSHHS shoreline dataset and place them in a convenient directory (we will call this directory GSHHS_l in the code samples shown here).
备注
We will use the low-resolution shapefiles to keep the amount of data manageable, and to avoid problems with large polygons triggering a “Got a packet bigger than max_allowed_packet bytes” error in MySQL. Large polygons are certainly supported by MySQL (by increasing the max_allowed_packet setting), but doing so is beyond the scope of this chapter. We’ll learn more about this setting in the next chapter.
使用 MySQL#
Working with MySQL
在这里,我们已经看到如何连接到 MySQL 并创建数据库表:
import MySQLdb
connection = MySQLdb.connect(user="..." passwd="...")
cursor = connection.cursor()
cursor.execute("DROP DATABASE IF EXISTS spatialTest")
cursor.execute("CREATE DATABASE spatialTest")
cursor.execute("USE spatialTest")
cursor.execute("""CREATE TABLE gshhs (
id INTEGER AUTO_INCREMENT,
level INTEGER,
geom POLYGON NOT NULL,
PRIMARY KEY (id)
INDEX (level),
SPATIAL INDEX (geom)) ENGINE=MyISAM
""")
connection.commit()
接下来,我们需要从 GSHHS shapefiles 中读取要素,并将其插入到数据库中:
import os.path
from osgeo import ogr
for level in [1, 2, 3, 4]:
fName = os.path.join("GSHHS_l", "GSHHS_l_L"+str(level)+".shp")
shapefile = ogr.Open(fName)
layer = shapefile.GetLayer(0)
for i in range(layer.GetFeatureCount()):
feature = layer.GetFeature(i)
geometry = feature.GetGeometryRef()
wkt = geometry.ExportToWkt()
cursor.execute("INSERT INTO gshhs (level, geom) " +
"VALUES (%s, GeomFromText(%s, 4326))",
(level, wkt))
connection.commit()
备注
请注意,在将要素导入数据库时,我们给它们分配了 SRID 值 (4326)。即使 MySQL 中没有 spatial_ref_sys 表,我们仍然遵循最佳实践,在数据库中存储 SRID 值。
现在我们希望查询数据库,查找我们想要的海岸线信息。在这种情况下,我们将获取伦敦的坐标,并搜索一个包含此点的 1 级(海洋边界)多边形。这将为我们提供英国的海岸线:
import shapely.wkt
LONDON = 'POINT(-0.1263 51.4980)'
cursor.execute("SELECT id,AsText(geom) FROM gshhs " +
"WHERE (level=%s) AND " +
"(MBRContains(geom, GeomFromText(%s, 4326)))",
(1, LONDON))
shoreline = None
for id,wkt in cursor:
polygon = shapely.wkt.loads(wkt)
point = shapely.wkt.loads(LONDON)
if polygon.contains(point):
shoreline = wkt
备注
请记住,MySQL 仅支持边界矩形查询,因此我们必须使用 Shapely 来确定点是否实际上在多边形内,而不仅仅是在其最小边界矩形内。
为了检查这个查询是否能够高效地运行,我们将按照推荐的最佳实践,询问 MySQL 查询优化器它将如何处理此查询:
% /usr/local/mysql/bin/mysql
mysql> use myDatabase;
mysql> EXPLAIN SELECT id,AsText(geom) FROM gshhs
WHERE (level=1) AND (MBRContains(geom,
GeomFromText('POINT(-0.1263 51.4980)',
4326)))\G
*********************** 1. row ***********************
id: 1
select_type: SIMPLE
table: gshhs
type: range
possible_keys: level,geom
key: geom
key_len: 34
ref: NULL
rows: 1
Extra: Using where
1 row in set (0.00 sec)
正如你所看到的,我们只是重新输入了查询,在前面加上了 EXPLAIN 并填写了参数,形成了一个有效的 SQL 语句。结果告诉我们,SELECT 查询确实在使用索引的 geom 列,这使得它能够快速找到所需的特征。
现在我们有了一个可以快速检索所需几何体的工作程序,我们将英国海岸线多边形保存到一个文本文件中:
f = file("uk-shoreline.wkt", "w")
f.write(shoreline)
f.close()
运行此程序将英国海岸线的低分辨率轮廓保存到 uk-shoreline.wkt 文件中:
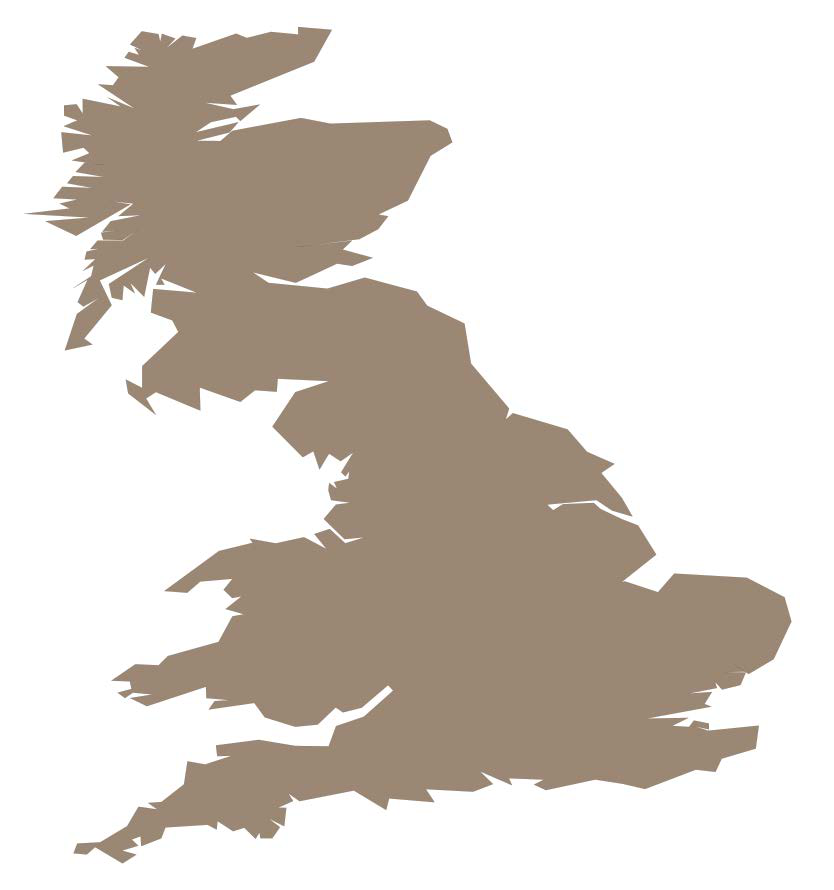
We have already seen how to connect to MySQL and create a database table:
import MySQLdb
connection = MySQLdb.connect(user="..." passwd="...")
cursor = connection.cursor()
cursor.execute("DROP DATABASE IF EXISTS spatialTest")
cursor.execute("CREATE DATABASE spatialTest")
cursor.execute("USE spatialTest")
cursor.execute("""CREATE TABLE gshhs (
id INTEGER AUTO_INCREMENT,
level INTEGER,
geom POLYGON NOT NULL,
PRIMARY KEY (id)
INDEX (level),
SPATIAL INDEX (geom)) ENGINE=MyISAM
""")
connection.commit()
We next need to read the features from the GSHHS shapefiles and insert them into the database:
import os.path
from osgeo import ogr
for level in [1, 2, 3, 4]:
fName = os.path.join("GSHHS_l", "GSHHS_l_L"+str(level)+".shp")
shapefile = ogr.Open(fName)
layer = shapefile.GetLayer(0)
for i in range(layer.GetFeatureCount()):
feature = layer.GetFeature(i)
geometry = feature.GetGeometryRef()
wkt = geometry.ExportToWkt()
cursor.execute("INSERT INTO gshhs (level, geom) " +
"VALUES (%s, GeomFromText(%s, 4326))",
(level, wkt))
connection.commit()
备注
Note that we are assigning an SRID value (4326) to the features as we import them into the database. Even though we don’t have a spatial_ref_sys table in MySQL, we are following the best practices by storing SRID values in the database.
We now want to query the database to find the shoreline information we want. In this case, we’ll take the coordinate for London and search for a level 1 (ocean boundary) polygon that contains this point. This will give us the shoreline for the United Kingdom:
import shapely.wkt
LONDON = 'POINT(-0.1263 51.4980)'
cursor.execute("SELECT id,AsText(geom) FROM gshhs " +
"WHERE (level=%s) AND " +
"(MBRContains(geom, GeomFromText(%s, 4326)))",
(1, LONDON))
shoreline = None
for id,wkt in cursor:
polygon = shapely.wkt.loads(wkt)
point = shapely.wkt.loads(LONDON)
if polygon.contains(point):
shoreline = wkt
备注
Remember that MySQL only supports bounding-rectangle queries, so we have to use Shapely to identify if the point is actually within the polygon, rather than just within its minimum bounding rectangle.
To check that this query can be run efficiently, we will follow the recommended best practice of asking the MySQL Query Optimizer what it will do with the query:
% /usr/local/mysql/bin/mysql
mysql> use myDatabase;
mysql> EXPLAIN SELECT id,AsText(geom) FROM gshhs
WHERE (level=1) AND (MBRContains(geom,
GeomFromText('POINT(-0.1263 51.4980)',
4326)))\G
*********************** 1. row ***********************
id: 1
select_type: SIMPLE
table: gshhs
type: range
possible_keys: level,geom
key: geom
key_len: 34
ref: NULL
rows: 1
Extra: Using where
1 row in set (0.00 sec)
As you can see, we simply retyped the query, adding the word EXPLAIN to the front and filling in the parameters to make a valid SQL statement. The result tells us that the SELECT query is indeed using the indexed geom column, allowing it to quickly find the desired feature.
Now that we have a working program that can quickly retrieve the desired geometry, let’s save the UK shoreline polygon to a text file:
f = file("uk-shoreline.wkt", "w")
f.write(shoreline)
f.close()
Running this program saves a low-resolution outline of the United Kingdom’s shoreline into the uk-shoreline.wkt file:
使用 PostGIS#
Working with PostGIS
让我们重写这个程序以使用 PostGIS。第一部分,我们打开数据库并定义 gshhs 表,几乎是完全相同的:
import psycopg2
connection = psycopg2.connect("dbname=... user=...")
cursor = connection.cursor()
cursor.execute("DROP TABLE IF EXISTS gshhs")
cursor.execute("""CREATE TABLE gshhs (
id
SERIAL,
level
INTEGER,
PRIMARY KEY (id))
""")
cursor.execute("CREATE INDEX levelIndex ON gshhs(level)")
cursor.execute("SELECT AddGeometryColumn('gshhs', " +
"'geom', 4326, 'POLYGON', 2)")
cursor.execute("CREATE INDEX geomIndex ON gshhs " +
"USING GIST (geom)")
connection.commit()
唯一的区别是我们必须使用 psycopg2 数据库适配器,并且我们必须将几何列(和空间索引)与 CREATE TABLE 语句分开创建。
第二部分,我们将数据从 shapefile 导入数据库,几乎与 MySQL 版本相同:
import os.path
from osgeo import ogr
for level in [1, 2, 3, 4]:
fName = os.path.join("GSHHS_l",
"GSHHS_l_L"+str(level)+".shp")
shapefile = ogr.Open(fName)
layer = shapefile.GetLayer(0)
for i in range(layer.GetFeatureCount()):
feature = layer.GetFeature(i)
geometry = feature.GetGeometryRef()
wkt = geometry.ExportToWkt()
cursor.execute("INSERT INTO gshhs (level, geom) " +
"VALUES (%s, ST_GeomFromText(%s, " +
"4326))", (level, wkt))
connection.commit()
现在我们已经将 shapefile 的内容导入数据库,我们需要在 PostGIS 中执行一项 MySQL 或 SpatiaLite 中不需要做的操作:我们需要运行 VACUUM ANALYZE 命令,以便 PostGIS 能够收集统计信息,帮助它优化我们的数据库查询:
old_level = connection.isolation_level
connection.set_isolation_level(0)
cursor.execute("VACUUM ANALYZE")
connection.set_isolation_level(old_level)
接下来,我们想根据伦敦的坐标搜索英国的海岸线。由于 PostGIS 会自动先进行边界框检查,再进行完整的多边形检查,所以这段代码比 MySQL 版本更简洁,我们不需要手动执行这些操作:
LONDON = 'POINT(-0.1263 51.4980)'
cursor.execute("SELECT id,ST_AsText(geom) FROM gshhs " +
"WHERE (level=%s) AND " +
"(ST_Contains(geom, ST_GeomFromText(%s, 4326)))",
(1, LONDON))
shoreline = None
for id,wkt in cursor:
shoreline = wkt
按照推荐的最佳实践,我们将请求 PostGIS 告诉我们它认为如何执行这个查询:
% usr/local/pgsql/bin/psql -U userName -d dbName
psql> EXPLAIN SELECT id,ST_AsText(geom) FROM gshhs
WHERE (level=2) AND (ST_Contains(geom,
ST_GeomFromText('POINT(-0.1263 51.4980)', 4326)));
QUERY PLAN
---------------------------------------------------------
Index Scan using geomindex on gshhs (cost=0.00..8.53 rows=1
width=673)
Index Cond: (geom && '0101000020E6100000ED0DBE30992AC0BF39B4C876BEB
F4940'::geometry)
Filter: ((level = 2) AND _st_contains(geom, '0101000020E6100000ED0D
BE30992AC0BF39B4C876BEBF4940'::geometry))
(3 rows)
这告诉我们,PostGIS 将通过扫描 geomindex 空间索引来回答此查询,首先使用 && 操作符按边界框过滤,然后调用 ST_Contains() 来检查多边形是否实际包含所需的点。
这正是我们希望看到的;数据库正在尽可能快速地处理此查询,同时仍然提供完全准确的结果。
现在我们已经得到了所需的海岸线多边形,让我们通过将该多边形的 WKT 表示保存到磁盘来完成我们的程序:
f = file("uk-shoreline.wkt", "w")
f.write(shoreline)
f.close()
与 MySQL 版本相同,运行此程序将创建 uk-shoreline.wkt 文件,其中包含英国海岸线的相同低分辨率轮廓。
Let’s rewrite this program to use PostGIS. The first part, where we open the database and define our gshhs table, is almost identical:
import psycopg2
connection = psycopg2.connect("dbname=... user=...")
cursor = connection.cursor()
cursor.execute("DROP TABLE IF EXISTS gshhs")
cursor.execute("""CREATE TABLE gshhs (
id
SERIAL,
level
INTEGER,
PRIMARY KEY (id))
""")
cursor.execute("CREATE INDEX levelIndex ON gshhs(level)")
cursor.execute("SELECT AddGeometryColumn('gshhs', " +
"'geom', 4326, 'POLYGON', 2)")
cursor.execute("CREATE INDEX geomIndex ON gshhs " +
"USING GIST (geom)")
connection.commit()
The only difference is that we have to use the psycopg2 database adapter, and the fact that we have to create the geometry column (and spatial index) separately from the CREATE TABLE statement itself.
The second part of this program where we import the data from the shapefile into the database is once again almost identical to the MySQL version:
import os.path
from osgeo import ogr
for level in [1, 2, 3, 4]:
fName = os.path.join("GSHHS_l",
"GSHHS_l_L"+str(level)+".shp")
shapefile = ogr.Open(fName)
layer = shapefile.GetLayer(0)
for i in range(layer.GetFeatureCount()):
feature = layer.GetFeature(i)
geometry = feature.GetGeometryRef()
wkt = geometry.ExportToWkt()
cursor.execute("INSERT INTO gshhs (level, geom) " +
"VALUES (%s, ST_GeomFromText(%s, " +
"4326))", (level, wkt))
connection.commit()
Now that we have brought the shapefile’s contents into the database, we need to do something in PostGIS that isn’t necessary with MySQL or SpatiaLite: we need to run a VACUUM ANALYZE command so that PostGIS can gather statistics to help it optimize our database queries:
old_level = connection.isolation_level
connection.set_isolation_level(0)
cursor.execute("VACUUM ANALYZE")
connection.set_isolation_level(old_level)
We next want to search for the UK shoreline based upon the coordinate for London. This code is simpler than the MySQL version, thanks to the fact that PostGIS automatically does the bounding box check followed by the full polygon check, so we don’t have to do this by hand:
LONDON = 'POINT(-0.1263 51.4980)'
cursor.execute("SELECT id,ST_AsText(geom) FROM gshhs " +
"WHERE (level=%s) AND " +
"(ST_Contains(geom, ST_GeomFromText(%s, 4326)))",
(1, LONDON))
shoreline = None
for id,wkt in cursor:
shoreline = wkt
Following the recommended best practices, we will ask PostGIS to tell us how it thinks this query will be performed:
% usr/local/pgsql/bin/psql -U userName -d dbName
psql> EXPLAIN SELECT id,ST_AsText(geom) FROM gshhs
WHERE (level=2) AND (ST_Contains(geom,
ST_GeomFromText('POINT(-0.1263 51.4980)', 4326)));
QUERY PLAN
---------------------------------------------------------
Index Scan using geomindex on gshhs (cost=0.00..8.53 rows=1
width=673)
Index Cond: (geom && '0101000020E6100000ED0DBE30992AC0BF39B4C876BEB
F4940'::geometry)
Filter: ((level = 2) AND _st_contains(geom, '0101000020E6100000ED0D
BE30992AC0BF39B4C876BEBF4940'::geometry))
(3 rows)
This tells us that PostGIS will answer this query by scanning through the geomindex spatial index, first filtering by bounding box (using the && operator), and then calling ST_Contains() to see if the polygon actually contains the desired point.
This is exactly what we were hoping to see; the database is processing this query as quickly as possible while still giving us completely accurate results.
Now that we have the desired shoreline polygon, let’s finish our program by saving the polygon’s WKT representation to disk:
f = file("uk-shoreline.wkt", "w")
f.write(shoreline)
f.close()
As with the MySQL version, running this program will create the uk-shoreline.wkt file containing the same low-resolution outline of the United Kingdom’s shoreline.
使用 SpatiaLite#
Working with SpatiaLite
让我们再次重写这个程序,这次使用 SpatiaLite。正如前面讨论的,我们将创建一个数据库文件,然后调用 InitSpatialMetaData() 函数。这将创建并设置我们的空间数据库。
import os, os.path
from pysqlite2 import dbapi2 as sqlite
if os.path.exists("gshhs-spatialite.db"):
os.remove("gshhs-spatialite.db")
db = sqlite.connect("gshhs-spatialite.db")
db.enable_load_extension(True)
db.execute('SELECT load_extension("libspatialite.dll")')
cursor = db.cursor()
cursor.execute("SELECT InitSpatialMetaData()")
备注
如果你正在使用 Mac OS X,你可以跳过 db.enable_load_extension(…) 和 db.execute(‘SELECT load_extension(…)’) 语句。
接下来,我们需要创建我们的数据库表。这与 PostGIS 版本几乎相同:
cursor.execute("DROP TABLE IF EXISTS gshhs")
cursor.execute("CREATE TABLE gshhs (" +
"id INTEGER PRIMARY KEY AUTOINCREMENT, " +
"level INTEGER)")
cursor.execute("CREATE INDEX gshhs_level on gshhs(level)")
cursor.execute("SELECT AddGeometryColumn('gshhs', 'geom', " +
"4326, 'POLYGON', 2)")
cursor.execute("SELECT CreateSpatialIndex('gshhs', 'geom')")
db.commit()
将 shapefile 的内容加载到数据库中几乎与其他版本的程序相同:
import os.path
from osgeo import ogr
for level in [1, 2, 3, 4]:
fName = os.path.join("GSHHS_l",
"GSHHS_l_L"+str(level)+".shp")
shapefile = ogr.Open(fName)
layer = shapefile.GetLayer(0)
for i in range(layer.GetFeatureCount()):
feature = layer.GetFeature(i)
geometry = feature.GetGeometryRef()
wkt = geometry.ExportToWkt()
cursor.execute("INSERT INTO gshhs (level, geom) " +
"VALUES (?, GeomFromText(?, 4326))",
(level, wkt))
db.commit()
我们现在到达了想要在数据库中搜索所需多边形的部分。以下是如何在 SpatiaLite 中执行此操作:
import shapely.wkt
LONDON = 'POINT(-0.1263 51.4980)'
pt = shapely.wkt.loads(LONDON)
cursor.execute("SELECT id,level,AsText(geom) " +
"FROM gshhs WHERE id IN " +
"(SELECT pkid FROM idx_gshhs_geom" +
" WHERE xmin <= ? AND ? <= xmax" +
" AND ymin <= ? and ? <= ymax) " +
"AND Contains(geom, GeomFromText(?, 4326))",
(pt.x, pt.x, pt.y, pt.y, LONDON))
shoreline = None
for id,level,wkt in cursor:
if level == 1:
shoreline = wkt
由于 SpatiaLite 的查询优化器默认不使用空间索引,我们必须在查询中显式地包含 idx_gshhs_geom 索引。不过,注意这次我们没有使用 Shapely 提取多边形来检查点是否位于其中。而是直接使用 SpatiaLite 的 Contains() 函数,在查询中完成完整的多边形检查,在使用空间索引进行边界框检查之后。
这个查询比较复杂,但理论上应该能产生快速且准确的结果。按照推荐的最佳实践,我们想通过询问 SpatiaLite 的查询优化器,了解查询是如何被处理的。这将告诉我们是否写对了查询。
不幸的是,取决于你的 SpatiaLite 安装方式,你可能无法访问 SQLite 命令行。所以我们改为在 Python 中调用 EXPLAIN QUERY PLAN 命令:
cursor.execute("EXPLAIN QUERY PLAN " +
"SELECT id,level,AsText(geom) " +
"FROM gshhs WHERE id IN " +
"(SELECT pkid FROM idx_gshhs_geom" +
" WHERE xmin <= ? AND ? <= xmax" +
" AND ymin <= ? and ? <= ymax) " +
"AND Contains(geom, GeomFromText(?, 4326))",
(pt.x, pt.x, pt.y, pt.y, LONDON))
for row in cursor:
print row
运行这段代码会告诉我们,SpatiaLite 查询优化器将使用空间索引(以及表的主键)通过边界框快速识别匹配的特征:
(0, 0, 0, 'SEARCH TABLE gshhs USING PRIMARY KEY (rowid=?) (~12 rows)')
(0, 0, 0, 'EXECUTE LIST SUBQUERY 1')
(1, 0, 0, 'SCAN TABLE idx_gshhs_geom VIRTUAL TABLE INDEX 2:BaDbBcDd (~0
rows)')
备注
注意,SpatiaLite 中有一个 bug,导致它在同一查询中无法同时使用空间索引和普通的 B*Tree 索引。这就是为什么我们的 Python 程序要求 SpatiaLite 返回 level 值,然后在识别海岸线之前显式检查 level,而不是直接在查询中嵌入 AND (level=1) 的原因。
现在我们已经得到了海岸线,将其保存到文本文件中再次变得非常简单:
f = file("uk-shoreline.wkt", "w")
f.write(shoreline)
f.close()
Let’s rewrite this program once more, this time to use SpatiaLite. As discussed earlier, we will create a database file and then call the InitSpatialMetaData() function. This will create and set up our spatial database.
import os, os.path
from pysqlite2 import dbapi2 as sqlite
if os.path.exists("gshhs-spatialite.db"):
os.remove("gshhs-spatialite.db")
db = sqlite.connect("gshhs-spatialite.db")
db.enable_load_extension(True)
db.execute('SELECT load_extension("libspatialite.dll")')
cursor = db.cursor()
cursor.execute("SELECT InitSpatialMetaData()")
备注
If you are running on Mac OS X, you can skip the db.enable_load_extension(…) and db.execute(‘SELECT load_extension(…)’) statements.
We next need to create our database table. This is done in almost exactly the same way as our PostGIS version:
cursor.execute("DROP TABLE IF EXISTS gshhs")
cursor.execute("CREATE TABLE gshhs (" +
"id INTEGER PRIMARY KEY AUTOINCREMENT, " +
"level INTEGER)")
cursor.execute("CREATE INDEX gshhs_level on gshhs(level)")
cursor.execute("SELECT AddGeometryColumn('gshhs', 'geom', " +
"4326, 'POLYGON', 2)")
cursor.execute("SELECT CreateSpatialIndex('gshhs', 'geom')")
db.commit()
Loading the contents of the shapefile into the database is almost the same as the other versions of our program:
import os.path
from osgeo import ogr
for level in [1, 2, 3, 4]:
fName = os.path.join("GSHHS_l",
"GSHHS_l_L"+str(level)+".shp")
shapefile = ogr.Open(fName)
layer = shapefile.GetLayer(0)
for i in range(layer.GetFeatureCount()):
feature = layer.GetFeature(i)
geometry = feature.GetGeometryRef()
wkt = geometry.ExportToWkt()
cursor.execute("INSERT INTO gshhs (level, geom) " +
"VALUES (?, GeomFromText(?, 4326))",
(level, wkt))
db.commit()
We’ve now reached the point where we want to search through the database for the desired polygon. Here is how we can do this in SpatiaLite:
import shapely.wkt
LONDON = 'POINT(-0.1263 51.4980)'
pt = shapely.wkt.loads(LONDON)
cursor.execute("SELECT id,level,AsText(geom) " +
"FROM gshhs WHERE id IN " +
"(SELECT pkid FROM idx_gshhs_geom" +
" WHERE xmin <= ? AND ? <= xmax" +
" AND ymin <= ? and ? <= ymax) " +
"AND Contains(geom, GeomFromText(?, 4326))",
(pt.x, pt.x, pt.y, pt.y, LONDON))
shoreline = None
for id,level,wkt in cursor:
if level == 1:
shoreline = wkt
Because SpatiaLite’s query optimizer doesn’t use spatial indexes by default, we have to explicitly included the idx_gshhs_geom index in our query. Notice, however, that this time we aren’t using Shapely to extract the polygon to see if the point is within it. Instead, we are using SpatiaLite’s Contains() function directly to do the full polygon check directly within the query itself, after doing the bounding-box check using the spatial index.
This query is complex, but in theory should produce a fast and accurate result. Following the recommended best practice, we want to check our query by asking SpatiaLite’s query optimizer how the query will be processed. This will tell us if we have written the query correctly.
Unfortunately, depending on how your copy of SpatiaLite was installed, you may not have access to the SQLite command line. So instead, let’s call the EXPLAIN QUERY PLAN command from Python:
cursor.execute("EXPLAIN QUERY PLAN " +
"SELECT id,level,AsText(geom) " +
"FROM gshhs WHERE id IN " +
"(SELECT pkid FROM idx_gshhs_geom" +
" WHERE xmin <= ? AND ? <= xmax" +
" AND ymin <= ? and ? <= ymax) " +
"AND Contains(geom, GeomFromText(?, 4326))",
(pt.x, pt.x, pt.y, pt.y, LONDON))
for row in cursor:
print row
Running this tells us that the SpatiaLite query optimizer will use the spatial index (along with the table’s primary key) to quickly identify the features that match by bounding box:
(0, 0, 0, 'SEARCH TABLE gshhs USING PRIMARY KEY (rowid=?) (~12 rows)')
(0, 0, 0, 'EXECUTE LIST SUBQUERY 1')
(1, 0, 0, 'SCAN TABLE idx_gshhs_geom VIRTUAL TABLE INDEX 2:BaDbBcDd (~0
rows)')
备注
Note that there is a bug in SpatiaLite that prevents it from using both a spatial index and an ordinary B*Tree index in the same query. This is why our Python program asks SpatiaLite to return the level value, and then checks for the level explicitly before identifying the shoreline, rather than simply embedding AND (level=1) in the query itself.
Now that we have the shoreline, saving it to a text file is again trivial:
f = file("uk-shoreline.wkt", "w")
f.write(shoreline)
f.close()
比较数据库#
Comparing the databases
现在,我们已经看过了如何使用这三种开源空间数据库来实现我们的程序,我们可以开始对这些数据库做出一些结论:
MySQL 设置和使用都非常简便,广泛部署,并且可以作为一个强大的空间数据库使用,尽管它确实存在一些限制,需要通过变通方法来解决。
PostGIS 是开源地理空间数据库的工作马。它快速且具有良好的扩展性,功能比我们审查的其他数据库更强大。同时,PostGIS 因为设置和管理较为复杂而闻名,对于某些应用来说可能是“过度设计”。
SpatiaLite 速度快,功能强大,尽管它使用起来有些复杂,并且有一些缺陷和 bug。
选择使用哪个数据库,当然取决于你想实现的目标,以及你在特定服务器上可以使用的工具等因素,还要考虑你个人对这些数据库的偏好。无论选择哪个数据库,你都可以放心地相信它能够满足你的空间数据库需求。
Now that we have seen how our program is implemented using each of the three open source spatial databases, we can start to draw some conclusions about these databases:
MySQL is easy to set up and use, is widely deployed, and can be used as a capable spatial database, though it does suffer from some limitations which require work-arounds.
PostGIS is the workhorse of open-source geospatial databases. It is fast and scales well, and has more capabilities than any of the other databases we have examined. At the same time, PostGIS has a reputation for being hard to set up and administer, and may be overkill for some applications.
SpatiaLite is fast and capable, though it is tricky to use well and has its fair share of quirks and bugs.
Which database you choose to use, of course, depends on what you are trying to achieve, as well as factors such as which tools you have access to on your particular server, and your personal preference for which of these databases you want to work with. Whichever database you choose, you can be confident that it is more than capable of meeting your spatial database needs.