前言
Alembic is a lightweight database migration tool for usage with the SQLAlchemy Database Toolkit for Python.
Alembic 是一种轻量级数据库迁移工具,可与Python的 SQLAlchemy 数据库库工具包一起使用。
Front Matter (指南)
Information about the Alembic project.
有关 Alembic 项目的信息。
Project Homepage (项目主页)
Alembic is hosted on GitHub at https://github.com/sqlalchemy/alembic under the SQLAlchemy organization.
Alembic 托管在 GitHub 上,网址为 https://github.com/sqlalchemy/alembic,隶属于 SQLAlchemy 组织。
Releases and project status are available on Pypi at https://pypi.python.org/pypi/alembic.
发布和项目状态可在 Pypi 上获取,网址为 https://pypi.python.org/pypi/alembic。
The most recent published version of this documentation should be at https://alembic.sqlalchemy.org.
本文档的最新发布版本位于 https://alembic.sqlalchemy.org。
Installation (安装)
While Alembic can be installed system wide, it’s more common that it’s installed local to a virtual environment , as it also uses libraries such as SQLAlchemy and database drivers that are more appropriate for local installations.
虽然 Alembic 可以在系统范围内安装,但更常见的是将其安装在本地虚拟环境中,因为它还使用更适合本地安装的 SQLAlchemy 和数据库驱动程序等库。
The documentation below is only one kind of approach to installing Alembic for a project; there are many such approaches. The documentation below is provided only for those users who otherwise have no specific project setup chosen.
下面的文档只是为项目安装 Alembic 的一种方法; 有很多这样的方法。 下面的文档仅提供给那些没有选择特定项目设置的用户。
To build a virtual environment for a specific project, first we assume that Python virtualenv is installed systemwide. Then:
要为特定项目构建虚拟环境,首先我们假设 Python virtualenv 已安装在系统范围内。 然后:
cd /path/to/your/project
virtualenv .venv
There is now a Python interpreter that you can access in /path/to/your/project/.venv/bin/python, as well as the pip installer tool in /path/to/your/project/.venv/bin/pip.
现在有一个 Python 解释器,您可以在
/path/to/your/project/.venv/bin/python中访问,以及/path/to/your/project/.venv/bin/pip中的 pip 安装程序工具.
We now install Alembic as follows:
我们现在按如下方式安装 Alembic:
/path/to/your/project/.venv/bin/pip install alembic
The install will add the alembic command to the virtual environment. All operations with Alembic in terms of this specific virtual environment will then proceed through the usage of this command, as in:
安装会将 alembic 命令添加到虚拟环境中。 然后,在此特定虚拟环境中使用 Alembic 的所有操作都将通过使用此命令进行,如下所示:
/path/to/your/project/.venv/bin/alembic init .
The next step is optional. If our project itself has a setup.py file, we can also install it in the local virtual environment in editable mode:
下一步是可选的。 如果我们的项目本身有setup.py文件,我们也可以在本地虚拟环境中以可编辑的模式安装:
/path/to/your/project/.venv/bin/pip install -e .
If we don’t “install” the project locally, that’s fine as well; the default alembic.ini file includes a directive prepend_sys_path = . so that the local path is also in sys.path. This allows us to run the alembic command line tool from this directory without our project being “installed” in that environment.
如果我们不在本地“安装”项目,那也没关系; 默认的 alembic.ini 文件包含一个指令
prepend_sys_path = .这样本地路径也在sys.path中。 这允许我们从该目录运行 alembic 命令行工具,而无需在该环境中“安装”我们的项目。
Changed in version 1.5.5: Fixed a long-standing issue where the
alembiccommand-line tool would not preserve the defaultsys.pathof.by implementingprepend_sys_pathoption.
1.5.5版本更新: 修复了一个长期存在的问题,即 alembic 命令行工具不会通过实现
prepend_sys_path选项来保留当前目录(.)在sys.path中。
As a final step, the virtualenv activate tool can be used so that the alembic command is available without any path information, within the context of the current shell:
作为最后一步,可以使用 virtualenv activate 工具,以便在当前 shell 的上下文中无需任何路径信息即可使用
alembic命令:
source /path/to/your/project/.venv/bin/activate
Dependencies (依赖)
Alembic’s install process will ensure that SQLAlchemy is installed, in addition to other dependencies. Alembic will work with SQLAlchemy as of version 1.3.0.
除了其他依赖项外,Alembic 安装过程将确保安装 SQLAlchemy。 从 1.3.0 版本开始,Alembic 将与 SQLAlchemy 一起使用。
Changed in version 1.5.0: Support for SQLAlchemy older than 1.3.0 was dropped.
版本1.5.0更新: 不再支持 1.3.0 版本之前的 SQLAlchemy。
Alembic supports Python versions 3.6 and above
Alembic 支持 Python 3.6 及以上版本
Changed in version 1.7: Alembic now supports Python 3.6 and newer; support for Python 2.7 has been dropped.
版本1.7更新: Alembic 现在支持 Python 3.6 及更新的版本; 已取消对 Python 2.7 的支持。
Community (社区)
Alembic is developed by Mike Bayer, and is loosely associated with the SQLAlchemy, Pylons, and Openstack projects.
Alembic 由 Mike Bayer 开发,与 SQLAlchemy、Pylons 和 Openstack 项目松散关联。
User issues, discussion of potential bugs and features should be posted to the Alembic Google Group at sqlalchemy-alembic.
用户问题、潜在错误和功能的讨论应发布到 Alembic 在 Google Group群组上的 sqlalchemy-alembic。
Bugs (问题)
Bugs and feature enhancements to Alembic should be reported on the GitHub issue tracker.
应在 GitHub issue tracker 上报告 Alembic 的错误和功能加强。
Tutorial
指南
Alembic provides for the creation, management, and invocation of change management scripts for a relational database, using SQLAlchemy as the underlying engine. This tutorial will provide a full introduction to the theory and usage of this tool.
Alembic 使用 SQLAlchemy 作为底层引擎,为关系数据库提供变更管理脚本的创建、管理和调用。 本教程将全面介绍该工具的理论和用法。
To begin, make sure Alembic is installed as described at Installation. As stated in the linked document, it is usually preferable that Alembic is installed in the same module / Python path as that of the target project, usually using a Python virtual environment, so that when the alembic command is run, the Python script which is invoked by alembic, namely your project’s env.py script, will have access to your application’s models. This is not strictly necessary in all cases, however in the vast majority of cases is usually preferred.
首先,请确保按照 安装 中的说明安装
Alembic。 如文档中所述,通常最好将Alembic安装在与目标项目相同的 / Python 路径的模块中,通常使用Python 虚拟环境,以便在运行 alembic 命令时,Python 脚本 由 alembic 调用,即你项目的env.py脚本,将可以访问您的应用程序模型。 这并非在所有情况下都严格必要,但在绝大多数情况下通常是首选。
The tutorial below assumes the alembic command line utility is present in the local path and when invoked, will have access to the same Python module environment as that of the target project.
下面的教程假设
alembic命令行实用程序存在于本地路径中,并且在调用时,将可以访问与目标项目相同的 Python 模块环境。
迁移环境
Usage of Alembic starts with creation of the Migration Environment. This is a directory of scripts that is specific to a particular application. The migration environment is created just once, and is then maintained along with the application’s source code itself. The environment is created using the init command of Alembic, and is then customizable to suit the specific needs of the application.
使用 Alembic 从创建迁移环境开始。这是独立于应用程序的特别脚本目录。迁移环境只创建一次,然后与应用程序的源代码本身一起维护。该环境是使用 Alembic 的
init命令创建的,然后可以自定义以满足应用程序的特别需求。
The structure of this environment, including some generated migration scripts, looks like:
这个环境的结构,包括一些生成的迁移脚本,看起来像:
yourproject/
alembic/
env.py
README
script.py.mako
versions/
3512b954651e_add_account.py
2b1ae634e5cd_add_order_id.py
3adcc9a56557_rename_username_field.py
The directory includes these directories/files:
该目录包括以下目录/文件:
-
yourproject - this is the root of your application’s source code, or some directory within it.
-
yourproject - 这是应用程序源代码的根目录,或其中的某个目录。
-
alembic - this directory lives within your application’s source tree and is the home of the migration environment. It can be named anything, and a project that uses multiple databases may even have more than one.
-
alembic - 该目录位于应用程序的源代码树中,是迁移环境的主目录。 它可以命名为任何名称,一个使用多个数据库的项目甚至可能有多个。
-
env.py - This is a Python script that is run whenever the alembic migration tool is invoked. At the very least, it contains instructions to configure and generate a SQLAlchemy engine, procure a connection from that engine along with a transaction, and then invoke the migration engine, using the connection as a source of database connectivity.
-
env.py - 这是一个 Python 脚本,只要调用 alembic 迁移工具就会运行。至少,它包含配置和生成 SQLAlchemy 引擎的指令,从该引擎获取连接以及事务,然后调用迁移引擎,使用该连接作为数据库连接的来源。
The
env.pyscript is part of the generated environment so that the way migrations run is entirely customizable. The exact specifics of how to connect are here, as well as the specifics of how the migration environment are invoked. The script can be modified so that multiple engines can be operated upon, custom arguments can be passed into the migration environment, application-specific libraries and models can be loaded in and made available.env.py脚本是生成环境的一部分,因此迁移运行的方式是完全可定制的。 如何连接的确切细节在这里,以及如何调用迁移环境的细节。 可以修改脚本以便可以操作多个引擎,可以将自定义参数传递到迁移环境中,可以加载特定于应用程序的库和模型并使其可用。Alembic includes a set of initialization templates which feature different varieties of
env.pyfor different use cases.Alembic 包含一组初始化模板,其中包含针对不同用例的不同类型的
env.py。 -
README - included with the various environment templates, should have something informative.
-
README - 包含在各种环境模板中,应该有的一些说明信息。
-
script.py.mako - This is a Mako template file which is used to generate new migration scripts. Whatever is here is used to generate new files within
versions/. This is scriptable so that the structure of each migration file can be controlled, including standard imports to be within each, as well as changes to the structure of theupgrade()anddowngrade()functions. For example, themultidbenvironment allows for multiple functions to be generated using a naming schemeupgrade_engine1(),upgrade_engine2(). -
script.py.mako - 这是一个 Mako 模板文件,用于生成新的迁移脚本。 这里的任何内容都用于在
versions/中生成新文件。 这是可编的写脚本,因此可以控制每个迁移文件的结构,包括每个迁移文件中的标准导入,以及对upgrade()和downgrade()函数结构的更改。 例如,多数据库(multidb)环境允许使用命名方案upgrade_engine1()、upgrade_engine2()生成多个函数。 -
versions/ - This directory holds the individual version scripts. Users of other migration tools may notice that the files here don’t use ascending integers, and instead use a partial GUID approach. In Alembic, the ordering of version scripts is relative to directives within the scripts themselves, and it is theoretically possible to “splice” version files in between others, allowing migration sequences from different branches to be merged, albeit carefully by hand.
-
versions/ 该目录包含各个版本的脚本。 其他迁移工具的用户可能会注意到这里的文件不使用升序整数,而是使用部分 GUID 方法。 在 Alembic 中,版本脚本的排序与脚本本身内的指令相关,理论上可以在其他版本文件之间“拼接”版本文件,允许合并来自不同分支的迁移序列,尽管需要小心的手动合并。
Creating an Environment
创建环境
With a basic understanding of what the environment is, we can create one using alembic init. This will create an environment using the “generic” template:
对环境是什么有了基本的了解后,我们可以使用 alembic init 创建一个。 这将使用“通用(generic)”模板创建一个环境:
cd /path/to/yourproject
source /path/to/yourproject/.venv/bin/activate # assuming a local virtualenv (激活一个本地环境)
alembic init alembic
Where above, the init command was called to generate a migrations directory called alembic:
在上面的地方,调用了 init 命令来生成一个名为 alembic 的迁移目录:
Creating directory /path/to/yourproject/alembic...done
Creating directory /path/to/yourproject/alembic/versions...done
Generating /path/to/yourproject/alembic.ini...done
Generating /path/to/yourproject/alembic/env.py...done
Generating /path/to/yourproject/alembic/README...done
Generating /path/to/yourproject/alembic/script.py.mako...done
Please edit configuration/connection/logging settings in '/path/to/yourproject/alembic.ini' before proceeding.
Alembic also includes other environment templates. These can be listed out using the list_templates command:
Alembic 还包括其他环境模板。 这些可以使用 list_templates 命令列出:
$ alembic list_templates
Available templates:
generic - Generic single-database configuration.
async - Generic single-database configuration with an async dbapi.
multidb - Rudimentary multi-database configuration.
pylons - Configuration that reads from a Pylons project environment.
Templates are used via the 'init' command, e.g.:
alembic init --template pylons ./scripts
Editing the .ini File
编辑.ini文件
Alembic placed a file alembic.ini into the current directory. This is a file that the alembic script looks for when invoked. This file can exist in a different directory, with the location to it specified by either the --config option for the alembic runner or the ALEMBIC_CONFIG environment variable (the former takes precedence).
Alembic 将文件
alembic.ini放入当前目录。 这是alembic脚本在调用时查找的文件。 该文件可以存在于不同的目录中,其位置由 alembic runner 的--config选项或ALEMBIC_CONFIG环境变量(前者优先)指定。
The file generated with the “generic” configuration looks like:
使用“通用(generic)”配置生成的文件如下所示:
# A generic, single database configuration.
# 通用的单一数据库配置。
[alembic]
# path to migration scripts
# 迁移脚本的路径
script_location = alembic
# template used to generate migration files
# 用于生成迁移文件的模板
# file_template = %%(rev)s_%%(slug)s
# sys.path path, will be prepended to sys.path if present.
# defaults to the current working directory.
# (new in 1.5.5)
# sys.path 路径,如果存在,将被添加到 sys.path 之前。
# 默认为当前工作目录。
# 版本1.5.5中新增
prepend_sys_path = .
# timezone to use when rendering the date within the migration file
# as well as the filename.
# If specified, requires the python-dateutil library that can be
# installed by adding `alembic[tz]` to the pip requirements
# string value is passed to dateutil.tz.gettz()
# leave blank for localtime
# 在迁移文件中呈现日期以及文件名时要使用的时区。
# 如果指定,则需要可以通过将 `alembic[tz]` 添加到 pip 要求来安装的 python-dateutil 库
# 字符串值将传递给 dateutil.tz.gettz()
# 本地时间留空
# timezone =
# max length of characters to apply to the
# "slug" field
# 应用于“slug”字段的最大字符长度
# truncate_slug_length = 40
# set to 'true' to run the environment during
# the 'revision' command, regardless of autogenerate
# 设置为 'true' 以在 'revision' 命令期间运行环境,而无论是否自动生成
# revision_environment = false
# set to 'true' to allow .pyc and .pyo files without
# a source .py file to be detected as revisions in the
# versions/ directory
# 设置为“true”以允许将没有源 .py 文件的 .pyc 和 .pyo 文件检测为 `versions/` 目录中的版本文件
# sourceless = false
# version location specification; This defaults
# to ${script_location}/versions. When using multiple version
# directories, initial revisions must be specified with --version-path.
# The path separator used here should be the separator specified by "version_path_separator" below.
# 版本位置规范; 这默认为`${script_location}/versions`。 使用多个版本目录时,必须使用 --version-path 指定初始版本。
# 这里使用的路径分隔符应该是下面“version_path_separator”指定的分隔符。
# version_locations = %(here)s/bar:%(here)s/bat:${script_location}/versions
# version path separator; As mentioned above, this is the character used to split
# version_locations. The default within new alembic.ini files is "os", which uses os.pathsep.
# If this key is omitted entirely, it falls back to the legacy behavior of splitting on spaces and/or commas.
# Valid values for version_path_separator are:
#
# 版本路径分隔符; 如上所述,这是用于拆分 version_locations 的字符。 新 alembic.ini 文件中的默认值是“os”,它使用 os.pathsep。
# 如果这个键被完全省略,它会退回到在空格和/或逗号上分割的传统行为。
# version_path_separator 的有效值为:
#
# version_path_separator = :
# version_path_separator = ;
# version_path_separator = space
version_path_separator = os # Use os.pathsep. Default configuration used for new projects. (使用 os.pathsep。 用于新项目的默认配置。)
# the output encoding used when revision files
# are written from script.py.mako
# 从 script.py.mako 写入修订文件时使用的输出编码
# output_encoding = utf-8
; sqlalchemy.url = driver://user:pass@localhost/dbname
sqlalchemy.url = postgresql://wangchao:@localhost/test
# [post_write_hooks]
# This section defines scripts or Python functions that are run
# on newly generated revision scripts. See the documentation for further
# detail and examples
# 本节定义在新生成的修订脚本上运行的脚本或 Python 函数。 有关更多详细信息和示例,请参阅文档
# format using "black" - use the console_scripts runner,
# against the "black" entrypoint
# 使用“black”格式 - 使用 console_scripts runner,针对“black”入口点
# hooks = black
# black.type = console_scripts
# black.entrypoint = black
# black.options = -l 79 REVISION_SCRIPT_FILENAME
# Logging configuration
# 日志记录配置
[loggers]
keys = root,sqlalchemy,alembic
[handlers]
keys = console
[formatters]
keys = generic
[logger_root]
level = WARN
handlers = console
qualname =
[logger_sqlalchemy]
level = WARN
handlers =
qualname = sqlalchemy.engine
[logger_alembic]
level = INFO
handlers =
qualname = alembic
[handler_console]
class = StreamHandler
args = (sys.stderr,)
level = NOTSET
formatter = generic
[formatter_generic]
format = %(levelname)-5.5s [%(name)s] %(message)s
datefmt = %H:%M:%S
The file is read using Python’s ConfigParser.SafeConfigParser object. The %(here)s variable is provided as a substitution variable, which can be used to produce absolute pathnames to directories and files, as we do above with the path to the Alembic script location.
该文件是使用 Python 的 ConfigParser.SafeConfigParser 对象读取的。 %(here)s 变量作为替代变量提供,可用于生成目录和文件的绝对路径名,就像我们上面对 Alembic 脚本位置的路径所做的那样。
This file contains the following features:
该文件包含以下功能:
-
[alembic] - this is the section read by Alembic to determine configuration. Alembic itself does not directly read any other areas of the file. The name “alembic” can be customized using the --name commandline flag; see Run Multiple Alembic Environments from one .ini file for a basic example of this.
-
[alembic] - 这是 Alembic 读取的用于确定配置的部分。 Alembic 本身不直接读取文件的任何其他区域。 可以使用 --name 命令行标志自定义名称“alembic”; 有关此操作的基本示例,请参阅从一个 .ini 文件运行多个 Alembic 环境。
-
script_location - this is the location of the Alembic environment. It is normally specified as a filesystem location, either relative or absolute. If the location is a relative path, it’s interpreted as relative to the current directory.
-
script_location - 这是 Alembic 环境的位置。 它通常被指定为相对或绝对的文件系统位置。 如果位置是相对路径,则将其解释为相对于当前目录。
This is the only key required by Alembic in all cases. The generation of the .ini file by the command
alembic init alembicautomatically placed the directory namealembichere. The special variable%(here)scan also be used, as in%(here)s/alembic.这是 Alembic 在所有情况下都需要的唯一密钥。 通过命令
alembic init alembic生成的.ini文件会自动将目录名alembic放置在这里。 也可以使用特殊变量%(here)s,如%(here)s/alembic。For support of applications that package themselves into .egg files, the value can also be specified as a package resource, in which case resource_filename() is used to find the file (new in 0.2.2). Any non-absolute URI which contains colons is interpreted here as a resource name, rather than a straight filename.
为了支持将自身打包成 .egg 文件的应用程序,该值也可以指定为包资源,在这种情况下,resource_filename() 用于查找文件(版本0.2.2 中的新功能)。 任何包含冒号的非绝对 URI 在这里都被解释为资源名称,而不是直接的文件名。
-
file_template - this is the naming scheme used to generate new migration files. The value present is the default, so is commented out. Tokens available include:
-
file_template - 这是用于生成新迁移文件的命名方案。 存在的值是默认值,因此被注释掉。 可用的token包括:
- %%(rev)s - revision id (修订号)
- %%(slug)s - a truncated string derived from the revision message (从修订消息派生的截断字符串)
- %%(year)d, %%(month).2d, %%(day).2d, %%(hour).2d, %%(minute).2d, %%(second).2d - components of the create date, by default datetime.datetime.now() unless the timezone configuration option is also used. (创建日期的组成部分,默认为 datetime.datetime.now() 除非还使用了 timezone 配置选项。)
-
timezone - an optional timezone name (e.g. UTC, EST5EDT, etc.) that will be applied to the timestamp which renders inside the migration file’s comment as well as within the filename. This option requires installing the python-dateutil library. If timezone is specified, the create date object is no longer derived from datetime.datetime.now() and is instead generated as:
-
timezone - 一个可选的时区名称(例如 UTC、EST5EDT 等),它将应用于在迁移文件的注释以及文件名中呈现的时间戳。 此选项需要安装 python-dateutil 库。 如果指定了时区,则创建日期对象不再从 datetime.datetime.now() 派生,而是生成为:
datetime.datetime.utcnow().replace( tzinfo=dateutil.tz.tzutc() ).astimezone( dateutil.tz.gettz(<timezone>) ) -
truncate_slug_length - defaults to 40, the max number of characters to include in the “slug” field.
-
truncate_slug_length - 默认为 40,即“slug”字段中包含的最大字符数。
-
sqlalchemy.url - A URL to connect to the database via SQLAlchemy. This configuration value is only used if the env.py file calls upon them; in the “generic” template, the call to config.get_main_option("sqlalchemy.url") in the run_migrations_offline() function and the call to engine_from_config(prefix="sqlalchemy.") in the run_migrations_online() function are where this key is referenced. If the SQLAlchemy URL should come from some other source, such as from environment variables or a global registry, or if the migration environment makes use of multiple database URLs, the developer is encouraged to alter the env.py file to use whatever methods are appropriate in order to acquire the database URL or URLs.
-
sqlalchemy.url - 通过 SQLAlchemy 连接到数据库的 URL。 此配置值仅在 env.py 文件调用它们时使用; 在“通用”模板中,run_migrations_offline() 函数中对 config.get_main_option("sqlalchemy.url") 的调用和 run_migrations_online() 函数中对 engine_from_config(prefix="sqlalchemy.") 的调用是该键所在的位置参考。 如果 SQLAlchemy URL 应该来自某些其他源,例如来自环境变量或全局注册表,或者如果迁移环境使用多个数据库 URL,则鼓励开发人员更改 env.py 文件以使用任何合适的方法以获取数据库 URL 或 其他URL。
-
revision_environment - this is a flag which when set to the value ‘true’, will indicate that the migration environment script env.py should be run unconditionally when generating new revision files, as well as when running the alembic history command.
-
revision_environment - 这是一个标志,当设置为值“true”时,将指示在生成新修订文件以及运行 alembic 历史命令时应无条件运行迁移环境脚本 env.py。
-
sourceless - when set to ‘true’, revision files that only exist as .pyc or .pyo files in the versions directory will be used as versions, allowing “sourceless” versioning folders. When left at the default of ‘false’, only .py files are consumed as version files.
-
sourceless - 当设置为“true”时,版本目录中仅作为 .pyc 或 .pyo 文件存在的修订文件将用作版本,允许“无源”版本控制文件夹。 当保留默认值“false”时,只有 .py 文件被用作版本文件。
-
version_locations - an optional list of revision file locations, to allow revisions to exist in multiple directories simultaneously. See Working with Multiple Bases for examples.
-
version_locations - 一个可选的修订文件位置列表,允许修订同时存在于多个目录中。 有关示例,请参阅 Working with Multiple Bases。
-
version_path_separator - a separator of version_locations paths. It should be defined if multiple version_locations is used. See Working with Multiple Bases for examples.
-
version_path_separator - version_locations 路径的分隔符。 如果使用多个 version_locations,则应定义它。 有关示例,请参阅Working with Multiple Bases。
-
output_encoding - the encoding to use when Alembic writes the script.py.mako file into a new migration file. Defaults to
'utf-8'. -
output_encoding - 当 Alembic 将 script.py.mako 文件写入新的迁移文件时使用的编码。 默认为“utf-8”。
-
[loggers], [handlers], [formatters], [logger_], [handler_], [formatter_*] - these sections are all part of Python’s standard logging configuration, the mechanics of which are documented at Configuration File Format. As is the case with the database connection, these directives are used directly as the result of the logging.config.fileConfig() call present in the env.py script, which you’re free to modify.
-
[loggers], [handlers], [formatters], [logger_], [handler_], [formatter_*] - 这些部分都是 Python 标准日志配置的一部分,其机制记录在配置文件格式中。 与数据库连接的情况一样,这些指令直接作为 env.py 脚本中存在的 logging.config.fileConfig() 调用的结果使用,您可以自由修改。
For starting up with just a single database and the generic configuration, setting up the SQLAlchemy URL is all that’s needed:
对于只使用单个数据库和通用配置的启动,只需要设置 SQLAlchemy URL:
sqlalchemy.url = postgresql://scott:tiger@localhost/test
Create a Migration Script
创建迁移脚本
With the environment in place we can create a new revision, using alembic revision:
环境准备好后,我们可以使用
alembic revision创建一个新修订:
$ alembic revision -m "create account table"
Generating /path/to/yourproject/alembic/versions/1975ea83b712_create_accoun
t_table.py...done
A new file 1975ea83b712_create_account_table.py is generated. Looking inside the file:
生成了一个新文件
1975ea83b712_create_account_table.py。 文件内容如下:
"""create account table
Revision ID: 1975ea83b712
Revises:
Create Date: 2011-11-08 11:40:27.089406
"""
# revision identifiers, used by Alembic.
revision = '1975ea83b712'
down_revision = None
branch_labels = None
from alembic import op
import sqlalchemy as sa
def upgrade():
pass
def downgrade():
pass
The file contains some header information, identifiers for the current revision and a “downgrade” revision, an import of basic Alembic directives, and empty upgrade() and downgrade() functions. Our job here is to populate the upgrade() and downgrade() functions with directives that will apply a set of changes to our database. Typically, upgrade() is required while downgrade() is only needed if down-revision capability is desired, though it’s probably a good idea.
该文件包含一些标题信息、当前修订和“downgrade”修订的标识符、Alembic 基本的导入指令以及空的
upgrade()和downgrade()函数。我们在这里的工作是使用指令填充upgrade()和downgrade()函数,这些指令将对我们的数据库应用一组更改。通常,upgrade()是必需的,而downgrade()仅在向下修订功能需要时才使用,尽管这可能是一个好主意。
Another thing to notice is the down_revision variable. This is how Alembic knows the correct order in which to apply migrations. When we create the next revision, the new file’s down_revision identifier would point to this one:
另一件需要注意的是
down_revision变量。 这就是 Alembic 知道应用迁移的正确顺序的方式。 当我们创建下一个修订版时,新文件的down_revision标识符将指向这个:
# revision identifiers, used by Alembic.
revision = 'ae1027a6acf'
down_revision = '1975ea83b712'
Every time Alembic runs an operation against the versions/ directory, it reads all the files in, and composes a list based on how the down_revision identifiers link together, with the down_revision of None representing the first file. In theory, if a migration environment had thousands of migrations, this could begin to add some latency to startup, but in practice a project should probably prune old migrations anyway (see the section Building an Up to Date Database from Scratch for a description on how to do this, while maintaining the ability to build the current database fully).
每次 Alembic 对
versions/目录运行操作时,它都会读取所有文件,并根据down_revision标识符链接在一起的方式组成一个列表,其中down_revision变量为None的文件代表第一个迁移文件。 理论上,如果迁移环境有数千次迁移,这在开始迁移时增加一些延迟,但在项目实践中,无论如何都应该精简旧的迁移(有关如何执行此操作的说明,请参阅从头开始构建最新数据库部分,同时保持完全构建当前数据库的能力).
We can then add some directives to our script, suppose adding a new table account:
然后我们可以向我们的脚本添加一些指令,假设添加一个新表
account:
def upgrade():
op.create_table(
'account',
sa.Column('id', sa.Integer, primary_key=True),
sa.Column('name', sa.String(50), nullable=False),
sa.Column('description', sa.Unicode(200)),
)
def downgrade():
op.drop_table('account')
create_table() and drop_table() are Alembic directives. Alembic provides all the basic database migration operations via these directives, which are designed to be as simple and minimalistic as possible; there’s no reliance upon existing table metadata for most of these directives. They draw upon a global “context” that indicates how to get at a database connection (if any; migrations can dump SQL/DDL directives to files as well) in order to invoke the command. This global context is set up, like everything else, in the env.py script.
create_table() 和 drop_table() 是 Alembic 指令。 Alembic 通过这些指令提供了所有基本的数据库迁移操作,这些指令设计得尽可能简单和简约; 大多数这些指令不依赖现有的表元数据。 它们利用一个全局“上下文”来指示如何获得数据库连接(如果有的话;迁移也可以将 SQL/DDL 指令转储到文件)以调用命令。 与其他所有内容一样,此全局上下文在
env.py脚本中设置。
An overview of all Alembic directives is at Operation Reference.
所有 Alembic 指令的概述位于 操作参考。
Running our First Migration
运行我们的第一次迁移
We now want to run our migration. Assuming our database is totally clean, it’s as yet unversioned. The alembic upgrade command will run upgrade operations, proceeding from the current database revision, in this example None, to the given target revision. We can specify 1975ea83b712 as the revision we’d like to upgrade to, but it’s easier in most cases just to tell it “the most recent”, in this case head:
我们现在想要运行我们的迁移。 假设我们的数据库完全干净,它还没有版本化。
alembic upgrade命令将运行升级操作,从当前数据库修订版(在本例中为“None”)到给定的目标修订版。 我们可以指定1975ea83b712作为我们想要升级到的修订版,但在大多数情况下,告诉它“最新的”更容易,在这种情况下是head:
$ alembic upgrade head
INFO [alembic.context] Context class PostgresqlContext.
INFO [alembic.context] Will assume transactional DDL.
INFO [alembic.context] Running upgrade None -> 1975ea83b712
Wow that rocked! Note that the information we see on the screen is the result of the logging configuration set up in alembic.ini - logging the alembic stream to the console (standard error, specifically).
哇,震撼! 请注意,我们在屏幕上看到的信息是在
alembic.ini中设置的日志配置的结果 - 将alembic流记录到控制台(特别是标准错误)。
The process which occurred here included that Alembic first checked if the database had a table called alembic_version, and if not, created it. It looks in this table for the current version, if any, and then calculates the path from this version to the version requested, in this case head, which is known to be 1975ea83b712. It then invokes the upgrade() method in each file to get to the target revision.
此处发生的过程包括 Alembic 首先检查数据库是否有名为“alembic_version”的表,如果没有,则创建它。 它在此表中查找当前版本(如果有),然后计算从该版本到请求版本的路径,在本例中为
head,已知为1975ea83b712。 然后它调用每个文件中的upgrade()方法以获取目标修订版。
再次运行迁移
Let’s do another one so we have some things to play with. We again create a revision file:
让我们再做一个,这样我们就有一些东西可以玩了。 我们再次创建一个修订文件:
$ alembic revision -m "Add a column"
Generating /path/to/yourapp/alembic/versions/ae1027a6acf_add_a_column.py...
done
Let’s edit this file and add a new column to the account table:
让我们编辑这个文件并向
account表中添加一个新列:
"""Add a column
Revision ID: ae1027a6acf
Revises: 1975ea83b712
Create Date: 2011-11-08 12:37:36.714947
"""
# revision identifiers, used by Alembic.
revision = 'ae1027a6acf'
down_revision = '1975ea83b712'
from alembic import op
import sqlalchemy as sa
def upgrade():
op.add_column('account', sa.Column('last_transaction_date', sa.DateTime))
def downgrade():
op.drop_column('account', 'last_transaction_date')
Running again to head:
再次运行到
head:
$ alembic upgrade head
INFO [alembic.context] Context class PostgresqlContext.
INFO [alembic.context] Will assume transactional DDL.
INFO [alembic.context] Running upgrade 1975ea83b712 -> ae1027a6acf
We’ve now added the last_transaction_date column to the database.
我们现在已将
last_transaction_date列添加到数据库中。
Partial Revision Identifiers
部分修订标识符
Any time we need to refer to a revision number explicitly, we have the option to use a partial number. As long as this number uniquely identifies the version, it may be used in any command in any place that version numbers are accepted:
任何时候我们需要明确引用修订号,我们都可以选择使用部分编号。 只要这个数字唯一标识版本,它就可以在任何接受版本号的地方用在任何命令中:
alembic upgrade ae1
Above, we use ae1 to refer to revision ae1027a6acf. Alembic will stop and let you know if more than one version starts with that prefix.
上面,我们使用
ae1来指代修订版ae1027a6acf。 如果有多个版本以该前缀开头,Alembic 将停止并通知您。
Relative Migration Identifiers
相对迁移标识符
Relative upgrades/downgrades are also supported. To move two versions from the current, a decimal value “+N” can be supplied:
还支持相对升级/降级。 要从当前移动两个版本,可以提供十进制值“+N”:
alembic upgrade +2
Negative values are accepted for downgrades:
降级接受负值:
alembic downgrade -1
Relative identifiers may also be in terms of a specific revision. For example, to upgrade to revision ae1027a6acf plus two additional steps:
相对标识符也可以是特定版本。 例如,要升级到修订版
ae1027a6acf加上两个额外的步骤:
alembic upgrade ae10+2
Getting Information
获取信息
With a few revisions present we can get some information about the state of things.
通过一些修改,我们可以获得一些关于迁移版本状态的信息。
First we can view the current revision:
首先我们可以查看当前版本:
$ alembic current
INFO [alembic.context] Context class PostgresqlContext.
INFO [alembic.context] Will assume transactional DDL.
Current revision for postgresql://scott:XXXXX@localhost/test: 1975ea83b712 -> ae1027a6acf (head), Add a column
head is displayed only if the revision identifier for this database matches the head revision.
仅当此数据库的修订标识符与头部修订匹配时才显示
head。
We can also view history with alembic history; the --verbose option (accepted by several commands, including history, current, heads and branches) will show us full information about each revision:
我们也可以用
alembic history命令查看历史;--verbose选项(多个命令都接受改选项,包括history、current、heads和branches)将向我们显示每个版本的完整信息:
$ alembic history --verbose
Rev: ae1027a6acf (head)
Parent: 1975ea83b712
Path: /path/to/yourproject/alembic/versions/ae1027a6acf_add_a_column.py
add a column
Revision ID: ae1027a6acf
Revises: 1975ea83b712
Create Date: 2014-11-20 13:02:54.849677
Rev: 1975ea83b712
Parent: <base>
Path: /path/to/yourproject/alembic/versions/1975ea83b712_add_account_table.py
create account table
Revision ID: 1975ea83b712
Revises:
Create Date: 2014-11-20 13:02:46.257104
Viewing History Ranges
查看历史范围
Using the -r option to alembic history, we can also view various slices of history. The -r argument accepts an argument [start]:[end], where either may be a revision number, symbols like head, heads or base, current to specify the current revision(s), as well as negative relative ranges for [start] and positive relative ranges for [end]:
使用
alembic history的-r选项,我们还可以查看历史片段。-r参数接受一个参数[start]:[end],其中可以是一个修订号,像head、heads或base、current这样的符号来指定当前的修订版本,以及[start]的负相对范围和[end]的正相对范围:
alembic history -r1975ea:ae1027
A relative range starting from three revisions ago up to current migration, which will invoke the migration environment against the database to get the current migration:
从前三个修订版本到当前迁移版本的相对范围,它将针对数据库调用迁移环境以获取当前迁移:
alembic history -r-3:current
View all revisions from 1975 to the head:
查看从
1975到head的所有修订:
alembic history -r1975ea:
Downgrading
降级
We can illustrate a downgrade back to nothing, by calling alembic downgrade back to the beginning, which in Alembic is called base:
我们可以通过调用
alembic downgrade回到最初始状态, 来演示降级到迁移最初始状态,在 Alembic 中称为base:
$ alembic downgrade base
INFO [alembic.context] Context class PostgresqlContext.
INFO [alembic.context] Will assume transactional DDL.
INFO [alembic.context] Running downgrade ae1027a6acf -> 1975ea83b712
INFO [alembic.context] Running downgrade 1975ea83b712 -> None
Back to nothing - and up again:
降级到最初始状态 - 然后再次升级:
$ alembic upgrade head
INFO [alembic.context] Context class PostgresqlContext.
INFO [alembic.context] Will assume transactional DDL.
INFO [alembic.context] Running upgrade None -> 1975ea83b712
INFO [alembic.context] Running upgrade 1975ea83b712 -> ae1027a6acf
Next Steps
下一步
The vast majority of Alembic environments make heavy use of the “autogenerate” feature. Continue onto the next section, Auto Generating Migrations.
绝大多数 Alembic 环境大量使用“自动生成”功能。 继续下一部分,自动生成迁移。
Auto Generating Migrations
自动生成迁移
Alembic can view the status of the database and compare against the table metadata in the application, generating the “obvious” migrations based on a comparison. This is achieved using the --autogenerate option to the alembic revision command, which places so-called candidate migrations into our new migrations file. We review and modify these by hand as needed, then proceed normally.
Alembic 可以查看数据库的状态并与应用程序中的表元数据进行比较,根据比较生成“显而易见”的迁移。 这是通过使用
alembic revision命令的--autogenerate选项来实现的,它将所有的待迁移放入我们的新迁移文件中。 我们根据需要手动审查和修改这些,然后正常进行。
To use autogenerate, we first need to modify our env.py so that it gets access to a table metadata object that contains the target. Suppose our application has a declarative base in myapp.mymodel. This base contains a MetaData object which contains Table objects defining our database. We make sure this is loaded in env.py and then passed to EnvironmentContext.configure() via the target_metadata argument. The env.py sample script used in the generic template already has a variable declaration near the top for our convenience, where we replace None with our MetaData. Starting with:
要使用自动生成,我们首先需要修改我们的
env.py以便它可以访问包含目标的表元数据对象。 假设我们的应用程序在myapp.mymodel中有一个 declarative base。 该 base 包含一个 MetaData 对象,该对象包含我们定义的数据库的 Table 对象。 我们确保它被加载到env.py中,然后通过target_metadata参数传递给 EnvironmentContext.configure()。 为方便起见,通用模板中使用的env.py示例脚本在靠近顶部的地方已经有一个变量声明,我们用 MetaData 替换了None。 比如:
# add your model's MetaData object here
# for 'autogenerate' support
# from myapp import mymodel
# target_metadata = mymodel.Base.metadata
target_metadata = None
we change to:
我们改变成:
from myapp.mymodel import Base
target_metadata = Base.metadata
-
Note: The above example refers to the
generic alembic env.py template, e.g. the one created by default when calling uponalembic init, and not the special-use templates such asmultidb. Please consult the source code and comments within theenv.pyscript directly for specific guidance on where and how the autogenerate metadata is established. -
注意: 上面的例子指的是“通用的 alembic env.py 模板”,例如 调用
alembic init时默认创建的那个,而不是像multidb这样的特殊模板。 请直接查阅“env.py”脚本中的源代码和注释,以获取有关在何处以及如何建立自动生成元数据的具体指导。
If we look later in the script, down in run_migrations_online(), we can see the directive passed to EnvironmentContext.configure():
如果我们稍后查看脚本,在
run_migrations_online()中,我们可以看到传递给 EnvironmentContext.configure() 的指令:
def run_migrations_online():
engine = engine_from_config(
config.get_section(config.config_ini_section), prefix='sqlalchemy.')
with engine.connect() as connection:
context.configure(
connection=connection,
target_metadata=target_metadata
)
with context.begin_transaction():
context.run_migrations()
We can then use the alembic revision command in conjunction with the --autogenerate option. Suppose our MetaData contained a definition for the account table, and the database did not. We’d get output like:
然后我们可以将
alembic revision命令与--autogenerate选项结合使用。 假设我们的 MetaData 包含对account表的定义,而数据库没有。 我们会得到如下输出:
$ alembic revision --autogenerate -m "Added account table"
INFO [alembic.context] Detected added table 'account'
Generating /path/to/foo/alembic/versions/27c6a30d7c24.py...done
We can then view our file 27c6a30d7c24.py and see that a rudimentary migration is already present:
然后我们可以查看我们的
27c6a30d7c24.py文件, 并看到一个基本的迁移已经存在:
"""empty message
Revision ID: 27c6a30d7c24
Revises: None
Create Date: 2011-11-08 11:40:27.089406
"""
# revision identifiers, used by Alembic.
revision = '27c6a30d7c24'
down_revision = None
from alembic import op
import sqlalchemy as sa
def upgrade():
### commands auto generated by Alembic - please adjust! ###
op.create_table(
'account',
sa.Column('id', sa.Integer()),
sa.Column('name', sa.String(length=50), nullable=False),
sa.Column('description', sa.VARCHAR(200)),
sa.Column('last_transaction_date', sa.DateTime()),
sa.PrimaryKeyConstraint('id')
)
### end Alembic commands ###
def downgrade():
### commands auto generated by Alembic - please adjust! ###
op.drop_table("account")
### end Alembic commands ###
The migration hasn’t actually run yet, of course. We do that via the usual upgrade command. We should also go into our migration file and alter it as needed, including adjustments to the directives as well as the addition of other directives which these may be dependent on - specifically data changes in between creates/alters/drops.
当然,迁移还没有真正运行。 我们通过常用的
upgrade命令来做到这一点。 我们还应该进入我们的迁移文件并根据需要更改它,包括对指令的调整以及添加这些可能依赖的其他指令 - 特别是在创建/更改/删除之间的数据更改。
What does Autogenerate Detect
The vast majority of user issues with Alembic centers on the topic of what kinds of changes autogenerate can and cannot detect reliably, as well as how it renders Python code for what it does detect. It is critical to note that autogenerate is not intended to be perfect. It is always necessary to manually review and correct the candidate migrations that autogenerate produces. The feature is getting more and more comprehensive and error-free as releases continue, but one should take note of the current limitations.
Alembic 的绝大多数用户问题都集中在自动生成哪些类型的更改可以和不能可靠检测的主题上,以及它如何为检测到的内容呈现 Python 代码。 重要的是要注意自动生成并不是完美的。 始终需要手动检查和更正自动生成的候选迁移。 随着版本的不断发布,该功能变得越来越全面且无错误,但应注意当前的限制。
Autogenerate will detect:
- Table additions, removals.
- Column additions, removals.
- Change of nullable status on columns.
- Basic changes in indexes and explicitly-named unique constraints
- Basic changes in foreign key constraints
Autogenerate 将检测:
- 表的添加、删除。
- 列添加、删除。
- 列可为空状态的更改。
- 索引和显式命名的唯一约束的基本变化.
- 外键约束的基本变化
Autogenerate can optionally detect:
-
Change of column type. This will occur if you set the EnvironmentContext.configure.compare_type parameter to
True. The default implementation will reliably detect major changes, such as between Numeric and String, as well as accommodate for the types generated by SQLAlchemy’s “generic” types such as Boolean. Arguments that are shared between both types, such as length and precision values, will also be compared. If either the metadata type or database type has additional arguments beyond that of the other type, these are not compared, such as if one numeric type featured a “scale” and other type did not, this would be seen as the backing database not supporting the value, or reporting on a default that the metadata did not specify.The type comparison logic is fully extensible as well; see Comparing Types for details.
Changed in version 1.4: type comparison code has been reworked such that column types are compared based on their rendered DDL, which should allow the functionality enabled by EnvironmentContext.configure.compare_type to be much more accurate, correctly accounting for the behavior of SQLAlchemy “generic” types as well as major arguments specified within types.
-
Change of server default. This will occur if you set the EnvironmentContext.configure.compare_server_default parameter to True, or to a custom callable function. This feature works well for simple cases but cannot always produce accurate results. The Postgresql backend will actually invoke the “detected” and “metadata” values against the database to determine equivalence. The feature is off by default so that it can be tested on the target schema first. Like type comparison, it can also be customized by passing a callable; see the function’s documentation for details.
Autogenerate 可以选择检测:
列类型的更改。 如果您将 EnvironmentContext.configure.compare_type 参数设置为
True,则会发生这种情况。 默认实现将可靠地检测主要更改,例如 Numeric 和 String 之间的更改,并适应 SQLAlchemy 生成的“通用”类型(例如 Boolean 类型)。 两种类型之间共享的参数,如长度和精度值,也将进行比较。如果元数据类型或数据库类型有其他类型的额外参数,则不会比较这些参数,例如如果一个 numeric 类型 具有 “scale” 而其他类型没有,这将被视为后端数据库不支持该值或者报告为元数据未指定的默认值。类型比较逻辑也是完全可扩展的; 有关详细信息,请参阅Comparing Types。
- 版本 1.4 更新: 类型比较代码已经过重新设计,以便根据它们呈现的 DDL 比较列类型,这应该允许 EnvironmentContext.configure.compare_type 启用的功能更加准确,更准确的解释 SQLAlchemy 的“通用”类型的行为以及类型中指定的主要参数。
更改服务端默认设置。 如果您将 EnvironmentContext.configure.compare_server_default 参数设置为 True 或自定义可调用函数,则会发生这种情况。 此功能适用于简单的情况,但不能始终产生准确的结果。Postgresql 后端实际上会针对数据库调用 “detected” 和 “metadata” 值以确定等效性。该功能默认处于关闭状态,因此可以先在目标架构上进行测试。 和类型比较一样,也可以通过传递一个callable来自定义; 有关详细信息,请参阅该函数的文档。
Autogenerate can not detect:
- Changes of table name. These will come out as an add/drop of two different tables, and should be hand-edited into a name change instead.
- Changes of column name. Like table name changes, these are detected as a column add/drop pair, which is not at all the same as a name change.
- Anonymously named constraints. Give your constraints a name, e.g. UniqueConstraint('col1', 'col2', name="my_name"). See the section The Importance of Naming Constraints for background on how to configure automatic naming schemes for constraints.
- Special SQLAlchemy types such as Enum when generated on a backend which doesn’t support ENUM directly - this because the representation of such a type in the non-supporting database, i.e. a CHAR+ CHECK constraint, could be any kind of CHAR+CHECK. For SQLAlchemy to determine that this is actually an ENUM would only be a guess, something that’s generally a bad idea. To implement your own “guessing” function here, use the sqlalchemy.events.DDLEvents.column_reflect() event to detect when a CHAR (or whatever the target type is) is reflected, and change it to an ENUM (or whatever type is desired) if it is known that that’s the intent of the type. The sqlalchemy.events.DDLEvents.after_parent_attach() can be used within the autogenerate process to intercept and un-attach unwanted CHECK constraints.
Autogenerate 不能检测:
- 表名的变化。 这些将作为两个不同表的新增/删除出现,并且应该手动编辑表名更改。
- 列名的变化。 与表名更改一样,这些被检测为列添加/删除两种操作,这与名称更改完全不同。
- 匿名命名的约束。 给你的约束一个名字, 例如 UniqueConstraint('col1', 'col2', name="my_name"). 有关如何为约束配置自动命名方案的信息,请参阅命名约束的重要性一节。
- 在不直接支持 ENUM 的后端生成的特殊 SQLAlchemy 的 Enum 类型 - 这是因为这种类型是在不支持 Enum 类型 的数据库中的表示,即 CHAR+CHECK 约束,可以是任何类型的 CHAR+CHECK。 对于 SQLAlchemy 确定这实际上是一个 ENUM 只是一个猜测,这通常是一个坏主意。要在这里实现你自己的“guessing”方法, 当 CHAR (或任何目标类型)被反射并更改为 ENUM 时(或所需的任何类型)时, 请使用 sqlalchemy.events.DDLEvents.column_reflect() 事件检测,如果这是改变目标类型的目的。 sqlalchemy.events.DDLEvents.after_parent_attach() 可以在自动生成过程中用来拦截和取消额外不需要的 CHECK 约束。
Autogenerate can’t currently, but will eventually detect:
- Some free-standing constraint additions and removals may not be supported, including PRIMARY KEY, EXCLUDE, CHECK; these are not necessarily implemented within the autogenerate detection system and also may not be supported by the supporting SQLAlchemy dialect.
- Sequence additions, removals - not yet implemented.
Autogenerate 不能实时, 但最终会检测:
- 可能不支持某些独立约束的添加和删除,包括 PRIMARY KEY、EXCLUDE、CHECK; 这些不一定在Autogenerate系统中实现,SQLAlchemy 支持的方言也可能不支持。
- 序列的添加、删除 - 尚未实现。
Autogenerating Multiple MetaData collections
自动生成多个元数据集合
The target_metadata collection may also be defined as a sequence if an application has multiple MetaData collections involved:
如果应用程序涉及多个 MetaData 集合,则
target_metadata集合也可以定义为一个序列:
from myapp.mymodel1 import Model1Base
from myapp.mymodel2 import Model2Base
target_metadata = [Model1Base.metadata, Model2Base.metadata]
The sequence of MetaData collections will be consulted in order during the autogenerate process. Note that each MetaData must contain unique table keys (e.g. the “key” is the combination of the table’s name and schema); if two MetaData objects contain a table with the same schema/name combination, an error is raised.
在自动生成过程中,将按顺序查询 MetaData 集合的顺序。 请注意,每个 MetaData 必须包含唯一的表键(例如,“键”是表名和模式的组合); 如果两个 MetaData 对象包含一个具有相同模式/名称组合的表,则会引发错误。
Controlling What to be Autogenerated
The autogenerate process scans across all table objects within the database that is referred towards by the current database connection in use.
自动生成过程扫描数据库中由当前正在使用的数据库连接引用的所有表对象。
The list of objects that are scanned in the target database connection include:
在目标数据库连接中扫描的对象列表包括:
- The “default” schema currently referred towards by the database connection.
- If the EnvironmentContext.configure.include_schemas is set to
True, all non-default “schemas”, which are those names returned by the get_schema_names() method of Inspector. The SQLAlchemy document Specifying the Schema Name discusses the concept of a “schema” in detail. - Within each “schema”, all tables present are scanned using the get_table_names() method of Inspector.
- Within each “table”, most sub-objects of the each Table construct are scanned, including columns and some forms of constraints. This process ultimately involves the use of methods on Inspector including get_columns(), get_indexes(), get_unique_constraints(), get_foreign_keys() (as of this writing, CHECK constraints and primary key constraints are not yet included).
- 数据库连接的当前引用为“default”模式。
- 如果 EnvironmentContext.configure.include_schemas 设置为
True, 将包含所有从 Inspector 的 get_schema_names() 返回的非默认“schemas”名称。SQLAlchemy 的文档里面指定模式名称详细讨论了模式(Schema)的概念。- 在每个模式(Schema)中,使用 Inspector 的 get_table_names() 方法扫描所有存在的表。
- 在每个“Table”中,会扫描每个 Table 构造的大多数子对象,包括列和某些形式的约束。 这个过程最终涉及使用 Inspector 上的方法,包括 get_columns(), get_indexes(), get_unique_constraints(), get_foreign_keys()(在撰写本文时,CHECK 约束和主键约束尚未包括在内)。
Omitting Schema Names from the Autogenerate Process
As the above set of database objects are typically to be compared to the contents of a single MetaData object, particularly when the EnvironmentContext.configure.include_schemas flag is enabled there is an important need to filter out unwanted “schemas”, which for some database backends might be the list of all the databases present. This filtering is best performed using the EnvironmentContext.configure.include_name hook, which provides for a callable that may return a boolean true/false indicating if a particular schema name should be included:
由于上述数据库对象集通常与单个 MetaData 对象的内容进行比较,特别是在启用 EnvironmentContext.configure.include_schemas 标志时,非常需要过滤掉不需要的“模式”,这对于某些数据库后端 可能是所有存在的数据库的列表。 最好使用 EnvironmentContext.configure.include_name 钩子执行此过滤,它提供了一个可调用对象,该可调用对象可能返回一个布尔值 true/false,指示是否应包含特定的模式名称:
def include_name(name, type_, parent_names):
if type_ == "schema":
# note this will not include the default schema
return name in ["schema_one", "schema_two"]
else:
return True
context.configure(
# ...
include_schemas = True,
include_name = include_name
)
Above, when the list of schema names is first retrieved, the names will be filtered through the above include_name function so that only schemas named "schema_one" and "schema_two" will be considered by the autogenerate process.
上面,当第一次检索模式名称列表时,将通过上述
include_name函数过滤名称,以便自动生成过程仅考虑名为“schema_one”和“schema_two”的模式。
In order to include the default schema, that is, the schema that is referred towards by the database connection without any explicit schema being specified, the name passed to the hook is None. To alter our above example to also include the default schema, we compare to None as well:
为了包含默认架构,即数据库连接所引用的架构,而没有指定任何显式架构,传递给钩子的名称为
None。 为了将上面的示例更改为也包含默认模式,我们还将与None进行比较:
def include_name(name, type_, parent_names):
if type_ == "schema":
# this **will* include the default schema
return name in [None, "schema_one", "schema_two"]
else:
return True
context.configure(
# ...
include_schemas = True,
include_name = include_name
)
Omitting Table Names from the Autogenerate Process
The EnvironmentContext.configure.include_name hook is also most appropriate to limit the names of tables in the target database to be considered. If a target database has many tables that are not part of the MetaData, the autogenerate process will normally assume these are extraneous tables in the database to be dropped, and it will generate a Operations.drop_table() operation for each. To prevent this, the EnvironmentContext.configure.include_name hook may be used to search for each name within the tables collection of the MetaData object and ensure names which aren’t present are not included:
EnvironmentContext.configure.include_name 钩子也最适合限制目标数据库中的表名。 如果目标数据库有许多不属于元数据的表,自动生成过程通常会假定这些是数据库中要删除的无关表,并且将为每个表生成一个 Operations.drop_table() 操作。 为了防止这种情况,EnvironmentContext.configure.include_name 钩子可用于搜索 MetaData 对象的表集合(tables)中的每个名称,并确保不包含不存在的名称:
target_metadata = MyModel.metadata
def include_name(name, type_, parent_names):
if type_ == "table":
return name in target_metadata.tables
else:
return True
context.configure(
# ...
target_metadata = target_metadata,
include_name = include_name,
include_schemas = False
)
The above example is limited to table names present in the default schema only. In order to search within a MetaData collection for schema-qualified table names as well, a table present in the non default schema will be present under a name of the form <schemaname>.<tablename>. The EnvironmentContext.configure.include_name hook will present this schema name on a per-tablename basis in the parent_names dictionary, using the key "schema_name" that refers to the name of the schema currently being considered, or None if the schema is the default schema of the database connection:
上面的示例仅限于默认模式中存在的表名。 为了在 MetaData 集合中搜索模式限定的表名,非默认模式中的表将以
<schemaname>.<tablename>形式的名称出现。 EnvironmentContext.configure.include_name 钩子将在parent_names字典中基于每个表名显示此模式名称,使用键“schema_name”表示当前正在考虑的模式的名称,或者如果数据库连接模式是默认模式,则为None:
# example fragment
if parent_names["schema_name"] is None:
return name in target_metadata.tables
else:
# build out schema-qualified name explicitly...
return (
"%s.%s" % (parent_names["schema_name"], name) in
target_metadata.tables
)
However more simply, the parent_names dictionary will also include the dot-concatenated name already constructed under the key "schema_qualified_table_name", which will also be suitably formatted for tables in the default schema as well with the dot omitted. So the full example of omitting tables with schema support may look like:
然而更简单地说,
parent_names字典还将包括已经在键“schema_qualified_table_name”下构建的点连接名称,该名称也将适用于默认模式中的表以及过滤点的格式。 因此,过滤具有模式支持的表的完整示例可能如下所示:
target_metadata = MyModel.metadata
def include_name(name, type_, parent_names):
if type_ == "schema":
return name in [None, "schema_one", "schema_two"]
elif type_ == "table":
# use schema_qualified_table_name directly
return (
parent_names["schema_qualified_table_name"] in
target_metadata.tables
)
else:
return True
context.configure(
# ...
target_metadata = target_metadata,
include_name = include_name,
include_schemas = True
)
The parent_names dictionary will also include the key "table_name" when the name being considered is that of a column or constraint object local to a particular table.
当所考虑的名称是特定表本地的列或约束对象的名称时,
parent_names字典还将包括键“table_name”。
The EnvironmentContext.configure.include_name hook only refers to reflected objects, and not those located within the target MetaData collection. For more fine-grained rules that include both MetaData and reflected object, the EnvironmentContext.configure.include_object hook discussed in the next section is more appropriate.
EnvironmentContext.configure.include_name 钩子仅引用反射对象,而不是位于目标 MetaData 集合中的对象。 对于同时包含 MetaData 和反射对象的更细粒度的规则,下一节讨论的 EnvironmentContext.configure.include_object 钩子更合适。
New in version 1.5: added the EnvironmentContext.configure.include_name hook.
版本1.5更新: 新增 EnvironmentContext.configure.include_name 钩子
Omitting Based on Object
The EnvironmentContext.configure.include_object hook provides for object-level inclusion/exclusion rules based on the Table object being reflected as well as the elements within it. This hook can be used to limit objects both from the local MetaData collection as well as from the target database. The limitation is that when it reports on objects in the database, it will have fully reflected that object, which can be expensive if a large number of objects will be omitted. The example below refers to a fine-grained rule that will skip changes on Column objects that have a user-defined flag skip_autogenerate placed into the info dictionary:
EnvironmentContext.configure.include_object 钩子提供了基于被反映的 Table 对象以及其中的元素的对象级包含/排除规则。 此钩子可用于限制来自本地 MetaData 集合以及来自目标数据库的对象。 限制是,当它报告数据库中的对象时,它会完全反映该对象,如果将省略大量对象,这可能会很昂贵。 下面的示例引用了一个细粒度的规则,该规则将跳过对 Column 对象的更改,这些对象将用户定义的标志
skip_autogenerate放置到 info 字典中:
def include_object(object, name, type_, reflected, compare_to):
if (type_ == "column" and
not reflected and
object.info.get("skip_autogenerate", False)):
return False
else:
return True
context.configure(
# ...
include_object = include_object
)
Comparing and Rendering Types
The area of autogenerate’s behavior of comparing and rendering Python-based type objects in migration scripts presents a challenge, in that there’s a very wide variety of types to be rendered in scripts, including those part of SQLAlchemy as well as user-defined types. A few options are given to help out with this task.
在迁移脚本中比较和呈现基于 Python 的类型对象的自动生成行为领域提出了一个挑战,因为在脚本中需要呈现各种各样的类型,包括 SQLAlchemy 的那些部分以及用户定义的类型。 提供了一些选项来帮助完成此任务。
Controlling the Module Prefix
When types are rendered, they are generated with a module prefix, so that they are available based on a relatively small number of imports. The rules for what the prefix is is based on the kind of datatype as well as configurational settings. For example, when Alembic renders SQLAlchemy types, it will by default prefix the type name with the prefix sa.:
渲染类型时,会使用 模块前缀 生成它们,以便它们基于相对少量的导入可用。 前缀的规则基于数据类型的种类以及配置设置。 例如,当 Alembic 呈现 SQLAlchemy 类型时,默认情况下,它会在类型名称前加上前缀
sa.:
Column("my_column", sa.Integer())
The use of the sa. prefix is controllable by altering the value of EnvironmentContext.configure.sqlalchemy_module_prefix:
使用
sa.前缀可以通过改变 EnvironmentContext.configure.sqlalchemy_module_prefix 的值来控制:
def run_migrations_online():
# ...
context.configure(
connection=connection,
target_metadata=target_metadata,
sqlalchemy_module_prefix="sqla.",
# ...
)
# ...
In either case, the sa. prefix, or whatever prefix is desired, should also be included in the imports section of script.py.mako; it also defaults to import sqlalchemy as sa.
在任何一种情况下,
sa.前缀,或任何需要的前缀,也应该包含在script.py.mako的导入部分中; 它还默认为import sqlalchemy as sa.
For user-defined types, that is, any custom type that is not within the sqlalchemy. module namespace, by default Alembic will use the value of __module__ for the custom type:
对于用户定义的类型,即不在
sqlalchemy.模块命名空间内的任何自定义类型,默认情况下,Alembic 将使用 value of __module__ 作为自定义类型:
Column("my_column", myapp.models.utils.types.MyCustomType())
The imports for the above type again must be made present within the migration, either manually, or by adding it to script.py.mako.
上述类型的导入必须再次出现在迁移中,要么手动,要么通过将其添加到
script.py.mako。
The above custom type has a long and cumbersome name based on the use of __module__ directly, which also implies that lots of imports would be needed in order to accommodate lots of types. For this reason, it is recommended that user-defined types used in migration scripts be made available from a single module. Suppose we call it myapp.migration_types:
基于直接使用
__module__,上述自定义类型的名称又长又麻烦,这也意味着需要大量导入才能容纳大量类型。 因此,建议将迁移脚本中使用的用户定义类型提供给单个模块。 假设我们称之为myapp.migration_types:
# myapp/migration_types.py
from myapp.models.utils.types import MyCustomType
We can first add an import for migration_types to our script.py.mako:
我们可以首先将
migration_types的导入添加到script.py.mako中:
from alembic import op
import sqlalchemy as sa
import myapp.migration_types
${imports if imports else ""}
We then override Alembic’s use of __module__ by providing a fixed prefix, using the EnvironmentContext.configure.user_module_prefix option:
然后,我们通过使用 EnvironmentContext.configure.user_module_prefix 选项提供固定前缀来覆盖 Alembic 对
__module__的使用:
def run_migrations_online():
# ...
context.configure(
connection=connection,
target_metadata=target_metadata,
user_module_prefix="myapp.migration_types.",
# ...
)
# ...
Above, we now would get a migration like:
经过上面设置,我们现在会得到如下迁移:
Column("my_column", myapp.migration_types.MyCustomType())
Now, when we inevitably refactor our application to move MyCustomType somewhere else, we only need modify the myapp.migration_types module, instead of searching and replacing all instances within our migration scripts.
现在,当我们不可避免地重构我们的应用程序以将
MyCustomType移动到其他地方时,我们只需要修改myapp.migration_types模块,而不是搜索和替换迁移脚本中的所有实例。
Affecting the Rendering of Types Themselves
The methodology Alembic uses to generate SQLAlchemy and user-defined type constructs as Python code is plain old __repr__(). SQLAlchemy’s built-in types for the most part have a __repr__() that faithfully renders a Python-compatible constructor call, but there are some exceptions, particularly in those cases when a constructor accepts arguments that aren’t compatible with __repr__(), such as a pickling function.
Alembic 用来生成 SQLAlchemy 和 用户自定义的类型的构造方法是 Python 的旧的生成文本的
__repr__()方法。 SQLAlchemy 的内置类型大部分都有一个__repr__(),它忠实地呈现与 Python 兼容的构造函数调用,但也有一些例外,特别是在构造函数接受与__repr__()不兼容的参数的情况下,例如 pick 函数。
When building a custom type that will be rendered into a migration script, it is often necessary to explicitly give the type a __repr__() that will faithfully reproduce the constructor for that type. This, in combination with EnvironmentContext.configure.user_module_prefix, is usually enough. However, if additional behaviors are needed, a more comprehensive hook is the EnvironmentContext.configure.render_item option. This hook allows one to provide a callable function within env.py that will fully take over how a type is rendered, including its module prefix:
在构建将呈现到迁移脚本中的自定义类型时,通常需要显式地为该类型指定一个
__repr__(),以便忠实地重现该类型的构造函数。 这与 EnvironmentContext.configure.user_module_prefix 结合使用通常就足够了。 但是,如果需要额外的行为,更全面的钩子是 EnvironmentContext.configure.render_item 选项。 这个钩子允许在env.py中提供一个可调用函数,它将完全接管一个类型的呈现方式,包括它的模块前缀:
def render_item(type_, obj, autogen_context):
"""Apply custom rendering for selected items."""
if type_ == 'type' and isinstance(obj, MySpecialType):
return "mypackage.%r" % obj
# default rendering for other objects
return False
def run_migrations_online():
# ...
context.configure(
connection=connection,
target_metadata=target_metadata,
render_item=render_item,
# ...
)
# ...
In the above example, we’d ensure our MySpecialType includes an appropriate __repr__() method, which is invoked when we call it against "%r".
在上面的示例中,我们将确保我们的
MySpecialType包含一个适当的__repr__()方法,当我们针对"%r"调用它时会调用它。
The callable we use for EnvironmentContext.configure.render_item can also add imports to our migration script. The AutogenContext passed in contains a datamember called AutogenContext.imports, which is a Python set() for which we can add new imports. For example, if MySpecialType were in a module called mymodel.types, we can add the import for it as we encounter the type:
我们用于 EnvironmentContext.configure.render_item 的可调用对象也可以将导入添加到我们的迁移脚本中。 传入的 AutogenContext 包含一个名为 AutogenContext.imports 的数据成员,它是一个 Python
set(),我们可以为其添加新的导入。 例如,如果MySpecialType在名为mymodel.types的模块中,我们可以在遇到类型时为其添加导入:
def render_item(type_, obj, autogen_context):
"""Apply custom rendering for selected items."""
if type_ == 'type' and isinstance(obj, MySpecialType):
# add import for this type
autogen_context.imports.add("from mymodel import types")
return "types.%r" % obj
# default rendering for other objects
return False
The finished migration script will include our imports where the ${imports} expression is used, producing output such as:
完成的迁移脚本将包含我们的导入,其中使用了
${imports}表达式,产生如下输出:
from alembic import op
import sqlalchemy as sa
from mymodel import types
def upgrade():
op.add_column('sometable', Column('mycolumn', types.MySpecialType()))
Comparing Types
The default type comparison logic will work for SQLAlchemy built in types as well as basic user defined types. This logic is only enabled if the EnvironmentContext.configure.compare_type parameter is set to True:
默认类型比较逻辑适用于 SQLAlchemy 内置类型以及基本用户定义类型。 此逻辑仅在 EnvironmentContext.configure.compare_type 参数设置为
True时启用:
context.configure(
# ...
compare_type = True
)
Note: The default type comparison logic (which is end-user extensible) currently (as of Alembic version 1.4.0) works by comparing the generated SQL for a column. It does this in two steps-
- First, it compares the outer type of each column such as VARCHAR or TEXT. Dialect implementations can have synonyms that are considered equivalent- this is because some databases support types by converting them to another type. For example, NUMERIC and DECIMAL are considered equivalent on all backends, while on the Oracle backend the additional synonyms BIGINT, INTEGER, NUMBER, SMALLINT are added to this list of equivalents
- Next, the arguments within the type, such as the lengths of strings, precision values for numerics, the elements inside of an enumeration are compared. If BOTH columns have arguments AND they are different, a change will be detected. If one column is just set to the default and the other has arguments, Alembic will pass on attempting to compare these. The rationale is that it is difficult to detect what a database backend sets as a default value without generating false positives.
注意: 当前(从 Alembic 版本 1.4.0 开始)默认类型比较逻辑(最终用户可扩展)通过比较为列生成的 SQL 来工作。 它分两步完成 -
- 首先,它比较每列的外部类型,例如 VARCHAR 或 TEXT。 方言实现可以具有被视为等效的同义词——这是因为某些数据库通过将类型转换为另一种类型来支持类型。 例如,NUMERIC 和 DECIMAL 在所有后端都被认为是等效的,而在 Oracle 后端,其他同义词 BIGINT、INTEGER、NUMBER、SMALLINT 被添加到此等效列表中
- 接下来,比较类型中的参数,例如字符串的长度、数字的精度值、枚举中的元素。 如果两列都有参数并且它们不同,则将检测到更改。 如果一列只是设置为默认值,而另一列有参数,Alembic 将继续尝试比较这些。 基本原理是很难检测数据库后端设置的默认值而不产生误报。
Changed in version 1.4.0: Added the text and keyword comparison for column types
版本1.4.0更新:添加了列类型的文本和关键字比较
Alternatively, the EnvironmentContext.configure.compare_type parameter accepts a callable function which may be used to implement custom type comparison logic, for cases such as where special user defined types are being used:
或者,EnvironmentContext.configure.compare_type 参数接受可用于实现自定义类型比较逻辑的可调用函数,例如使用特殊用户定义类型的情况:
def my_compare_type(context, inspected_column,
metadata_column, inspected_type, metadata_type):
# return False if the metadata_type is the same as the inspected_type
# or None to allow the default implementation to compare these
# types. a return value of True means the two types do not
# match and should result in a type change operation.
return None
context.configure(
# ...
compare_type = my_compare_type
)
Above, inspected_column is a [sqlalchemy.schema.Column] as returned by sqlalchemy.engine.reflection.Inspector.reflect_table(), whereas metadata_column is a [sqlalchemy.schema.Column] from the local model environment. A return value of None indicates that default type comparison to proceed.
上面,
inspected_column是由 sqlalchemy.engine.reflection.Inspector.reflect_table() 返回的 [sqlalchemy.schema.Column],而 metadata_column 是 [sqlalchemy.schema.Column] 来自本地模型环境。None的返回值表示要进行默认类型比较。
Additionally, custom types that are part of imported or third party packages which have special behaviors such as per-dialect behavior should implement a method called compare_against_backend() on their SQLAlchemy type. If this method is present, it will be called where it can also return True or False to specify the types compare as equivalent or not; if it returns None, default type comparison logic will proceed:
此外,作为具有特殊行为(例如每种方言行为)的导入包或第三方包的一部分的自定义类型应在其 SQLAlchemy 类型上实现名为
“compare_against_backend()”的方法。 如果此方法存在,它将被调用,它还可以返回True或False以指定类型比较是否等效; 如果它返回None,默认类型比较逻辑将继续:
class MySpecialType(TypeDecorator):
# ...
def compare_against_backend(self, dialect, conn_type):
# return True if this type is the same as the given database type,
# or None to allow the default implementation to compare these
# types. a return value of False means the given type does not
# match this type.
if dialect.name == 'postgresql':
return isinstance(conn_type, postgresql.UUID)
else:
return isinstance(conn_type, String)
Warning: The boolean return values for the above
compare_against_backendmethod, which is part of SQLAlchemy and not Alembic,are the opposite of that of the EnvironmentContext.configure.compare_type callable, returningTruefor types that are the same vs.Falsefor types that are different.The EnvironmentContext.configure.compare_type callable on the other hand should returnTruefor types that are different.
警告:上述
compare_against_backend方法的布尔返回值,它是 SQLAlchemy 的一部分,而不是 Alembic,与 EnvironmentContext.configure.compare_type 可调用的方法相反,对于相同的类型返回True,对于不相同的类型返回False。另一方面,EnvironmentContext.configure.compare_type 可调用应该为不同的类型返回True。
The order of precedence regarding the EnvironmentContext.configure.compare_type callable vs. the type itself implementing compare_against_backend is that the EnvironmentContext.configure.compare_type callable is favored first; if it returns None, then the compare_against_backend method will be used, if present on the metadata type. If that returns None, then a basic check for type equivalence is run.
关于 EnvironmentContext.configure.compare_type 可调用对象与实现
compare_against_backend的类型本身的优先顺序是 EnvironmentContext.configure.compare_type 可调用对象优先; 如果它返回None,则将使用compare_against_backend方法(如果存在于元数据类型上)。 如果返回None,则运行类型等价的基本检查。
New in version 1.4.0: - added column keyword comparisons and the type_synonyms property.
版本1.4.0新功能: 添加了列关键字比较和 type_synonyms 属性。
Applying Post Processing and Python Code Formatters to Generated Revisions
Revision scripts generated by the alembic revision command can optionally be piped through a series of post-production functions which may analyze or rewrite Python source code generated by Alembic, within the scope of running the revision command. The primary intended use of this feature is to run code-formatting tools such as Black or autopep8, as well as custom-written formatting and linter functions, on revision files as Alembic generates them. Any number of hooks can be configured and they will be run in series, given the path to the newly generated file as well as configuration options.
由 alembic 修订命令生成的修订脚本可以选择通过一系列后期制作功能进行管道传输,这些功能可以在运行修订命令的范围内分析或重写 Alembic 生成的 Python 源代码。 此功能的主要预期用途是在 Alembic 生成修订文件时在修订文件上运行代码格式化工具,例如 Black 或 autopep8 ,以及自定义编写的格式化和 linter 函数。 给定新生成文件的路径以及配置选项,可以配置任意数量的钩子,并且它们将连续运行。
The post write hooks, when configured, run against generated revision files regardless of whether or not the autogenerate feature was used.
对于提交的钩子,在配置后,无论是否使用自动生成功能,都会针对生成的修订文件运行。
New in version 1.2.0
版本1.2.0 新增
Note: Alembic’s post write system is partially inspired by the pre-commit tool, which configures git hooks that reformat source files as they are committed to a git repository. Pre-commit can serve this role for Alembic revision files as well, applying code formatters to them as they are committed. Alembic’s post write hooks are useful only in that they can format the files immediately upon generation, rather than at commit time, and also can be useful for projects that prefer not to use pre-commit.
注意: Alembic 的写后系统部分受到 pre-commit 工具的启发,该工具配置了 git 钩子,在源文件提交到 git 存储库时重新格式化它们。 预提交也可以为 Alembic 修订文件服务,在提交时将代码格式化程序应用于它们。 Alembic 的 post write hook 的用处仅在于它们可以在生成文件时立即格式化文件,而不是在提交时格式化,并且对于不喜欢使用 pre-commit 的项目也很有用。
Basic Formatter Configuration
The alembic.ini samples now include commented-out configuration illustrating how to configure code-formatting tools to run against the newly generated file path. Example:
alembic.ini示例现在包含注释掉的配置,说明如何配置代码格式化工具以针对新生成的文件路径运行。 例子:
[post_write_hooks]
# format using "black"
hooks=black
black.type = console_scripts
black.entrypoint = black
black.options = -l 79
Above, we configure hooks to be a single post write hook labeled "black". Note that this label is arbitrary. We then define the configuration for the "black" post write hook, which includes:
上面,我们将
hooks配置为标记为"black"的单个 post write hook。 请注意,此标签是任意的。 然后我们定义了"black"post write hook的配置,包括:
type- this is the type of hook we are running. Alembic includes a hook runner called"console_scripts", which is specifically a Python function that usessubprocess.run()to invoke a separate Python script against the revision file. For a custom-written hook function, this configuration variable would refer to the name under which the custom hook was registered; see the next section for an example.
type- 这是我们正在运行的钩子类型。 Alembic 包含一个名为"console_scripts"的钩子运行器,它专门是一个 Python 函数,它使用subprocess.run()针对修订文件调用单独的 Python 脚本。 对于自定义编写的钩子函数,此配置变量将引用注册自定义钩子的名称; 有关示例,请参见下一节。
The following configuration options are specific to the "console_scripts" hook runner:
以下配置选项特定于
"console_scripts"钩子运行:
-
entrypoint- the name of the setuptools entrypoint that is used to define the console script. Within the scope of standard Python console scripts, this name will match the name of the shell command that is usually run for the code formatting tool, in this caseblack. -
options- a line of command-line options that will be passed to the code formatting tool. In this case, we want to run the commandblack /path/to/revision.py -l 79. By default, the revision path is positioned as the first argument. In order specify a different position, we can use theREVISION_SCRIPT_FILENAMEtoken as illustrated by the subsequent examples.Note: Make sure options for the script are provided such that it will rewrite the input file in place. For example, when running autopep8, the
--in-placeoption should be provided:[post_write_hooks] hooks = autopep8 autopep8.type = console_scripts autopep8.entrypoint = autopep8 autopep8.options = --in-place REVISION_SCRIPT_FILENAME -
cwd- optional working directory from which the console script is run.
entrypoint- 用于定义控制台脚本的 setuptools entrypoint 的名称。 在标准 Python 控制台脚本的范围内,此名称将匹配通常为代码格式化工具运行的 shell 命令的名称,在本例中为“black”。
options- 将传递给代码格式化工具的命令行选项。 在这种情况下,我们要运行命令“black /path/to/revision.py -l 79”。 默认情况下,修订路径定位为第一个参数。 为了指定不同的位置,我们可以使用REVISION_SCRIPT_FILENAME标记,如后续示例所示。注意: 确保提供了脚本选项,以便它会在 原地 重写输入文件。 例如,在运行
autopep8时,应提供--in-place选项:[post_write_hooks] hooks = autopep8 autopep8.type = console_scripts autopep8.entrypoint = autopep8 autopep8.options = --in-place REVISION_SCRIPT_FILENAME
cwd- 运行控制台脚本的可选工作目录。
When running alembic revision -m "rev1", we will now see the black tool’s output as well:
当运行
alembic revision -m "rev1"时,我们现在也会看到black工具的输出:
$ alembic revision -m "rev1"
Generating /path/to/project/versions/481b13bc369a_rev1.py ... done
Running post write hook "black" ...
reformatted /path/to/project/versions/481b13bc369a_rev1.py
All done! ✨ 🍰 ✨
1 file reformatted.
done
Hooks may also be specified as a list of names, which correspond to hook runners that will run sequentially. As an example, we can also run the zimports import rewriting tool (written by Alembic’s author) subsequent to running the black tool, using a configuration as follows:
钩子也可以指定为名称列表,这些名称对应于将按顺序运行的挂钩运行器。 例如,我们还可以在运行
black工具之后运行 zimports 导入重写工具(由 Alembic 的作者编写),使用如下配置:
[post_write_hooks]
# format using "black", then "zimports"
hooks=black, zimports
black.type = console_scripts
black.entrypoint = black
black.options = -l 79 REVISION_SCRIPT_FILENAME
zimports.type = console_scripts
zimports.entrypoint = zimports
zimports.options = --style google REVISION_SCRIPT_FILENAME
When using the above configuration, a newly generated revision file will be processed first by the “black” tool, then by the “zimports” tool.
使用上述配置时,新生成的修订文件将首先由“black”工具处理,然后由“zimports”工具处理。
Alternatively, one can run pre-commit itself as follows:
或者,可以按如下方式运行预提交本身:
[post_write_hooks]
hooks = pre-commit
pre-commit.type = console_scripts
pre-commit.entrypoint = pre-commit
pre-commit.options = run --files REVISION_SCRIPT_FILENAME
pre-commit.cwd = %(here)s
(The last line helps to ensure that the .pre-commit-config.yaml file will always be found, regardless of from where the hook was called.)
(最后一行有助于确保始终可以找到
.pre-commit-config.yaml文件,无论从何处调用钩子。)
Writing Custom Hooks as Python Functions
The previous section illustrated how to run command-line code formatters, through the use of a post write hook provided by Alembic known as console_scripts. This hook is in fact a Python function that is registered under that name using a registration function that may be used to register other types of hooks as well.
上一节说明了如何通过使用 Alembic 提供的称为
“console_scripts”的写后挂钩来运行命令行代码格式化程序。 这个钩子实际上是一个 Python 函数,它使用一个注册函数以该名称注册,该注册函数也可用于注册其他类型的钩子。
To illustrate, we will use the example of a short Python function that wants to rewrite the generated code to use tabs instead of four spaces. For simplicity, we will illustrate how this function can be present directly in the env.py file. The function is declared and registered using the write_hooks.register() decorator:
为了说明,我们将使用一个简短的 Python 函数示例,该函数希望重写生成的代码以使用制表符而不是四个空格。 为简单起见,我们将说明如何将此函数直接存在于
env.py文件中。 该函数使用 write_hooks.register() 装饰器声明和注册:
from alembic.script import write_hooks
import re
@write_hooks.register("spaces_to_tabs")
def convert_spaces_to_tabs(filename, options):
lines = []
with open(filename) as file_:
for line in file_:
lines.append(
re.sub(
r"^( )+",
lambda m: "\t" * (len(m.group(1)) // 4),
line
)
)
with open(filename, "w") as to_write:
to_write.write("".join(lines))
Our new "spaces_to_tabs" hook can be configured in alembic.ini as follows:
我们新的
"spaces_to_tabs"钩子可以在alembic.ini中配置如下:
[alembic]
# ...
# ensure the revision command loads env.py
revision_environment = true
[post_write_hooks]
hooks = spaces_to_tabs
spaces_to_tabs.type = spaces_to_tabs
When alembic revision is run, the env.py file will be loaded in all cases, the custom “spaces_to_tabs” function will be registered and it will then be run against the newly generated file path:
当
alembic revision运行时,env.py文件将在所有情况下被加载,自定义的“spaces_to_tabs”函数将被注册,然后它将针对新生成的文件路径运行:
$ alembic revision -m "rev1"
Generating /path/to/project/versions/481b13bc369a_rev1.py ... done
Running post write hook "spaces_to_tabs" ...
done
Generating SQL Scripts (a.k.a. “Offline Mode”)
生成SQL脚本(又称离线模式)
A major capability of Alembic is to generate migrations as SQL scripts, instead of running them against the database - this is also referred to as offline mode. This is a critical feature when working in large organizations where access to DDL is restricted, and SQL scripts must be handed off to DBAs. Alembic makes this easy via the --sql option passed to any upgrade or downgrade command. We can, for example, generate a script that revises up to rev ae1027a6acf:
Alembic 的一个主要功能是将迁移生成为 SQL 脚本,而不是针对数据库运行它们 - 这也称为离线模式。 在限制访问 DDL 且 SQL 脚本必须交给 DBA 的大型组织中工作时,这是一项关键功能。 Alembic 通过传递给任何
upgrade或downgrade命令的--sql选项使这变得容易。 例如,我们可以生成一个脚本,修改为修订版ae1027a6acf:
$ alembic upgrade ae1027a6acf --sql
INFO [alembic.context] Context class PostgresqlContext.
INFO [alembic.context] Will assume transactional DDL.
BEGIN;
CREATE TABLE alembic_version (
version_num VARCHAR(32) NOT NULL
);
INFO [alembic.context] Running upgrade None -> 1975ea83b712
CREATE TABLE account (
id SERIAL NOT NULL,
name VARCHAR(50) NOT NULL,
description VARCHAR(200),
PRIMARY KEY (id)
);
INFO [alembic.context] Running upgrade 1975ea83b712 -> ae1027a6acf
ALTER TABLE account ADD COLUMN last_transaction_date TIMESTAMP WITHOUT TIME ZONE;
INSERT INTO alembic_version (version_num) VALUES ('ae1027a6acf');
COMMIT;
While the logging configuration dumped to standard error, the actual script was dumped to standard output - so in the absence of further configuration (described later in this section), we’d at first be using output redirection to generate a script:
当日志配置转发到标准错误时,实际的脚本消息被转发到标准输出 - 所以在没有进一步配置的情况下(本节稍后描述),我们首先使用输出重定向来生成脚本:
alembic upgrade ae1027a6acf --sql > migration.sql
Getting the Start Version
获取起始版本
Notice that our migration script started at the base - this is the default when using offline mode, as no database connection is present and there’s no alembic_version table to read from.
One way to provide a starting version in offline mode is to provide a range to the command line. This is accomplished by providing the “version” in start:end syntax:
请注意,我们的迁移脚本从base开始 - 这是使用离线模式时的默认设置,因为不存在数据库连接并且没有
alembic_version表可供读取。在离线模式下提供起始版本的一种方法是为命令行提供范围。 这是通过在
start:end语法中提供 “version” (版本)来实现的:
alembic upgrade 1975ea83b712:ae1027a6acf --sql > migration.sql
The start:end syntax is only allowed in offline mode; in “online” mode, the alembic_version table is always used to get at the current version.
It’s also possible to have the env.py script retrieve the “last” version from the local environment, such as from a local file. A scheme like this would basically treat a local file in the same way alembic_version works:
start:end语法只允许在离线模式下使用; 在“online”(在线)模式下,总是使用alembic_version表来获取当前版本。也可以让
env.py脚本从本地环境(例如本地文件)中检索“last”(最后)版本。 像这样的方案基本上会以与alembic_version相同的方式处理本地文件:
if context.is_offline_mode():
version_file = os.path.join(os.path.dirname(config.config_file_name), "version.txt")
if os.path.exists(version_file):
current_version = open(version_file).read()
else:
current_version = None
context.configure(dialect_name=engine.name, starting_rev=current_version)
context.run_migrations()
end_version = context.get_revision_argument()
if end_version and end_version != current_version:
open(version_file, 'w').write(end_version)
Writing Migration Scripts to Support Script Generation
编写支持生成脚本的迁移脚本
The challenge of SQL script generation is that the scripts we generate can’t rely upon any client/server database access. This means a migration script that pulls some rows into memory via a SELECT statement will not work in --sql mode. It’s also important that the Alembic directives, all of which are designed specifically to work in both “live execution” as well as “offline SQL generation” mode, are used.
SQL 脚本生成的挑战在于我们生成的脚本不能依赖于任何客户端/服务器数据库访问。 这意味着通过
SELECT语句将一些行拉入内存的迁移脚本将无法在--sql模式下工作。 同时 Alembic 指令也很重要,所有这些指令都是专门为在 “live execution”(实时执行)和 “offline SQL generation”(离线SQL生成) 模式下工作而设计的。
Customizing the Environment
Users of the --sql option are encouraged to hack their env.py files to suit their needs. The env.py script as provided is broken into two sections: run_migrations_online() and run_migrations_offline(). Which function is run is determined at the bottom of the script by reading EnvironmentContext.is_offline_mode(), which basically determines if the --sql flag was enabled.
For example, a multiple database configuration may want to run through each database and set the output of the migrations to different named files - the EnvironmentContext.configure() function accepts a parameter output_buffer for this purpose. Below we illustrate this within the run_migrations_offline() function:
鼓励使用
--sql选项的用户修改他们的env.py文件以满足他们的需要。 提供的env.py脚本分为两部分:run_migrations_online()和run_migrations_offline()。 运行哪个函数是在脚本底部通过读取 EnvironmentContext.is_offline_mode() 确定的,它基本上确定是否启用了--sql标志。例如,多数据库配置可能希望通过每个数据库运行并将迁移的输出设置为不同的命名文件 - 为此,EnvironmentContext.configure() 函数接受一个参数
output_buffer。 下面我们在run_migrations_offline()函数中说明这一点:
from alembic import context
import myapp
import sys
db_1 = myapp.db_1
db_2 = myapp.db_2
def run_migrations_offline():
"""Run migrations *without* a SQL connection."""
for name, engine, file_ in [
("db1", db_1, "db1.sql"),
("db2", db_2, "db2.sql"),
]:
context.configure(
url=engine.url,
transactional_ddl=False,
output_buffer=open(file_, 'w'))
context.execute("-- running migrations for '%s'" % name)
context.run_migrations(name=name)
sys.stderr.write("Wrote file '%s'" % file_)
def run_migrations_online():
"""Run migrations *with* a SQL connection."""
for name, engine in [
("db1", db_1),
("db2", db_2),
]:
connection = engine.connect()
context.configure(connection=connection)
try:
context.run_migrations(name=name)
session.commit()
except:
session.rollback()
raise
if context.is_offline_mode():
run_migrations_offline()
else:
run_migrations_online()
The Importance of Naming Constraints
命名约束的重要性
An important topic worth mentioning is that of constraint naming conventions. As we’ve proceeded here, we’ve talked about adding tables and columns, and we’ve also hinted at lots of other operations listed in Operation Reference such as those which support adding or dropping constraints like foreign keys and unique constraints. The way these constraints are referred to in migration scripts is by name, however these names by default are in most cases generated by the relational database in use, when the constraint is created. For example, if you emitted two CREATE TABLE statements like this on Postgresql:
值得一提的一个重要主题是约束命名约定。 正如我们在这里进行的那样,我们已经讨论了添加表和列,并且我们还暗示了 操作参考 中列出的许多其他操作,例如支持添加或删除外键和唯一约束等约束的操作。 在迁移脚本中引用这些约束的方式是按名称,但是在大多数情况下,这些名称默认情况下是由使用的关系数据库在创建约束时生成的。 例如,如果您在 Postgresql 上发出两个这样的 CREATE TABLE 语句:
test=> CREATE TABLE user_account (id INTEGER PRIMARY KEY);
CREATE TABLE
test=> CREATE TABLE user_order (
test(> id INTEGER PRIMARY KEY,
test(> user_account_id INTEGER REFERENCES user_account(id));
CREATE TABLE
Suppose we wanted to DROP the REFERENCES that we just applied to the user_order.user_account_id column, how do we do that? At the prompt, we’d use ALTER TABLE <tablename> DROP CONSTRAINT <constraint_name>, or if using Alembic we’d be using Operations.drop_constraint(). But both of those functions need a name - what’s the name of this constraint?
假设我们想要删除刚刚应用于
user_order.user_account_id列的REFERENCES,我们该怎么做? 在提示符下,我们将使用ALTER TABLE <tablename> DROP CONSTRAINT <constraint_name>,或者如果使用 Alembic,我们将使用 Operations.drop_constraint()。 但是这两个函数都需要一个名字——这个约束的名字是什么?
It does have a name, which in this case we can figure out by looking at the Postgresql catalog tables:
它确实有一个名称,在这种情况下,我们可以通过查看 Postgresql 目录表来确定:
test=> SELECT r.conname FROM
test-> pg_catalog.pg_class c JOIN pg_catalog.pg_namespace n ON n.oid = c.relnamespace
test-> JOIN pg_catalog.pg_constraint r ON c.oid = r.conrelid
test-> WHERE c.relname='user_order' AND r.contype = 'f'
test-> ;
conname
---------------------------------
user_order_user_account_id_fkey
(1 row)
The name above is not something that Alembic or SQLAlchemy created; user_order_user_account_id_fkey is a naming scheme used internally by Postgresql to name constraints that are otherwise not named.
上面的名字不是 Alembic 或 SQLAlchemy 创建的;
user_order_user_account_id_fkey是 Postgresql 内部使用的命名方案,用于命名未命名的约束。
This scheme doesn’t seem so complicated, and we might want to just use our knowledge of it so that we know what name to use for our Operations.drop_constraint() call. But is that a good idea? What if for example we needed our code to run on Oracle as well. OK, certainly Oracle uses this same scheme, right? Or if not, something similar. Let’s check:
这个方案似乎并不复杂,我们可能只想使用我们对它的了解,以便我们知道为 Operations.drop_constraint() 调用使用什么名称。 但这是个好主意吗? 例如,如果我们也需要我们的代码在 Oracle 上运行怎么办。 好的,Oracle 肯定使用相同的方案,对吧? 或者如果没有,类似的东西。 让我们检查:
Oracle Database 10g Express Edition Release 10.2.0.1.0 - Production
SQL> CREATE TABLE user_account (id INTEGER PRIMARY KEY);
Table created.
SQL> CREATE TABLE user_order (
2 id INTEGER PRIMARY KEY,
3 user_account_id INTEGER REFERENCES user_account(id));
Table created.
SQL> SELECT constraint_name FROM all_constraints WHERE
2 table_name='USER_ORDER' AND constraint_type in ('R');
CONSTRAINT_NAME
-----------------------------------------------------
SYS_C0029334
Oh, we can see that is…..much worse. Oracle’s names are entirely unpredictable alphanumeric codes, and this will make being able to write migrations quite tedious, as we’d need to look up all these names.
哦,我们可以看到那是……更糟。 Oracle 的名称是完全不可预测的字母数字代码,这将使编写迁移变得非常乏味,因为我们需要查找所有这些名称。
The solution to having to look up names is to make your own names. This is an easy, though tedious thing to do manually. For example, to create our model in SQLAlchemy ensuring we use names for foreign key constraints would look like:
必须查找名称的解决方案是自己命名。 手动完成这是一件容易但乏味的事情。 例如,要在 SQLAlchemy 中创建我们的模型,确保我们使用名称作为外键约束,如下所示:
from sqlalchemy import MetaData, Table, Column, Integer, ForeignKey
meta = MetaData()
user_account = Table('user_account', meta,
Column('id', Integer, primary_key=True)
)
user_order = Table('user_order', meta,
Column('id', Integer, primary_key=True),
Column('user_order_id', Integer,
ForeignKey('user_account.id', name='fk_user_order_id'))
)
Simple enough, though this has some disadvantages. The first is that it’s tedious; we need to remember to use a name for every ForeignKey object, not to mention every UniqueConstraint, CheckConstraint, Index, and maybe even PrimaryKeyConstraint as well if we wish to be able to alter those too, and beyond all that, all the names have to be globally unique. Even with all that effort, if we have a naming scheme in mind, it’s easy to get it wrong when doing it manually each time.
很简单,尽管这有一些缺点。 首先是乏味; 我们需要记住为每个 ForeignKey 对象使用一个名称,更不用说每个 UniqueConstraint, CheckConstraint, Index, 甚至 PrimaryKeyConstraint,如果我们也希望能够更改它们,除此之外,所有名称都必须是全局唯一的。 即使付出了所有努力,如果我们有一个命名方案,每次手动执行时很容易出错。
What’s worse is that manually naming constraints (and indexes) gets even more tedious in that we can no longer use convenience features such as the .unique=True or .index=True flag on Column:
更糟糕的是,手动命名约束(和索引)变得更加乏味,因为我们不能再在列上使用
.unique=True或.index=True标志等便利功能:
user_account = Table('user_account', meta,
Column('id', Integer, primary_key=True),
Column('name', String(50), unique=True)
)
Above, the unique=True flag creates a UniqueConstraint, but again, it’s not named. If we want to name it, manually we have to forego the usage of unique=True and type out the whole constraint:
上面,
unique=True标志创建了一个 UniqueConstraint ,但同样,它没有命名。 如果我们想命名它,我们必须手动放弃使用unique=True并输入整个约束:
user_account = Table('user_account', meta,
Column('id', Integer, primary_key=True),
Column('name', String(50)),
UniqueConstraint('name', name='uq_user_account_name')
)
There’s a solution to all this naming work, which is to use an automated naming convention. For some years, SQLAlchemy has encourgaged the use of DDL Events in order to create naming schemes. The after_parent_attach() event in particular is the best place to intercept when Constraint and Index objects are being associated with a parent Table object, and to assign a .name to the constraint while making use of the name of the table and associated columns.
所有这些命名工作都有一个解决方案,那就是使用 自动命名约定。 多年来,SQLAlchemy 一直鼓励使用 DDL 事件来创建命名方案。 当 约束 和 索引 对象与父 表 对象关联时,
after_parent_attach()事件是拦截的最佳位置,并在使用表名和关联列的名称时为约束分配.name。
But there is also a better way to go, which is to make use of a feature new in SQLAlchemy 0.9.2 which makes use of the events behind the scenes known as naming_convention. Here, we can create a new MetaData object while passing a dictionary referring to a naming scheme:
但是还有一个更好的方法,那就是利用 SQLAlchemy 0.9.2 版本中的一个新特性,它利用称为 naming_convention 的幕后事件。 在这里,我们可以创建一个新的 MetaData 对象,同时传递一个引用命名方案的字典:
convention = {
"ix": "ix_%(column_0_label)s",
"uq": "uq_%(table_name)s_%(column_0_name)s",
"ck": "ck_%(table_name)s_%(constraint_name)s",
"fk": "fk_%(table_name)s_%(column_0_name)s_%(referred_table_name)s",
"pk": "pk_%(table_name)s"
}
metadata = MetaData(naming_convention=convention)
If we define our models using a MetaData as above, the given naming convention dictionary will be used to provide names for all constraints and indexes.
如果我们使用上面的 MetaData 定义我们的模型,那么给定的命名约定字典将用于为所有约束和索引提供名称。
Integration of Naming Conventions into Operations, Autogenerate
As of Alembic 0.6.4, the naming convention feature is integrated into the Operations object, so that the convention takes effect for any constraint that is otherwise unnamed. The naming convention is passed to Operations using the MigrationsContext.configure.target_metadata parameter in env.py, which is normally configured when autogenerate is used:
从 Alembic 0.6.4 开始,命名约定功能集成到 Operations 对象中,因此约定对任何未命名的约束生效。 命名约定使用
env.py中的 MigrationsContext.configure.target_metadata 参数传递给 Operations ,通常在使用 autogenerate 时配置:
# in your application's model:
meta = MetaData(naming_convention={
"ix": "ix_%(column_0_label)s",
"uq": "uq_%(table_name)s_%(column_0_name)s",
"ck": "ck_%(table_name)s_%(constraint_name)s",
"fk": "fk_%(table_name)s_%(column_0_name)s_%(referred_table_name)s",
"pk": "pk_%(table_name)s"
})
Base = declarative_base(metadata=meta)
# .. in your Alembic env.py:
# add your model's MetaData object here
# for 'autogenerate' support
from myapp import mymodel
target_metadata = mymodel.Base.metadata
# ...
def run_migrations_online():
# ...
context.configure(
connection=connection,
target_metadata=target_metadata
)
Above, when we render a directive like the following:
以上,当我们渲染一个指令时:
op.add_column('sometable', Column('q', Boolean(name='q_bool')))
The Boolean type will render a CHECK constraint with the name "ck_sometable_q_bool", assuming the backend in use does not support native boolean types.
假设使用的后端不支持原生布尔类型,布尔类型将呈现名为
“ck_sometable_q_bool”的 CHECK 约束。
We can also use op directives with constraints and not give them a name at all, if the naming convention doesn’t require one. The value of None will be converted into a name that follows the appropriate naming conventions:
如果命名约定不需要,我们也可以使用带有约束的
op指令而不给它们命名。None的值将转换为遵循适当命名约定的名称:
def upgrade():
op.create_unique_constraint(None, 'some_table', 'x')
When autogenerate renders constraints in a migration script, it renders them typically with their completed name. If using at least Alembic 0.6.4 as well as SQLAlchemy 0.9.4, these will be rendered with a special directive Operations.f() which denotes that the string has already been tokenized:
当自动生成在迁移脚本中呈现约束时,它通常使用完整的名称呈现它们。 如果至少使用 Alembic 0.6.4 和 SQLAlchemy 0.9.4,这些将使用特殊指令 Operations.f() 呈现,表示字符串已经被标记:
def upgrade():
op.create_unique_constraint(op.f('uq_const_x'), 'some_table', 'x')
For more detail on the naming convention feature, see Configuring Constraint Naming Conventions.
有关命名约定功能的更多详细信息,请参阅配置约束命名约定。
Running “Batch” Migrations for SQLite and Other Databases
在SQLite和其他数据中运行"批处理"迁移脚本
The SQLite database presents a challenge to migration tools in that it has almost no support for the ALTER statement which relational schema migrations rely upon. The rationale for this stems from philosophical and architectural concerns within SQLite, and they are unlikely to be changed.
SQLite 数据库对迁移工具提出了挑战,因为它几乎不支持关系模式迁移所依赖的 ALTER 语句。 这样做的理由源于 SQLite 中的哲学和架构问题,它们不太可能被改变。
Migration tools are instead expected to produce copies of SQLite tables that correspond to the new structure, transfer the data from the existing table to the new one, then drop the old table. For our purposes here we’ll call this “move and copy” workflow, and in order to accommodate it in a way that is reasonably predictable, while also remaining compatible with other databases, Alembic provides the batch operations context.
相反,迁移工具应该生成与新结构相对应的 SQLite 表副本,将数据从现有表传输到新表,然后删除旧表。 出于我们的目的,我们将这里称为 “移动和复制” 工作流,并且为了以合理可预测的方式适应它,同时保持与其他数据库的兼容性,Alembic 提供了 批处理 操作上下文。
Within this context, a relational table is named, and then a series of mutation operations to that table alone are specified within the block. When the context is complete, a process begins whereby the “move and copy” procedure begins; the existing table structure is reflected from the database, a new version of this table is created with the given changes, data is copied from the old table to the new table using “INSERT from SELECT”, and finally the old table is dropped and the new one renamed to the original name.
在此上下文中,一个关系表被命名,然后在块中指定对该表的一系列变异操作。 当上下文完成时,一个过程开始,“移动和复制” 过程开始; 现有的表结构反映在数据库中,使用给定的更改创建该表的新版本,使用 “INSERT from SELECT” 将数据从旧表复制到新表,最后旧表被删除,新表重命名为原始名称。
The Operations.batch_alter_table() method provides the gateway to this process:
Operations.batch_alter_table() 方法提供了此过程的上下文:
with op.batch_alter_table("some_table") as batch_op:
batch_op.add_column(Column('foo', Integer))
batch_op.drop_column('bar')
When the above directives are invoked within a migration script, on a SQLite backend we would see SQL like:
当在迁移脚本中调用上述指令时,在 SQLite 后端我们会看到如下 SQL:
CREATE TABLE _alembic_batch_temp (
id INTEGER NOT NULL,
foo INTEGER,
PRIMARY KEY (id)
);
INSERT INTO _alembic_batch_temp (id) SELECT some_table.id FROM some_table;
DROP TABLE some_table;
ALTER TABLE _alembic_batch_temp RENAME TO some_table;
On other backends, we’d see the usual ALTER statements done as though there were no batch directive - the batch context by default only does the “move and copy” process if SQLite is in use, and if there are migration directives other than Operations.add_column() present, which is the one kind of column-level ALTER statement that SQLite supports. Operations.batch_alter_table() can be configured to run “move and copy” unconditionally in all cases, including on databases other than SQLite; more on this is below.
在其他后端,我们会看到执行通常的 ALTER 语句,就好像没有批处理指令一样 - 默认情况下,批处理上下文仅在使用 SQLite 并且存在除 Operations.add_column() 之外的迁移指令(这是 SQLite 支持的一种列级 ALTER 语句)时才执行 “移动和复制” 过程。 Operations.batch_alter_table() 可以配置为在所有情况下无条件地运行 “移动和复制”,包括在 SQLite 以外的数据库上; 更多内容如下。
Controlling Table Reflection
控制表反射
The Table object that is reflected when “move and copy” proceeds is performed using the standard autoload=True approach. This call can be affected using the reflect_args and reflect_kwargs arguments. For example, to override a Column within the reflection process such that a Boolean object is reflected with the create_constraint flag set to False:
使用标准
autoload=True方法执行 “移动和复制” 时反射的 Table 对象。 使用 reflect_args 和 reflect_kwargs 参数可以影响此调用。 例如,要在反射过程中覆盖 Column,以便在将create_constraint标志设置为False的情况下反射布尔对象:
with self.op.batch_alter_table(
"bar",
reflect_args=[Column('flag', Boolean(create_constraint=False))]
) as batch_op:
batch_op.alter_column(
'flag', new_column_name='bflag', existing_type=Boolean)
Another use case, add a listener to the Table as it is reflected so that special logic can be applied to columns or types, using the column_reflect() event:
另一个用例,使用 column_reflect() 事件在 表 反射时向 表 添加一个侦听器,以便可以将特殊逻辑应用于列或类型:
def listen_for_reflect(inspector, table, column_info):
"correct an ENUM type"
if column_info['name'] == 'my_enum':
column_info['type'] = Enum('a', 'b', 'c')
with self.op.batch_alter_table(
"bar",
reflect_kwargs=dict(
listeners=[
('column_reflect', listen_for_reflect)
]
)
) as batch_op:
batch_op.alter_column(
'flag', new_column_name='bflag', existing_type=Boolean)
The reflection process may also be bypassed entirely by sending a pre-fabricated Table object; see Working in Offline Mode for an example.
Dealing with Constraints
处理约束
There are a variety of issues when using “batch” mode with constraints, such as FOREIGN KEY, CHECK and UNIQUE constraints. This section will attempt to detail many of these scenarios.
使用带有约束的“批处理”模式时会出现各种问题,例如 FOREIGN KEY、CHECK 和 UNIQUE 约束。 本节将尝试详细介绍其中的许多场景。
Dropping Unnamed or Named Foreign Key Constraints
删除未命名或命名的外键约束
SQLite, unlike any other database, allows constraints to exist in the database that have no identifying name. On all other backends, the target database will always generate some kind of name, if one is not given.
与任何其他数据库不同,SQLite 允许数据库中存在没有标识名称的约束。 在所有其他后端,如果没有给出,目标数据库将始终生成某种名称。
The first challenge this represents is that an unnamed constraint can’t by itself be targeted by the BatchOperations.drop_constraint() method. An unnamed FOREIGN KEY constraint is implicit whenever the ForeignKey or ForeignKeyConstraint objects are used without passing them a name. Only on SQLite will these constraints remain entirely unnamed when they are created on the target database; an automatically generated name will be assigned in the case of all other database backends.
这代表的第一个挑战是未命名的约束本身不能被 BatchOperations.drop_constraint() 方法定位。 每当使用 ForeignKey 或 ForeignKeyConstraint 对象而不传递名称时,未命名的 FOREIGN KEY 约束是隐式的。 只有在 SQLite 上,这些约束在目标数据库上创建时才会完全保持未命名; 对于所有其他数据库后端,将分配一个自动生成的名称。
A second issue is that SQLAlchemy itself has inconsistent behavior in dealing with SQLite constraints as far as names. Prior to version 1.0, SQLAlchemy omits the name of foreign key constraints when reflecting them against the SQLite backend. So even if the target application has gone through the steps to apply names to the constraints as stated in the database, they still aren’t targetable within the batch reflection process prior to SQLAlchemy 1.0.
第二个问题是 SQLAlchemy 本身在处理 SQLite 约束时的行为不一致,就名称而言。 在 1.0 版之前,SQLAlchemy 在将外键约束反映到 SQLite 后端时省略了它们的名称。 因此,即使目标应用程序已经完成了将名称应用于数据库中所述的约束的步骤,它们仍然不能在 SQLAlchemy 1.0 之前的批处理反射过程中成为目标。
Within the scope of batch mode, this presents the issue that the BatchOperations.drop_constraint() method requires a constraint name in order to target the correct constraint.
在批处理模式的范围内,这提出了 BatchOperations.drop_constraint() 方法需要一个约束名称才能定位正确的约束的问题。
In order to overcome this, the Operations.batch_alter_table() method supports a naming_convention argument, so that all reflected constraints, including foreign keys that are unnamed, or were named but SQLAlchemy isn’t loading this name, may be given a name, as described in Integration of Naming Conventions into Operations, Autogenerate. Usage is as follows:
为了克服这个问题,Operations.batch_alter_table() 方法支持一个命名约定参数,以便所有反映的约束,包括未命名的外键,或已命名但 SQLAlchemy 未加载此名称的外键,都可以指定一个名称,如 将命名约定集成到操作中,自动生成中进行了描述。 用法如下:
naming_convention = {
"fk":
"fk_%(table_name)s_%(column_0_name)s_%(referred_table_name)s",
}
with self.op.batch_alter_table(
"bar", naming_convention=naming_convention) as batch_op:
batch_op.drop_constraint(
"fk_bar_foo_id_foo", type_="foreignkey")
Note that the naming convention feature requires at least SQLAlchemy 0.9.4 for support.
请注意,命名约定功能至少需要 SQLAlchemy 0.9.4 的支持。
Including unnamed UNIQUE constraints
包含未命名的 UNIQUE 约束
A similar, but frustratingly slightly different, issue is that in the case of UNIQUE constraints, we again have the issue that SQLite allows unnamed UNIQUE constraints to exist on the database, however in this case, SQLAlchemy prior to version 1.0 doesn’t reflect these constraints at all. It does properly reflect named unique constraints with their names, however.
一个类似但令人沮丧的稍微不同的问题是,在 UNIQUE 约束的情况下,我们再次遇到 SQLite 允许数据库上存在未命名的 UNIQUE 约束的问题,但是在这种情况下,1.0 版之前的 SQLAlchemy 没有反映这些 根本没有约束。 但是,它确实正确地反映了命名的唯一约束及其名称。
So in this case, the workaround for foreign key names is still not sufficient prior to SQLAlchemy 1.0. If our table includes unnamed unique constraints, and we’d like them to be re-created along with the table, we need to include them directly, which can be via the table_args argument:
所以在这种情况下,外键名称的解决方法在 SQLAlchemy 1.0 之前仍然不够。 如果我们的表包含未命名的唯一约束,并且我们希望它们与表一起重新创建,我们需要直接包含它们,这可以通过 table_args 参数:
with self.op.batch_alter_table(
"bar", table_args=(UniqueConstraint('username'),)
):
batch_op.add_column(Column('foo', Integer))
Changing the Type of Boolean, Enum and other implicit CHECK datatypes
更改布尔、枚举和其他隐式 CHECK 数据类型的类型
The SQLAlchemy types Boolean and Enum are part of a category of types known as “schema” types; this style of type creates other structures along with the type itself, most commonly (but not always) a CHECK constraint.
SQLAlchemy 类型 Boolean 和 Enum 是称为 “schema” 类型的类型类别的一部分; 这种类型的类型会与类型本身一起创建其他结构,最常见的(但不总是)是 CHECK 约束。
Alembic handles dropping and creating the CHECK constraints here automatically, including in the case of batch mode. When changing the type of an existing column, what’s necessary is that the existing type be specified fully:
Alembic 在此处自动处理删除和创建 CHECK 约束,包括在批处理模式的情况下。 更改现有列的类型时,需要完全指定现有类型:
with self.op.batch_alter_table("some_table") as batch_op:
batch_op.alter_column(
'q', type_=Integer,
existing_type=Boolean(create_constraint=True, constraint_name="ck1"))
When dropping a column that includes a named CHECK constraint, as of Alembic 1.7 this named constraint must also be provided using a similar form, as there is no ability for Alembic to otherwise link this reflected CHECK constraint as belonging to a particular column:
当删除包含命名 CHECK 约束的列时,从 Alembic 1.7 开始,此命名约束也必须使用类似的形式提供,因为 Alembic 无法以其他方式将此反映的 CHECK 约束链接为属于特定列:
with self.op.batch_alter_table("some_table") as batch_op:
batch_op.drop_column(
'q',
existing_type=Boolean(create_constraint=True, constraint_name="ck1"))
)
Changed in version 1.7: The BatchOperations.drop_column() operation can accept an
existing_typedirective where a “schema type” such as Boolean and Enum may be specified such that an associated named constraint can be removed.
版本1.7更新:BatchOperations.drop_column() 操作可以接受
existing_type指令,其中可以指定诸如布尔和枚举之类的“模式类型”,以便可以删除关联的命名约束。
Including CHECK constraints
包括 CHECK 约束
As of Alembic 1.7, named CHECK constraints are automatically included in batch mode, as modern SQLAlchemy versions are capable of reflecting these constraints like any other constraint.
从 Alembic 1.7 开始,已命名 的 CHECK 约束自动包含在批处理模式中,因为现代 SQLAlchemy 版本能够像任何其他约束一样反映这些约束。
Note that when dropping or renaming a column that is mentioned in a named CHECK constraint, this CHECK constraint must be explicitly dropped first, as Alembic has no means of linking a reflected CHECK constraint to that column. Supposing column q of some_table were mentioned in a CHECK constraint named ck1. In order to drop this column, we have to drop the check constraint also:
请注意,当删除或重命名命名 CHECK 约束中提到的列时,必须首先显式删除此 CHECK 约束,因为 Alembic 无法将反射的 CHECK 约束链接到该列。 假设
some_table的列q在名为ck1的 CHECK 约束中被提及。 为了删除此列,我们还必须删除检查约束:
with self.op.batch_alter_table("some_table") as batch_op:
batch_op.drop_constraint("ck1", "check")
batch_op.drop_column('q')
Changed in version 1.7: Named CHECK constraints participate in batch mode in the same way as any other kind of constraint. This requires that column drops or renames now include explicit directives to drop an existing named constraint which refers to this column, as it will otherwise not be automatically detected as being associated with that particular column.
Unnamed CHECK constraints continue to be silently omitted from the table recreate operation.
版本1.7更新: 命名 CHECK 约束以与任何其他类型的约束相同的方式参与批处理模式。 这要求列的删除或重命名现在包含显式指令, 以删除引用此列的现有命名约束,否则将不会自动检测到它与该特定列的关联关系。
未命名的 CHECK 约束将继续在表重新创建操作中被忽略。
For unnamed CHECK constraints, these are still not automatically included as part of the batch process. Note that this limitation includes the CHECK constraints generated by the Boolean or Enum datatypes, which up through SQLAlchemy 1.3 would generate CHECK constraints automatically and cannot be tracked to the reflected table, assuming they are generated in an unnamed way.
对于 未命名 的 CHECK 约束,它们仍然不会自动包含在批处理过程中。 请注意,此限制包括由 Boolean 或 Enum 数据类型生成的 CHECK 约束,通过 SQLAlchemy 1.3 将自动生成 CHECK 约束并且不能跟踪到反射表,假设它们以未命名的方式生成。
Unnamed constraints can be stated explicitly if they are to be included in the recreated table:
如果要在重新创建的表中包含未命名的约束,则可以显式声明它们:
with op.batch_alter_table("some_table", table_args=[
CheckConstraint('x > 5')
]) as batch_op:
batch_op.add_column(Column('foo', Integer))
batch_op.drop_column('bar')
The above step needs only be taken for CHECK constraints that are explicitly stated as part of the table definition.
上述步骤只需要对明确声明为表定义的一部分的 CHECK 约束进行。
For CHECK constraints that are generated by datatypes such as Boolean or Enum, the type objects themselves must be named in order for their CHECK constraints to be included in the batch process. Boolean and Enum datatypes that do not have the .name attribute set will not have CHECK constraints regenerated. This name can be set by specifying the .name parameter or by using a named Python Enum object as the source of enumeration.
对于由 Boolean 或 Enum 等数据类型生成的 CHECK 约束,必须为类型对象本身命名,以便将它们的 CHECK 约束包含在批处理过程中。 没有设置
.name属性的 Boolean 和 Enum 数据类型将不会重新生成 CHECK 约束。 可以通过指定.name参数或使用命名的 PythonEnum对象作为枚举源来设置此名称。
Dealing with Referencing Foreign Keys
处理引用外键
It is important to note that batch table operations do not work with foreign keys that enforce referential integrity. This because the target table is dropped; if foreign keys refer to it, this will raise an error. On SQLite, whether or not foreign keys actually enforce is controlled by the PRAGMA FOREIGN KEYS pragma; this pragma, if in use, must be disabled when the workflow mode proceeds. When the operation is complete, the batch-migrated table will have the same name that it started with, so those referring foreign keys will again refer to this table.
需要注意的是,批处理表操作 不适用于 强制参照完整性的外键。 这是因为目标表被删除了; 如果外键引用它,这将引发错误。 在 SQLite 上,是否实际执行外键由
PRAGMA FOREIGN KEYS语法控制; 如果正在使用此编译指示,则必须在工作流模式继续时禁用。 操作完成后,批量迁移的表将与开始时的名称相同,因此引用外键的人将再次引用该表。
A special case is dealing with self-referring foreign keys. Here, Alembic takes a special step of recreating the self-referring foreign key as referring to the original table name, rather than at the “temp” table, so that like in the case of other foreign key constraints, when the table is renamed to its original name, the foreign key again references the correct table. This operation only works when referential integrity is disabled, consistent with the same requirement for referring foreign keys from other tables.
一种特殊情况是处理自引用外键。 在这里,Alembic 采取了一个特殊的步骤,将自引用外键重新创建为引用原始表名,而不是在“临时”表中,这样就像在其他外键约束的情况下一样,当表被重命名为它的原始名称,外键再次引用正确的表。 此操作仅在禁用引用完整性时有效,与从其他表引用外键的相同要求一致。
When SQLite’s PRAGMA FOREIGN KEYS mode is turned on, it does provide the service that foreign key constraints, including self-referential, will automatically be modified to point to their table across table renames, however this mode prevents the target table from being dropped as is required by a batch migration. Therefore it may be necessary to manipulate the PRAGMA FOREIGN KEYS setting if a migration seeks to rename a table vs. batch migrate it.
当 SQLite 的
PRAGMA FOREIGN KEYS模式开启时,它确实提供了外键约束的服务,包括自引用, 将自动修改为跨表重命名指向其表,但是此模式可防止目标表按照批量迁移的要求被删除。 因此,如果迁移试图重命名表而不是批量迁移,则可能需要操作PRAGMA FOREIGN KEYS设置。
Working in Offline Mode
在离线模式下工作
In the preceding sections, we’ve seen how much of an emphasis the “move and copy” process has on using reflection in order to know the structure of the table that is to be copied. This means that in the typical case, “online” mode, where a live database connection is present so that Operations.batch_alter_table() can reflect the table from the database, is required; the --sql flag cannot be used without extra steps.
在前面的部分中,我们已经看到 “移动和复制” 过程对于使用反射来了解要复制的表的结构有多么重要。 这意味着在典型情况下,需要“在线”模式,其中存在实时数据库连接,以便 Operations.batch_alter_table() 可以反映数据库中的表; 如果没有额外的步骤,就不能使用
--sql标志。
To support offline mode, the system must work without table reflection present, which means the full table as it intends to be created must be passed to Operations.batch_alter_table() using copy_from:
为了支持离线模式,系统必须在没有表反射的情况下工作,这意味着必须使用 copy_from 将要创建的完整表传递给 Operations.batch_alter_table():
meta = MetaData()
some_table = Table(
'some_table', meta,
Column('id', Integer, primary_key=True),
Column('bar', String(50))
)
with op.batch_alter_table("some_table", copy_from=some_table) as batch_op:
batch_op.add_column(Column('foo', Integer))
batch_op.drop_column('bar')
The above use pattern is pretty tedious and quite far off from Alembic’s preferred style of working; however, if one needs to do SQLite-compatible “move and copy” migrations and need them to generate flat SQL files in “offline” mode, there’s not much alternative.
上述使用模式相当乏味,与 Alembic 喜欢的工作方式相去甚远; 但是,如果需要进行与 SQLite 兼容的“移动和复制”迁移,并需要它们在“离线”模式下生成平面 SQL 文件,则别无选择。
Batch mode with Autogenerate
自动生成和批处理模式
The syntax of batch mode is essentially that Operations.batch_alter_table() is used to enter a batch block, and the returned BatchOperations context works just like the regular Operations context, except that the “table name” and “schema name” arguments are omitted.
批处理模式的语法本质上是 Operations.batch_alter_table() 用于进入批处理块,返回的 BatchOperations 上下文与常规操作上下文一样工作,只是省略了 “table name” 和 “schema name” 参数。
To support rendering of migration commands in batch mode for autogenerate, configure the EnvironmentContext.configure.render_as_batch flag in env.py:
要支持以批处理模式渲染迁移命令以进行自动生成,请在
env.py中配置 EnvironmentContext.configure.render_as_batch 标志:
context.configure(
connection=connection,
target_metadata=target_metadata,
render_as_batch=True
)
Autogenerate will now generate along the lines of:
Autogenerate 现在将按照以下方式生成:
def upgrade():
### commands auto generated by Alembic - please adjust! ###
with op.batch_alter_table('address', schema=None) as batch_op:
batch_op.add_column(sa.Column('street', sa.String(length=50), nullable=True))
This mode is safe to use in all cases, as the Operations.batch_alter_table() directive by default only takes place for SQLite; other backends will behave just as they normally do in the absence of the batch directives.
此模式在所有情况下都可以安全使用,因为默认情况下 Operations.batch_alter_table() 指令仅适用于 SQLite; 在没有批处理指令的情况下,其他后端的行为将与它们通常的行为一样。
Note that autogenerate support does not include “offline” mode, where the Operations.batch_alter_table.copy_from parameter is used. The table definition here would need to be entered into migration files manually if this is needed.
请注意,自动生成支持不包括使用 Operations.batch_alter_table.copy_from 参数的“离线”模式。 如果需要,此处的表定义需要手动输入到迁移文件中。
Batch mode with databases other than SQLite
SQLite 以外的数据库的批处理模式
There’s an odd use case some shops have, where the “move and copy” style of migration is useful in some cases for databases that do already support ALTER. There’s some cases where an ALTER operation may block access to the table for a long time, which might not be acceptable. “move and copy” can be made to work on other backends, though with a few extra caveats.
一些商店有一个奇怪的用例,其中“移动和复制”风格的迁移在某些情况下对于已经支持 ALTER 的数据库很有用。 在某些情况下,ALTER 操作可能会长时间阻止对表的访问,这可能是不可接受的。 “移动和复制” 可以在其他后端工作,尽管有一些额外的警告。
The batch mode directive will run the “recreate” system regardless of backend if the flag recreate='always' is passed:
如果传递了标志
recreate='always',批处理模式指令将运行 “recreate” 系统,而不管后端如何:
with op.batch_alter_table("some_table", recreate='always') as batch_op:
batch_op.add_column(Column('foo', Integer))
The issues that arise in this mode are mostly to do with constraints. Databases such as Postgresql and MySQL with InnoDB will enforce referential integrity (e.g. via foreign keys) in all cases. Unlike SQLite, it’s not as simple to turn off referential integrity across the board (nor would it be desirable). Since a new table is replacing the old one, existing foreign key constraints which refer to the target table will need to be unconditionally dropped before the batch operation, and re-created to refer to the new table afterwards. Batch mode currently does not provide any automation for this.
这种模式下出现的问题主要与约束有关。 在所有情况下,带有 InnoDB 的 Postgresql 和 MySQL 等数据库都将强制执行引用完整性(例如通过外键)。 与 SQLite 不同,全面关闭参照完整性并不那么简单(也不是可取的)。 由于新表正在替换旧表,因此需要在批处理操作之前无条件地删除引用目标表的现有外键约束,然后重新创建以引用新表。 批处理模式目前不为此提供任何自动化。
The Postgresql database and possibly others also have the behavior such that when the new table is created, a naming conflict occurs with the named constraints of the new table, in that they match those of the old table, and on Postgresql, these names need to be unique across all tables. The Postgresql dialect will therefore emit a “DROP CONSTRAINT” directive for all constraints on the old table before the new one is created; this is “safe” in case of a failed operation because Postgresql also supports transactional DDL.
Postgresql 数据库和可能的其他数据库也有这样的行为,即在创建新表时,与新表的命名约束发生命名冲突,因为它们与旧表的约束匹配,并且在 Postgresql 上,这些名称需要 在所有表中都是唯一的。 因此,在创建新表之前,Postgresql 方言将为旧表上的所有约束发出“DROP CONSTRAINT”指令; 这在操作失败的情况下是“安全的”,因为 Postgresql 还支持事务 DDL。
Note that also as is the case with SQLite, CHECK constraints need to be moved over between old and new table manually using the Operations.batch_alter_table.table_args parameter.
请注意,与 SQLite 的情况一样,需要使用 Operations.batch_alter_table.table_args 参数在新旧表之间手动移动 CHECK 约束。
Working with Branches
工作分支
A branch describes a point in a migration stream when two or more versions refer to the same parent migration as their anscestor. Branches occur naturally when two divergent source trees, both containing Alembic revision files created independently within those source trees, are merged together into one. When this occurs, the challenge of a branch is to merge the branches into a single series of changes, so that databases established from either source tree individually can be upgraded to reference the merged result equally. Another scenario where branches are present are when we create them directly; either at some point in the migration stream we’d like different series of migrations to be managed independently (e.g. we create a tree), or we’d like separate migration streams for different features starting at the root (e.g. a forest). We’ll illustrate all of these cases, starting with the most common which is a source-merge-originated branch that we’ll merge.
当两个或多个版本将相同的父迁移作为其祖先时,分支描述了迁移流中的一个点。当两个不同的源代码树(都包含在这些源代码树中独立创建的 Alembic 修订文件)合并为一个时,分支自然会出现。发生这种情况时,分支的挑战是将分支合并为一系列更改,以便从任一源树单独建立的数据库可以升级以平等地引用合并的结果。存在分支的另一种情况是我们直接创建它们时;要么在迁移流中的某个时刻,我们希望独立管理不同系列的迁移(例如,我们创建一棵树),要么我们希望从根开始(例如,森林)为不同的特征提供单独的迁移流。我们将说明所有这些情况,从最常见的开始,即我们将合并的源合并起源分支。
Starting with the “account table” example we began in Create a Migration Script, assume we have our basemost version 1975ea83b712, which leads into the second revision ae1027a6acf, and the migration files for these two revisions are checked into our source repository. Consider if we merged into our source repository another code branch which contained a revision for another table called shopping_cart. This revision was made against our first Alembic revision, the one that generated account. After loading the second source tree in, a new file 27c6a30d7c24_add_shopping_cart_table.py exists within our versions directory. Both it, as well as ae1027a6acf_add_a_column.py, reference 1975ea83b712_add_account_table.py as the “downgrade” revision. To illustrate:
从我们在 创建迁移脚本 中开始的“帐户表”示例开始,假设我们有最基本的版本
1975ea83b712,它导致第二个修订版ae1027a6acf,并且这两个修订版的迁移文件被签入我们的源存储库。 考虑如果我们将另一个代码分支合并到我们的源存储库中,其中包含另一个名为shopping_cart的表的修订。 此修订是针对我们的第一个 Alembic 修订进行的,即生成帐户的修订。 加载第二个源代码树后,我们的版本目录中存在一个新文件27c6a30d7c24_add_shopping_cart_table.py。 它以及ae1027a6acf_add_a_column.py都将1975ea83b712_add_account_table.py引用为“降级”修订版。 为了显示:
# main source tree:
1975ea83b712 (create account table) -> ae1027a6acf (add a column)
# branched source tree
1975ea83b712 (create account table) -> 27c6a30d7c24 (add shopping cart table)
Above, we can see 1975ea83b712 is our branch point; two distinct versions both refer to it as its parent. The Alembic command branches illustrates this fact:
上面,我们可以看到
1975ea83b712是我们的分支点; 两个不同的版本都将其称为其父级。 Alembic 命令branches说明了这一事实:
$ alembic branches --verbose
Rev: 1975ea83b712 (branchpoint)
Parent: <base>
Branches into: 27c6a30d7c24, ae1027a6acf
Path: foo/versions/1975ea83b712_add_account_table.py
create account table
Revision ID: 1975ea83b712
Revises:
Create Date: 2014-11-20 13:02:46.257104
-> 27c6a30d7c24 (head), add shopping cart table
-> ae1027a6acf (head), add a column
History shows it too, illustrating two head entries as well as a branchpoint:
历史也显示了这一点,说明了两个头条
head和一个branchpoint(分支点):
$ alembic history
1975ea83b712 -> 27c6a30d7c24 (head), add shopping cart table
1975ea83b712 -> ae1027a6acf (head), add a column
<base> -> 1975ea83b712 (branchpoint), create account table
We can get a view of just the current heads using alembic heads:
我们可以使用
alembic heads来查看当前的 heads:
$ alembic heads --verbose
Rev: 27c6a30d7c24 (head)
Parent: 1975ea83b712
Path: foo/versions/27c6a30d7c24_add_shopping_cart_table.py
add shopping cart table
Revision ID: 27c6a30d7c24
Revises: 1975ea83b712
Create Date: 2014-11-20 13:03:11.436407
Rev: ae1027a6acf (head)
Parent: 1975ea83b712
Path: foo/versions/ae1027a6acf_add_a_column.py
add a column
Revision ID: ae1027a6acf
Revises: 1975ea83b712
Create Date: 2014-11-20 13:02:54.849677
If we try to run an upgrade to the usual end target of head, Alembic no longer considers this to be an unambiguous command. As we have more than one head, the upgrade command wants us to provide more information:
如果我们尝试
upgrade到通常的最终目标head,Alembic 不再认为这是一个明确的命令。 由于我们有多个head,upgrade命令希望我们提供更多信息:
$ alembic upgrade head
FAILED: Multiple head revisions are present for given argument 'head'; please specify a specific
target revision, '<branchname>@head' to narrow to a specific head, or 'heads' for all heads
The upgrade command gives us quite a few options in which we can proceed with our upgrade, either giving it information on which head we’d like to upgrade towards, or alternatively stating that we’d like all heads to be upgraded towards at once. However, in the typical case of two source trees being merged, we will want to pursue a third option, which is that we can merge these branches.
upgrade命令为我们提供了很多选项,我们可以在其中继续进行upgrade,或者提供有关我们想要upgrade到哪个head的信息,或者说明我们希望同时升级所有head。 然而,在两个源代码树被合并的典型情况下,我们将要追求第三种选择,即我们可以合并这些分支。
Merging Branches
合并分支
An Alembic merge is a migration file that joins two or more “head” files together. If the two branches we have right now can be said to be a “tree” structure, introducing this merge file will turn it into a “diamond” structure:
Alembic 合并是将两个或多个 “head” 文件连接在一起的迁移文件。 如果我们现在的两个分支可以说是一个 “tree” 结构,那么引入这个合并文件就会变成一个 “diamond”(菱形)结构:
-- ae1027a6acf -->
/ \
<base> --> 1975ea83b712 --> --> mergepoint
\ /
-- 27c6a30d7c24 -->
We create the merge file using alembic merge; with this command, we can pass to it an argument such as heads, meaning we’d like to merge all heads. Or, we can pass it individual revision numbers sequentally:
我们使用
alembic merge创建合并文件; 使用这个命令,我们可以向它传递一个参数,例如heads,这意味着我们想要合并所有的heads。 或者,我们可以依次传递单独的修订号:
$ alembic merge -m "merge ae1 and 27c" ae1027 27c6a
Generating /path/to/foo/versions/53fffde5ad5_merge_ae1_and_27c.py ... done
Looking inside the new file, we see it as a regular migration file, with the only new twist is that down_revision points to both revisions:
查看新文件,我们将其视为常规迁移文件,唯一的新变化是
down_revision指向两个修订版:
"""merge ae1 and 27c
Revision ID: 53fffde5ad5
Revises: ae1027a6acf, 27c6a30d7c24
Create Date: 2014-11-20 13:31:50.811663
"""
# revision identifiers, used by Alembic.
revision = '53fffde5ad5'
down_revision = ('ae1027a6acf', '27c6a30d7c24')
branch_labels = None
from alembic import op
import sqlalchemy as sa
def upgrade():
pass
def downgrade():
pass
This file is a regular migration file, and if we wish to, we may place Operations directives into the upgrade() and downgrade() functions like any other migration file. Though it is probably best to limit the instructions placed here only to those that deal with any kind of reconciliation that is needed between the two merged branches, if any.
这个文件是一个常规的迁移文件,如果我们愿意,我们可以像任何其他迁移文件一样将操作指令放入
upgrade()和downgrade()函数中。 尽管最好将此处的说明限制为仅处理两个合并分支之间所需的任何类型的协调(如果有)的说明。
The heads command now illustrates that the multiple heads in our versions/ directory have been resolved into our new head:
现在,
heads命令说明我们的versions/目录中的多个heads已被解析为我们的新head:
$ alembic heads --verbose
Rev: 53fffde5ad5 (head) (mergepoint)
Merges: ae1027a6acf, 27c6a30d7c24
Path: foo/versions/53fffde5ad5_merge_ae1_and_27c.py
merge ae1 and 27c
Revision ID: 53fffde5ad5
Revises: ae1027a6acf, 27c6a30d7c24
Create Date: 2014-11-20 13:31:50.811663
History shows a similar result, as the mergepoint becomes our head:
历史显示了类似的结果,因为合并点成为我们的
head:
$ alembic history
ae1027a6acf, 27c6a30d7c24 -> 53fffde5ad5 (head) (mergepoint), merge ae1 and 27c
1975ea83b712 -> ae1027a6acf, add a column
1975ea83b712 -> 27c6a30d7c24, add shopping cart table
<base> -> 1975ea83b712 (branchpoint), create account table
With a single head target, a generic upgrade can proceed:
使用单个
head目标,可以进行通用upgrade:
$ alembic upgrade head
INFO [alembic.migration] Context impl PostgresqlImpl.
INFO [alembic.migration] Will assume transactional DDL.
INFO [alembic.migration] Running upgrade -> 1975ea83b712, create account table
INFO [alembic.migration] Running upgrade 1975ea83b712 -> 27c6a30d7c24, add shopping cart table
INFO [alembic.migration] Running upgrade 1975ea83b712 -> ae1027a6acf, add a column
INFO [alembic.migration] Running upgrade ae1027a6acf, 27c6a30d7c24 -> 53fffde5ad5, merge ae1 and 27c
merge mechanics
合并机制
The upgrade process traverses through all of our migration files using a topological sorting algorithm, treating the list of migration files not as a linked list, but as a directed acyclic graph. The starting points of this traversal are the current heads within our database, and the end point is the “head” revision or revisions specified.
升级过程使用 拓扑排序 算法遍历我们所有的迁移文件,将迁移文件列表不作为链表,而是作为有向无环图。 此遍历的起点是我们数据库中的 current heads,终点是“head”修订版或指定的修订版。
When a migration proceeds across a point at which there are multiple heads, the alembic_version table will at that point store multiple rows, one for each head. Our migration process above will emit SQL against alembic_version along these lines:
当迁移跨越一个有多个
head的点时,alembic_version表将在该点存储多行,每个head一个。 我们上面的迁移过程将按照以下几行针对alembic_version发出 SQL:
-- Running upgrade -> 1975ea83b712, create account table
INSERT INTO alembic_version (version_num) VALUES ('1975ea83b712')
-- Running upgrade 1975ea83b712 -> 27c6a30d7c24, add shopping cart table
UPDATE alembic_version SET version_num='27c6a30d7c24' WHERE alembic_version.version_num = '1975ea83b712'
-- Running upgrade 1975ea83b712 -> ae1027a6acf, add a column
INSERT INTO alembic_version (version_num) VALUES ('ae1027a6acf')
-- Running upgrade ae1027a6acf, 27c6a30d7c24 -> 53fffde5ad5, merge ae1 and 27c
DELETE FROM alembic_version WHERE alembic_version.version_num = 'ae1027a6acf'
UPDATE alembic_version SET version_num='53fffde5ad5' WHERE alembic_version.version_num = '27c6a30d7c24'
At the point at which both 27c6a30d7c24 and ae1027a6acf exist within our database, both values are present in alembic_version, which now has two rows. If we upgrade to these two versions alone, then stop and run alembic current, we will see this:
在我们的数据库中同时存在
27c6a30d7c24和ae1027a6acf时,这两个值都存在于alembic_version中,现在它有两行。 如果我们单独升级到这两个版本,然后停止并运行alembic current,我们将看到:
$ alembic current --verbose
Current revision(s) for postgresql://scott:XXXXX@localhost/test:
Rev: ae1027a6acf
Parent: 1975ea83b712
Path: foo/versions/ae1027a6acf_add_a_column.py
add a column
Revision ID: ae1027a6acf
Revises: 1975ea83b712
Create Date: 2014-11-20 13:02:54.849677
Rev: 27c6a30d7c24
Parent: 1975ea83b712
Path: foo/versions/27c6a30d7c24_add_shopping_cart_table.py
add shopping cart table
Revision ID: 27c6a30d7c24
Revises: 1975ea83b712
Create Date: 2014-11-20 13:03:11.436407
A key advantage to the merge process is that it will run equally well on databases that were present on version ae1027a6acf alone, versus databases that were present on version 27c6a30d7c24 alone; whichever version was not yet applied, will be applied before the merge point can be crossed. This brings forth a way of thinking about a merge file, as well as about any Alembic revision file. As they are considered to be “nodes” within a set that is subject to topological sorting, each “node” is a point that cannot be crossed until all of its dependencies are satisfied.
合并过程的一个关键优势是,它在单独存在于
ae1027a6acf版本上的数据库上与单独存在于版本27c6a30d7c24上的数据库上运行同样好; 无论哪个版本尚未应用,都将在可以跨越合并点之前应用。 这带来了一种考虑合并文件以及任何 Alembic 修订文件的方式。 由于它们被认为是受拓扑排序的集合中的“节点”,因此每个“节点”都是一个点,在满足其所有依赖关系之前无法跨越。
Prior to Alembic’s support of merge points, the use case of databases sitting on different heads was basically impossible to reconcile; having to manually splice the head files together invariably meant that one migration would occur before the other, thus being incompatible with databases that were present on the other migration.
在 Alembic 支持合并点之前,数据库位于不同头部的用例基本上是无法协调的; 必须手动将头文件拼接在一起, 意味着一个迁移将在另一个迁移之前发生,因此与另一个迁移中存在的数据库不兼容。
Working with Explicit Branches
使用显式分支
The alembic upgrade command hinted at other options besides merging when dealing with multiple heads. Let’s back up and assume we’re back where we have as our heads just ae1027a6acf and 27c6a30d7c24:
alembic upgrade命令暗示了在处理多个head时除了合并之外的其他选项。 让我们备份并假设我们回到了我们头脑中只有ae1027a6acf和27c6a30d7c24的地方:
$ alembic heads
27c6a30d7c24
ae1027a6acf
Earlier, when we did alembic upgrade head, it gave us an error which suggested please specify a specific target revision, '<branchname>@head' to narrow to a specific head, or 'heads' for all heads in order to proceed without merging. Let’s cover those cases.
早些时候,当我们做 alembic upgrade head 时,它给了我们一个错误提示
请指定特定的目标修订,'<branchname>@head'缩小到特定的head,或“heads”用于所有head以便在不合并的情况下继续进行。 让我们涵盖这些情况。
Referring to all heads at once
一次引用到所有的head
The heads identifier is a lot like head, except it explicitly refers to all heads at once. That is, it’s like telling Alembic to do the operation for both ae1027a6acf and 27c6a30d7c24 simultaneously. If we started from a fresh database and ran upgrade heads we’d see:
heads标识符很像head,除了它一次明确地引用所有heads。也就是说,这就像告诉 Alembic 对ae1027a6acf和27c6a30d7c24同时进行操作。如果我们从一个新的数据库开始并运行upgrade heads,我们会看到:
$ alembic upgrade heads
INFO [alembic.migration] Context impl PostgresqlImpl.
INFO [alembic.migration] Will assume transactional DDL.
INFO [alembic.migration] Running upgrade -> 1975ea83b712, create account table
INFO [alembic.migration] Running upgrade 1975ea83b712 -> ae1027a6acf, add a column
INFO [alembic.migration] Running upgrade 1975ea83b712 -> 27c6a30d7c24, add shopping cart table
Since we’ve upgraded to heads, and we do in fact have more than one head, that means these two distinct heads are now in our alembic_version table. We can see this if we run alembic current:
由于我们已经升级到
heads,而且我们实际上有不止一个 head ,这意味着这两个不同的heads现在在我们的alembic_version表中。 如果我们运行alembic current,我们可以看到这一点:
$ alembic current
ae1027a6acf (head)
27c6a30d7c24 (head)
That means there’s two rows in alembic_version right now. If we downgrade one step at a time, Alembic will delete from the alembic_version table each branch that’s closed out, until only one branch remains; then it will continue updating the single value down to the previous versions:
这意味着现在
alembic_version中有两行。 如果我们一次降级一个步骤,Alembic 将从alembic_version表中 删除 每个关闭的分支,直到只剩下一个分支; 然后它将继续将单个值更新到以前的版本:
$ alembic downgrade -1
INFO [alembic.migration] Running downgrade ae1027a6acf -> 1975ea83b712, add a column
$ alembic current
27c6a30d7c24 (head)
$ alembic downgrade -1
INFO [alembic.migration] Running downgrade 27c6a30d7c24 -> 1975ea83b712, add shopping cart table
$ alembic current
1975ea83b712 (branchpoint)
$ alembic downgrade -1
INFO [alembic.migration] Running downgrade 1975ea83b712 -> , create account table
$ alembic current
Referring to a Specific Version
引用特定版本
We can pass a specific version number to upgrade. Alembic will ensure that all revisions upon which this version depends are invoked, and nothing more. So if we upgrade either to 27c6a30d7c24 or ae1027a6acf specifically, it guarantees that 1975ea83b712 will have been applied, but not that any “sibling” versions are applied:
我们可以将特定的版本号传递给
upgrade。 Alembic 将确保调用此版本所依赖的所有修订,仅此而已。 因此,如果我们将upgrade升级到27c6a30d7c24或ae1027a6acf,它保证会应用1975ea83b712,但不会应用任何 “兄弟” 版本:
$ alembic upgrade 27c6a
INFO [alembic.migration] Running upgrade -> 1975ea83b712, create account table
INFO [alembic.migration] Running upgrade 1975ea83b712 -> 27c6a30d7c24, add shopping cart table
With 1975ea83b712 and 27c6a30d7c24 applied, ae1027a6acf is just a single additional step:
应用
1975ea83b712和27c6a30d7c24后,ae1027a6acf只是一个额外的步骤:
$ alembic upgrade ae102
INFO [alembic.migration] Running upgrade 1975ea83b712 -> ae1027a6acf, add a column
Working with Branch Labels
使用分支标注
To satisfy the use case where an environment has long-lived branches, especially independent branches as will be discussed in the next section, Alembic supports the concept of branch labels. These are string values that are present within the migration file, using the new identifier branch_labels. For example, if we want to refer to the “shopping cart” branch using the name “shoppingcart”, we can add that name to our file 27c6a30d7c24_add_shopping_cart_table.py:
为了满足环境具有长期存在的分支的用例,尤其是下一节将讨论的独立分支,Alembic 支持分支标签的概念。 这些是迁移文件中存在的字符串值,使用新的标识符
branch_labels。 例如,如果我们想使用名称“shopping cart”来引用“购物车”分支,我们可以将该名称添加到我们的文件27c6a30d7c24_add_shopping_cart_table.py中:
"""add shopping cart table
"""
# revision identifiers, used by Alembic.
revision = '27c6a30d7c24'
down_revision = '1975ea83b712'
branch_labels = ('shoppingcart',)
# ...
The branch_labels attribute refers to a string name, or a tuple of names, which will now apply to this revision, all descendants of this revision, as well as all ancestors of this revision up until the preceding branch point, in this case 1975ea83b712. We can see the shoppingcart label applied to this revision:
branch_labels属性指的是字符串名称或名称元组,现在将应用于此修订版、此修订版的所有后代,以及此修订版的所有祖先,直到前一个分支点,在本例中为1975ea83b712。 我们可以看到应用于此修订版的shoppingcart标签:
$ alembic history
1975ea83b712 -> 27c6a30d7c24 (shoppingcart) (head), add shopping cart table
1975ea83b712 -> ae1027a6acf (head), add a column
<base> -> 1975ea83b712 (branchpoint), create account table
With the label applied, the name shoppingcart now serves as an alias for the 27c6a30d7c24 revision specifically. We can illustrate this by showing it with alembic show:
应用标签后,名称
shoppingcart现在专门用作27c6a30d7c24修订版的别名。 我们可以通过alembic show展示它来说明这一点:
$ alembic show shoppingcart
Rev: 27c6a30d7c24 (head)
Parent: 1975ea83b712
Branch names: shoppingcart
Path: foo/versions/27c6a30d7c24_add_shopping_cart_table.py
add shopping cart table
Revision ID: 27c6a30d7c24
Revises: 1975ea83b712
Create Date: 2014-11-20 13:03:11.436407
However, when using branch labels, we usually want to use them using a syntax known as “branch at” syntax; this syntax allows us to state that we want to use a specific revision, let’s say a “head” revision, in terms of a specific branch. While normally, we can’t refer to alembic upgrade head when there’s multiple heads, we can refer to this head specifcally using shoppingcart@head syntax:
但是,在使用分支标签时,我们通常希望使用一种称为 “branch at” 的语法来使用它们; 这种语法允许我们声明我们想要使用一个特定的修订,比如说一个 “head” 修订,就特定的分支而言。 虽然通常情况下,当有多个
head时,我们不能引用alembic upgrade head,但我们可以使用shoppingcart@head语法专门引用这个head:
$ alembic upgrade shoppingcart@head
INFO [alembic.migration] Running upgrade 1975ea83b712 -> 27c6a30d7c24, add shopping cart table
The shoppingcart@head syntax becomes important to us if we wish to add new migration files to our versions directory while maintaining multiple branches. Just like the upgrade command, if we attempted to add a new revision file to our multiple-heads layout without a specific parent revision, we’d get a familiar error:
如果我们希望在维护多个分支的同时将新的迁移文件添加到版本目录中,
shoppingcart@head语法对我们来说变得很重要。 就像upgrade命令一样,如果我们试图在没有特定父版本的情况下向多头布局添加新的版本文件,我们会得到一个熟悉的错误:
$ alembic revision -m "add a shopping cart column"
FAILED: Multiple heads are present; please specify the head revision on
which the new revision should be based, or perform a merge.
The alembic revision command is pretty clear in what we need to do; to add our new revision specifically to the shoppingcart branch, we use the --head argument, either with the specific revision identifier 27c6a30d7c24, or more generically using our branchname shoppingcart@head:
alembic revision命令非常清楚我们需要做什么; 为了将我们的新版本专门添加到shoppingcart分支,我们使用--head参数,或者使用特定的版本标识符27c6a30d7c24,或者更一般地使用我们的分支名称shoppingcart@head:
$ alembic revision -m "add a shopping cart column" --head shoppingcart@head
Generating /path/to/foo/versions/d747a8a8879_add_a_shopping_cart_column.py ... done
alembic history shows both files now part of the shoppingcart branch:
alembic history显示两个文件现在都属于shoppingcart分支:
$ alembic history
1975ea83b712 -> ae1027a6acf (head), add a column
27c6a30d7c24 -> d747a8a8879 (shoppingcart) (head), add a shopping cart column
1975ea83b712 -> 27c6a30d7c24 (shoppingcart), add shopping cart table
<base> -> 1975ea83b712 (branchpoint), create account table
We can limit our history operation just to this branch as well:
我们也可以将历史操作限制在这个分支上:
$ alembic history -r shoppingcart:
27c6a30d7c24 -> d747a8a8879 (shoppingcart) (head), add a shopping cart column
1975ea83b712 -> 27c6a30d7c24 (shoppingcart), add shopping cart table
If we want to illustrate the path of shoppingcart all the way from the base, we can do that as follows:
如果我们想说明
shoppingcart从 base 开始的路径,我们可以这样做:
$ alembic history -r :shoppingcart@head
27c6a30d7c24 -> d747a8a8879 (shoppingcart) (head), add a shopping cart column
1975ea83b712 -> 27c6a30d7c24 (shoppingcart), add shopping cart table
<base> -> 1975ea83b712 (branchpoint), create account table
We can run this operation from the “base” side as well, but we get a different result:
我们也可以从“base”端运行这个操作,但是我们得到了不同的结果:
1975ea83b712 -> ae1027a6acf (head), add a column
27c6a30d7c24 -> d747a8a8879 (shoppingcart) (head), add a shopping cart column
1975ea83b712 -> 27c6a30d7c24 (shoppingcart), add shopping cart table
<base> -> 1975ea83b712 (branchpoint), create account table
When we list from shoppingcart@base without an endpoint, it’s really shorthand for -r shoppingcart@base:heads, e.g. all heads, and since shoppingcart@base is the same “base” shared by the ae1027a6acf revision, we get that revision in our listing as well. The <branchname>@base syntax can be useful when we are dealing with individual bases, as we’ll see in the next section.
当我们从
shoppingcart@base列出没有端点时,它实际上是 -rshoppingcart@base:heads 的简写,例如 所有的head,因为shoppingcart@base是ae1027a6acf修订版共享的同一个“基础”,我们也可以在我们的清单中获得该修订版。<branchname>@base语法在我们处理单个碱基时很有用,我们将在下一节中看到。
The <branchname>@head format can also be used with revision numbers instead of branch names, though this is less convenient. If we wanted to add a new revision to our branch that includes the un-labeled ae1027a6acf, if this weren’t a head already, we could ask for the “head of the branch that includes ae1027a6acf” as follows:
<branchname>@head格式也可以与修订号一起使用,而不是分支名称,尽管这样不太方便。 如果我们想向我们的分支添加一个包含未标记的ae1027a6acf的新修订,如果这还不是一个head,我们可以要求“包含 ae1027a6acf 的分支的head”,如下所示:
$ alembic revision -m "add another account column" --head ae10@head
Generating /path/to/foo/versions/55af2cb1c267_add_another_account_column.py ... done
More Label Syntaxes
更多标注语法
The heads symbol can be combined with a branch label, in the case that your labeled branch itself breaks off into multiple branches:
heads符号可以与分支标签结合使用,以防你的标签分支本身分裂成多个分支:
alembic upgrade shoppingcart@heads
Relative identifiers, as introduced in Relative Migration Identifiers, work with labels too. For example, upgrading to shoppingcart@+2 means to upgrade from current heads on “shoppingcart” upwards two revisions:
Relative Migration Identifiers 中介绍的相对标识符也适用于标签。 例如,升级到
shoppingcart@+2意味着将“shoppingcart”上的当前头像向上升级两个版本:
alembic upgrade shoppingcart@+2
This kind of thing works from history as well:
这也适用于历史:
alembic history -r current:shoppingcart@+2
The newer relnum+delta format can be combined as well, for example if we wanted to list along shoppingcart up until two revisions before the head:
更新的
relnum+delta格式也可以组合,例如,如果我们想沿着shoppingcart列出直到head之前的两个修订:
alembic history -r :shoppingcart@head-2
Working with Multiple Bases
基于多个base工作
Note: The multiple base feature is intended to allow for multiple Alembic versioning lineages which share the same alembic_version table. This is so that individual revisions within the lineages can have cross-dependencies on each other. For the simpler case where one project has multiple, completely independent revision lineages that refer to separate alembic_version tables, see the example in Run Multiple Alembic Environments from one .ini file.
注意:多基础功能旨在允许共享同一个
alembic_version表的多个 Alembic 版本控制沿袭。 这样一来,沿袭中的各个修订可以相互交叉依赖。 对于一个项目具有多个、完全独立的修订沿袭的更简单情况,这些修订沿袭引用单独的alembic_version表,请参阅 从一个 .ini 文件运行多个 Alembic 环境 中的示例。
We’ve seen in the previous section that alembic upgrade is fine if we have multiple heads, alembic revision allows us to tell it which “head” we’d like to associate our new revision file with, and branch labels allow us to assign names to branches that we can use in subsequent commands. Let’s put all these together and refer to a new “base”, that is, a whole new tree of revision files that will be semi-independent of the account/shopping cart revisions we’ve been working with. This new tree will deal with database tables involving “networking”.
我们在上一节中已经看到,如果我们有多个头,
alembic upgrade很好,alembic revision允许我们告诉它我们想将我们的新修订文件关联到哪个“head”,并且分支标签允许我们为可以在后续命令中使用的分支分配名称。 让我们把所有这些放在一起并指代一个新的“base”,即一个全新的修订文件树,它将半独立于我们一直在使用的帐户/购物车修订。 这棵新树将处理涉及“networking”的数据库表。
Setting up Multiple Version Directories
设置多版本目录
While optional, it is often the case that when working with multiple bases, we’d like different sets of version files to exist within their own directories; typically, if an application is organized into several sub-modules, each one would have a version directory containing migrations pertinent to that module. So to start out, we can edit alembic.ini to refer to multiple directories; we’ll also state the current versions directory as one of them:
虽然是可选的,但通常情况下,在使用多个基础时,我们希望不同的版本文件集存在于它们自己的目录中; 通常,如果一个应用程序被组织成几个子模块,每个子模块都会有一个版本目录,其中包含与该模块相关的迁移。 因此,首先,我们可以编辑
alembic.ini来引用多个目录; 我们还将当前的versions目录声明为其中之一:
# A separator for the location paths must be defined first.
version_path_separator = os # Use os.pathsep.
# version location specification; this defaults
# to foo/versions. When using multiple version
# directories, initial revisions must be specified with --version-path
version_locations = %(here)s/model/networking:%(here)s/alembic/versions
The new directory %(here)s/model/networking is in terms of where the alembic.ini file is, as we are using the symbol %(here)s which resolves to this location. When we create our first new revision targeted at this directory, model/networking will be created automatically if it does not exist yet. Once we’ve created a revision here, the path is used automatically when generating subsequent revision files that refer to this revision tree.
新目录
%(here)s/model/networking与alembic.ini文件的位置有关,因为我们使用符号%(here)s来解析该位置。 当我们针对这个目录创建第一个新版本时,如果model/networking尚不存在,它将自动创建。 一旦我们在此处创建了修订,在生成引用此修订树的后续修订文件时,将自动使用该路径。
Creating a Labeled Base Revision
创建带标注的基本修订
We also want our new branch to have its own name, and for that we want to apply a branch label to the base. In order to achieve this using the alembic revision command without editing, we need to ensure our script.py.mako file, used for generating new revision files, has the appropriate substitutions present. If Alembic version 0.7.0 or greater was used to generate the original migration environment, this is already done. However when working with an older environment, script.py.mako needs to have this directive added, typically underneath the down_revision directive:
我们还希望我们的新分支有自己的名称,为此我们希望将分支标签应用于基础。 为了在不编辑的情况下使用
alembic revision命令实现这一点,我们需要确保用于生成新修订文件的script.py.mako文件具有适当的替换。 如果使用 Alembic 0.7.0 或更高版本来生成原始迁移环境,这已经完成。 但是,在使用旧环境时,script.py.mako需要添加此指令,通常在down_revision指令下方:
# revision identifiers, used by Alembic.
revision = ${repr(up_revision)}
down_revision = ${repr(down_revision)}
# add this here in order to use revision with branch_label
branch_labels = ${repr(branch_labels)}
With this in place, we can create a new revision file, starting up a branch that will deal with database tables involving networking; we specify the --head version of base, a --branch-label of networking, and the directory we want this first revision file to be placed in with --version-path:
有了这个,我们可以创建一个新的修订文件,启动一个处理涉及网络的数据库表的分支; 我们指定
base的--head版本,networking的--branch-label,以及我们希望使用--version-path放置第一个修订文件的目录:
$ alembic revision -m "create networking branch" --head=base --branch-label=networking --version-path=model/networking
Creating directory /path/to/foo/model/networking ... done
Generating /path/to/foo/model/networking/3cac04ae8714_create_networking_branch.py ... done
If we ran the above command and we didn’t have the newer script.py.mako directive, we’d get this error:
如果我们运行上面的命令并且我们没有更新的
script.py.mako指令,我们会得到这个错误:
FAILED: Version 3cac04ae8714 specified branch_labels networking, however
the migration file foo/model/networking/3cac04ae8714_create_networking_branch.py
does not have them; have you upgraded your script.py.mako to include the 'branch_labels'
section?
When we receive the above error, and we would like to try again, we need to either delete the incorrectly generated file in order to run revision again, or we can edit the 3cac04ae8714_create_networking_branch.py directly to add the branch_labels in of our choosing.
当我们收到上述错误,我们想重试时,我们需要删除错误生成的文件才能再次运行
revision,或者我们可以直接编辑3cac04ae8714_create_networking_branch.py添加我们选择的branch_labels。
Running with Multiple Bases
基于多个base运行
Once we have a new, permanent (for as long as we desire it to be) base in our system, we’ll always have multiple heads present:
一旦我们在我们的系统中有一个新的、永久的(只要我们希望它是)base,我们就会一直有多个head:
$ alembic heads
3cac04ae8714 (networking) (head)
27c6a30d7c24 (shoppingcart) (head)
ae1027a6acf (head)
When we want to add a new revision file to networking, we specify networking@head as the --head. The appropriate version directory is now selected automatically based on the head we choose:
当我们想向
networking添加一个新的修订文件时,我们将networking@head指定为--head。 现在根据我们选择的头自动选择适当的版本目录:
$ alembic revision -m "add ip number table" --head=networking@head
Generating /path/to/foo/model/networking/109ec7d132bf_add_ip_number_table.py ... done
It’s important that we refer to the head using networking@head; if we only refer to networking, that refers to only 3cac04ae8714 specifically; if we specify this and it’s not a head, alembic revision will make sure we didn’t mean to specify the head:
重要的是我们使用 networking@head 来引用 head ; 如果我们只指
networking,那具体指的是3cac04ae8714; 如果我们指定这个并且它不是一个头,alembic revision将确保我们不是要指定头:
$ alembic revision -m "add DNS table" --head=networking
FAILED: Revision 3cac04ae8714 is not a head revision; please
specify --splice to create a new branch from this revision
As mentioned earlier, as this base is independent, we can view its history from the base using history -r networking@base::
如前所述,由于这个base是独立的,我们可以使用
history -r networking@base:从base查看它的历史:
$ alembic history -r networking@base:
109ec7d132bf -> 29f859a13ea (networking) (head), add DNS table
3cac04ae8714 -> 109ec7d132bf (networking), add ip number table
<base> -> 3cac04ae8714 (networking), create networking branch
At the moment, this is the same output we’d get at this point if we used -r :networking@head. However, that will change later on as we use additional directives.
目前,如果我们使用
-r :networking@head,这与我们此时得到的输出相同。 然而,随着我们使用额外的指令,这将在稍后改变。
We may now run upgrades or downgrades freely, among individual branches (let’s assume a clean database again):
我们现在可以在各个分支之间自由地运行 upgrades 或 downgrades (让我们再次假设一个干净的数据库):
$ alembic upgrade networking@head
INFO [alembic.migration] Running upgrade -> 3cac04ae8714, create networking branch
INFO [alembic.migration] Running upgrade 3cac04ae8714 -> 109ec7d132bf, add ip number table
INFO [alembic.migration] Running upgrade 109ec7d132bf -> 29f859a13ea, add DNS table
or against the whole thing using heads:
或使用
heads替换全部事情:
$ alembic upgrade heads
INFO [alembic.migration] Running upgrade -> 1975ea83b712, create account table
INFO [alembic.migration] Running upgrade 1975ea83b712 -> 27c6a30d7c24, add shopping cart table
INFO [alembic.migration] Running upgrade 27c6a30d7c24 -> d747a8a8879, add a shopping cart column
INFO [alembic.migration] Running upgrade 1975ea83b712 -> ae1027a6acf, add a column
INFO [alembic.migration] Running upgrade ae1027a6acf -> 55af2cb1c267, add another account column
Branch Dependencies
When working with multiple roots, it is expected that these different revision streams will need to refer to one another. For example, a new revision in networking which needs to refer to the account table will want to establish 55af2cb1c267, add another account column, the last revision that works with the account table, as a dependency. From a graph perspective, this means nothing more that the new file will feature both 55af2cb1c267, add another account column and 29f859a13ea, add DNS table as “down” revisions, and looks just as though we had merged these two branches together. However, we don’t want to consider these as “merged”; we want the two revision streams to remain independent, even though a version in networking is going to reach over into the other stream. To support this use case, Alembic provides a directive known as depends_on, which allows a revision file to refer to another as a “dependency”, very similar to an entry in down_revision from a graph perspective, but different from a semantic perspective.
当使用多个根时,预计这些不同的修订流将需要相互引用。例如,需要引用
account表的networking中的新修订版将要建立55af2cb1c267,添加另一个account列,即与account表一起使用的最后一个修订版,作为依赖项。从图表的角度来看,这仅意味着新文件将同时包含55af2cb1c267,添加另一个“account”列和29f859a13ea,添加 DNS 表作为 “down” 修订,看起来就像我们将这两个分支合并在一起.但是,我们不想将这些视为“merge”;我们希望两个修订流保持独立,即使networking中的一个版本将延伸到另一个流。为了支持这个用例,Alembic 提供了一个名为depends_on的指令,它允许修订文件将另一个文件称为“依赖项”,从图形的角度来看,这与down_revision中的条目非常相似,但不同于语义看法。
To use depends_on, we can specify it as part of our alembic revision command:
要使用
depends_on,我们可以将其指定为alembic revision命令的一部分:
$ alembic revision -m "add ip account table" --head=networking@head --depends-on=55af2cb1c267
Generating /path/to/foo/model/networking/2a95102259be_add_ip_account_table.py ... done
Within our migration file, we’ll see this new directive present:
在我们的迁移文件中,我们将看到这个新指令:
# revision identifiers, used by Alembic.
revision = '2a95102259be'
down_revision = '29f859a13ea'
branch_labels = None
depends_on='55af2cb1c267'
depends_on may be either a real revision number or a branch name. When specified at the command line, a resolution from a partial revision number will work as well. It can refer to any number of dependent revisions as well; for example, if we were to run the command:
depends_on可以是真实的修订号或分支名称。 当在命令行中指定时,部分修订号的解析也将起作用。 它也可以引用任意数量的相关修订; 例如,如果我们要运行命令:
$ alembic revision -m "add ip account table" \\
--head=networking@head \\
--depends-on=55af2cb1c267 --depends-on=d747a --depends-on=fa445
Generating /path/to/foo/model/networking/2a95102259be_add_ip_account_table.py ... done
We’d see inside the file:
我们会在文件中看到:
# revision identifiers, used by Alembic.
revision = '2a95102259be'
down_revision = '29f859a13ea'
branch_labels = None
depends_on = ('55af2cb1c267', 'd747a8a8879', 'fa4456a9201')
We also can of course add or alter this value within the file manually after it is generated, rather than using the --depends-on argument.
我们当然也可以在文件生成后手动添加或更改此值,而不是使用
--depends-on参数。
We can see the effect this directive has when we view the history of the networking branch in terms of “heads”, e.g., all the revisions that are descendants:
当我们以“heads”的形式查看“networking”分支的历史时,我们可以看到该指令的效果,例如,所有作为后代的修订:
$ alembic history -r :networking@head
29f859a13ea (55af2cb1c267) -> 2a95102259be (networking) (head), add ip account table
109ec7d132bf -> 29f859a13ea (networking), add DNS table
3cac04ae8714 -> 109ec7d132bf (networking), add ip number table
<base> -> 3cac04ae8714 (networking), create networking branch
ae1027a6acf -> 55af2cb1c267 (effective head), add another account column
1975ea83b712 -> ae1027a6acf, Add a column
<base> -> 1975ea83b712 (branchpoint), create account table
What we see is that the full history of the networking branch, in terms of an “upgrade” to the “head”, will include that the tree building up 55af2cb1c267, add another account column will be pulled in first. Interstingly, we don’t see this displayed when we display history in the other direction, e.g. from networking@base:
我们看到的是,
networking分支的完整历史记录,就“upgrade”到“head”而言,将包括构建55af2cb1c267, add another account column的树将首先被拉入。 有趣的是,当我们在另一个方向显示历史记录时,我们看不到这一点,例如 来自networking@base:
$ alembic history -r networking@base:
29f859a13ea (55af2cb1c267) -> 2a95102259be (networking) (head), add ip account table
109ec7d132bf -> 29f859a13ea (networking), add DNS table
3cac04ae8714 -> 109ec7d132bf (networking), add ip number table
<base> -> 3cac04ae8714 (networking), create networking branch
The reason for the discrepancy is that displaying history from the base shows us what would occur if we ran a downgrade operation, instead of an upgrade. If we downgraded all the files in networking using networking@base, the dependencies aren’t affected, they’re left in place.
出现差异的原因是,显示基础的历史记录向我们展示了如果我们运行降级操作而不是升级会发生什么。 如果我们使用
networking@base降级networking中的所有文件,则依赖关系不会受到影响,它们会保留在原处。
We also see something odd if we view heads at the moment:
如果我们现在查看
heads,我们也会看到一些奇怪的东西:
$ alembic heads
2a95102259be (networking) (head)
27c6a30d7c24 (shoppingcart) (head)
55af2cb1c267 (effective head)
The head file that we used as a “dependency”, 55af2cb1c267, is displayed as an “effective” head, which we can see also in the history display earlier. What this means is that at the moment, if we were to upgrade all versions to the top, the 55af2cb1c267 revision number would not actually be present in the alembic_version table; this is because it does not have a branch of its own subsequent to the 2a95102259be revision which depends on it:
我们用作“依赖”的head文件“55af2cb1c267”显示为 “effective” head,我们也可以在前面的历史显示中看到。 这意味着目前,如果我们将所有版本升级到顶部,则
55af2cb1c267修订号实际上不会出现在alembic_version表中; 这是因为它在依赖于它的2a95102259be修订版之后没有自己的分支:
$ alembic upgrade heads
INFO [alembic.migration] Running upgrade 29f859a13ea, 55af2cb1c267 -> 2a95102259be, add ip account table
$ alembic current
2a95102259be (head)
27c6a30d7c24 (head)
The entry is still displayed in alembic heads because Alembic knows that even though this revision isn’t a “real” head, it’s still something that we developers consider semantically to be a head, so it’s displayed, noting its special status so that we don’t get quite as confused when we don’t see it within alembic current.
该条目仍然显示在
alembic heads中,因为 Alembic 知道即使此修订版不是“真正的”head,它仍然是我们开发人员在语义上认为是head的东西,所以它被显示,并指出它的特殊状态,以便当我们在“alembic current”中看不到它时,我们不会那么困惑。
If we add a new revision onto 55af2cb1c267, the branch again becomes a “real” branch which can have its own entry in the database:
如果我们在
55af2cb1c267上添加一个新版本,该分支再次成为一个“真正的”分支,它可以在数据库中拥有自己的条目:
$ alembic revision -m "more account changes" --head=55af2cb@head
Generating /path/to/foo/versions/34e094ad6ef1_more_account_changes.py ... done
$ alembic upgrade heads
INFO [alembic.migration] Running upgrade 55af2cb1c267 -> 34e094ad6ef1, more account changes
$ alembic current
2a95102259be (head)
27c6a30d7c24 (head)
34e094ad6ef1 (head)
For posterity, the revision tree now looks like:
对于后代,修订树现在看起来像:
$ alembic history
29f859a13ea (55af2cb1c267) -> 2a95102259be (networking) (head), add ip account table
109ec7d132bf -> 29f859a13ea (networking), add DNS table
3cac04ae8714 -> 109ec7d132bf (networking), add ip number table
<base> -> 3cac04ae8714 (networking), create networking branch
1975ea83b712 -> 27c6a30d7c24 (shoppingcart) (head), add shopping cart table
55af2cb1c267 -> 34e094ad6ef1 (head), more account changes
ae1027a6acf -> 55af2cb1c267, add another account column
1975ea83b712 -> ae1027a6acf, Add a column
<base> -> 1975ea83b712 (branchpoint), create account table
--- 27c6 --> d747 --> <head>
/ (shoppingcart)
<base> --> 1975 -->
\
--- ae10 --> 55af --> <head>
^
+--------+ (dependency)
|
|
<base> --> 3782 -----> 109e ----> 29f8 ---> 2a95 --> <head>
(networking)
If there’s any point to be made here, it’s if you are too freely branching, merging and labeling, things can get pretty crazy! Hence the branching system should be used carefully and thoughtfully for best results.
如果这里有什么要说的,那就是如果你过于自由地分支、合并和标记,事情会变得非常疯狂! 因此,应谨慎使用分支系统以获得最佳结果。
Operation Reference
操作参考
This file provides documentation on Alembic migration directives.
此文件提供有关 Alembic 迁移指令的文档。
The directives here are used within user-defined migration files, within the upgrade() and downgrade() functions, as well as any functions further invoked by those.
此处的指令用于 用户定义的迁移文件、upgrade() 和 downgrade() 函数以及由这些函数进一步调用的任何函数。
All directives exist as methods on a class called Operations. When migration scripts are run, this object is made available to the script via the alembic.op datamember, which is a proxy to an actual instance of Operations. Currently, alembic.op is a real Python module, populated with individual proxies for each method on Operations, so symbols can be imported safely from the alembic.op namespace.
所有指令都作为称为 Operations 的类上的方法存在。 运行迁移脚本时,该对象通过
alembic.op数据成员对脚本可用,该数据成员是操作的实际实例的代理。 目前,alembic.op是一个真正的 Python 模块,为操作上的每个方法填充了单独的代理,因此可以从alembic.op命名空间安全地导入符号。
The Operations system is also fully extensible. See Operation Plugins for details on this.
Operations系统 也是完全可扩展的。 有关这方面的详细信息,请参阅 Operation Plugins 。
A key design philosophy to the Operation Directives methods is that to the greatest degree possible, they internally generate the appropriate SQLAlchemy metadata, typically involving Table and Constraint objects. This so that migration instructions can be given in terms of just the string names and/or flags involved. The exceptions to this rule include the add_column() and create_table() directives, which require full Column objects, though the table metadata is still generated here.
Operation Directives 方法的一个关键设计理念是尽可能地在内部生成适当的 SQLAlchemy 元数据,通常涉及 Table 和 Constraint 对象。 这样就可以仅根据所涉及的字符串名称和/或标志给出迁移指令。 此规则的例外情况包括 add_column() 和 create_table() 指令,它们需要完整的 Column 对象,但仍会在此处生成表元数据。
The functions here all require that a MigrationContext has been configured within the env.py script first, which is typically via EnvironmentContext.configure(). Under normal circumstances they are called from an actual migration script, which itself would be invoked by the EnvironmentContext.run_migrations() method.
这里的函数都需要首先在
env.py脚本中配置 MigrationContext,这通常是通过 EnvironmentContext.configure()。 在正常情况下,它们是从实际的迁移脚本中调用的,该脚本本身将由 EnvironmentContext.run_migrations() 方法调用。
alembic.operations.Operations
class alembic.operations.Operations(migration_context: MigrationContext, impl: Optional[BatchOperationsImpl] = None)
Define high level migration operations.
定义高级迁移操作。
Each operation corresponds to some schema migration operation, executed against a particular MigrationContext which in turn represents connectivity to a database, or a file output stream.
每个操作对应于一些模式迁移操作,针对特定的 MigrationContext 执行,而后者又表示与数据库或文件输出流的连接。
While Operations is normally configured as part of the EnvironmentContext.run_migrations() method called from an env.py script, a standalone Operations instance can be made for use cases external to regular Alembic migrations by passing in a MigrationContext:
虽然 Operations 通常配置为从
env.py脚本调用的 EnvironmentContext.run_migrations() 方法的一部分,但可以通过传入 MigrationContext 为常规 Alembic 迁移之外的用例创建独立的 Operations实例:
from alembic.migration import MigrationContext
from alembic.operations import Operations
conn = myengine.connect()
ctx = MigrationContext.configure(conn)
op = Operations(ctx)
op.alter_column("t", "c", nullable=True)
Note that as of 0.8, most of the methods on this class are produced dynamically using the Operations.register_operation() method.
请注意,从 0.8 开始,此类中的大多数方法都是使用 Operations.register_operation() 方法动态生成的。
Construct a new Operations
构建一个新的 Operations
参数:
migration_context – a MigrationContext instance. (一个 MigrationContext 实例)
add_column
add_column(table_name: str, column: Column, schema: Optional[str] = None) → Optional[Table]
Issue an “add column” instruction using the current migration context.
使用当前迁移上下文发出“添加列”指令。
e.g.:
from alembic import op
from sqlalchemy import Column, String
op.add_column('organization',
Column('name', String())
)
The provided Column object can also specify a ForeignKey, referencing a remote table name. Alembic will automatically generate a stub “referenced” table and emit a second ALTER statement in order to add the constraint separately:
提供的 Column 对象还可以指定一个 ForeignKey,引用一个远程表名。 Alembic 将自动生成一个存根“引用”表并发出第二个 ALTER 语句,以便单独添加约束:
from alembic import op
from sqlalchemy import Column, INTEGER, ForeignKey
op.add_column('organization',
Column('account_id', INTEGER, ForeignKey('accounts.id'))
)
Note that this statement uses the Column construct as is from the SQLAlchemy library. In particular,
defaultvalues to be created on the database side are specified using theserver_defaultparameter, and notdefaultwhich only specifies Python-side defaults:
注意: 该语句使用 SQLAlchemy 库中的 Column 构造。 特别是,要在数据库端创建的默认值是使用
server_default参数指定的,而不是default,它只指定 Python 端的默认值:
Parameters:
参数:
- table_name – String name of the parent table.
- column – a sqlalchemy.schema.Column object representing the new column.
- schema – Optional schema name to operate within. To control quoting of the schema outside of the default behavior, use the SQLAlchemy construct quoted_name.
- table_name – 父表的字符串名称。
- column – 表示新列的 sqlalchemy.schema.Column 对象。
- schema – 要在其中操作的可选 schema 名称。 要控制默认行为之外的 schema 引用,请使用 SQLAlchemy 构造 quoted_name。
alter_column
alter_column(table_name: str, column_name: str, nullable: Optional[bool] = None, comment: Optional[Union[str, bool]] = False, server_default: Any = False, new_column_name: Optional[str] = None, type_: Optional[Union[TypeEngine, Type[TypeEngine]]] = None, existing_type: Optional[Union[TypeEngine, Type[TypeEngine]]] = None, existing_server_default: Optional[Union[str, bool, Identity, Computed]] = False, existing_nullable: Optional[bool] = None, existing_comment: Optional[str] = None, schema: Optional[str] = None, **kw) → Optional[Table]
Issue an “alter column” instruction using the current migration context.
使用当前迁移上下文发出“alter column”指令。
Generally, only that aspect of the column which is being changed, i.e. name, type, nullability, default, needs to be specified. Multiple changes can also be specified at once and the backend should “do the right thing”, emitting each change either separately or together as the backend allows.
通常,只需要指定正在更改的列的某些方面,即名称、类型、可空性、默认值。 也可以一次指定多个更改,并且后端应该“做正确的事情”,在后端允许的情况下单独或一起发出每个更改。
MySQL has special requirements here, since MySQL cannot ALTER a column without a full specification. When producing MySQL-compatible migration files, it is recommended that the existing_type, existing_server_default, and existing_nullable parameters be present, if not being altered.
MySQL 在这里有特殊要求,因为 MySQL 不能在没有完整规范的情况下 ALTER 列。 在生成与 MySQL 兼容的迁移文件时,如果未更改,建议提供
existing_type、existing_server_default和existing_nullable参数。
Type changes which are against the SQLAlchemy “schema” types Boolean and Enum may also add or drop constraints which accompany those types on backends that don’t support them natively. The existing_type argument is used in this case to identify and remove a previous constraint that was bound to the type object.
与 SQLAlchemy “schema” 类型 Boolean 和 Enum 相抵触的类型更改也可能会添加或删除伴随这些类型在本机不支持它们的后端上的约束。
在这种情况下,existing_type参数用于识别和删除绑定到类型对象的先前约束。
Parameters:
- table_name – string name of the target table.
- column_name – string name of the target column, as it exists before the operation begins.
- nullable – Optional; specify
TrueorFalseto alter the column’s nullability. - server_default – Optional; specify a string SQL expression, text(), or DefaultClause to indicate an alteration to the column’s default value. Set to
Noneto have the default removed. - comment – optional string text of a new comment to add to the column.
- New in version 1.0.6.
- new_column_name – Optional; specify a string name here to indicate the new name within a column rename operation.
- type_ – Optional; a TypeEngine type object to specify a change to the column’s type. For SQLAlchemy types that also indicate a constraint (i.e. Boolean, Enum), the constraint is also generated.
- autoincrement – set the
AUTO_INCREMENTflag of the column; currently understood by the MySQL dialect. - existing_type – Optional; a TypeEngine type object to specify the previous type. This is required for all MySQL column alter operations that don’t otherwise specify a new type, as well as for when nullability is being changed on a SQL Server column. It is also used if the type is a so-called SQLlchemy “schema” type which may define a constraint (i.e. Boolean, Enum), so that the constraint can be dropped.
- existing_server_default – Optional; The existing default value of the column. Required on MySQL if an existing default is not being changed; else MySQL removes the default.
- existing_nullable – Optional; the existing nullability of the column. Required on MySQL if the existing nullability is not being changed; else MySQL sets this to NULL.
- existing_autoincrement – Optional; the existing autoincrement of the column. Used for MySQL’s system of altering a column that specifies
AUTO_INCREMENT. - existing_comment – string text of the existing comment on the column to be maintained. Required on MySQL if the existing comment on the column is not being changed.
- New in version 1.0.6.
- schema – Optional schema name to operate within. To control quoting of the schema outside of the default behavior, use the SQLAlchemy construct quoted_name.
- postgresql_using – String argument which will indicate a SQL expression to render within the Postgresql-specific USING clause within ALTER COLUMN. This string is taken directly as raw SQL which must explicitly include any necessary quoting or escaping of tokens within the expression.
参数:
- table_name – 目标表的字符串名称。
- column_name – 目标列的字符串名称,因为它在操作开始之前就存在。
- nullable – 可选; 指定为
True或False改变列的可空性. - server_default – 可选; 指定字符串
SQL 表达式、text() 或 DefaultClause 以指示对列默认值的更改。 设置为None以删除默认值。 - comment – 可选; 要添加到列的新注释的字符串文本。
版本 1.0.6.新增
- new_column_name – 可选; 在此处指定字符串名称以指示列重命名操作中的新名称。
- type_ – 可选; 一个 TypeEngine 类型对象,用于指定对列类型的更改。 对于也指示约束(即 Boolean、Enum)的 SQLAlchemy 类型,也会生成约束。
- autoincrement – 设置列的
AUTO_INCREMENT标志; 目前被MySQL方言所理解。 - existing_type – 可选; 一个 TypeEngine 类型对象来指定以前的类型。 这对于所有未指定新类型的 MySQL 列更改操作以及在 SQL Server 列上更改可空性时都是必需的。 如果类型是所谓的 SQLlchemy “schema” 类型,它也可以定义一个约束(即**Boolean、Enum**),以便可以删除约束。
- existing_server_default – 可选; 列的现有默认值。 如果未更改现有默认值,则在 MySQL 上是必需提供的; 否则 MySQL 将删除默认值。
- existing_nullable – 可选; 列的现有可空性。 如果没有更改现有的可空性,则在 MySQL 上是必需提供的; 否则 MySQL 将其设置为
NULL。 - existing_autoincrement – 可选; 列的现有自动增量。 用于 MySQL 系统更改指定
AUTO_INCREMENT的列。 - existing_comment – 要维护的列上现有注释的字符串文本。 如果未更改列上的现有注释,则在 MySQL 上是必需的。
版本 1.0.6.新增
- schema – 要在其中操作的可选 schema 名称。 要控制默认行为之外的模式引用,请使用 SQLAlchemy 构造 quoted_name。
- postgresql_using – 字符串参数,它将指示要在 ALTER COLUMN 中的 Postgresql 特定的 USING 子句中呈现的 SQL 表达式。 该字符串被直接视为原始 SQL,它必须在表达式中显式地包含任何必要的标记引用或转义。
batch_alter_table
batch_alter_table(table_name, schema=None, recreate='auto', partial_reordering=None, copy_from=None, table_args=(), table_kwargs={}, reflect_args=(), reflect_kwargs={}, naming_convention=None)
Invoke a series of per-table migrations in batch.
Batch mode allows a series of operations specific to a table to be syntactically grouped together, and allows for alternate modes of table migration, in particular the “recreate” style of migration required by SQLite.
“recreate” style is as follows:
- A new table is created with the new specification, based on the migration directives within the batch, using a temporary name.
- the data copied from the existing table to the new table.
- the existing table is dropped.
- the new table is renamed to the existing table name.
The directive by default will only use “recreate” style on the SQLite backend, and only if directives are present which require this form, e.g. anything other than add_column(). The batch operation on other backends will proceed using standard ALTER TABLE operations.
The method is used as a context manager, which returns an instance of BatchOperations; this object is the same as Operations except that table names and schema names are omitted. E.g.:
with op.batch_alter_table("some_table") as batch_op:
batch_op.add_column(Column('foo', Integer))
batch_op.drop_column('bar')
The operations within the context manager are invoked at once when the context is ended. When run against SQLite, if the migrations include operations not supported by SQLite’s ALTER TABLE, the entire table will be copied to a new one with the new specification, moving all data across as well.
The copy operation by default uses reflection to retrieve the current structure of the table, and therefore batch_alter_table() in this mode requires that the migration is run in “online” mode. The copy_from parameter may be passed which refers to an existing Table object, which will bypass this reflection step.
Note The table copy operation will currently not copy CHECK constraints, and may not copy UNIQUE constraints that are unnamed, as is possible on SQLite. See the section Dealing with Constraints for workarounds.
Parameters:
-
table_name – name of table
-
schema – optional schema name.
-
recreate – under what circumstances the table should be recreated. At its default of
"auto", the SQLite dialect will recreate the table if any operations other thanadd_column(),create_index(), ordrop_index()are present. Other options include"always"and"never". -
copy_from – optional Table object that will act as the structure of the table being copied. If omitted, table reflection is used to retrieve the structure of the table.
See also Working in Offline Mode
reflect_args
reflect_kwargs
-
reflect_args – a sequence of additional positional arguments that will be applied to the table structure being reflected / copied; this may be used to pass column and constraint overrides to the table that will be reflected, in lieu of passing the whole Table using copy_from.
-
reflect_kwargs – a dictionary of additional keyword arguments that will be applied to the table structure being copied; this may be used to pass additional table and reflection options to the table that will be reflected, in lieu of passing the whole Table using copy_from.
-
table_args – a sequence of additional positional arguments that will be applied to the new Table when created, in addition to those copied from the source table. This may be used to provide additional constraints such as CHECK constraints that may not be reflected.
-
table_args – a sequence of additional positional arguments that will be applied to the new Table when created, in addition to those copied from the source table. This may be used to provide additional constraints such as CHECK constraints that may not be reflected.
-
table_kwargs – a dictionary of additional keyword arguments that will be applied to the new Table when created, in addition to those copied from the source table. This may be used to provide for additional table options that may not be reflected.
-
naming_convention – a naming convention dictionary of the form described at Integration of Naming Conventions into Operations, Autogenerate which will be applied to the MetaData during the reflection process. This is typically required if one wants to drop SQLite constraints, as these constraints will not have names when reflected on this backend. Requires SQLAlchemy 0.9.4 or greater.
See also
-
partial_reordering – a list of tuples, each suggesting a desired ordering of two or more columns in the newly created table. Requires that batch_alter_table.recreate is set to
"always". Examples, given a table with columns “a”, “b”, “c”, and “d”:Specify the order of all columns:
with op.batch_alter_table( "some_table", recreate="always", partial_reordering=[("c", "d", "a", "b")] ) as batch_op: passEnsure “d” appears before “c”, and “b”, appears before “a”:
with op.batch_alter_table( "some_table", recreate="always", partial_reordering=[("d", "c"), ("b", "a")] ) as batch_op: passThe ordering of columns not included in the partial_reordering set is undefined. Therefore it is best to specify the complete ordering of all columns for best results.
New in version 1.4.0.
Note: batch mode requires SQLAlchemy 0.8 or above.
See also Running “Batch” Migrations for SQLite and Other Databases
bulk_insert
bulk_insert(table: Union[Table, TableClause], rows: List[dict], multiinsert: bool = True) → None
Issue a “bulk insert” operation using the current migration context.
This provides a means of representing an INSERT of multiple rows which works equally well in the context of executing on a live connection as well as that of generating a SQL script. In the case of a SQL script, the values are rendered inline into the statement.
e.g.:
from alembic import op
from datetime import date
from sqlalchemy.sql import table, column
from sqlalchemy import String, Integer, Date
# Create an ad-hoc table to use for the insert statement.
accounts_table = table('account',
column('id', Integer),
column('name', String),
column('create_date', Date)
)
op.bulk_insert(accounts_table,
[
{'id':1, 'name':'John Smith',
'create_date':date(2010, 10, 5)},
{'id':2, 'name':'Ed Williams',
'create_date':date(2007, 5, 27)},
{'id':3, 'name':'Wendy Jones',
'create_date':date(2008, 8, 15)},
]
)
When using –sql mode, some datatypes may not render inline automatically, such as dates and other special types. When this issue is present, Operations.inline_literal() may be used:
op.bulk_insert(accounts_table,
[
{'id':1, 'name':'John Smith',
'create_date':op.inline_literal("2010-10-05")},
{'id':2, 'name':'Ed Williams',
'create_date':op.inline_literal("2007-05-27")},
{'id':3, 'name':'Wendy Jones',
'create_date':op.inline_literal("2008-08-15")},
],
multiinsert=False
)
When using Operations.inline_literal() in conjunction with Operations.bulk_insert(), in order for the statement to work in “online” (e.g. non –sql) mode, the multiinsert flag should be set to False, which will have the effect of individual INSERT statements being emitted to the database, each with a distinct VALUES clause, so that the “inline” values can still be rendered, rather than attempting to pass the values as bound parameters.
Parameters:
- table – a table object which represents the target of the INSERT.
- rows – a list of dictionaries indicating rows.
- multiinsert – when at its default of True and –sql mode is not enabled, the INSERT statement will be executed using “executemany()” style, where all elements in the list of dictionaries are passed as bound parameters in a single list. Setting this to False results in individual INSERT statements being emitted per parameter set, and is needed in those cases where non-literal values are present in the parameter sets.
create_check_constraint
create_check_constraint(constraint_name: Optional[str], table_name: str, condition: Union[str, BinaryExpression], schema: Optional[str] = None, **kw) → Optional[Table]
Issue a “create check constraint” instruction using the current migration context.
e.g.:
from alembic import op
from sqlalchemy.sql import column, func
op.create_check_constraint(
"ck_user_name_len",
"user",
func.len(column('name')) > 5
)
CHECK constraints are usually against a SQL expression, so ad-hoc table metadata is usually needed. The function will convert the given arguments into a sqlalchemy.schema.CheckConstraint bound to an anonymous table in order to emit the CREATE statement.
Parameters:
- name – Name of the check constraint. The
nameis necessary so that an ALTER statement can be emitted. For setups that use an automated naming scheme such as that described at Configuring Constraint Naming Conventions,namehere can beNone, as the event listener will apply thenameto the constraint object when it is associated with the table. - table_name – String name of the source table.
- condition – SQL expression that’s the condition of the constraint. Can be a string or SQLAlchemy expression language structure.
- deferrable – optional bool. If set, emit DEFERRABLE or NOT DEFERRABLE when issuing DDL for this constraint.
- initially – optional string. If set, emit INITIALLY
when issuing DDL for this constraint. - schema – Optional schema name to operate within. To control quoting of the schema outside of the default behavior, use the SQLAlchemy construct quoted_name.
create_exclude_constraint
create_exclude_constraint(constraint_name: str, table_name: str, *elements: Any, **kw: Any) → Optional[Table]
Issue an alter to create an EXCLUDE constraint using the current migration context.
Note: This method is Postgresql specific, and additionally requires at least SQLAlchemy 1.0.
e.g.:
from alembic import op
op.create_exclude_constraint(
"user_excl",
"user",
("period", '&&'),
("group", '='),
where=("group != 'some group'")
)
Note that the expressions work the same way as that of the
ExcludeConstraintobject itself; if plain strings are passed, quoting rules must be applied manually.
Parameters:
- name – Name of the constraint.
- table_name – String name of the source table.
- elements – exclude conditions.
- where – SQL expression or SQL string with optional WHERE clause.
- deferrable – optional bool. If set, emit DEFERRABLE or NOT DEFERRABLE when issuing DDL for this constraint.
- initially – optional string. If set, emit INITIALLY
when issuing DDL for this constraint. - schema – Optional schema name to operate within.
create_foreign_key
create_foreign_key(constraint_name: Optional[str], source_table: str, referent_table: str, local_cols: List[str], remote_cols: List[str], onupdate: Optional[str] = None, ondelete: Optional[str] = None, deferrable: Optional[bool] = None, initially: Optional[str] = None, match: Optional[str] = None, source_schema: Optional[str] = None, referent_schema: Optional[str] = None, **dialect_kw) → Optional[Table]
Issue a “create foreign key” instruction using the current migration context.
e.g.:
from alembic import op
op.create_foreign_key(
"fk_user_address", "address",
"user", ["user_id"], ["id"])
This internally generates a Table object containing the necessary columns, then generates a new ForeignKeyConstraint object which it then associates with the Table. Any event listeners associated with this action will be fired off normally. The AddConstraint construct is ultimately used to generate the ALTER statement.
Parameters:
- constraint_name – Name of the foreign key constraint. The
nameis necessary so that an ALTER statement can be emitted. For setups that use an automated naming scheme such as that described at Configuring Constraint Naming Conventions,namehere can beNone, as the event listener will apply thenameto the constraint object when it is associated with the table. - source_table – String name of the source table.
- referent_table – String name of the destination table.
- local_cols – a list of string column names in the source table.
- remote_cols – a list of string column names in the remote table.
- onupdate – Optional string. If set, emit ON UPDATE
<value>when issuing DDL for this constraint. Typical values include CASCADE, DELETE and RESTRICT. - ondelete – Optional string. If set, emit ON DELETE
<value>when issuing DDL for this constraint. Typical values include CASCADE, DELETE and RESTRICT. - deferrable – optional bool. If set, emit DEFERRABLE or NOT DEFERRABLE when issuing DDL for this constraint.
- source_schema – Optional schema name of the source table.
- referent_schema – Optional schema name of the destination table.
create_index
create_index(index_name: str, table_name: str, columns: Sequence[Union[str, TextClause, Function]], schema: Optional[str] = None, unique: bool = False, **kw) → Optional[Table]
Issue a “create index” instruction using the current migration context.
e.g.:
from alembic import op
op.create_index('ik_test', 't1', ['foo', 'bar'])
Functional indexes can be produced by using the sqlalchemy.sql.expression.text() construct:
from alembic import op
from sqlalchemy import text
op.create_index('ik_test', 't1', [text('lower(foo)')])
Parameters:
- index_name – name of the index.
- table_name – name of the owning table.
- columns – a list consisting of string column names and/or text() constructs.
- schema – Optional schema name to operate within. To control quoting of the schema outside of the default behavior, use the SQLAlchemy construct quoted_name.
- unique – If True, create a unique index.
- quote – Force quoting of this column’s name on or off, corresponding to
TrueorFalse. When left at its default ofNone, the column identifier will be quoted according to whether the name is case sensitive (identifiers with at least one upper case character are treated as case sensitive), or if it’s a reserved word. This flag is only needed to force quoting of a reserved word which is not known by the SQLAlchemy dialect. - **kw – Additional keyword arguments not mentioned above are dialect specific, and passed in the form
<dialectname>_<argname>. See the documentation regarding an individual dialect at Dialects for detail on documented arguments.
create_primary_key
create_primary_key(constraint_name: Optional[str], table_name: str, columns: List[str], schema: Optional[str] = None) → Optional[Table]
Issue a “create primary key” instruction using the current migration context.
e.g.:
from alembic import op
op.create_primary_key(
"pk_my_table", "my_table",
["id", "version"]
)
This internally generates a Table object containing the necessary columns, then generates a new PrimaryKeyConstraint object which it then associates with the Table. Any event listeners associated with this action will be fired off normally. The AddConstraint construct is ultimately used to generate the ALTER statement.
Parameters:
- constraint_name – Name of the primary key constraint. The
nameis necessary so that an ALTER statement can be emitted. For setups that use an automated naming scheme such as that described at Configuring Constraint Naming Conventionsnamehere can beNone, as the event listener will apply thenameto the constraint object when it is associated with the table. - table_name – String name of the target table.
- columns – a list of string column names to be applied to the primary key constraint.
- schema – Optional schema name to operate within. To control quoting of the schema outside of the default behavior, use the SQLAlchemy construct quoted_name.
create_table
create_table(table_name: str, *columns, **kw) → Optional[Table]
Issue a “create table” instruction using the current migration context.
This directive receives an argument list similar to that of the traditional sqlalchemy.schema.Table construct, but without the metadata:
from sqlalchemy import INTEGER, VARCHAR, NVARCHAR, Column
from alembic import op
op.create_table(
'account',
Column('id', INTEGER, primary_key=True),
Column('name', VARCHAR(50), nullable=False),
Column('description', NVARCHAR(200)),
Column('timestamp', TIMESTAMP, server_default=func.now())
)
Note: that create_table() accepts Column constructs directly from the SQLAlchemy library. In particular,
defaultvalues to be created on the database side are specified using theserver_defaultparameter, and notdefaultwhich only specifies Python-side defaults:
from alembic import op
from sqlalchemy import Column, TIMESTAMP, func
# specify "DEFAULT NOW" along with the "timestamp" column
op.create_table('account',
Column('id', INTEGER, primary_key=True),
Column('timestamp', TIMESTAMP, server_default=func.now())
)
The function also returns a newly created Table object, corresponding to the table specification given, which is suitable for immediate SQL operations, in particular Operations.bulk_insert():
from sqlalchemy import INTEGER, VARCHAR, NVARCHAR, Column
from alembic import op
account_table = op.create_table(
'account',
Column('id', INTEGER, primary_key=True),
Column('name', VARCHAR(50), nullable=False),
Column('description', NVARCHAR(200)),
Column('timestamp', TIMESTAMP, server_default=func.now())
)
op.bulk_insert(
account_table,
[
{"name": "A1", "description": "account 1"},
{"name": "A2", "description": "account 2"},
]
)
Parameters:
- table_name – Name of the table
- *columns – collection of Column objects within the table, as well as optional Constraint objects and Index objects.
- schema – Optional schema name to operate within. To control quoting of the schema outside of the default behavior, use the SQLAlchemy construct quoted_name.
- **kw – Other keyword arguments are passed to the underlying sqlalchemy.schema.Table object created for the command.
Returns: the Table object corresponding to the parameters given.
create_table_comment
create_table_comment(table_name: str, comment: Optional[str], existing_comment: None = None, schema: Optional[str] = None) → Optional[Table]
Emit a COMMENT ON operation to set the comment for a table.
New in version 1.0.6.
Parameters:
- table_name – string name of the target table.
- comment – string value of the comment being registered against the specified table.
- existing_comment – String value of a comment already registered on the specified table, used within autogenerate so that the operation is reversible, but not required for direct use.
See also:
create_unique_constraint
create_unique_constraint(constraint_name: Optional[str], table_name: str, columns: Sequence[str], schema: Optional[str] = None, **kw) → Any
Issue a “create unique constraint” instruction using the current migration context.
e.g.:
from alembic import op
op.create_unique_constraint("uq_user_name", "user", ["name"])
This internally generates a Table object containing the necessary columns, then generates a new UniqueConstraint object which it then associates with the Table. Any event listeners associated with this action will be fired off normally. The AddConstraint construct is ultimately used to generate the ALTER statement.
Parameters:
- name – Name of the unique constraint. The
nameis necessary so that an ALTER statement can be emitted. For setups that use an automated naming scheme such as that described at Configuring Constraint Naming Conventions,namehere can beNone, as the event listener will apply thenameto the constraint object when it is associated with the table. - table_name – String name of the source table.
- columns – a list of string column names in the source table.
- deferrable – optional bool. If set, emit DEFERRABLE or NOT DEFERRABLE when issuing DDL for this constraint.
- initially – optional string. If set, emit INITIALLY
when issuing DDL for this constraint. - schema – Optional schema name to operate within. To control quoting of the schema outside of the default behavior, use the SQLAlchemy construct quoted_name.
drop_column
drop_column(table_name: str, column_name: str, schema: Optional[str] = None, **kw) → Optional[Table]
Issue a “drop column” instruction using the current migration context.
e.g.:
drop_column('organization', 'account_id')
Parameters:
- table_name – name of table
- column_name – name of column
- schema – Optional schema name to operate within. To control quoting of the schema outside of the default behavior, use the SQLAlchemy construct quoted_name.
- mssql_drop_check – Optional boolean. When
True, on Microsoft SQL Server only, first drop the CHECK constraint on the column using a SQL-script-compatible block that selects into a @variable from sys.check_constraints, then exec’s a separate DROP CONSTRAINT for that constraint. - mssql_drop_default – Optional boolean. When
True, on Microsoft SQL Server only, first drop the DEFAULT constraint on the column using a SQL-script-compatible block that selects into a @variable from sys.default_constraints, then exec’s a separate DROP CONSTRAINT for that default. - mssql_drop_foreign_key – Optional boolean. When
True, on Microsoft SQL Server only, first drop a single FOREIGN KEY constraint on the column using a SQL-script-compatible block that selects into a @variable from sys.foreign_keys/sys.foreign_key_columns, then exec’s a separate DROP CONSTRAINT for that default. Only works if the column has exactly one FK constraint which refers to it, at the moment.
drop_constraint
drop_constraint(constraint_name: str, table_name: str, type_: Optional[str] = None, schema: Optional[str] = None) → Optional[Table]
Drop a constraint of the given name, typically via DROP CONSTRAINT.
Parameters:
- constraint_name – name of the constraint.
- table_name – table name.
- type_ – optional, required on MySQL. can be ‘foreignkey’, ‘primary’, ‘unique’, or ‘check’.
- schema – Optional schema name to operate within. To control quoting of the schema outside of the default behavior, use the SQLAlchemy construct quoted_name.
drop_index
drop_index(index_name: str, table_name: Optional[str] = None, schema: Optional[str] = None, **kw) → Optional[Table]
Issue a “drop index” instruction using the current migration context.
e.g.:
drop_index("accounts")
Parameters:
- index_name – name of the index.
- table_name – name of the owning table. Some backends such as Microsoft SQL Server require this.
- schema – Optional schema name to operate within. To control quoting of the schema outside of the default behavior, use the SQLAlchemy construct quoted_name.
- **kw – Additional keyword arguments not mentioned above are dialect specific, and passed in the form
<dialectname>_<argname>. See the documentation regarding an individual dialect at Dialects for detail on documented arguments.
drop_table
drop_table(table_name: str, schema: Optional[str] = None, **kw: Any) → None
Issue a “drop table” instruction using the current migration context.
e.g.:
drop_table("accounts")
Parameters:
- table_name – Name of the table
- schema – Optional schema name to operate within. To control quoting of the schema outside of the default behavior, use the SQLAlchemy construct quoted_name.
- **kw – Other keyword arguments are passed to the underlying sqlalchemy.schema.Table object created for the command.
drop_table_comment
drop_table_comment(table_name: str, existing_comment: Optional[str] = None, schema: Optional[str] = None) → Optional[Table]
Issue a “drop table comment” operation to remove an existing comment set on a table.
New in version 1.0.6.
Parameters:
- table_name – string name of the target table.
- existing_comment – An optional string value of a comment already registered on the specified table.
See also:
execute
execute(sqltext: Union[str, TextClause, Update], execution_options: None = None) → Optional[Table]
Execute the given SQL using the current migration context.
The given SQL can be a plain string, e.g.:
op.execute("INSERT INTO table (foo) VALUES ('some value')")
Or it can be any kind of Core SQL Expression construct, such as below where we use an update construct:
from sqlalchemy.sql import table, column
from sqlalchemy import String
from alembic import op
account = table('account',
column('name', String)
)
op.execute(
account.update().\\
where(account.c.name==op.inline_literal('account 1')).\\
values({'name':op.inline_literal('account 2')})
)
Above, we made use of the SQLAlchemy sqlalchemy.sql.expression.table() and sqlalchemy.sql.expression.column() constructs to make a brief, ad-hoc table construct just for our UPDATE statement. A full Table construct of course works perfectly fine as well, though note it’s a recommended practice to at least ensure the definition of a table is self-contained within the migration script, rather than imported from a module that may break compatibility with older migrations.
In a SQL script context, the statement is emitted directly to the output stream. There is no return result, however, as this function is oriented towards generating a change script that can run in “offline” mode. Additionally, parameterized statements are discouraged here, as they will not work in offline mode. Above, we use inline_literal() where parameters are to be used.
For full interaction with a connected database where parameters can also be used normally, use the “bind” available from the context:
from alembic import op
connection = op.get_bind()
connection.execute(
account.update().where(account.c.name=='account 1').
values({"name": "account 2"})
)
Additionally, when passing the statement as a plain string, it is first coerceed into a sqlalchemy.sql.expression.text() construct before being passed along. In the less likely case that the literal SQL string contains a colon, it must be escaped with a backslash, as:
op.execute("INSERT INTO table (foo) VALUES ('\:colon_value')")
Parameters:
- sqltext – Any legal SQLAlchemy expression, including:
- a string
- a sqlalchemy.sql.expression.text() construct.
- a sqlalchemy.sql.expression.insert() construct.
- a sqlalchemy.sql.expression.update(), sqlalchemy.sql.expression.insert(), or sqlalchemy.sql.expression.delete() construct.
- Pretty much anything that’s “executable” as described in SQL Expression Language Tutorial (1.x API).
Note: when passing a plain string, the statement is coerced into a sqlalchemy.sql.expression.text() construct. This construct considers symbols with colons, e.g.
:footo be bound parameters. To avoid this, ensure that colon symbols are escaped, e.g.\:foo. - execution_options – Optional dictionary of execution options, will be passed to sqlalchemy.engine.Connection.execution_options().
f
f(name: str) → sqlalchemy.sql.elements.conv
Indicate a string name that has already had a naming convention applied to it.
This feature combines with the SQLAlchemy naming_convention feature to disambiguate constraint names that have already had naming conventions applied to them, versus those that have not. This is necessary in the case that the "%(constraint_name)s" token is used within a naming convention, so that it can be identified that this particular name should remain fixed.
If the Operations.f() is used on a constraint, the naming convention will not take effect:
op.add_column('t', 'x', Boolean(name=op.f('ck_bool_t_x')))
Above, the CHECK constraint generated will have the name ck_bool_t_x regardless of whether or not a naming convention is in use.
Alternatively, if a naming convention is in use, and ‘f’ is not used, names will be converted along conventions. If the target_metadata contains the naming convention {"ck": "ck_bool_%(table_name)s_%(constraint_name)s"}, then the output of the following:
op.add_column(‘t’, ‘x’, Boolean(name=’x’))
will be:
CONSTRAINT ck_bool_t_x CHECK (x in (1, 0)))
The function is rendered in the output of autogenerate when a particular constraint name is already converted.
get_bind
get_bind() → Connection
Return the current ‘bind’.
Under normal circumstances, this is the Connection currently being used to emit SQL to the database.
In a SQL script context, this value is None. [TODO: verify this]
get_context
get_context()
Return the MigrationContext object that’s currently in use.
implementation_for
classmethod implementation_for(op_cls: Any) → Callable
Register an implementation for a given MigrateOperation.
This is part of the operation extensibility API.
See also:
Operation Plugins - example of use
inline_literal
inline_literal(value: Union[str, int], type_: None = None) → _literal_bindparam
Produce an ‘inline literal’ expression, suitable for using in an INSERT, UPDATE, or DELETE statement.
When using Alembic in “offline” mode, CRUD operations aren’t compatible with SQLAlchemy’s default behavior surrounding literal values, which is that they are converted into bound values and passed separately into the execute() method of the DBAPI cursor. An offline SQL script needs to have these rendered inline. While it should always be noted that inline literal values are an enormous security hole in an application that handles untrusted input, a schema migration is not run in this context, so literals are safe to render inline, with the caveat that advanced types like dates may not be supported directly by SQLAlchemy.
See execute() for an example usage of inline_literal().
The environment can also be configured to attempt to render “literal” values inline automatically, for those simple types that are supported by the dialect; see EnvironmentContext.configure.literal_binds for this more recently added feature.
Parameters:
-
value – The value to render. Strings, integers, and simple numerics should be supported. Other types like boolean, dates, etc. may or may not be supported yet by various backends.
-
type_ – optional - a sqlalchemy.types.TypeEngine subclass stating the type of this value. In SQLAlchemy expressions, this is usually derived automatically from the Python type of the value itself, as well as based on the context in which the value is used.
See also:
invoke
invoke(operation: MigrateOperation) → Any
Given a MigrateOperation, invoke it in terms of this Operations instance.
register_operation
classmethod register_operation(name: str, sourcename: Optional[str] = None) → Callable
Register a new operation for this class.
This method is normally used to add new operations to the Operations class, and possibly the BatchOperations class as well. All Alembic migration operations are implemented via this system, however the system is also available as a public API to facilitate adding custom operations.
See also:
rename_table
rename_table(old_table_name: str, new_table_name: str, schema: Optional[str] = None) → Optional[Table]
Emit an ALTER TABLE to rename a table.
Parameters:
- old_table_name – old name.
- new_table_name – new name.
- schema – Optional schema name to operate within. To control quoting of the schema outside of the default behavior, use the SQLAlchemy construct quoted_name.
alembic.operations.BatchOperations
class alembic.operations.BatchOperations(migration_context: MigrationContext, impl: Optional[BatchOperationsImpl] = None)
Modifies the interface Operations for batch mode.
This basically omits the table_name and schema parameters from associated methods, as these are a given when running under batch mode.
See also: Operations.batch_alter_table()
Note: that as of 0.8, most of the methods on this class are produced dynamically using the Operations.register_operation() method.
Construct a new Operations
Parameters:
- migration_context – a MigrationContext instance.
add_column
add_column(column: Column, insert_before: Optional[str] = None, insert_after: Optional[str] = None) → Optional[Table]
Issue an “add column” instruction using the current batch migration context.
See also:
alter_column
alter_column(column_name: str, nullable: Optional[bool] = None, comment: bool = False, server_default: Union[Function, bool] = False, new_column_name: Optional[str] = None, type_: Optional[Union[TypeEngine, Type[TypeEngine]]] = None, existing_type: Optional[Union[TypeEngine, Type[TypeEngine]]] = None, existing_server_default: bool = False, existing_nullable: None = None, existing_comment: None = None, insert_before: None = None, insert_after: None = None, **kw) → Optional[Table]
Issue an “alter column” instruction using the current batch migration context.
Parameters are the same as that of Operations.alter_column(), as well as the following option(s):
Parameters:
- insert_before – String name of an existing column which this column should be placed before, when creating the new table.
New in version 1.4.0.
- insert_after – String name of an existing column which this column should be placed after, when creating the new table. If both BatchOperations.alter_column.insert_before and BatchOperations.alter_column.insert_after are omitted, the column is inserted after the last existing column in the table.
New in version 1.4.0.
See also:
create_check_constraint
create_check_constraint(constraint_name: str, condition: TextClause, **kw) → Optional[Table]
Issue a “create check constraint” instruction using the current batch migration context.
The batch form of this call omits the source and schema arguments from the call.
See also:
create_exclude_constraint
create_exclude_constraint(constraint_name, *elements, **kw)
Issue a “create exclude constraint” instruction using the current batch migration context.
Note: This method is Postgresql specific, and additionally requires at least SQLAlchemy 1.0.
See also:
create_foreign_key
create_foreign_key(constraint_name: str, referent_table: str, local_cols: List[str], remote_cols: List[str], referent_schema: Optional[str] = None, onupdate: None = None, ondelete: None = None, deferrable: None = None, initially: None = None, match: None = None, **dialect_kw) → None
Issue a “create foreign key” instruction using the current batch migration context.
The batch form of this call omits the source and source_schema arguments from the call.
e.g.:
with batch_alter_table("address") as batch_op:
batch_op.create_foreign_key(
"fk_user_address",
"user", ["user_id"], ["id"])
See also:
create_index
create_index(index_name: str, columns: List[str], **kw) → Optional[Table]
Issue a “create index” instruction using the current batch migration context.
See also:
create_primary_key
create_primary_key(constraint_name: str, columns: List[str]) → None
Issue a “create primary key” instruction using the current batch migration context.
The batch form of this call omits the table_name and schema arguments from the call.
See also:
create_table_comment
create_table_comment(comment, existing_comment=None)
Emit a COMMENT ON operation to set the comment for a table using the current batch migration context.
New in version 1.6.0.
Parameters:
- comment – string value of the comment being registered against the specified table.
- existing_comment – String value of a comment already registered on the specified table, used within autogenerate so that the operation is reversible, but not required for direct use.
create_unique_constraint
create_unique_constraint(constraint_name: str, columns: Sequence[str], **kw) → Any
Issue a “create unique constraint” instruction using the current batch migration context.
The batch form of this call omits the source and schema arguments from the call.
See also:
drop_column
drop_column(column_name: str, **kw) → Optional[Table]
Issue a “drop column” instruction using the current batch migration context.
See also:
drop_constraint
drop_constraint(constraint_name: str, type_: Optional[str] = None) → None
Issue a “drop constraint” instruction using the current batch migration context.
The batch form of this call omits the table_name and schema arguments from the call.
See also:
drop_index
drop_index(index_name: str, **kw) → Optional[Table]
Issue a “drop index” instruction using the current batch migration context.
See also:
drop_table_comment
drop_table_comment(existing_comment=None)
Issue a “drop table comment” operation to remove an existing comment set on a table using the current batch operations context.
New in version 1.6.0.
Parameters:
- existing_comment – An optional string value of a comment already registered on the specified table.
cookbook
A collection of “How-Tos” highlighting popular ways to extend Alembic.
Note: This is a new section where we catalogue various “how-tos” based on user requests. It is often the case that users will request a feature only to learn it can be provided with a simple customization.
一系列“操作方法”,重点介绍了扩展 Alembic 的流行方法。
备注: 这是一个新的部分,我们根据用户请求对各种“操作方法”进行分类。 通常情况下,用户会请求一个功能只是为了学习它, 并且可以通过简单的定制来提供。
Building an Up to Date Database from Scratch
从头开始构建最新的数据库
There’s a theory of database migrations that says that the revisions in existence for a database should be able to go from an entirely blank schema to the finished product, and back again. Alembic can roll this way. Though we think it’s kind of overkill, considering that SQLAlchemy itself can emit the full CREATE statements for any given model using create_all(). If you check out a copy of an application, running this will give you the entire database in one shot, without the need to run through all those migration files, which are instead tailored towards applying incremental changes to an existing database.
有一种数据库迁移理论认为,数据库的现有修订应该能够从完全空白的模式转移到成品,然后再返回。 Alembic 可以这样滚动。 尽管我们认为这有点矫枉过正,但考虑到 SQLAlchemy 本身可以使用 create_all() 为任何给定模型发出完整的 CREATE 语句。 如果您检查一个应用程序的副本,运行它将一次性为您提供整个数据库,而无需运行所有这些迁移文件,这些迁移文件是针对对现有数据库应用增量更改而量身定制的。
Alembic can integrate with a create_all() script quite easily. After running the create operation, tell Alembic to create a new version table, and to stamp it with the most recent revision (i.e. head):
Alembic 可以很容易地与 create_all() 脚本集成。 运行
create操作后,告诉Alembic创建一个新的版本表,并用最新的修订(即head)标记它:
# inside of a "create the database" script, first create
# tables:
# 在“创建数据库”脚本中,首先创建表
my_metadata.create_all(engine)
# then, load the Alembic configuration and generate the
# version table, "stamping" it with the most recent rev:
# 然后,加载 Alembic 配置并生成版本表,用最新版本“标记”它:
from alembic.config import Config
from alembic import command
alembic_cfg = Config("/path/to/yourapp/alembic.ini")
command.stamp(alembic_cfg, "head")
When this approach is used, the application can generate the database using normal SQLAlchemy techniques instead of iterating through hundreds of migration scripts. Now, the purpose of the migration scripts is relegated just to movement between versions on out-of-date databases, not new databases. You can now remove old migration files that are no longer represented on any existing environments.
当使用这种方法时,应用程序可以使用普通的 SQLAlchemy 技术生成数据库,而不是遍历数百个迁移脚本。 现在,迁移脚本的目的仅是在过期数据库上的版本之间移动,而不是在新数据库上移动。 您现在可以删除不再存在于任何现有环境中的旧迁移文件。
To prune old migration files, simply delete the files. Then, in the earliest, still-remaining migration file, set down_revision to None:
要修剪旧的迁移文件,只需删除这些文件。 然后,在最早的、仍然存在的迁移文件中,将
down_revision设置为None:
# replace this:
#down_revision = '290696571ad2'
# with this:
down_revision = None
That file now becomes the “base” of the migration series.
该文件现在成为迁移系列的 “base”。
Conditional Migration Elements
条件迁移元素
This example features the basic idea of a common need, that of affecting how a migration runs based on command line switches.
此示例具有共同需求的基本思想,即基于命令行开关影响迁移的运行方式。
The technique to use here is simple; within a migration script, inspect the EnvironmentContext.get_x_argument() collection for any additional, user-defined parameters. Then take action based on the presence of those arguments.
这里使用的技术很简单; 在迁移脚本中,检查 EnvironmentContext.get_x_argument() 集合中是否有任何其他用户定义的参数。 然后根据这些参数的存在采取行动。
To make it such that the logic to inspect these flags is easy to use and modify, we modify our script.py.mako template to make this feature available in all new revision files:
为了使检查这些标志的逻辑易于使用和修改,我们修改了我们的
script.py.mako模板,以使该功能在所有新修订文件中都可用:
"""${message}
Revision ID: ${up_revision}
Revises: ${down_revision}
Create Date: ${create_date}
"""
# revision identifiers, used by Alembic.
revision = ${repr(up_revision)}
down_revision = ${repr(down_revision)}
from alembic import op
import sqlalchemy as sa
${imports if imports else ""}
from alembic import context
def upgrade():
schema_upgrades()
if context.get_x_argument(as_dictionary=True).get('data', None):
data_upgrades()
def downgrade():
if context.get_x_argument(as_dictionary=True).get('data', None):
data_downgrades()
schema_downgrades()
def schema_upgrades():
"""schema upgrade migrations go here."""
${upgrades if upgrades else "pass"}
def schema_downgrades():
"""schema downgrade migrations go here."""
${downgrades if downgrades else "pass"}
def data_upgrades():
"""Add any optional data upgrade migrations here!"""
pass
def data_downgrades():
"""Add any optional data downgrade migrations here!"""
pass
Now, when we create a new migration file, the data_upgrades() and data_downgrades() placeholders will be available, where we can add optional data migrations:
现在,当我们创建一个新的迁移文件时,
data_upgrades()和data_downgrades()新增的函数将可用,我们可以在其中添加可选的数据迁移:
"""rev one
Revision ID: 3ba2b522d10d
Revises: None
Create Date: 2014-03-04 18:05:36.992867
"""
# revision identifiers, used by Alembic.
revision = '3ba2b522d10d'
down_revision = None
from alembic import op
import sqlalchemy as sa
from sqlalchemy import String, Column
from sqlalchemy.sql import table, column
from alembic import context
def upgrade():
schema_upgrades()
if context.get_x_argument(as_dictionary=True).get('data', None):
data_upgrades()
def downgrade():
if context.get_x_argument(as_dictionary=True).get('data', None):
data_downgrades()
schema_downgrades()
def schema_upgrades():
"""schema upgrade migrations go here."""
op.create_table("my_table", Column('data', String))
def schema_downgrades():
"""schema downgrade migrations go here."""
op.drop_table("my_table")
def data_upgrades():
"""Add any optional data upgrade migrations here!"""
my_table = table('my_table',
column('data', String),
)
op.bulk_insert(my_table,
[
{'data': 'data 1'},
{'data': 'data 2'},
{'data': 'data 3'},
]
)
def data_downgrades():
"""Add any optional data downgrade migrations here!"""
op.execute("delete from my_table")
To invoke our migrations with data included, we use the -x flag:
要调用包含数据的迁移,我们使用
-x标志:
alembic -x data=true upgrade head
The EnvironmentContext.get_x_argument() is an easy way to support new commandline options within environment and migration scripts.
EnvironmentContext.get_x_argument() 是一种在环境和迁移脚本中支持新命令行选项的简单方法。
Sharing a Connection with a Series of Migration Commands and Environments
与一系列迁移命令和环境共享连接
It is often the case that an application will need to call upon a series of commands within Commands, where it would be advantageous for all operations to proceed along a single transaction. The connectivity for a migration is typically solely determined within the env.py script of a migration environment, which is called within the scope of a command.
通常情况下,应用程序需要调用 Commands 中的一系列命令,在这种情况下,所有操作都沿单个事务进行是有利的。 迁移的连接性通常仅在迁移环境的
env.py脚本中确定,该脚本在命令范围内调用。
The steps to take here are:
这里要采取的步骤是:
- Produce the Connection object to use.
- Place it somewhere that
env.pywill be able to access it. This can be either a. a module-level global somewhere, or b. an attribute which we place into the Config.attributes dictionary (if we are on an older Alembic version, we may also attach an attribute directly to the Config object). - The
env.pyscript is modified such that it looks for this Connection and makes use of it, in lieu of building up its own Engine instance.
- 生成要使用的 Connection 对象。
- 将它放在
env.py能够访问它的地方。 这可以是全局的模块级的a.a或b.,然后我们将其作为属性放入 Config.attributes 字典。(如果我们使用的是较旧的 Alembic 版本,我们也可以将属性直接附加到 Config 对象)。- 修改了
env.py脚本,使其查找此 Connection 并使用它,而不是构建自己的 Engine 实例。
We illustrate using Config.attributes:
我们使用 Config.attributes 进行说明:
from alembic import command, config
cfg = config.Config("/path/to/yourapp/alembic.ini")
with engine.begin() as connection:
cfg.attributes['connection'] = connection
command.upgrade(cfg, "head")
Then in env.py:
然后在
env.py中:
def run_migrations_online():
connectable = config.attributes.get('connection', None)
if connectable is None:
# only create Engine if we don't have a Connection
# from the outside
connectable = engine_from_config(
config.get_section(config.config_ini_section),
prefix='sqlalchemy.',
poolclass=pool.NullPool)
context.configure(
connection=connectable,
target_metadata=target_metadata
)
with context.begin_transaction():
context.run_migrations()
Changed in version 1.4: Prior to this version, we used a “branched connection”, by calling connect(). This is now deprecated and unnecessary, since we no longer have to guess if the given “connection” is an
EngineorConnection, it is always aConnection.
版本1.4更新: 在此版本之前,我们通过调用 connect() 使用 “分支连接” 。 现在已弃用且不必要,因为我们不再需要猜测给定的
connection是Engine的实例还是Connection的实例,它始终是Connection的实例。
Replaceable Objects
可替换对象
This recipe proposes a hypothetical way of dealing with what we might call a replaceable schema object. A replaceable object is a schema object that needs to be created and dropped all at once. Examples of such objects include views, stored procedures, and triggers.
本文章提出了一种假设的方法来处理我们可能称之为可替换模式对象的东西。 可替换对象是需要一次性创建和删除的模式对象。 此类对象的示例包括视图、存储过程和触发器。
See also: The Replaceable Object concept has been integrated by the Alembic Utils project, which provides autogenerate and migration support for PostgreSQL functions and views. See Alembic Utils at https://github.com/olirice/alembic_utils .
同样参考: 可替换对象概念已被 Alembic Utils 项目集成,该项目为 PostgreSQL 函数和视图提供自动生成和迁移支持。 请参阅 https://github.com/olirice/alembic_utils 上的 Alembic Utils。
Replaceable objects present a problem in that in order to make incremental changes to them, we have to refer to the whole definition at once. If we need to add a new column to a view, for example, we have to drop it entirely and recreate it fresh with the extra column added, referring to the whole structure; but to make it even tougher, if we wish to support downgrade operarations in our migration scripts, we need to refer to the previous version of that construct fully, and we’d much rather not have to type out the whole definition in multiple places.
可替换对象存在一个问题,即为了对它们进行增量更改,我们必须立即引用整个定义。 例如,如果我们需要向视图添加一个新列,我们必须完全删除它并重新创建它并添加额外的列,以引用整个结构; 但更难的是,如果我们希望在我们的迁移脚本中支持降级操作,我们需要完全引用该结构的先前版本,我们宁愿不必在多个地方输入整个定义。
This recipe proposes that we may refer to the older version of a replaceable construct by directly naming the migration version in which it was created, and having a migration refer to that previous file as migrations run. We will also demonstrate how to integrate this logic within the Operation Plugins feature introduced in Alembic 0.8. It may be very helpful to review this section first to get an overview of this API.
这篇文章建议我们可以通过直接命名创建它的迁移版本来引用可替换构造的旧版本,并在迁移运行时让迁移引用之前的文件。 我们还将演示如何将此逻辑集成到 Alembic 0.8 中引入的 操作插件 功能中。 首先查看此部分以了解此 API 的概述可能会非常有帮助。
The Replaceable Object Structure
可替换对象结构
We first need to devise a simple format that represents the “CREATE XYZ” / “DROP XYZ” aspect of what it is we’re building. We will work with an object that represents a textual definition; while a SQL view is an object that we can define using a table-metadata-like system, this is not so much the case for things like stored procedures, where we pretty much need to have a full string definition written down somewhere. We’ll use a simple value object called ReplaceableObject that can represent any named set of SQL text to send to a “CREATE” statement of some kind:
我们首先需要设计一个简单的格式来代表我们正在构建的“CREATE XYZ”/“DROP XYZ”表达式。 我们将使用一个表示文本定义的对象; 虽然 SQL 视图是我们可以使用类似 表元数据的系统 来定义的对象,但对于像存储过程这样的东西来说,情况并非如此,我们几乎需要在某处写下完整的字符串定义。 我们将使用一个名为
ReplaceableObject的简单值对象,它可以表示任何命名的 SQL 文本集,以发送到某种“CREATE”语句:
class ReplaceableObject:
def __init__(self, name, sqltext):
self.name = name
self.sqltext = sqltext
Using this object in a migration script, assuming a Postgresql-style syntax, looks like:
在迁移脚本中使用此对象,假设使用 Postgresql 样式的语法,如下所示:
customer_view = ReplaceableObject(
"customer_view",
"SELECT name, order_count FROM customer WHERE order_count > 0"
)
add_customer_sp = ReplaceableObject(
"add_customer_sp(name varchar, order_count integer)",
"""
RETURNS integer AS $$
BEGIN
insert into customer (name, order_count)
VALUES (in_name, in_order_count);
END;
$$ LANGUAGE plpgsql;
"""
)
The ReplaceableObject class is only one very simplistic way to do this. The structure of how we represent our schema objects is not too important for the purposes of this example; we can just as well put strings inside of tuples or dictionaries, as well as that we could define any kind of series of fields and class structures we want. The only important part is that below we will illustrate how organize the code that can consume the structure we create here.
ReplaceableObject类只是执行此操作的一种非常简单的方法。 对于这个例子来说,我们如何表示我们的模式对象的结构并不是很重要; 我们也可以将字符串放在元组或字典中,也可以定义我们想要的任何类型的字段序列和类结构。 唯一重要的部分是,下面我们将说明如何组织可以使用我们在这里创建的结构的代码。
Create Operations for the Target Objects
为目标对象创建操作
We’ll use the Operations extension API to make new operations for create, drop, and replace of views and stored procedures. Using this API is also optional; we can just as well make any kind of Python function that we would invoke from our migration scripts. However, using this API gives us operations built directly into the Alembic op.* namespace very nicely.
我们将使用 Operations 扩展 API 来创建、删除和替换视图和存储过程的新操作。 使用此 API 也是可选的; 我们也可以创建从迁移脚本中调用的任何类型的 Python 函数。 然而,使用这个 API 可以很好地为我们提供直接内置到 Alembic
op.*命名空间中的操作。
The most intricate class is below. This is the base of our “replaceable” operation, which includes not just a base operation for emitting CREATE and DROP instructions on a ReplaceableObject, it also assumes a certain model of “reversibility” which makes use of references to other migration files in order to refer to the “previous” version of an object:
最复杂的
Class如下。 这是我们“可替换”操作的基础,它不仅包括在可替换对象上发出CREATE和DROP指令的基本操作,它还假设了某种“可逆性”模型,该模型利用对其他迁移文件的引用来实现。 参考对象的“先前”版本:
from alembic.operations import Operations, MigrateOperation
class ReversibleOp(MigrateOperation):
def __init__(self, target):
self.target = target
@classmethod
def invoke_for_target(cls, operations, target):
op = cls(target)
return operations.invoke(op)
def reverse(self):
raise NotImplementedError()
@classmethod
def _get_object_from_version(cls, operations, ident):
version, objname = ident.split(".")
module = operations.get_context().script.get_revision(version).module
obj = getattr(module, objname)
return obj
@classmethod
def replace(cls, operations, target, replaces=None, replace_with=None):
if replaces:
old_obj = cls._get_object_from_version(operations, replaces)
drop_old = cls(old_obj).reverse()
create_new = cls(target)
elif replace_with:
old_obj = cls._get_object_from_version(operations, replace_with)
drop_old = cls(target).reverse()
create_new = cls(old_obj)
else:
raise TypeError("replaces or replace_with is required")
operations.invoke(drop_old)
operations.invoke(create_new)
The workings of this class should become clear as we walk through the example. To create usable operations from this base, we will build a series of stub classes and use Operations.register_operation() to make them part of the op.* namespace:
当我们通过这个例子时,这个类的工作应该会变得很清楚。 为了从这个基础创建可用的操作,我们将构建一系列存根类并使用 Operations.register_operation() 使它们成为
op.*命名空间的一部分:
@Operations.register_operation("create_view", "invoke_for_target")
@Operations.register_operation("replace_view", "replace")
class CreateViewOp(ReversibleOp):
def reverse(self):
return DropViewOp(self.target)
@Operations.register_operation("drop_view", "invoke_for_target")
class DropViewOp(ReversibleOp):
def reverse(self):
return CreateViewOp(self.target)
@Operations.register_operation("create_sp", "invoke_for_target")
@Operations.register_operation("replace_sp", "replace")
class CreateSPOp(ReversibleOp):
def reverse(self):
return DropSPOp(self.target)
@Operations.register_operation("drop_sp", "invoke_for_target")
class DropSPOp(ReversibleOp):
def reverse(self):
return CreateSPOp(self.target)
To actually run the SQL like “CREATE VIEW” and “DROP SEQUENCE”, we’ll provide implementations using Operations.implementation_for() that run straight into Operations.execute():
要实际运行像 “CREATE VIEW” 和 “DROP SEQUENCE” 这样的 SQL,我们将使用直接运行到 Operations.execute() 的 Operations.implementation_for() 提供实现:
@Operations.implementation_for(CreateViewOp)
def create_view(operations, operation):
operations.execute("CREATE VIEW %s AS %s" % (
operation.target.name,
operation.target.sqltext
))
@Operations.implementation_for(DropViewOp)
def drop_view(operations, operation):
operations.execute("DROP VIEW %s" % operation.target.name)
@Operations.implementation_for(CreateSPOp)
def create_sp(operations, operation):
operations.execute(
"CREATE FUNCTION %s %s" % (
operation.target.name, operation.target.sqltext
)
)
@Operations.implementation_for(DropSPOp)
def drop_sp(operations, operation):
operations.execute("DROP FUNCTION %s" % operation.target.name)
All of the above code can be present anywhere within an application’s source tree; the only requirement is that when the env.py script is invoked, it includes imports that ultimately call upon these classes as well as the Operations.register_operation() and Operations.implementation_for() sequences.
上述所有代码都可以出现在应用程序源代码树中的任何位置; 唯一的要求是,当调用
env.py脚本时,它包含最终调用这些类以及Operations.register_operation()和Operations.implementation_for()序列的导入。
Create Initial Migrations
创建初始迁移
We can now illustrate how these objects look during use. For the first step, we’ll create a new migration to create a “customer” table:
我们现在可以说明这些对象在使用过程中的外观。 第一步,我们将创建一个新的迁移来创建一个 “customer” 表:
alembic revision -m "create table"
We build the first revision as follows:
我们构建第一个修订版如下:
"""create table
Revision ID: 3ab8b2dfb055
Revises:
Create Date: 2015-07-27 16:22:44.918507
"""
# revision identifiers, used by Alembic.
revision = '3ab8b2dfb055'
down_revision = None
branch_labels = None
depends_on = None
from alembic import op
import sqlalchemy as sa
def upgrade():
op.create_table(
"customer",
sa.Column('id', sa.Integer, primary_key=True),
sa.Column('name', sa.String),
sa.Column('order_count', sa.Integer),
)
def downgrade():
op.drop_table('customer')
For the second migration, we will create a view and a stored procedure which act upon this table:
对于第二次迁移,我们将创建一个视图和一个作用于该表的存储过程:
alembic revision -m "create views/sp"
This migration will use the new directives:
此迁移将使用新指令:
"""create views/sp
Revision ID: 28af9800143f
Revises: 3ab8b2dfb055
Create Date: 2015-07-27 16:24:03.589867
"""
# revision identifiers, used by Alembic.
revision = '28af9800143f'
down_revision = '3ab8b2dfb055'
branch_labels = None
depends_on = None
from alembic import op
import sqlalchemy as sa
from foo import ReplaceableObject
customer_view = ReplaceableObject(
"customer_view",
"SELECT name, order_count FROM customer WHERE order_count > 0"
)
add_customer_sp = ReplaceableObject(
"add_customer_sp(name varchar, order_count integer)",
"""
RETURNS integer AS $$
BEGIN
insert into customer (name, order_count)
VALUES (in_name, in_order_count);
END;
$$ LANGUAGE plpgsql;
"""
)
def upgrade():
op.create_view(customer_view)
op.create_sp(add_customer_sp)
def downgrade():
op.drop_view(customer_view)
op.drop_sp(add_customer_sp)
We see the use of our new create_view(), create_sp(), drop_view(), and drop_sp() directives. Running these to “head” we get the following (this includes an edited view of SQL emitted):
我们看到了我们新的
create_view()、create_sp()、drop_view()和drop_sp()指令的使用。 将这些运行到“head”,我们得到以下信息(这包括发出的 SQL 的编辑视图):
$ alembic upgrade 28af9800143
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [sqlalchemy.engine.base.Engine] BEGIN (implicit)
INFO [sqlalchemy.engine.base.Engine] select relname from pg_class c join pg_namespace n on n.oid=c.relnamespace where pg_catalog.pg_table_is_visible(c.oid) and relname=%(name)s
INFO [sqlalchemy.engine.base.Engine] {'name': u'alembic_version'}
INFO [sqlalchemy.engine.base.Engine] SELECT alembic_version.version_num
FROM alembic_version
INFO [sqlalchemy.engine.base.Engine] {}
INFO [sqlalchemy.engine.base.Engine] select relname from pg_class c join pg_namespace n on n.oid=c.relnamespace where pg_catalog.pg_table_is_visible(c.oid) and relname=%(name)s
INFO [sqlalchemy.engine.base.Engine] {'name': u'alembic_version'}
INFO [alembic.runtime.migration] Running upgrade -> 3ab8b2dfb055, create table
INFO [sqlalchemy.engine.base.Engine]
CREATE TABLE customer (
id SERIAL NOT NULL,
name VARCHAR,
order_count INTEGER,
PRIMARY KEY (id)
)
INFO [sqlalchemy.engine.base.Engine] {}
INFO [sqlalchemy.engine.base.Engine] INSERT INTO alembic_version (version_num) VALUES ('3ab8b2dfb055')
INFO [sqlalchemy.engine.base.Engine] {}
INFO [alembic.runtime.migration] Running upgrade 3ab8b2dfb055 -> 28af9800143f, create views/sp
INFO [sqlalchemy.engine.base.Engine] CREATE VIEW customer_view AS SELECT name, order_count FROM customer WHERE order_count > 0
INFO [sqlalchemy.engine.base.Engine] {}
INFO [sqlalchemy.engine.base.Engine] CREATE FUNCTION add_customer_sp(name varchar, order_count integer)
RETURNS integer AS $$
BEGIN
insert into customer (name, order_count)
VALUES (in_name, in_order_count);
END;
$$ LANGUAGE plpgsql;
INFO [sqlalchemy.engine.base.Engine] {}
INFO [sqlalchemy.engine.base.Engine] UPDATE alembic_version SET version_num='28af9800143f' WHERE alembic_version.version_num = '3ab8b2dfb055'
INFO [sqlalchemy.engine.base.Engine] {}
INFO [sqlalchemy.engine.base.Engine] COMMIT
We see that our CREATE TABLE proceeded as well as the CREATE VIEW and CREATE FUNCTION operations produced by our new directives.
我们看到我们的 CREATE TABLE 以及由我们的新指令产生的 CREATE VIEW 和 CREATE FUNCTION 操作正常进行。
Create Revision Migrations
创建修订迁移
Finally, we can illustrate how we would “revise” these objects. Let’s consider we added a new column email to our customer table:
最后,我们可以说明我们将如何“修改”这些对象。 假设我们在
customer表中添加了一个新列
alembic revision -m "add email col"
The migration is:
迁移是:
"""add email col
Revision ID: 191a2d20b025
Revises: 28af9800143f
Create Date: 2015-07-27 16:25:59.277326
"""
# revision identifiers, used by Alembic.
revision = '191a2d20b025'
down_revision = '28af9800143f'
branch_labels = None
depends_on = None
from alembic import op
import sqlalchemy as sa
def upgrade():
op.add_column("customer", sa.Column("email", sa.String()))
def downgrade():
op.drop_column("customer", "email")
We now need to recreate the customer_view view and the add_customer_sp function. To include downgrade capability, we will need to refer to the previous version of the construct; the replace_view() and replace_sp() operations we’ve created make this possible, by allowing us to refer to a specific, previous revision. the replaces and replace_with arguments accept a dot-separated string, which refers to a revision number and an object name, such as "28af9800143f.customer_view". The ReversibleOp class makes use of the Operations.get_context() method to locate the version file we refer to:
我们现在需要重新创建
customer_view视图和add_customer_sp函数。 要包括downgrade功能,我们需要参考以前版本的构造; 我们创建的replace_view()和replace_sp()操作通过允许我们参考特定的先前版本来实现这一点。replaces和replace_with参数接受点分隔的字符串,它指的是修订号和对象名称,例如“28af9800143f.customer_view”。ReversibleOp类使用Operations.get_context()方法来定位我们引用的版本文件:
alembic revision -m "update views/sp"
The migration:
迁移是:
"""update views/sp
Revision ID: 199028bf9856
Revises: 191a2d20b025
Create Date: 2015-07-27 16:26:31.344504
"""
# revision identifiers, used by Alembic.
revision = '199028bf9856'
down_revision = '191a2d20b025'
branch_labels = None
depends_on = None
from alembic import op
import sqlalchemy as sa
from foo import ReplaceableObject
customer_view = ReplaceableObject(
"customer_view",
"SELECT name, order_count, email "
"FROM customer WHERE order_count > 0"
)
add_customer_sp = ReplaceableObject(
"add_customer_sp(name varchar, order_count integer, email varchar)",
"""
RETURNS integer AS $$
BEGIN
insert into customer (name, order_count, email)
VALUES (in_name, in_order_count, email);
END;
$$ LANGUAGE plpgsql;
"""
)
def upgrade():
op.replace_view(customer_view, replaces="28af9800143f.customer_view")
op.replace_sp(add_customer_sp, replaces="28af9800143f.add_customer_sp")
def downgrade():
op.replace_view(customer_view, replace_with="28af9800143f.customer_view")
op.replace_sp(add_customer_sp, replace_with="28af9800143f.add_customer_sp")
Above, instead of using create_view(), create_sp(), drop_view(), and drop_sp() methods, we now use replace_view() and replace_sp(). The replace operation we’ve built always runs a DROP and a CREATE. Running an upgrade to head we see:
上面,我们现在使用
replace_view()和replace_sp(),而不是使用create_view()、create_sp()、drop_view()和drop_sp()方法。 我们构建的替换操作总是运行 DROP 和 CREATE。 运行升级到 head 我们看到:
$ alembic upgrade head
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [sqlalchemy.engine.base.Engine] BEGIN (implicit)
INFO [sqlalchemy.engine.base.Engine] select relname from pg_class c join pg_namespace n on n.oid=c.relnamespace where pg_catalog.pg_table_is_visible(c.oid) and relname=%(name)s
INFO [sqlalchemy.engine.base.Engine] {'name': u'alembic_version'}
INFO [sqlalchemy.engine.base.Engine] SELECT alembic_version.version_num
FROM alembic_version
INFO [sqlalchemy.engine.base.Engine] {}
INFO [alembic.runtime.migration] Running upgrade 28af9800143f -> 191a2d20b025, add email col
INFO [sqlalchemy.engine.base.Engine] ALTER TABLE customer ADD COLUMN email VARCHAR
INFO [sqlalchemy.engine.base.Engine] {}
INFO [sqlalchemy.engine.base.Engine] UPDATE alembic_version SET version_num='191a2d20b025' WHERE alembic_version.version_num = '28af9800143f'
INFO [sqlalchemy.engine.base.Engine] {}
INFO [alembic.runtime.migration] Running upgrade 191a2d20b025 -> 199028bf9856, update views/sp
INFO [sqlalchemy.engine.base.Engine] DROP VIEW customer_view
INFO [sqlalchemy.engine.base.Engine] {}
INFO [sqlalchemy.engine.base.Engine] CREATE VIEW customer_view AS SELECT name, order_count, email FROM customer WHERE order_count > 0
INFO [sqlalchemy.engine.base.Engine] {}
INFO [sqlalchemy.engine.base.Engine] DROP FUNCTION add_customer_sp(name varchar, order_count integer)
INFO [sqlalchemy.engine.base.Engine] {}
INFO [sqlalchemy.engine.base.Engine] CREATE FUNCTION add_customer_sp(name varchar, order_count integer, email varchar)
RETURNS integer AS $$
BEGIN
insert into customer (name, order_count, email)
VALUES (in_name, in_order_count, email);
END;
$$ LANGUAGE plpgsql;
INFO [sqlalchemy.engine.base.Engine] {}
INFO [sqlalchemy.engine.base.Engine] UPDATE alembic_version SET version_num='199028bf9856' WHERE alembic_version.version_num = '191a2d20b025'
INFO [sqlalchemy.engine.base.Engine] {}
INFO [sqlalchemy.engine.base.Engine] COMMIT
After adding our new email column, we see that both customer_view and add_customer_sp() are dropped before the new version is created. If we downgrade back to the old version, we see the old version of these recreated again within the downgrade for this migration:
添加新的
customer_view和add_customer_sp()在创建新版本之前都被删除了。 如果我们降级回旧版本,我们会看到这些旧版本在此迁移的降级中再次重新创建:
$ alembic downgrade 28af9800143
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [sqlalchemy.engine.base.Engine] BEGIN (implicit)
INFO [sqlalchemy.engine.base.Engine] select relname from pg_class c join pg_namespace n on n.oid=c.relnamespace where pg_catalog.pg_table_is_visible(c.oid) and relname=%(name)s
INFO [sqlalchemy.engine.base.Engine] {'name': u'alembic_version'}
INFO [sqlalchemy.engine.base.Engine] SELECT alembic_version.version_num
FROM alembic_version
INFO [sqlalchemy.engine.base.Engine] {}
INFO [alembic.runtime.migration] Running downgrade 199028bf9856 -> 191a2d20b025, update views/sp
INFO [sqlalchemy.engine.base.Engine] DROP VIEW customer_view
INFO [sqlalchemy.engine.base.Engine] {}
INFO [sqlalchemy.engine.base.Engine] CREATE VIEW customer_view AS SELECT name, order_count FROM customer WHERE order_count > 0
INFO [sqlalchemy.engine.base.Engine] {}
INFO [sqlalchemy.engine.base.Engine] DROP FUNCTION add_customer_sp(name varchar, order_count integer, email varchar)
INFO [sqlalchemy.engine.base.Engine] {}
INFO [sqlalchemy.engine.base.Engine] CREATE FUNCTION add_customer_sp(name varchar, order_count integer)
RETURNS integer AS $$
BEGIN
insert into customer (name, order_count)
VALUES (in_name, in_order_count);
END;
$$ LANGUAGE plpgsql;
INFO [sqlalchemy.engine.base.Engine] {}
INFO [sqlalchemy.engine.base.Engine] UPDATE alembic_version SET version_num='191a2d20b025' WHERE alembic_version.version_num = '199028bf9856'
INFO [sqlalchemy.engine.base.Engine] {}
INFO [alembic.runtime.migration] Running downgrade 191a2d20b025 -> 28af9800143f, add email col
INFO [sqlalchemy.engine.base.Engine] ALTER TABLE customer DROP COLUMN email
INFO [sqlalchemy.engine.base.Engine] {}
INFO [sqlalchemy.engine.base.Engine] UPDATE alembic_version SET version_num='28af9800143f' WHERE alembic_version.version_num = '191a2d20b025'
INFO [sqlalchemy.engine.base.Engine] {}
INFO [sqlalchemy.engine.base.Engine] COMMIT
Rudimental Schema-Level Multi Tenancy for PostgreSQL Databases
PostgreSQL 数据库的基础架构级多租户
Multi tenancy refers to an application that accommodates for many clients simultaneously. Within the scope of a database migrations tool, multi-tenancy typically refers to the practice of maintaining multiple, identical databases where each database is assigned to one client.
多租户是指同时容纳多个客户端的应用程序。 在数据库迁移工具的范围内,多租户通常是指维护多个相同数据库的做法,其中每个数据库都分配给一个客户端。
Alembic does not currently have explicit multi-tenant support; typically, the approach must involve running Alembic multiple times against different database URLs.
Alembic 目前没有明确的多租户支持; 通常,该方法必须涉及针对不同的数据库 URL 多次运行 Alembic。
One common approach to multi-tenancy, particularly on the PostgreSQL database, is to install tenants within individual PostgreSQL schemas. When using PostgreSQL’s schemas, a special variable search_path is offered that is intended to assist with targeting of different schemas.
多租户的一种常见方法,特别是在 PostgreSQL 数据库上,是在单个 PostgreSQL 模式中安装租户。 使用 PostgreSQL 的模式时,提供了一个特殊的变量
search_path,旨在帮助定位不同的模式。
Note: SQLAlchemy includes a system of directing a common set of
Tablemetadata to many schemas called schema_translate_map. Alembic at the time of this writing lacks adequate support for this feature. The recipe below should be considered interim until Alembic has more first-class support for schema-level multi-tenancy.
注意: SQLAlchemy 包含一个系统,该系统将一组通用的表元数据定向到许多称为 schema_translate_map 的模式。 在撰写本文时,Alembic 对此功能缺乏足够的支持。 在 Alembic 对模式级多租户提供更多一流的支持之前,应将以下解决方法视为临时方案。
The recipe below can be altered for flexibility. The primary purpose of this recipe is to illustrate how to point the Alembic process towards one PostgreSQL schema or another.
可以更改以下配方以提高灵活性。 这个秘籍的主要目的是说明如何将 Alembic 进程指向一个或另一个 PostgreSQL 模式。
-
The model metadata used as the target for autogenerate must not include any schema name for tables; the schema must be non-present or set to
None. Otherwise, Alembic autogenerate will still attempt to compare and render tables in terms of this schema:class A(Base): __tablename__ = 'a' id = Column(Integer, primary_key=True) data = Column(UnicodeText()) foo = Column(Integer) __table_args__ = { "schema": None } -
The EnvironmentContext.configure.include_schemas flag must also be False or not included.
-
The “tenant” will be a schema name passed to Alembic using the “-x” flag. In
env.pyan approach like the following allows-xtenant=some_schemato be supported by making use of EnvironmentContext.get_x_argument():def run_migrations_online(): connectable = engine_from_config( config.get_section(config.config_ini_section), prefix="sqlalchemy.", poolclass=pool.NullPool, ) current_tenant = context.get_x_argument(as_dictionary=True).get("tenant") with connectable.connect() as connection: # set search path on the connection, which ensures that # PostgreSQL will emit all CREATE / ALTER / DROP statements # in terms of this schema by default connection.execute("set search_path to %s" % current_tenant) # make use of non-supported SQLAlchemy attribute to ensure # the dialect reflects tables in terms of the current tenant name connection.dialect.default_schema_name = current_tenant context.configure( connection=connection, target_metadata=target_metadata, ) with context.begin_transaction(): context.run_migrations()The current tenant is set using the PostgreSQL
search_pathvariable on the connection. Note above we must employ a non-supported SQLAlchemy workaround at the moment which is to hardcode the SQLAlchemy dialect’s default schema name to our target schema.It is also important to note that the above changes remain on the connection permanently unless reversed explicitly. If the alembic application simply exits above, there is no issue. However if the application attempts to continue using the above connection for other purposes, it may be necessary to reset these variables back to the default, which for PostgreSQL is usually the name “public” however may be different based on configuration.
-
Alembic operations will now proceed in terms of whichever schema we pass on the command line. All logged SQL will show no schema, except for reflection operations which will make use of the
default_schema_nameattribute:[]$ alembic -x tenant=some_schema revision -m "rev1" --autogenerate -
Since all schemas are to be maintained in sync, autogenerate should be run against only one schema, generating new Alembic migration files. Autogenerate migratin operations are then run against all schemas.
-
用作自动生成目标的模型元数据不得包含表的任何
schema名称;schema必须不存在或设置为None。 否则,Alembic 自动生成仍将尝试根据此模式比较和呈现表:class A(Base): __tablename__ = 'a' id = Column(Integer, primary_key=True) data = Column(UnicodeText()) foo = Column(Integer) __table_args__ = { "schema": None } -
EnvironmentContext.configure.include_schemas 标志也必须为
False或不包括在内。 -
“租户”将是使用
“-x”选项传递给 Alembic 的模式名称。 在env.py中,类似以下的方法允许通过使用 EnvironmentContext.get_x_argument() 来支持-xtenant=some_schema:def run_migrations_online(): connectable = engine_from_config( config.get_section(config.config_ini_section), prefix="sqlalchemy.", poolclass=pool.NullPool, ) current_tenant = context.get_x_argument(as_dictionary=True).get("tenant") with connectable.connect() as connection: # set search path on the connection, which ensures that # PostgreSQL will emit all CREATE / ALTER / DROP statements # in terms of this schema by default connection.execute("set search_path to %s" % current_tenant) # make use of non-supported SQLAlchemy attribute to ensure # the dialect reflects tables in terms of the current tenant name connection.dialect.default_schema_name = current_tenant context.configure( connection=connection, target_metadata=target_metadata, ) with context.begin_transaction(): context.run_migrations()当前租户是使用连接上的 PostgreSQL
search_path变量设置的。 请注意,我们目前必须采用 不受支持的 SQLAlchemy 解决方法,即将 SQLAlchemy 方言的默认模式名称硬编码到我们的目标模式。同样重要的是要注意,除非明确撤销,否则上述更改将永久保留在连接上。 如果 alembic 应用程序只是在上面退出,则没有问题。 但是,如果应用程序尝试继续使用上述连接用于其他目的,则可能需要将这些变量重置为默认值,对于 PostgreSQL,默认值通常是名称 “public”,但根据配置可能会有所不同。
-
Alembic 操作现在将根据我们在命令行上传递的任何模式进行。 除了使用
default_schema_name属性的反射操作外,所有记录的 SQL 都不会显示任何模式:[]$ alembic -x tenant=some_schema revision -m "rev1" --autogenerate -
由于 所有schema 都将保持同步,因此自动生成应该只针对 一个schema 运行,生成新的 Alembic 迁移文件。 然后针对 所有schema 运行自动生成迁移操作。
Don’t Generate Empty Migrations with Autogenerate
不要使用 Autogenerate 生成空迁移
A common request is to have the alembic revision --autogenerate command not actually generate a revision file if no changes to the schema is detected. Using the EnvironmentContext.configure.process_revision_directives hook, this is straightforward; place a process_revision_directives hook in MigrationContext.configure() which removes the single MigrationScript directive if it is empty of any operations:
一个常见的要求是如果没有检测到
schema的更改,则让alembic revision --autogenerate命令不实际生成修订文件。 使用 EnvironmentContext.configure.process_revision_directives 钩子,这很简单; 在 MigrationContext.configure() 中放置一个process_revision_directives钩子,如果单个 MigrationScript 指令没有任何操作,它将删除它:
def run_migrations_online():
# ...
def process_revision_directives(context, revision, directives):
if config.cmd_opts.autogenerate:
script = directives[0]
if script.upgrade_ops.is_empty():
directives[:] = []
# connectable = ...
with connectable.connect() as connection:
context.configure(
connection=connection,
target_metadata=target_metadata,
process_revision_directives=process_revision_directives
)
with context.begin_transaction():
context.run_migrations()
Don’t emit DROP INDEX when the table is to be dropped as well
MySQL may complain when dropping an index that is against a column that also has a foreign key constraint on it. If the table is to be dropped in any case, the DROP INDEX isn’t necessary. This recipe will process the set of autogenerate directives such that all DropIndexOp directives are removed against tables that themselves are to be dropped:
MySQL 可能会在删除针对列的索引时抱怨,该列也具有外键约束。 如果要在任何情况下删除表,则不需要 DROP INDEX。 此配方将处理自动生成指令集,以便针对本身要删除的表删除所有 DropIndexOp 指令:
def run_migrations_online():
# ...
from alembic.operations import ops
def process_revision_directives(context, revision, directives):
script = directives[0]
# process both "def upgrade()", "def downgrade()"
for directive in (script.upgrade_ops, script.downgrade_ops):
# make a set of tables that are being dropped within
# the migration function
tables_dropped = set()
for op in directive.ops:
if isinstance(op, ops.DropTableOp):
tables_dropped.add((op.table_name, op.schema))
# now rewrite the list of "ops" such that DropIndexOp
# is removed for those tables. Needs a recursive function.
directive.ops = list(
_filter_drop_indexes(directive.ops, tables_dropped)
)
def _filter_drop_indexes(directives, tables_dropped):
# given a set of (tablename, schemaname) to be dropped, filter
# out DropIndexOp from the list of directives and yield the result.
for directive in directives:
# ModifyTableOps is a container of ALTER TABLE types of
# commands. process those in place recursively.
if isinstance(directive, ops.ModifyTableOps) and \
(directive.table_name, directive.schema) in tables_dropped:
directive.ops = list(
_filter_drop_indexes(directive.ops, tables_dropped)
)
# if we emptied out the directives, then skip the
# container altogether.
if not directive.ops:
continue
elif isinstance(directive, ops.DropIndexOp) and \
(directive.table_name, directive.schema) in tables_dropped:
# we found a target DropIndexOp. keep looping
continue
# otherwise if not filtered, yield out the directive
yield directive
# connectable = ...
with connectable.connect() as connection:
context.configure(
connection=connection,
target_metadata=target_metadata,
process_revision_directives=process_revision_directives
)
with context.begin_transaction():
context.run_migrations()
Whereas autogenerate, when dropping two tables with a foreign key and an index, would previously generate something like:
在自动生成的情况下,当删除具有外键和索引的两个表时,以前会生成如下内容:
def downgrade():
# ### commands auto generated by Alembic - please adjust! ###
op.drop_index(op.f('ix_b_aid'), table_name='b')
op.drop_table('b')
op.drop_table('a')
# ### end Alembic commands ###
With the above rewriter, it generates as:
使用上面的重写后,它生成为:
def downgrade():
# ### commands auto generated by Alembic - please adjust! ###
op.drop_table('b')
op.drop_table('a')
# ### end Alembic commands ###
Don’t generate any DROP TABLE directives with autogenerate
When running autogenerate against a database that has existing tables outside of the application’s autogenerated metadata, it may be desirable to prevent autogenerate from considering any of those existing tables to be dropped. This will prevent autogenerate from detecting tables removed from the local metadata as well however this is only a small caveat.
当对具有应用程序自动生成的元数据之外的现有表的数据库运行自动生成时,可能需要阻止自动生成考虑删除任何现有的表。 这也将阻止自动生成检测从本地元数据中删除的表,但这只是一个小警告。
The most direct way to achieve this using the EnvironmentContext.configure.include_object hook. There is no need to hardcode a fixed “whitelist” of table names; the hook gives enough information in the given arguments to determine if a particular table name is not part of the local MetaData being autogenerated, by checking first that the type of object is "table", then that reflected is True, indicating this table name is from the local database connection, not the MetaData, and finally that compare_to is None, indicating autogenerate is not comparing this Table to any Table in the local MetaData collection:
使用 EnvironmentContext.configure.include_object 钩子实现此目的的最直接方法。 无需硬编码固定的表名“白名单”; 钩子在给定的参数中提供了足够的信息来确定特定的表名是否不是自动生成的本地元数据的一部分,首先检查对象的类型是“表”,然后反映的是真,表明这个表名是来自本地数据库连接,而不是
MetaData,最后compare_to为None,表示 autogenerate 不会将此Table与本地MetaData集合中的任何Table进行比较:
# in env.py
def include_object(object, name, type_, reflected, compare_to):
if type_ == "table" and reflected and compare_to is None:
return False
else:
return True
context.configure(
# ...
include_object = include_object
)
Apply Custom Sorting to Table Columns within CREATE TABLE
This example illustrates use of the Rewriter object introduced at Fine-Grained Autogenerate Generation with Rewriters. While the rewriter grants access to the individual ops.MigrateOperation objects, there are sometimes some special techniques required to get around some structural limitations that are present.
此示例说明了 使用重写器在细粒度自动生成 中介绍的 Rewriter 对象的使用。 虽然重写器授予对单个 ops.MigrateOperation 对象的访问权限,但有时需要一些特殊技术来解决存在的一些结构限制。
One is when trying to reorganize the order of columns in a table within a ops.CreateTableOp directive. This directive, when generated by autogenerate, actually holds onto the original Table object as the source of its information, so attempting to reorder the ops.CreateTableOp.columns collection will usually have no effect. Instead, a new ops.CreateTableOp object may be constructed with the new ordering. However, a second issue is that the Column objects inside will already be associated with the Table that is from the model being autogenerated, meaning they can’t be reassigned directly to a new Table. To get around this, we can copy all the columns and constraints using methods like Column.copy().
一种是尝试在 ops.CreateTableOp 指令中重新组织表中列的顺序时。 该指令在由 autogenerate 生成时,实际上保留原始
Table对象作为其信息的来源,因此尝试重新排序ops.CreateTableOp.columns集合通常不会有任何效果。 相反,可以使用新的排序构造一个新的 ops.CreateTableOp 对象。 然而,第二个问题是内部的Column对象已经与来自正在自动生成的模型的表相关联,这意味着它们不能直接重新分配给新表。 为了解决这个问题,我们可以使用 Column.copy() 等方法复制所有列和约束。
Below we use Rewriter to create a new ops.CreateTableOp directive and to copy the Column objects from one into another, copying each column or constraint object and applying a new sorting scheme:
下面我们使用 Rewriter 创建一个新的 ops.CreateTableOp 指令并将
Column对象从一个复制到另一个,复制每个列或约束对象并应用新的排序方案:
# in env.py
from alembic.operations import ops
from alembic.autogenerate import rewriter
writer = rewriter.Rewriter()
@writer.rewrites(ops.CreateTableOp)
def order_columns(context, revision, op):
special_names = {"id": -100, "created_at": 1001, "updated_at": 1002}
cols_by_key = [
(
special_names.get(col.key, index)
if isinstance(col, Column)
else 2000,
col.copy(),
)
for index, col in enumerate(op.columns)
]
columns = [
col for idx, col in sorted(cols_by_key, key=lambda entry: entry[0])
]
return ops.CreateTableOp(
op.table_name, columns, schema=op.schema, **op.kw)
# ...
context.configure(
# ...
process_revision_directives=writer
)
Above, when we apply the writer to a table such as:
上面,当我们将 writer 应用于表时,例如:
Table(
"my_table",
m,
Column("data", String(50)),
Column("created_at", DateTime),
Column("id", Integer, primary_key=True),
Column("updated_at", DateTime),
UniqueConstraint("data", name="uq_data")
)
This will render in the autogenerated file as:
这将在自动生成的文件中呈现为:
def upgrade():
# ### commands auto generated by Alembic - please adjust! ###
op.create_table(
"my_table",
sa.Column("id", sa.Integer(), nullable=False),
sa.Column("data", sa.String(length=50), nullable=True),
sa.Column("created_at", sa.DateTime(), nullable=True),
sa.Column("updated_at", sa.DateTime(), nullable=True),
sa.PrimaryKeyConstraint("id"),
sa.UniqueConstraint("data", name="uq_data"),
)
# ### end Alembic commands ###
Don’t emit CREATE TABLE statements for Views
It is sometimes convenient to create Table instances for views so that they can be queried using normal SQLAlchemy techniques. Unfortunately this causes Alembic to treat them as tables in need of creation and to generate spurious create_table() operations. This is easily fixable by flagging such Tables and using the include_object hook to exclude them:
有时为视图创建 Table 实例很方便,以便可以使用普通的 SQLAlchemy 技术来查询它们。 不幸的是,这导致 Alembic 将它们视为需要创建的表并生成虚假的
create_table()操作。 这很容易通过标记此类表并使用 include_object 钩子排除它们来解决:
my_view = Table('my_view', metadata, autoload=True, info=dict(is_view=True)) # Flag this as a view
Then define include_object as:
def include_object(object, name, type_, reflected, compare_to):
"""
Exclude views from Alembic's consideration.
"""
return not object.info.get('is_view', False)
Finally, in env.py pass your include_object as a keyword argument to EnvironmentContext.configure().
最后,在
env.py中将您的include_object作为关键字参数传递给 EnvironmentContext.configure()。
Run Multiple Alembic Environments from one .ini file
Long before Alembic had the “multiple bases” feature described in Working with Multiple Bases, projects had a need to maintain more than one Alembic version history in a single project, where these version histories are completely independent of each other and each refer to their own alembic_version table, either across multiple databases, schemas, or namespaces. A simple approach was added to support this, the --name flag on the commandline.
早在 Alembic 拥有使用多个base中描述的“多base”功能之前,项目需要在单个项目中维护多个 Alembic 版本历史,其中这些版本历史完全相互独立,并且每个都引用自己的
alembic_version表,可以跨多个数据库、模式或命名空间。 添加了一种简单的方法来支持这一点,即命令行上的--name标志。
First, one would create an alembic.ini file of this form:
首先,创建一个这种形式的
alembic.ini文件:
[DEFAULT]
# all defaults shared between environments go here
sqlalchemy.url = postgresql://scott:tiger@hostname/mydatabase
[schema1]
# path to env.py and migration scripts for schema1
script_location = myproject/revisions/schema1
[schema2]
# path to env.py and migration scripts for schema2
script_location = myproject/revisions/schema2
[schema3]
# path to env.py and migration scripts for schema3
script_location = myproject/revisions/db2
# this schema uses a different database URL as well
sqlalchemy.url = postgresql://scott:tiger@hostname/myotherdatabase
Above, in the [DEFAULT] section we set up a default database URL. Then we create three sections corresponding to different revision lineages in our project. Each of these directories would have its own env.py and set of versioning files. Then when we run the alembic command, we simply give it the name of the configuration we want to use:
如上所示,在
[DEFAULT]部分中,我们设置了默认的 数据库URL。 然后我们在我们的项目中创建三个对应于不同修订沿袭的部分。 这些目录中的每一个都有自己的env.py和一组版本控制文件。 然后当我们运行alembic命令时,我们只需给它指定我们要使用的配置的名称:
alembic --name schema2 revision -m "new rev for schema 2" --autogenerate
Above, the alembic command makes use of the configuration in [schema2], populated with defaults from the [DEFAULT] section.
上面,
alembic命令使用[schema2]中的配置,填充了[DEFAULT]部分的默认值。
The above approach can be automated by creating a custom front-end to the Alembic commandline as well.
上述方法也可以通过为 Alembic 命令行创建自定义前端来实现自动化。
Print Python Code to Generate Particular Database Tables
打印 Python 代码以生成特定的数据库表
Suppose you have a database already, and want to generate some op.create_table() and other directives that you’d have in a migration file. How can we automate generating that code? Suppose the database schema looks like (assume MySQL):
假设您已经有一个数据库,并且想要生成一些
op.create_table()和迁移文件中的其他指令。 我们如何自动生成该代码? 假设数据库模式看起来像(假设为 MySQL):
CREATE TABLE IF NOT EXISTS `users` (
`id` int(11) NOT NULL,
KEY `id` (`id`)
);
CREATE TABLE IF NOT EXISTS `user_properties` (
`users_id` int(11) NOT NULL,
`property_name` varchar(255) NOT NULL,
`property_value` mediumtext NOT NULL,
UNIQUE KEY `property_name_users_id` (`property_name`,`users_id`),
KEY `users_id` (`users_id`),
CONSTRAINT `user_properties_ibfk_1` FOREIGN KEY (`users_id`)
REFERENCES `users` (`id`) ON DELETE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Using ops.UpgradeOps, ops.CreateTableOp, and ops.CreateIndexOp, we create a migration file structure, using Table objects that we get from SQLAlchemy reflection. The structure is passed to autogenerate.render_python_code() to produce the Python code for a migration file:
使用 ops.UpgradeOps, ops.CreateTableOp 和 ops.CreateIndexOp,我们使用从 SQLAlchemy 反射获得的
Table对象创建迁移文件结构。 该结构被传递给 autogenerate.render_python_code() 以生成迁移文件的 Python 代码:
from sqlalchemy import create_engine
from sqlalchemy import MetaData, Table
from alembic import autogenerate
from alembic.operations import ops
e = create_engine("mysql://scott:tiger@localhost/test")
with e.connect() as conn:
m = MetaData()
user_table = Table('users', m, autoload_with=conn)
user_property_table = Table('user_properties', m, autoload_with=conn)
print(autogenerate.render_python_code(
ops.UpgradeOps(
ops=[
ops.CreateTableOp.from_table(table) for table in m.tables.values()
] + [
ops.CreateIndexOp.from_index(idx) for table in m.tables.values()
for idx in table.indexes
]
))
)
Output:
# ### commands auto generated by Alembic - please adjust! ###
op.create_table('users',
sa.Column('id', mysql.INTEGER(display_width=11), autoincrement=False, nullable=False),
mysql_default_charset='latin1',
mysql_engine='InnoDB'
)
op.create_table('user_properties',
sa.Column('users_id', mysql.INTEGER(display_width=11), autoincrement=False, nullable=False),
sa.Column('property_name', mysql.VARCHAR(length=255), nullable=False),
sa.Column('property_value', mysql.MEDIUMTEXT(), nullable=False),
sa.ForeignKeyConstraint(['users_id'], ['users.id'], name='user_properties_ibfk_1', ondelete='CASCADE'),
mysql_comment='user properties',
mysql_default_charset='utf8',
mysql_engine='InnoDB'
)
op.create_index('id', 'users', ['id'], unique=False)
op.create_index('users_id', 'user_properties', ['users_id'], unique=False)
op.create_index('property_name_users_id', 'user_properties', ['property_name', 'users_id'], unique=True)
# ### end Alembic commands ###
Run Alembic Operation Objects Directly (as in from autogenerate)
The Operations object has a method known as Operations.invoke() that will generically invoke a particular operation object. We can therefore use the autogenerate.produce_migrations() function to run an autogenerate comparison, get back a ops.MigrationScript structure representing the changes, and with a little bit of insider information we can invoke them directly.
Operations 对象有一个称为 Operations.invoke() 的方法,它通常会调用特定的操作对象。 因此,我们可以使用 autogenerate.produce_migrations() 函数来运行自动生成比较,返回一个表示更改的 ops.MigrationScript 结构,并且通过一些内部信息,我们可以直接调用它们。
The traversal through the ops.MigrationScript structure is as follows:
通过 ops.MigrationScript 结构的遍历如下:
use_batch = engine.name == "sqlite"
stack = [migrations.upgrade_ops]
while stack:
elem = stack.pop(0)
if use_batch and isinstance(elem, ModifyTableOps):
with operations.batch_alter_table(
elem.table_name, schema=elem.schema
) as batch_ops:
for table_elem in elem.ops:
# work around Alembic issue #753 (fixed in 1.5.0)
if hasattr(table_elem, "column"):
table_elem.column = table_elem.column.copy()
batch_ops.invoke(table_elem)
elif hasattr(elem, "ops"):
stack.extend(elem.ops)
else:
# work around Alembic issue #753 (fixed in 1.5.0)
if hasattr(elem, "column"):
elem.column = elem.column.copy()
operations.invoke(elem)
Above, we detect elements that have a collection of operations by looking for the .ops attribute. A check for ModifyTableOps allows us to use a batch context if we are supporting that. Finally there’s a workaround for an Alembic issue that exists for SQLAlchemy 1.3.20 and greater combined with Alembic older than 1.5.
上面,我们通过查找
.ops属性来检测具有操作集合的元素。 如果我们支持,对 ModifyTableOps 的检查允许我们使用批处理上下文。 最后,对于 SQLAlchemy 1.3.20 和更高版本以及早于 1.5 的 Alembic 存在的 Alembic 问题,有一个解决方法。
A full example follows. The overall setup here is copied from the example at autogenerate.compare_metadata():
下面是一个完整的例子。 这里的整体设置是从 autogenerate.compare_metadata() 的示例复制而来的:
from sqlalchemy import Column
from sqlalchemy import create_engine
from sqlalchemy import Integer
from sqlalchemy import MetaData
from sqlalchemy import String
from sqlalchemy import Table
from alembic.autogenerate import produce_migrations
from alembic.migration import MigrationContext
from alembic.operations import Operations
from alembic.operations.ops import ModifyTableOps
engine = create_engine("sqlite://", echo=True)
with engine.connect() as conn:
conn.execute(
"""
create table foo (
id integer not null primary key,
old_data varchar(50),
x integer
)"""
)
conn.execute(
"""
create table bar (
data varchar(50)
)"""
)
metadata = MetaData()
Table(
"foo",
metadata,
Column("id", Integer, primary_key=True),
Column("data", Integer),
Column("x", Integer, nullable=False),
)
Table("bat", metadata, Column("info", String(100)))
mc = MigrationContext.configure(engine.connect())
migrations = produce_migrations(mc, metadata)
operations = Operations(mc)
use_batch = engine.name == "sqlite"
stack = [migrations.upgrade_ops]
while stack:
elem = stack.pop(0)
if use_batch and isinstance(elem, ModifyTableOps):
with operations.batch_alter_table(
elem.table_name, schema=elem.schema
) as batch_ops:
for table_elem in elem.ops:
# work around Alembic issue #753 (fixed in 1.5.0)
if hasattr(table_elem, "column"):
table_elem.column = table_elem.column.copy()
batch_ops.invoke(table_elem)
elif hasattr(elem, "ops"):
stack.extend(elem.ops)
else:
# work around Alembic issue #753 (fixed in 1.5.0)
if hasattr(elem, "column"):
elem.column = elem.column.copy()
operations.invoke(elem)
Test current database revision is at head(s)
A recipe to determine if a database schema is up to date in terms of applying Alembic migrations. May be useful for test or installation suites to determine if the target database is up to date. Makes use of the MigrationContext.get_current_heads() as well as ScriptDirectory.get_heads() methods so that it accommodates for a branched revision tree:
在应用 Alembic 迁移方面确定数据库模式是否是最新的配方。 可能有助于测试或安装套件确定目标数据库是否是最新的。 使用 MigrationContext.get_current_heads() 和 ScriptDirectory.get_heads() 方法,以便它适应分支的修订树:
from alembic import config, script
from alembic.runtime import migration
from sqlalchemy import engine
def check_current_head(alembic_cfg, connectable):
# type: (config.Config, engine.Engine) -> bool
directory = script.ScriptDirectory.from_config(alembic_cfg)
with connectable.begin() as connection:
context = migration.MigrationContext.configure(connection)
return set(context.get_current_heads()) == set(directory.get_heads())
e = engine.create_engine("mysql://scott:tiger@localhost/test", echo=True)
cfg = config.Config("alembic.ini")
print(check_current_head(cfg, e))
同样参考:
Using Asyncio with Alembic
将 Asyncio 与 Alembic 结合使用
SQLAlchemy version 1.4 introduced experimental support for asyncio, allowing use of most of its interface from async applications. Alembic currently does not provide an async api directly, but it can use an use SQLAlchemy Async engine to run the migrations and autogenerate.
SQLAlchemy 1.4 版引入了对
asyncio的实验性支持,允许在异步应用程序中使用其大部分接口。 Alembic 目前不直接提供异步 API,但它可以使用 SQLAlchemy 异步引擎来运行迁移和自动生成。
New configurations can use the template “async” to bootstrap an environment which can be used with async DBAPI like asyncpg, running the command:
新配置可以使用模板
“async”来引导一个环境,该环境可以与asyncpg之类的异步 DBAPI 一起使用,运行命令:
alembic init -t async <script_directory_here>
Existing configurations can be updated to use an async DBAPI by updating the env.py file that’s used by Alembic to start its operations. In particular only run_migrations_online will need to be updated to be something like the example below:
通过更新 Alembic 用于启动其操作的
env.py文件,可以更新现有配置以使用异步 DBAPI。 特别是只有run_migrations_online需要更新为类似于以下示例的内容:
import asyncio
# ... no change required to the rest of the code
def do_run_migrations(connection):
context.configure(connection=connection, target_metadata=target_metadata)
with context.begin_transaction():
context.run_migrations()
async def run_migrations_online():
"""Run migrations in 'online' mode.
In this scenario we need to create an Engine
and associate a connection with the context.
"""
connectable = AsyncEngine(
engine_from_config(
config.get_section(config.config_ini_section),
prefix="sqlalchemy.",
poolclass=pool.NullPool,
future=True,
)
)
async with connectable.connect() as connection:
await connection.run_sync(do_run_migrations)
if context.is_offline_mode():
run_migrations_offline()
else:
asyncio.run(run_migrations_online())
An asnyc application can also interact with the Alembic api directly by using the SQLAlchemy run_sync method to adapt the non-async api of Alembic to an async consumer.
asnyc 应用程序也可以通过使用 SQLAlchemy 的
run_sync方法直接与 Alembic api 交互,以使 Alembic 的非异步 api 适应异步使用者。
API Details
API详细
Alembic’s internal API has many public integration points that can be used to extend Alembic’s functionality as well as to re-use its functionality in new ways. As the project has grown, more APIs are created and exposed for this purpose.
Direct use of the vast majority of API details discussed here is not needed for rudimentary use of Alembic; the only API that is used normally by end users is the methods provided by the Operations class, which is discussed outside of this subsection, and the parameters that can be passed to the EnvironmentContext.configure() method, used when configuring one’s env.py environment. However, real-world applications will usually end up using more of the internal API, in particular being able to run commands programmatically, as discussed in the section Commands.
Overview
Note: this section is a technical overview of the internal API of Alembic. This section is only useful for developers who wish to extend the capabilities of Alembic; for regular users, reading this section is not necessary.
A visualization of the primary features of Alembic’s internals is presented in the following figure. The module and class boxes do not list out all the operations provided by each unit; only a small set of representative elements intended to convey the primary purpose of each system.
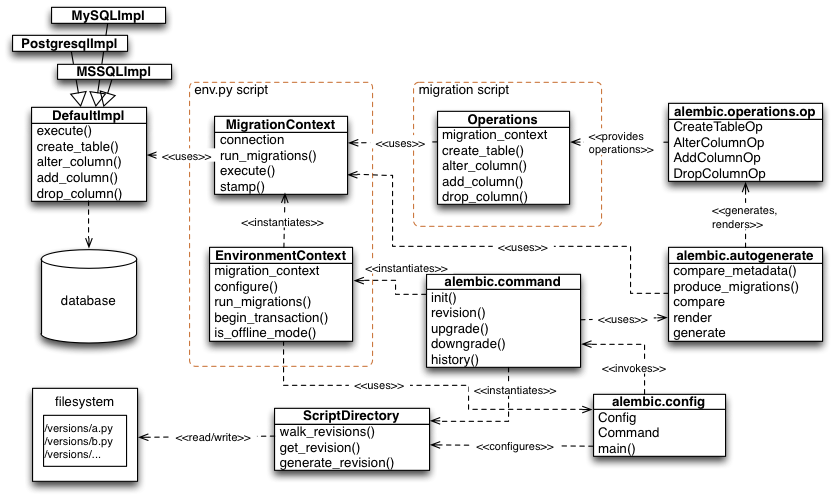
The script runner for Alembic is present in the Configuration module. This module produces a Config object and passes it to the appropriate function in Commands. Functions within Commands will typically instantiate an ScriptDirectory instance, which represents the collection of version files, and an EnvironmentContext, which is a configurational facade passed to the environment’s env.py script.
The EnvironmentContext object is the primary object used within the env.py script, whose main purpose is that of a facade for creating and using a MigrationContext object, which is the actual migration engine that refers to a database implementation. The primary method called on this object within an env.py script is the EnvironmentContext.configure() method, which sets up the MigrationContext with database connectivity and behavioral configuration. It also supplies methods for transaction demarcation and migration running, but these methods ultimately call upon the MigrationContext that’s been configured.
MigrationContext is the gateway to the database for other parts of the application, and produces a DefaultImpl object which does the actual database communication, and knows how to create the specific SQL text of the various DDL directives such as ALTER TABLE; DefaultImpl has subclasses that are per-database-backend. In “offline” mode (e.g. --sql), the MigrationContext will produce SQL to a file output stream instead of a database.
During an upgrade or downgrade operation, a specific series of migration scripts are invoked starting with the MigrationContext in conjunction with the ScriptDirectory; the actual scripts themselves make use of the Operations object, which provide the end-user interface to specific database operations. The Operations object is generated based on a series of “operation directive” objects that are user-extensible, and start out in the Built-in Operation Objects module.
Another prominent feature of Alembic is the “autogenerate” feature, which produces new migration scripts that contain Python code. The autogenerate feature starts in Autogeneration, and is used exclusively by the alembic.command.revision() command when the --autogenerate flag is passed. Autogenerate refers to the MigrationContext and DefaultImpl in order to access database connectivity and access per-backend rules for autogenerate comparisons. It also makes use of Built-in Operation Objects in order to represent the operations that it will render into scripts.
Runtime Objects
The “runtime” of Alembic involves the EnvironmentContext and MigrationContext objects. These are the objects that are in play once the env.py script is loaded up by a command and a migration operation proceeds.
The Environment Context
The EnvironmentContext class provides most of the API used within an env.py script. Within env.py, the instantated EnvironmentContext is made available via a special proxy module called alembic.context. That is, you can import alembic.context like a regular Python module, and each name you call upon it is ultimately routed towards the current EnvironmentContext in use.
In particular, the key method used within env.py is EnvironmentContext.configure(), which establishes all the details about how the database will be accessed.
class alembic.runtime.environment.EnvironmentContext(config: Config, script: ScriptDirectory, **kw)
A configurational facade made available in an env.py script.
The EnvironmentContext acts as a facade to the more nuts-and-bolts objects of MigrationContext as well as certain aspects of Config, within the context of the env.py script that is invoked by most Alembic commands.
EnvironmentContext is normally instantiated when a command in alembic.command is run. It then makes itself available in the alembic.context module for the scope of the command. From within an env.py script, the current EnvironmentContext is available by importing this module.
EnvironmentContext also supports programmatic usage. At this level, it acts as a Python context manager, that is, is intended to be used using the with: statement. A typical use of EnvironmentContext:
from alembic.config import Config
from alembic.script import ScriptDirectory
config = Config()
config.set_main_option("script_location", "myapp:migrations")
script = ScriptDirectory.from_config(config)
def my_function(rev, context):
'''do something with revision "rev", which
will be the current database revision,
and "context", which is the MigrationContext
that the env.py will create'''
with EnvironmentContext(
config,
script,
fn = my_function,
as_sql = False,
starting_rev = 'base',
destination_rev = 'head',
tag = "sometag"
):
script.run_env()
The above script will invoke the env.py script within the migration environment. If and when env.py calls MigrationContext.run_migrations(), the my_function() function above will be called by the MigrationContext, given the context itself as well as the current revision in the database.
Note: For most API usages other than full blown invocation of migration scripts, the MigrationContext and ScriptDirectory objects can be created and used directly. The EnvironmentContext object is only needed when you need to actually invoke the
env.pymodule present in the migration environment.
Construct a new EnvironmentContext.
Parameters:
- config – a Config instance.
- script – a ScriptDirectory instance.
- **kw – keyword options that will be ultimately passed along to the MigrationContext when EnvironmentContext.configure() is called.
begin_transaction
begin_transaction() → Union[_ProxyTransaction, AbstractContextManager]
Return a context manager that will enclose an operation within a “transaction”, as defined by the environment’s offline and transactional DDL settings.
e.g.:
with context.begin_transaction():
context.run_migrations()
begin_transaction() is intended to “do the right thing” regardless of calling context:
- If is_transactional_ddl() is
False, returns a “do nothing” context manager which otherwise produces no transactional state or directives. - If is_offline_mode() is
True, returns a context manager that will invoke the DefaultImpl.emit_begin() and DefaultImpl.emit_commit() methods, which will produce the string directivesBEGINandCOMMITon the output stream, as rendered by the target backend (e.g. SQL Server would emitBEGINTRANSACTION). - Otherwise, calls sqlalchemy.engine.Connection.begin() on the current online connection, which returns a sqlalchemy.engine.Transaction object. This object demarcates a real transaction and is itself a context manager, which will roll back if an exception is raised.
Note: that a custom
env.pyscript which has more specific transactional needs can of course manipulate the Connection directly to produce transactional state in “online” mode.
config
config: Config = None
An instance of Config representing the configuration file contents as well as other variables set programmatically within it.
configure
configure(connection: Optional[Connection] = None, url: Optional[str] = None, dialect_name: Optional[str] = None, dialect_opts: Optional[dict] = None, transactional_ddl: Optional[bool] = None, transaction_per_migration: bool = False, output_buffer: Optional[TextIO] = None, starting_rev: Optional[str] = None, tag: Optional[str] = None, template_args: Optional[dict] = None, render_as_batch: bool = False, target_metadata: Optional[MetaData] = None, include_name: Optional[Callable] = None, include_object: Optional[Callable] = None, include_schemas: bool = False, process_revision_directives: Optional[Callable] = None, compare_type: bool = False, compare_server_default: bool = False, render_item: Optional[Callable] = None, literal_binds: bool = False, upgrade_token: str = 'upgrades', downgrade_token: str = 'downgrades', alembic_module_prefix: str = 'op.', sqlalchemy_module_prefix: str = 'sa.', user_module_prefix: Optional[str] = None, on_version_apply: Optional[Callable] = None, **kw) → None
Configure a MigrationContext within this EnvironmentContext which will provide database connectivity and other configuration to a series of migration scripts.
Many methods on EnvironmentContext require that this method has been called in order to function, as they ultimately need to have database access or at least access to the dialect in use. Those which do are documented as such.
The important thing needed by configure() is a means to determine what kind of database dialect is in use. An actual connection to that database is needed only if the MigrationContext is to be used in “online” mode.
If the is_offline_mode() function returns True, then no connection is needed here. Otherwise, the connection parameter should be present as an instance of sqlalchemy.engine.Connection.
This function is typically called from the env.py script within a migration environment. It can be called multiple times for an invocation. The most recent Connection for which it was called is the one that will be operated upon by the next call to run_migrations().
General parameters:
- connection – a Connection to use for SQL execution in “online” mode. When present, is also used to determine the type of dialect in use.
- url – a string database url, or a sqlalchemy.engine.url.URL object. The type of dialect to be used will be derived from this if
connectionis not passed. - dialect_name – string name of a dialect, such as “postgresql”, “mssql”, etc. The type of dialect to be used will be derived from this if
connectionandurlare not passed. - dialect_opts – dictionary of options to be passed to dialect constructor.
New in version 1.0.12.
- transactional_ddl – Force the usage of “transactional” DDL on or off; this otherwise defaults to whether or not the dialect in use supports it.
- transaction_per_migration – if True, nest each migration script in a transaction rather than the full series of migrations to run.
- output_buffer – a file-like object that will be used for textual output when the
--sqloption is used to generate SQL scripts. Defaults tosys.stdoutif not passed here and also not present on the Config object. The value here overrides that of the Config object. - output_encoding – when using
--sqlto generate SQL scripts, apply this encoding to the string output. - literal_binds – when using
--sqlto generate SQL scripts, pass through theliteral_bindsflag to the compiler so that any literal values that would ordinarily be bound parameters are converted to plain strings.Warning: Dialects can typically only handle simple datatypes like strings and numbers for auto-literal generation. Datatypes like dates, intervals, and others may still require manual formatting, typically using Operations.inline_literal().
Note: the
literal_bindsflag is ignored on SQLAlchemy versions prior to 0.8 where this feature is not supported.See also: Operations.inline_literal()
- starting_rev – Override the “starting revision” argument when using
--sqlmode. - tag – a string tag for usage by custom
env.pyscripts. Set via the--tagoption, can be overridden here. - template_args – dictionary of template arguments which will be added to the template argument environment when running the “revision” command. Note that the script environment is only run within the “revision” command if the –autogenerate option is used, or if the option “revision_environment=true” is present in the alembic.ini file.
- version_table – The name of the Alembic version table. The default is
'alembic_version'. - version_table_schema – Optional schema to place version table within.
- version_table_pk – boolean, whether the Alembic version table should use a primary key constraint for the “value” column; this only takes effect when the table is first created. Defaults to True; setting to False should not be necessary and is here for backwards compatibility reasons.
- on_version_apply – a callable or collection of callables to be run for each migration step. The callables will be run in the order they are given, once for each migration step, after the respective operation has been applied but before its transaction is finalized. Each callable accepts no positional arguments and the following keyword arguments:
- ctx: the MigrationContext running the migration,
- step: a
MigrationInforepresenting thestepcurrently being applied, - heads: a collection of version strings representing the current
heads, - run_args: the
**kwargspassed to run_migrations().
Parameters specific to the autogenerate feature, when alembic revision is run with the --autogenerate feature:
-
target_metadata – a sqlalchemy.schema.MetaData object, or a sequence of MetaData objects, that will be consulted during autogeneration. The tables present in each MetaData will be compared against what is locally available on the target Connection to produce candidate upgrade/downgrade operations.
-
compare_type – Indicates type comparison behavior during an autogenerate operation. Defaults to
Falsewhich disables type comparison. Set toTrueto turn on default type comparison, which has varied accuracy depending on backend. See Comparing Types for an example as well as information on other type comparison options.See also: Comparing Types
-
compare_server_default – Indicates server default comparison behavior during an autogenerate operation. Defaults to
Falsewhich disables server default comparison. Set toTrueto turn on server default comparison, which has varied accuracy depending on backend.To customize server default comparison behavior, a callable may be specified which can filter server default comparisons during an autogenerate operation. defaults during an autogenerate operation. The format of this callable is:
def my_compare_server_default(context, inspected_column, metadata_column, inspected_default, metadata_default, rendered_metadata_default): # return True if the defaults are different, # False if not, or None to allow the default implementation # to compare these defaults return None context.configure( # ... compare_server_default = my_compare_server_default )inspected_column is a dictionary structure as returned by sqlalchemy.engine.reflection.Inspector.get_columns(), whereas
metadata_columnis a sqlalchemy.schema.Column from the local model environment.A return value of
Noneindicates to allow default server default comparison to proceed. Note that some backends such as Postgresql actually execute the two defaults on the database side to compare for equivalence. -
include_name – A callable function which is given the chance to return
TrueorFalsefor any database reflected object based on its name, including database schema names when the EnvironmentContext.configure.include_schemas flag is set toTrue.The function accepts the following positional arguments:
-
name: the
nameof the object, such as schemanameor tablename. Will beNonewhen indicating the default schemanameof the database connection. -
type: a string describing the
typeof object; currently"schema","table","column","index","unique_constraint", or "foreign_key_constraint" -
parent_names: a dictionary of “parent” object names, that are relative to the name being given. Keys in this dictionary may include:
"schema_name","table_name".E.g.:
def include_name(name, type_, parent_names): if type_ == "schema": return name in ["schema_one", "schema_two"] else: return True context.configure( # ... include_schemas = True, include_name = include_name )New in version 1.5.
See also: Controlling What to be Autogenerated
-
-
include_object – A callable function which is given the chance to return
TrueorFalsefor any object, indicating if the given object should be considered in the autogenerate sweep.The function accepts the following positional arguments:
-
object: a SchemaItem
objectsuch as a Table, Column, Index UniqueConstraint, or ForeignKeyConstraint object -
name: the
nameof the object. This is typically available viaobject.name. -
type: a string describing the
typeof object; currently"table","column","index","unique_constraint", or "foreign_key_constraint" -
reflected:
Trueif the given object was produced based on table reflection,Falseif it’s from a localMetaDataobject. -
compare_to: the object being compared against, if available, else
None. E.g.:def include_object(object, name, type_, reflected, compare_to): if (type_ == "column" and not reflected and object.info.get("skip_autogenerate", False)): return False else: return True context.configure( # ... include_object = include_object )For the use case of omitting specific schemas from a target database when EnvironmentContext.configure.include_schemas is set to
True, theschemaattribute can be checked for each Table object passed to the hook, however it is much more efficient to filter on schemas before reflection of objects takes place using the EnvironmentContext.configure.include_name hook.See also: Controlling What to be Autogenerated
-
-
render_as_batch – if True, commands which alter elements within a table will be placed under a
with batch_alter_table():directive, so that batch migrations will take place.See also: Running “Batch” Migrations for SQLite and Other Databases
-
include_schemas – If True, autogenerate will scan across all schemas located by the SQLAlchemy get_schema_names() method, and include all differences in tables found across all those schemas. When using this option, you may want to also use the EnvironmentContext.configure.include_name parameter to specify a callable which can filter the tables/schemas that get included.
See also: Controlling What to be Autogenerated
-
render_item – Callable that can be used to override how any schema item, i.e. column, constraint, type, etc., is rendered for autogenerate. The callable receives a string describing the type of object, the object, and the autogen context. If it returns False, the default rendering method will be used. If it returns None, the item will not be rendered in the context of a Table construct, that is, can be used to skip columns or constraints within op.create_table():
def my_render_column(type_, col, autogen_context): if type_ == "column" and isinstance(col, MySpecialCol): return repr(col) else: return False context.configure( # ... render_item = my_render_column )Available values for the type string include:
"column","primary_key","foreign_key","unique","check","type","server_default". -
upgrade_token – When autogenerate completes, the text of the candidate upgrade operations will be present in this template variable when
script.py.makois rendered. Defaults toupgrades. -
downgrade_token – When autogenerate completes, the text of the candidate downgrade operations will be present in this template variable when
script.py.makois rendered. Defaults todowngrades. -
alembic_module_prefix – When autogenerate refers to Alembic alembic.operations constructs, this prefix will be used (i.e. op.create_table) Defaults to “op.”. Can be
Noneto indicate no prefix. -
sqlalchemy_module_prefix – When autogenerate refers to SQLAlchemy Column or type classes, this prefix will be used (i.e. sa.Column("somename", sa.Integer)) Defaults to “sa.”. Can be
Noneto indicate no prefix. Note that when dialect-specific types are rendered, autogenerate will render them using the dialect module name, i.e.mssql.BIT(),postgresql.UUID(). -
user_module_prefix – When autogenerate refers to a SQLAlchemy type (e.g. TypeEngine) where the module name is not under the
sqlalchemynamespace, this prefix will be used within autogenerate. If left at its default ofNone, the__module__attribute of the type is used to render the import module. It’s a good practice to set this and to have all custom types be available from a fixed module space, in order to future-proof migration files against reorganizations in modules.See also: Controlling the Module Prefix
-
process_revision_directives – a callable function that will be passed a structure representing the end result of an autogenerate or plain “revision” operation, which can be manipulated to affect how the
alembic revisioncommand ultimately outputs new revision scripts. The structure of the callable is:def process_revision_directives(context, revision, directives): passThe
directivesparameter is a Python list containing a single MigrationScript directive, which represents therevisionfile to be generated. This list as well as its contents may be freely modified to produce any set of commands. The section Customizing Revision Generation shows an example of doing this. Thecontextparameter is the MigrationContext in use, andrevisionis a tuple ofrevisionidentifiers representing the currentrevisionof the database.The callable is invoked at all times when the
--autogenerateoption is passed toalembic revision. If--autogenerateis not passed, the callable is invoked only if therevision_environmentvariable is set to True in the Alembic configuration, in which case the givendirectivescollection will contain empty UpgradeOps and DowngradeOps collections for.upgrade_opsand.downgrade_ops. The--autogenerateoption itself can be inferred by inspectingcontext.config.cmd_opts.autogenerate.The callable function may optionally be an instance of a Rewriter object. This is a helper object that assists in the production of autogenerate-stream rewriter functions.
See also: Customizing Revision Generation
Parameters specific to individual backends:
- mssql_batch_separator – The “batch separator” which will be placed between each statement when generating offline SQL Server migrations. Defaults to
GO. Note this is in addition to the customary semicolon;at the end of each statement; SQL Server considers the “batch separator” to denote the end of an individual statement execution, and cannot group certain dependent operations in one step. - oracle_batch_separator – The “batch separator” which will be placed between each statement when generating offline Oracle migrations. Defaults to
/. Oracle doesn’t add a semicolon between statements like most other backends.
execute
execute(sql, execution_options=None)
Execute the given SQL using the current change context.
The behavior of execute() is the same as that of Operations.execute(). Please see that function’s documentation for full detail including caveats and limitations.
This function requires that a MigrationContext has first been made available via configure().
get_bind
get_bind()
Return the current ‘bind’.
In “online” mode, this is the sqlalchemy.engine.Connection currently being used to emit SQL to the database.
This function requires that a MigrationContext has first been made available via configure().
get_context
get_context() → alembic.runtime.migration.MigrationContext
Return the current MigrationContext object.
If EnvironmentContext.configure() has not been called yet, raises an exception.
get_head_revision
get_head_revision() → Optional[Union[str, Tuple[str, ...]]]
Return the hex identifier of the ‘head’ script revision.
If the script directory has multiple heads, this method raises a CommandError; EnvironmentContext.get_head_revisions() should be preferred.
This function does not require that the MigrationContext has been configured.
See also:
get_head_revisions
get_head_revisions() → Optional[Union[str, Tuple[str, ...]]]
Return the hex identifier of the ‘heads’ script revision(s).
This returns a tuple containing the version number of all heads in the script directory.
This function does not require that the MigrationContext has been configured.
get_revision_argument
get_revision_argument() → Optional[Union[str, Tuple[str, ...]]]
Get the ‘destination’ revision argument.
This is typically the argument passed to the upgrade or downgrade command.
If it was specified as head, the actual version number is returned; if specified as base, None is returned.
This function does not require that the MigrationContext has been configured.
get_starting_revision_argument
get_starting_revision_argument() → Optional[Union[str, Tuple[str, ...]]]
Return the ‘starting revision’ argument, if the revision was passed using start:end.
This is only meaningful in “offline” mode. Returns None if no value is available or was configured.
This function does not require that the MigrationContext has been configured.
get_tag_argument
get_tag_argument() → Optional[str]
Return the value passed for the --tag argument, if any.
The --tag argument is not used directly by Alembic, but is available for custom env.py configurations that wish to use it; particularly for offline generation scripts that wish to generate tagged filenames.
This function does not require that the MigrationContext has been configured.
See also:
EnvironmentContext.get_x_argument() - a newer and more open ended system of extending env.py scripts via the command line.
get_x_argument
get_x_argument(as_dictionary: Literal[False] = False) → List[str]
get_x_argument(as_dictionary: Literal[True] = False) → Dict[str, str]
Return the value(s) passed for the -x argument, if any.
The -x argument is an open ended flag that allows any user-defined value or values to be passed on the command line, then available here for consumption by a custom env.py script.
The return value is a list, returned directly from the argparse structure. If as_dictionary=True is passed, the x arguments are parsed using key=value format into a dictionary that is then returned.
For example, to support passing a database URL on the command line, the standard env.py script can be modified like this:
cmd_line_url = context.get_x_argument(
as_dictionary=True).get('dbname')
if cmd_line_url:
engine = create_engine(cmd_line_url)
else:
engine = engine_from_config(
config.get_section(config.config_ini_section),
prefix='sqlalchemy.',
poolclass=pool.NullPool)
This then takes effect by running the alembic script as:
alembic -x dbname=postgresql://user:pass@host/dbname upgrade head
This function does not require that the MigrationContext has been configured.
See also:
is_offline_mode
is_offline_mode() → bool
Return True if the current migrations environment is running in “offline mode”.
This is True or False depending on the --sql flag passed.
This function does not require that the MigrationContext has been configured.
is_transactional_ddl
is_transactional_ddl()
Return True if the context is configured to expect a transactional DDL capable backend.
This defaults to the type of database in use, and can be overridden by the transactional_ddl argument to configure()
This function requires that a MigrationContext has first been made available via configure().
run_migrations
run_migrations(**kw) → None
Run migrations as determined by the current command line configuration as well as versioning information present (or not) in the current database connection (if one is present).
The function accepts optional **kw arguments. If these are passed, they are sent directly to the upgrade() and downgrade() functions within each target revision file. By modifying the script.py.mako file so that the upgrade() and downgrade() functions accept arguments, parameters can be passed here so that contextual information, usually information to identify a particular database in use, can be passed from a custom env.py script to the migration functions.
This function requires that a MigrationContext has first been made available via configure().
script
An instance of ScriptDirectory which provides programmatic access to version files within the versions/ directory.
static_output
static_output(text)
Emit text directly to the “offline” SQL stream.
Typically this is for emitting comments that start with –. The statement is not treated as a SQL execution, no ; or batch separator is added, etc.
The Migration Context
The MigrationContext handles the actual work to be performed against a database backend as migration operations proceed. It is generally not exposed to the end-user, except when the on_version_apply callback hook is used.
class alembic.runtime.migration.MigrationContext(dialect: Dialect, connection: Optional[Connection], opts: Dict[str, Any], environment_context: Optional[EnvironmentContext] = None)
Represent the database state made available to a migration script.
MigrationContext is the front end to an actual database connection, or alternatively a string output stream given a particular database dialect, from an Alembic perspective.
When inside the env.py script, the MigrationContext is available via the EnvironmentContext.get_context() method, which is available at alembic.context:
# from within env.py script
from alembic import context
migration_context = context.get_context()
For usage outside of an env.py script, such as for utility routines that want to check the current version in the database, the MigrationContext.configure() method to create new MigrationContext objects. For example, to get at the current revision in the database using MigrationContext.get_current_revision():
# in any application, outside of an env.py script
from alembic.migration import MigrationContext
from sqlalchemy import create_engine
engine = create_engine("postgresql://mydatabase")
conn = engine.connect()
context = MigrationContext.configure(conn)
current_rev = context.get_current_revision()
The above context can also be used to produce Alembic migration operations with an Operations instance:
# in any application, outside of the normal Alembic environment
from alembic.operations import Operations
op = Operations(context)
op.alter_column("mytable", "somecolumn", nullable=True)
autocommit_block
autocommit_block() → Iterator[None]
Enter an “autocommit” block, for databases that support AUTOCOMMIT isolation levels.
This special directive is intended to support the occasional database DDL or system operation that specifically has to be run outside of any kind of transaction block. The PostgreSQL database platform is the most common target for this style of operation, as many of its DDL operations must be run outside of transaction blocks, even though the database overall supports transactional DDL.
The method is used as a context manager within a migration script, by calling on Operations.get_context() to retrieve the MigrationContext, then invoking MigrationContext.autocommit_block() using the with: statement:
def upgrade():
with op.get_context().autocommit_block():
op.execute("ALTER TYPE mood ADD VALUE 'soso'")
Above, a PostgreSQL “ALTER TYPE..ADD VALUE” directive is emitted, which must be run outside of a transaction block at the database level. The MigrationContext.autocommit_block() method makes use of the SQLAlchemy AUTOCOMMIT isolation level setting, which against the psycogp2 DBAPI corresponds to the connection.autocommit setting, to ensure that the database driver is not inside of a DBAPI level transaction block.
Warning: As is necessary, the database transaction preceding the block is unconditionally committed. This means that the run of migrations preceding the operation will be committed, before the overall migration operation is complete.
It is recommended that when an application includes migrations with “autocommit” blocks, that EnvironmentContext.transaction_per_migration be used so that the calling environment is tuned to expect short per-file migrations whether or not one of them has an autocommit block.
New in version 1.2.0.
begin_transaction
begin_transaction(_per_migration: bool = False) → Union[alembic.runtime.migration._ProxyTransaction, AbstractContextManager]
Begin a logical transaction for migration operations.
This method is used within an env.py script to demarcate where the outer “transaction” for a series of migrations begins. Example:
def run_migrations_online():
connectable = create_engine(...)
with connectable.connect() as connection:
context.configure(
connection=connection, target_metadata=target_metadata
)
with context.begin_transaction():
context.run_migrations()
Above, MigrationContext.begin_transaction() is used to demarcate where the outer logical transaction occurs around the MigrationContext.run_migrations() operation.
A “Logical” transaction means that the operation may or may not correspond to a real database transaction. If the target database supports transactional DDL (or EnvironmentContext.configure.transactional_ddl is true), the EnvironmentContext.configure.transaction_per_migration flag is not set, and the migration is against a real database connection (as opposed to using “offline” --sql mode), a real transaction will be started. If --sql mode is in effect, the operation would instead correspond to a string such as “BEGIN” being emitted to the string output.
The returned object is a Python context manager that should only be used in the context of a with: statement as indicated above. The object has no other guaranteed API features present.
See also:
bind
property bind: Optional[Connection]
Return the current “bind”.
In online mode, this is an instance of sqlalchemy.engine.Connection, and is suitable for ad-hoc execution of any kind of usage described in SQL Expression Language Tutorial (1.x API) as well as for usage with the sqlalchemy.schema.Table.create() and sqlalchemy.schema.MetaData.create_all() methods of Table, MetaData.
Note: that when “standard output” mode is enabled, this bind will be a “mock” connection handler that cannot return results and is only appropriate for a very limited subset of commands.
config
property config: OptionalConfig
Return the Config used by the current environment, if any.
configure
configure(connection: Optional[Connection] = None, url: Optional[str] = None, dialect_name: Optional[str] = None, dialect: Optional[Dialect] = None, environment_context: Optional[EnvironmentContext] = None, dialect_opts: Optional[Dict[str, str]] = None, opts: Optional[Any] = None) → MigrationContext
Create a new MigrationContext.
This is a factory method usually called by EnvironmentContext.configure().
Parameters:
- connection – a Connection to use for SQL execution in “online” mode. When present, is also used to determine the type of dialect in use.
- url – a string database url, or a sqlalchemy.engine.url.URL object. The type of dialect to be used will be derived from this if
connectionis not passed. - dialect_name – string name of a dialect, such as “postgresql”, “mssql”, etc. The type of dialect to be used will be derived from this if
connectionandurlare not passed. - opts – dictionary of options. Most other options accepted by EnvironmentContext.configure() are passed via this dictionary.
execute
execute(sql: str, execution_options: None = None) → None
Execute a SQL construct or string statement.
The underlying execution mechanics are used, that is if this is “offline mode” the SQL is written to the output buffer, otherwise the SQL is emitted on the current SQLAlchemy connection.
get_current_heads
get_current_heads() → Tuple[str, ...]
Return a tuple of the current ‘head versions’ that are represented in the target database.
For a migration stream without branches, this will be a single value, synonymous with that of MigrationContext.get_current_revision(). However when multiple unmerged branches exist within the target database, the returned tuple will contain a value for each head.
If this MigrationContext was configured in “offline” mode, that is with as_sql=True, the starting_rev parameter is returned in a one-length tuple.
If no version table is present, or if there are no revisions present, an empty tuple is returned.
get_current_revision
get_current_revision() → Optional[str]
Return the current revision, usually that which is present in the alembic_version table in the database.
This method intends to be used only for a migration stream that does not contain unmerged branches in the target database; if there are multiple branches present, an exception is raised. The MigrationContext.get_current_heads() should be preferred over this method going forward in order to be compatible with branch migration support.
If this MigrationContext was configured in “offline” mode, that is with as_sql=True, the starting_rev parameter is returned instead, if any.
run_migrations
run_migrations(**kw) → None
Run the migration scripts established for this MigrationContext, if any.
The commands in alembic.command will set up a function that is ultimately passed to the MigrationContext as the fn argument. This function represents the “work” that will be done when MigrationContext.run_migrations() is called, typically from within the env.py script of the migration environment. The “work function” then provides an iterable of version callables and other version information which in the case of the upgrade or downgrade commands are the list of version scripts to invoke. Other commands yield nothing, in the case that a command wants to run some other operation against the database such as the current or stamp commands.
Parameters:
- **kw – keyword arguments here will be passed to each migration callable, that is the
upgrade()ordowngrade()method within revision scripts.
stamp
stamp(script_directory: ScriptDirectory, revision: str) → None
Stamp the version table with a specific revision.
This method calculates those branches to which the given revision can apply, and updates those branches as though they were migrated towards that revision (either up or down). If no current branches include the revision, it is added as a new branch head.
Configuration
Note: this section discusses the internal API of Alembic as regards internal configuration constructs. This section is only useful for developers who wish to extend the capabilities of Alembic. For documentation on configuration of an Alembic environment, please see Tutorial.
The Config object represents the configuration passed to the Alembic environment. From an API usage perspective, it is needed for the following use cases:
- to create a ScriptDirectory, which allows you to work with the actual script files in a migration environment
- to create an EnvironmentContext, which allows you to actually run the
env.pymodule within the migration environment - to programmatically run any of the commands in the Commands module.
The Config is not needed for these cases:
- to instantiate a MigrationContext directly - this object only needs a SQLAlchemy connection or dialect name.
- to instantiate a Operations object - this object only needs a MigrationContext.
Config(file_: Optional[str] = None, ini_section: str = 'alembic', output_buffer: Optional[TextIO] = None, stdout: TextIO = <_io.TextIOWrapper name='
Represent an Alembic configuration.
Within an env.py script, this is available via the EnvironmentContext.config attribute, which in turn is available at alembic.context:
from alembic import context
some_param = context.config.get_main_option("my option")
When invoking Alembic programatically, a new Config can be created by passing the name of an .ini file to the constructor:
from alembic.config import Config
alembic_cfg = Config("/path/to/yourapp/alembic.ini")
With a Config object, you can then run Alembic commands programmatically using the directives in alembic.command.
The Config object can also be constructed without a filename. Values can be set programmatically, and new sections will be created as needed:
from alembic.config import Config
alembic_cfg = Config()
alembic_cfg.set_main_option("script_location", "myapp:migrations")
alembic_cfg.set_main_option("sqlalchemy.url", "postgresql://foo/bar")
alembic_cfg.set_section_option("mysection", "foo", "bar")
Warning: When using programmatic configuration, make sure the
env.pyfile in use is compatible with the target configuration; including that the call to Pythonlogging.fileConfig()is omitted if the programmatic configuration doesn’t actually include logging directives.
For passing non-string values to environments, such as connections and engines, use the Config.attributes dictionary:
with engine.begin() as connection:
alembic_cfg.attributes['connection'] = connection
command.upgrade(alembic_cfg, "head")
Parameters:
- file_ – name of the .ini file to open.
- ini_section – name of the main Alembic section within the .ini file
- output_buffer – optional file-like input buffer which will be passed to the MigrationContext - used to redirect the output of “offline generation” when using Alembic programmatically.
- stdout – buffer where the “print” output of commands will be sent. Defaults to
sys.stdout. - config_args – A dictionary of keys and values that will be used for substitution in the alembic config file. The dictionary as given is copied to a new one, stored locally as the attribute
.config_args. When the Config.file_config attribute is first invoked, the replacement variableherewill be added to this dictionary before the dictionary is passed toConfigParser()to parse the .ini file. - attributes – optional dictionary of arbitrary Python keys/values, which will be populated into the Config.attributes dictionary.
See also:
Construct a new Config
attributes
attributes
A Python dictionary for storage of additional state.
This is a utility dictionary which can include not just strings but engines, connections, schema objects, or anything else. Use this to pass objects into an env.py script, such as passing a sqlalchemy.engine.base.Connection when calling commands from alembic.command programmatically.
See also: Sharing a Connection with a Series of Migration Commands and Environments
cmd_opts
cmd_opts
The command-line options passed to the alembic script.
Within an env.py script this can be accessed via the EnvironmentContext.config attribute.
See also:
config_file_name
config_file_name
Filesystem path to the .ini file in use.
config_ini_section
config_ini_section
Name of the config file section to read basic configuration from. Defaults to alembic, that is the [alembic] section of the .ini file. This value is modified using the -n/--name option to the Alembic runner.
file_config
file_config
Return the underlying ConfigParser object.
Direct access to the .ini file is available here, though the Config.get_section() and Config.get_main_option() methods provide a possibly simpler interface.
get_main_option
get_main_option(name: str, default: str) → str
get_main_option(name: str, default: Optional[str] = None) → Optional[str]
Return an option from the ‘main’ section of the .ini file.
This defaults to being a key from the [alembic] section, unless the -n/--name flag were used to indicate a different section.
get_section
get_section get_section(name: str, default: Dict[str, str]) → Dict[str, str]
get_section get_section(name: str, default: Optional[Dict[str, str]] = None) → Optional[Dict[str, str]]
Return all the configuration options from a given .ini file section as a dictionary.
get_section_option
get_section_option(section: str, name: str, default: Optional[str] = None) → Optional[str]
Return an option from the given section of the .ini file.
get_template_directory
get_template_directory() → str
Return the directory where Alembic setup templates are found.
This method is used by the alembic init and list_templates commands.
print_stdout
print_stdout(text: str, *arg) → None
Render a message to standard out.
When Config.print_stdout() is called with additional args those arguments will formatted against the provided text, otherwise we simply output the provided text verbatim.
e.g.:
>>> config.print_stdout('Some text %s', 'arg')
Some Text arg
set_main_option
set_main_option(name: str, value: str) → None
Set an option programmatically within the ‘main’ section.
This overrides whatever was in the .ini file.
Parameters:
- name – name of the value
- value – the value. Note that this value is passed to
ConfigParser.set, which supports variable interpolation using pyformat (e.g. %(some_value)s). A raw percent sign not part of an interpolation symbol must therefore be escaped, e.g.%%. The given value may refer to another value already in the file using the interpolation format.
set_section_option
set_section_option(section: str, name: str, value: str) → None
Set an option programmatically within the given section.
The section is created if it doesn’t exist already. The value here will override whatever was in the .ini file.
Parameters:
- section – name of the section
- name – name of the value
- value – the value. Note that this value is passed to
ConfigParser.set, which supports variable interpolation using pyformat (e.g. %(some_value)s). A raw percent sign not part of an interpolation symbol must therefore be escaped, e.g.%%. The given value may refer to another value already in the file using the interpolation format.
main
alembic.config.main(argv=None, prog=None, **kwargs)
The console runner function for Alembic.
Commands
Note: this section discusses the internal API of Alembic as regards its command invocation system. This section is only useful for developers who wish to extend the capabilities of Alembic. For documentation on using Alembic commands, please see Tutorial.
注意:本节讨论 Alembic的内部API 关于其命令调用系统。 本节仅对希望扩展 Alembic 功能的开发人员有用。 有关使用 Alembic 命令的文档,请参阅 教程.
Alembic commands are all represented by functions in the Commands package. They all accept the same style of usage, being sent the Config object as the first argument.
Alembic 命令全部由 Commands 包中的函数表示。 它们都接受相同的使用方式,将 Config 对象作为第一个参数发送。
Commands can be run programmatically, by first constructing a Config object, as in:
命令可以通过首先构造一个 Config 对象以编程方式运行,如下所示:
from alembic.config import Config
from alembic import command
alembic_cfg = Config("/path/to/yourapp/alembic.ini")
command.upgrade(alembic_cfg, "head")
In many cases, and perhaps more often than not, an application will wish to call upon a series of Alembic commands and/or other features. It is usually a good idea to link multiple commands along a single connection and transaction, if feasible. This can be achieved using the Config.attributes dictionary in order to share a connection:
在许多情况下,也许更多时候,应用程序会希望调用一系列 Alembic 的命令以及其他功能。 如果可行,沿单个连接和事务并链接多个命令通常是一个好主意。 这可以使用 Config.attributes 字典来实现,以便共享连接:
with engine.begin() as connection:
alembic_cfg.attributes['connection'] = connection
command.upgrade(alembic_cfg, "head")
This recipe requires that env.py consumes this connection argument; see the example in Sharing a Connection with a Series of Migration Commands and Environments for details.
这个示例片段要求
env.py使用这个connection参数; 有关详细信息,请参阅与一系列迁移命令和环境共享连接中的示例。
To write small API functions that make direct use of database and script directory information, rather than just running one of the built-in commands, use the ScriptDirectory and MigrationContext classes directly.
要编写直接使用数据库和脚本目录信息的小型 API 函数,而不仅仅是运行内置命令之一,请直接使用 ScriptDirectory 和 MigrationContext 类。
branches
alembic.command.branches(config, verbose=False)
Show current branch points.
显示当前分支点。
Parameters:
- config – a Config instance.
- verbose – output in verbose mode.
参数:
- config – 一个 Config 实例.
- verbose – 以 详细 模式输出。
current
alembic.command.current(config: Config, verbose: bool = False) → None
Display the current revision for a database.
显示数据库的当前版本。
Parameters:
- config – a Config instance.
- verbose – output in verbose mode.
参数:
- config – 一个 Config 实例.
- verbose – 以 详细 模式输出。
downgrade
alembic.command.downgrade(config: Config, revision: str, sql: bool = False, tag: Optional[str] = None) → None
Revert to a previous version.
恢复到以前的版本。
Parameters:
- config – a Config instance.
- revision – string revision target or range for –sql mode
- sql – if True, use
--sqlmode - tag – an arbitrary “tag” that can be intercepted by custom
env.pyscripts via the EnvironmentContext.get_tag_argument() method.
参数:
- config – 一个 Config 实例.
- revision –
–sql模式的字符串 修订 目标或范围- sql – 如果为
True, 使用--sql模式- tag – 一个可以通过定义
env.py脚本的 EnvironmentContext.get_tag_argument() 方法 获取的任意”标签“=
edit
alembic.command.edit(config: Config, rev: str) → None
Edit revision script(s) using $EDITOR.
使用 $EDITOR 编辑修订脚本。
Parameters:
- config – a Config instance.
- rev – target revision.
参数:
- config – 一个 Config 实例.
- rev – 目标修订.
ensure_version
alembic.command.ensure_version(config: Config, sql: bool = False) → None
Create the alembic version table if it doesn’t exist already .
如果 alembic 版本表不存在,则创建它。
Parameters:
-
config – a Config instance.
-
sql – use
--sqlmodeNew in version 1.7.6.
参数:
config – 一个 Config 实例.
sql – 使用
--sql模式1.7.6版本中新增
heads
alembic.command.heads(config, verbose=False, resolve_dependencies=False)
Show current available heads in the script directory.
在脚本目录中显示当前可用的head。
Parameters:
- config – a Config instance.
- verbose – output in verbose mode.
- resolve_dependencies – treat dependency version as down revisions.
参数:
- config – 一个 Config 实例.
- verbose – 以 详细 模式输出。
- resolve_dependencies – 将依赖版本视为向下修订。
history
alembic.command.history(config: Config, rev_range: Optional[str] = None, verbose: bool = False, indicate_current: bool = False) → None
List changeset scripts in chronological order.
Parameters:
- config – a Config instance.
- rev_range – string revision range
- verbose – output in verbose mode.
- indicate_current – indicate current revision.
参数:
- config – 一个 Config 实例.
- rev_range – 字符串的修订范围
- verbose – 以 详细 模式输出。
- indicate_current – 表示当前版本。
init
alembic.command.init(config: Config, directory: str, template: str = 'generic', package: bool = False) → None
Initialize a new scripts directory.
初始化一个新的脚本目录。
Parameters:
-
config – a Config object.
-
directory – string path of the target directory
-
template – string name of the migration environment template to use.
-
package – when True, write
__init__.pyfiles into the environment location as well as theversions/location.New in version 1.2.
参数:
config – 一个 Config 实例.
directory – 目标目录的字符串路径
template – 要使用的迁移环境 模板 的字符串名称。
package – 如果为
True,则将__init__.py文件写入环境位置以及 版本目录 位置。1.2.版本中新增
list_templates
alembic.command.list_templates(config)
List available templates.
列出可用模板。
Parameters:
- config – a Config object.
参数:
- config – 一个 Config 实例.
merge
alembic.command.merge(config: Config, revisions: str, message: str = None, branch_label: str = None, rev_id: str = None) → Optional[Script]
Merge two revisions together. Creates a new migration file.
将两个修订合并在一起。 创建一个新的迁移文件。
Parameters:
- config – a Config instance
- message – string message to apply to the revision
- branch_label – string label name to apply to the new revision
- rev_id – hardcoded revision identifier instead of generating a new one.
See also: Working with Branches
参数:
- config – 一个 Config 实例.
- message – 应用于修订的字符串 消息 。
- branch_label – 应用于新修订的字符串标签名称
- rev_id – 硬编码的修订标识符,而不是生成一个新的。
同样参考: 使用分支
revision
alembic.command.revision(config: Config, message: Optional[str] = None, autogenerate: bool = False, sql: bool = False, head: str = 'head', splice: bool = False, branch_label: Optional[str] = None, version_path: Optional[str] = None, rev_id: Optional[str] = None, depends_on: Optional[str] = None, process_revision_directives: Callable = None) → Union[Script, None, List[Optional[Script]]]
Create a new revision file.
创建一个新的修订文件。
Parameters:
- config – a Config object.
- message – string message to apply to the revision; this is the
-moption toalembic revision. - autogenerate – whether or not to autogenerate the script from the database; this is the
--autogenerateoption toalembic revision. - sql – whether to dump the script out as a SQL string; when specified, the script is dumped to stdout. This is the
--sqloption toalembic revision. - head – head revision to build the new revision upon as a parent; this is the
--headoption toalembic revision. - splice – whether or not the new revision should be made into a new
headof its own; is required when the givenheadis not itself ahead. This is the--spliceoption toalembic revision. - branch_label – string label to apply to the branch; this is the
--branch-labeloption toalembic revision. - version_path – string symbol identifying a specific version path from the configuration; this is the
--version-pathoption toalembic revision. - rev_id – optional revision identifier to use instead of having one generated; this is the
--rev-idoption toalembic revision. - depends_on – optional list of “depends on” identifiers; this is the
--depends-onoption toalembic revision. - process_revision_directives – this is a callable that takes the same form as the callable described at EnvironmentContext.configure.process_revision_directives; will be applied to the structure generated by the revision process where it can be altered programmatically. Note that unlike all the other parameters, this option is only available via programmatic use of command.revision()
参数:
- config – 一个 Config 实例.
- message – 应用于修订的字符串 消息 ; 这是
alembic revision命令的-m选项。- autogenerate – 是否从数据库 自动生成 脚本; 这是
alembic revision命令的--autogenerate选项。- sql – 是否将脚本作为 SQL 字符串转储; 指定时,脚本被转储到标准输出。 这是
alembic revision命令的--sql选项。- head – head 修订,以作为父版本构建新修订; 这是
alembic revision命令的--head选项。- splice – 新的修订是否应该成为的新 head; 当给定的
head本身不是head时是必需的。 这是alembic revision命令的--splice选项。- branch_label – 应用于分支的字符串标签; 这是
alembic revision命令的--branch-label选项。- version_path – 标识配置中特定版本路径的字符串符号; 这是
alembic revision命令的--version-path选项。- rev_id – 要使用的可选修订标识符,而不是生成一个; 这是
alembic revision命令的--rev-id选项。- depends_on – “依赖于xxx”标识符的可选列表; 这是
alembic revision命令的--depends-on选项。- process_revision_directives – 这是一个可调用对象,其形式与 EnvironmentContext.configure.process_revision_directives 中描述的可调用对象相同; 将应用于由修订过程生成的结构,可以通过编程方式对其进行更改。 请注意,与所有其他参数不同,此选项仅可通过以编程方式使用 command.revision()
show
alembic.command.show(config, rev)
Show the revision(s) denoted by the given symbol.
显示由给定符号表示的修订。
Parameters:
- config – a Config instance.
- revision – string revision target
参数:
- config – 一个 Config 实例.
- revision – 字符串的目标 修订
stamp
alembic.command.stamp(config: Config, revision: str, sql: bool = False, tag: Optional[str] = None, purge: bool = False) → None
‘stamp’ the revision table with the given revision; don’t run any migrations.
用给定的修订“标记”修订表; 不要运行任何迁移。
Parameters:
-
config – a Config instance.
-
revision – target revision or list of revisions. May be a list to indicate stamping of multiple branch heads.
Note: this parameter is called “revisions” in the command line interface.
Changed in version 1.2: The revision may be a single revision or list of revisions when stamping multiple branch heads.
-
sql – use
--sqlmode -
tag – an arbitrary “tag” that can be intercepted by custom
env.pyscripts via the [EnvironmentContext.get_tag_argument] method. -
purge – delete all entries in the version table before stamping.
New in version 1.2.
参数:
config – 一个 Config 实例.
revision – 目标修订或修订列表。 可能是一个列表,表明多个分支head的标记。
注意: 此参数在命令行界面中称为 “revisions”。
版本1.2更新: 当标记多个分支head时,修订可以是单个修订或修订列表。
sql – 使用
--sql模式tag – 一个任意"标签", 可以通过
env.py文件中的 [EnvironmentContext.get_tag_argument] 方法定义。purge – 在标记之前删除版本表中的所有条目。
版本 1.2.中新增
upgrade
alembic.command.upgrade(config: Config, revision: str, sql: bool = False, tag: Optional[str] = None) → None
Upgrade to a later version.
Parameters:
- config – a Config instance.
- revision – string revision target or range for –sql mode
- sql – if True, use
--sqlmode - tag – an arbitrary “tag” that can be intercepted by custom
env.pyscripts via the EnvironmentContext.get_tag_argument() method.
参数:
- config – 一个 Config 实例.
- revision –
–sql模式的字符串 修订 目标或范围- sql – 如果为
True, 使用--sql模式- tag – 一个任意"标签", 可以通过
env.py文件中的 [EnvironmentContext.get_tag_argument] 方法定义。
Operation Directives
Note: this section discusses the internal API of Alembic as regards the internal system of defining migration operation directives. This section is only useful for developers who wish to extend the capabilities of Alembic. For end-user guidance on Alembic migration operations, please see Operation Reference.
Within migration scripts, actual database migration operations are handled via an instance of Operations. The Operations class lists out available migration operations that are linked to a MigrationContext, which communicates instructions originated by the Operations object into SQL that is sent to a database or SQL output stream.
Most methods on the Operations class are generated dynamically using a “plugin” system, described in the next section Operation Plugins. Additionally, when Alembic migration scripts actually run, the methods on the current Operations object are proxied out to the alembic.op module, so that they are available using module-style access.
For an overview of how to use an Operations object directly in programs, as well as for reference to the standard operation methods as well as “batch” methods, see Operation Reference.
Operation Plugins
The Operations object is extensible using a plugin system. This system allows one to add new op.<some_operation> methods at runtime. The steps to use this system are to first create a subclass of MigrateOperation, register it using the Operations.register_operation() class decorator, then build a default “implementation” function which is established using the Operations.implementation_for() decorator.
Below we illustrate a very simple operation CreateSequenceOp which will implement a new method op.create_sequence() for use in migration scripts:
from alembic.operations import Operations, MigrateOperation
@Operations.register_operation("create_sequence")
class CreateSequenceOp(MigrateOperation):
"""Create a SEQUENCE."""
def __init__(self, sequence_name, schema=None):
self.sequence_name = sequence_name
self.schema = schema
@classmethod
def create_sequence(cls, operations, sequence_name, **kw):
"""Issue a "CREATE SEQUENCE" instruction."""
op = CreateSequenceOp(sequence_name, **kw)
return operations.invoke(op)
def reverse(self):
# only needed to support autogenerate
return DropSequenceOp(self.sequence_name, schema=self.schema)
@Operations.register_operation("drop_sequence")
class DropSequenceOp(MigrateOperation):
"""Drop a SEQUENCE."""
def __init__(self, sequence_name, schema=None):
self.sequence_name = sequence_name
self.schema = schema
@classmethod
def drop_sequence(cls, operations, sequence_name, **kw):
"""Issue a "DROP SEQUENCE" instruction."""
op = DropSequenceOp(sequence_name, **kw)
return operations.invoke(op)
def reverse(self):
# only needed to support autogenerate
return CreateSequenceOp(self.sequence_name, schema=self.schema)
Above, the CreateSequenceOp and DropSequenceOp classes represent new operations that will be available as op.create_sequence() and op.drop_sequence(). The reason the operations are represented as stateful classes is so that an operation and a specific set of arguments can be represented generically; the state can then correspond to different kinds of operations, such as invoking the instruction against a database, or autogenerating Python code for the operation into a script.
In order to establish the migrate-script behavior of the new operations, we use the Operations.implementation_for() decorator:
@Operations.implementation_for(CreateSequenceOp)
def create_sequence(operations, operation):
if operation.schema is not None:
name = "%s.%s" % (operation.schema, operation.sequence_name)
else:
name = operation.sequence_name
operations.execute("CREATE SEQUENCE %s" % name)
@Operations.implementation_for(DropSequenceOp)
def drop_sequence(operations, operation):
if operation.schema is not None:
name = "%s.%s" % (operation.schema, operation.sequence_name)
else:
name = operation.sequence_name
operations.execute("DROP SEQUENCE %s" % name)
Above, we use the simplest possible technique of invoking our DDL, which is just to call Operations.execute() with literal SQL. If this is all a custom operation needs, then this is fine. However, options for more comprehensive support include building out a custom SQL construct, as documented at Custom SQL Constructs and Compilation Extension.
With the above two steps, a migration script can now use new methods op.create_sequence() and op.drop_sequence() that will proxy to our object as a classmethod:
def upgrade():
op.create_sequence("my_sequence")
def downgrade():
op.drop_sequence("my_sequence")
The registration of new operations only needs to occur in time for the env.py script to invoke MigrationContext.run_migrations(); within the module level of the env.py script is sufficient.
See also:
Autogenerating Custom Operation Directives - how to add autogenerate support to custom operations.
Built-in Operation Objects
The migration operations present on Operations are themselves delivered via operation objects that represent an operation and its arguments. All operations descend from the MigrateOperation class, and are registered with the Operations class using the Operations.register_operation() class decorator. The MigrateOperation objects also serve as the basis for how the autogenerate system renders new migration scripts.
See also:
The built-in operation objects are listed below.
-
class alembic.operations.ops.AddColumnOp(table_name: str, column: Column, schema: Optional[str] = None, **kw) → Optional[Table] Optional[Table]
Represent an add column operation.
-
classmethod add_column(operations: Operations, table_name: str, column: Column, schema: Optional[str] = None) → Optional[Table]
This method is proxied on the Operations class, via the Operations.add_column() method.
-
classmethod batch_add_column(operations: BatchOperations, column: Column, insert_before: Optional[str] = None, insert_after: Optional[str] = None) → Optional[Table]
This method is proxied on the BatchOperations class, via the BatchOperations.add_column() method.
-
-
class alembic.operations.ops.AddConstraintOp
Represent an add constraint operation.
-
class alembic.operations.ops.AlterColumnOp(table_name: str, column_name: str, schema: Optional[str] = None, existing_type: Optional[Any] = None, existing_server_default: Any = False, existing_nullable: Optional[bool] = None, existing_comment: Optional[str] = None, modify_nullable: Optional[bool] = None, modify_comment: Optional[Union[str, bool]] = False, modify_server_default: Any = False, modify_name: Optional[str] = None, modify_type: Optional[Any] = None, **kw)
Represent an alter column operation.
-
class alembic.operations.ops.alter_column batch_alter_column(operations: alembic.operations.base.Operations, table_name: str, column_name: str, nullable: Optional[bool] = None, comment: Optional[Union[str, bool]] = False, server_default: Any = False, new_column_name: Optional[str] = None, type_: Optional[Union[TypeEngine, Type[TypeEngine]]] = None, existing_type: Optional[Union[TypeEngine, Type[TypeEngine]]] = None, existing_server_default: Optional[Union[str, bool, Identity, Computed]] = False, existing_nullable: Optional[bool] = None, existing_comment: Optional[str] = None, schema: Optional[str] = None,**kw) → Optional[Table]
This method is proxied on the Operations class, via the Operations.alter_column() method.
-
class alembic.operations.ops.batch_alter_column( operations: alembic.operations.base.BatchOperations, column_name: str, nullable: Optional[bool] = None, comment: bool = False, server_default: Union[Function, bool] = False, new_column_name: Optional[str] = None, type_: Optional[Union[TypeEngine, Type[TypeEngine]]] = None, existing_type: Optional[Union[TypeEngine, Type[TypeEngine]]] = None, existing_server_default: bool = False, existing_nullable: None = None, existing_comment: None = None, insert_before: None = None, insert_after: None = None,**kw) → Optional[Table]
This method is proxied on the BatchOperations class, via the BatchOperations.alter_column() method.
-
-
class alembic.operations.ops.AlterTableOp(table_name: str, schema: Optional[str] = None)
Represent an alter table operation.
-
class alembic.operations.ops.BulkInsertOp(table: Union[Table, TableClause], rows: List[dict], multiinsert: bool = True) → None
Represent a bulk insert operation.
-
classmethod bulk_insert(operations: alembic.operations.base.Operations, table: Union[Table, TableClause], rows: List[dict], multiinsert: bool = True) → None
This method is proxied on the Operations class, via the Operations.bulk_insert() method.
-
-
class alembic.operations.ops.CreateCheckConstraintOp(constraint_name: Optional[str], table_name: str, condition: Union[str, TextClause, ColumnElement[Any]], schema: Optional[str] = None, **kw)
Represent a create check constraint operation.
-
classmethod batch_create_check_constraint(operations: BatchOperations, constraint_name: str, condition: TextClause, **kw) → None
This method is proxied on the BatchOperations class, via the BatchOperations.create_check_constraint() method.
-
classmethod create_check_constraint(operations: Operations, constraint_name: Optional[str], table_name: str, condition: Union[str, BinaryExpression], schema: Optional[str] = None, **kw) → None
This method is proxied on the Operations class, via the Operations.create_check_constraint() method.
-
-
class alembic.operations.ops.CreateForeignKeyOp(constraint_name: Optional[str], source_table: str, referent_table: str, local_cols: List[str], remote_cols: List[str], **kw)
Represent a create foreign key constraint operation.
-
class batch_create_foreign_key(operations: alembic.operations.base.BatchOperations, constraint_name: str, referent_table: str, local_cols: List[str], remote_cols: List[str], referent_schema: Optional[str] = None, onupdate: None = None, ondelete: None = None, deferrable: None = None, initially: None = None, match: None = None,**dialect_kw) → None Optional[Table]
This method is proxied on the BatchOperations class, via the BatchOperations.create_foreign_key() method.
-
class create_foreign_key(operations: Operations, constraint_name: Optional[str],source_table: str, referent_table: str,local_cols: List[str], remote_cols: List[str],onupdate: Optional[str] = None,ondelete: Optional[str] = None,deferrable: Optional[bool] = None,initially: Optional[str] = None,match: Optional[str] = None,source_schema: Optional[str] = None, referent_schema: Optional[str] = None, **dialect_kw) → None Optional[Table]
This method is proxied on the Operations class, via the Operations.create_foreign_key() method.
-
-
class alembic.operations.ops.CreateIndexOp batch_create_index create_index(index_name: str, table_name: str, columns: Sequence[Union[str, TextClause, ColumnElement[Any]]], schema: Optional[str] = None, unique: bool = False, **kw) Represent a create index operation.
-
classmethod CreateIndexOp(kw, operations: BatchOperations, index_name: str, columns: List[str], **kw, ) → Optional[Table]
This method is proxied on the BatchOperations class, via the BatchOperations.create_index() method.
-
classmethod create_index(operations: alembic.operations.base.Operations, index_name: str, table_name: str, columns: Sequence[Union[str, TextClause, Function]], schema: Optional[str] = None, unique: bool = False, **kw) → Optional[Table]
This method is proxied on the Operations class, via the Operations.create_index() method.
-
-
class alembic.operations.ops.CreatePrimaryKeyOp(constraint_name: Optional[str], table_name: str, columns: Sequence[str], schema: Optional[str] = None, **kw)
Represent a create primary key operation.
-
classmethod batch_create_primary_key(operations: alembic.operations.base.BatchOperations, constraint_name: str,columns: List[str],) → None
This method is proxied on the BatchOperations class, via the BatchOperations.create_primary_key() method.
-
classmethod create_primary_key(operations: Operations,constraint_name: Optional[str], table_name: str,columns: List[str],schema: Optional[str] = None) → Optional[Table]
This method is proxied on the Operations class, via the Operations.create_primary_key() method.
-
-
class alembic.operations.ops.CreateTableCommentOp(table_name: str, comment: Optional[str], schema: Optional[str] = None, existing_comment: Optional[str] = None, operations, comment, existing_comment=None)
Represent a COMMENT ON table operation.
-
classmethod batch_create_table_comment(operations, comment, existing_comment=None)
This method is proxied on the BatchOperations class, via the BatchOperations.create_table_comment() method.
-
classmethod create_table_comment(operations: Operations, table_name: str,comment: Optional[str],existing_comment: None = None, schema: Optional[str] = None) → Optional[Table]
This method is proxied on the Operations class, via the Operations.create_table_comment() method.
-
reverse()
Reverses the COMMENT ON operation against a table.
-
-
class alembic.operations.ops.CreateTableOp(table_name: str, columns: Sequence[Union[Column, Constraint]], schema: Optional[str] = None, _namespace_metadata: Optional[MetaData] = None, _constraints_included: bool = False, **kw)
Represent a create table operation.
-
classmethod create_table(operations: Operations,table_name: str, *columns, **kw) → Optional[Table]
This method is proxied on the Operations class, via the Operations.create_table() method.
-
-
class alembic.operations.ops.CreateUniqueConstraintOp(constraint_name: Optional[str], table_name: str, columns: Sequence[str], schema: Optional[str] = None, **kw)
Represent a create unique constraint operation.
-
classmethod batch_create_unique_constraint(operations: alembic.operations.base.BatchOperations, constraint_name: str,columns: Sequence[str], **kw) → Any
This method is proxied on the BatchOperations class, via the BatchOperations.create_unique_constraint() method.
-
classmethod create_unique_constraint(operations: alembic.operations.base.Operations, constraint_name: Optional[str], table_name: str, columns: Sequence[str], schema: Optional[str] = None,**kw) → Any
This method is proxied on the Operations class, via the Operations.create_unique_constraint() method.
-
-
class alembic.operations.ops.DowngradeOps(ops: Sequence[[alembic.operations.ops.MigrateOperation]] = (), downgrade_token: str = 'downgrades')
contains a sequence of operations that would apply to the ‘downgrade’ stream of a script.
See also: Customizing Revision Generation
class alembic.operations.ops.DropColumnOp batch_drop_column drop_column(table_name: str, column_name: str, schema: Optional[str] = None, _reverse: Optional[[alembic.operations.ops.AddColumnOp]] = None, **kw)
Represent a drop column operation.
- classmethod batch_drop_column(operations: BatchOperations, column_name: str, **kw) → Optional[Table]
This method is proxied on the BatchOperations class, via the BatchOperations.drop_column() method.
- classmethod drop_column(operations: Operations, table_name: str, column_name: str, schema: Optional[str] = None, **kw) → Optional[Table]
This method is proxied on the Operations class, via the Operations.drop_column() method.
-
class alembic.operations.ops.DropConstraintOp(constraint_name: Optional[str], table_name: str, type_: Optional[str] = None, schema: Optional[str] = None, _reverse: Optional[[alembic.operations.ops.AddConstraintOp]] = None)
Represent a drop constraint operation.
-
classmethod batch_drop_constraint drop_constraint(operations: alembic.operations.base.BatchOperations, constraint_name: str, type_: Optional[str] = None) → None
This method is proxied on the BatchOperations class, via the BatchOperations.drop_constraint() method.
-
classmethod batch_drop_constraint drop_constraint(operations: Operations, constraint_name: str, table_name: str, type_: Optional[str] = None, schema: Optional[str] = None) → Optional[Table]
This method is proxied on the Operations class, via the Operations.drop_constraint() method.
-
-
class alembic.operations.ops.DropIndexOp(index_name: Union[quoted_name, str, conv], table_name: Optional[str] = None, schema: Optional[str] = None, _reverse: Optional[[CreateIndexOp]] = None, **kw)
Represent a drop index operation.
-
classmethod batch_drop_index(operations: alembic.operations.base.BatchOperations, index_name: str, **kw) → Optional[Table]
This method is proxied on the BatchOperations class, via the BatchOperations.drop_index() method.
-
classmethod drop_index(operations: Operations, index_name: str, table_name: Optional[str] = None, schema: Optional[str] = None,**kw) → Optional[Table]
This method is proxied on the Operations class, via the Operations.drop_index() method.
-
-
class alembic.operations.ops.DropTableCommentOp batch_drop_table_comment drop_table_comment reverse(table_name: str, schema: Optional[str] = None, existing_comment: Optional[str] = None)
Represent an operation to remove the comment from a table.
-
classmethod batch_drop_table_comment(operations, existing_comment=None)
This method is proxied on the BatchOperations class, via the BatchOperations.drop_table_comment() method.
-
classmethod drop_table_comment(operations: Operations, table_name: str,existing_comment: Optional[str] = None, schema: Optional[str] = None) → Optional[Table]
This method is proxied on the Operations class, via the Operations.drop_table_comment() method.
-
reverse()
Reverses the COMMENT ON operation against a table.
-
-
class alembic.operations.ops.DropTableOp drop_table(table_name: str, schema: Optional[str] = None, table_kw: Optional[MutableMapping[Any, Any]] = None, _reverse: Optional[[alembic.operations.ops.CreateTableOp]] = None) → None
Represent a drop table operation.
-
classmethod drop_table(operations: alembic.operations.base.Operations, table_name: str,schema: Optional[str] = None, **kw: Any) → None
This method is proxied on the Operations class, via the Operations.drop_table() method.
-
class alembic.operations.ops.ExecuteSQLOp execute(sqltext: Union[Update, str, Insert, TextClause], execution_options: None = None)
Represent an execute SQL operation.
-
execute(operations: alembic.operations.base.Operations, sqltext: Union[str, TextClause, Update], execution_options: None = None) → Optional[Table]
This method is proxied on the Operations class, via the Operations.execute() method.
-
-
class alembic.operations.ops.MigrateOperation
base class for migration command and organization objects.
This system is part of the operation extensibility API.
See also: Built-in Operation Objects
-
info
A dictionary that may be used to store arbitrary information along with this MigrateOperation object.
-
-
class alembic.operations.ops.MigrationScript(rev_id: Optional[str], upgrade_ops: [alembic.operations.ops.UpgradeOps], downgrade_ops: [alembic.operations.ops.DowngradeOps], message: Optional[str] = None, imports: Set[str] = {}, head: Optional[str] = None, splice: Optional[bool] = None, branch_label: Optional[str] = None, version_path: Optional[str] = None, depends_on: Optional[Union[str, Sequence[str]]] = None)
represents a migration script.
E.g. when autogenerate encounters this object, this corresponds to the production of an actual script file.
A normal MigrationScript object would contain a single UpgradeOps and a single DowngradeOps directive. These are accessible via the
.upgrade_opsand.downgrade_opsattributes.In the case of an autogenerate operation that runs multiple times, such as the multiple database example in the “multidb” template, the
.upgrade_opsand.downgrade_opsattributes are disabled, and instead these objects should be accessed via the.upgrade_ops_listand.downgrade_ops_listlist-based attributes. These latter attributes are always available at the very least as single-element lists.See also: Customizing Revision Generation
-
property downgrade_ops
An instance of DowngradeOps.
See also: MigrationScript.downgrade_ops_list
-
property downgrade_ops_list: List[[alembic.operations.ops.DowngradeOps]]
A list of DowngradeOps instances.
This is used in place of the MigrationScript.downgrade_ops attribute when dealing with a revision operation that does multiple autogenerate passes.
-
property upgrade_ops
An instance of UpgradeOps.
See also: MigrationScript.upgrade_ops_list
-
property upgrade_ops_list
A list of UpgradeOps instances.
This is used in place of the MigrationScript.upgrade_ops attribute when dealing with a revision operation that does multiple autogenerate passes.
-
-
class alembic.operations.ops.ModifyTableOps(table_name: str, ops: Sequence[[alembic.operations.ops.MigrateOperation]], schema: Optional[str] = None)
Contains a sequence of operations that all apply to a single Table.
-
class alembic.operations.ops.OpContainer(ops: Sequence[[alembic.operations.ops.MigrateOperation]] = ())
Represent a sequence of operations operation.
-
class alembic.operations.ops.RenameTableOp rename_table(old_table_name: str, new_table_name: str, schema: Optional[str] = None)
Represent a rename table operation.
-
rename_table(operations: Operations, old_table_name: str, new_table_name: str, schema: Optional[str] = None) → Optional[Table]
This method is proxied on the Operations class, via the Operations.rename_table() method.
-
-
class alembic.operations.ops.UpgradeOps(ops: Sequence[[alembic.operations.ops.MigrateOperation]] = (), upgrade_token: str = 'upgrades')
contains a sequence of operations that would apply to the ‘upgrade’ stream of a script.
See also: Customizing Revision Generation
Autogeneration
Note: this section discusses the internal API of Alembic as regards the autogeneration feature of the
alembic revisioncommand. This section is only useful for developers who wish to extend the capabilities of Alembic. For general documentation on the autogenerate feature, please see Auto Generating Migrations.
The autogeneration system has a wide degree of public API, including the following areas:
- The ability to do a “diff” of a MetaData object against a database, and receive a data structure back. This structure is available either as a rudimentary list of changes, or as a MigrateOperation structure.
- The ability to alter how the
alembic revisioncommand generates revision scripts, including support for multiple revision scripts generated in one pass. - The ability to add new operation directives to autogeneration, including custom schema/model comparison functions and revision script rendering.
注意: 本节讨论 Alembic 的内部 API 关于 alembic 修订命令的自动生成功能。 本节仅对希望扩展 Alembic 功能的开发人员有用。 有关自动生成功能的一般文档,请参阅自动生成迁移。
自动生成系统具有广泛的公共API,包括以下领域:
- 能够根据数据库对 MetaData 对象进行“比较”,并接收返回的数据结构。 此结构可用作基本更改列表或 MigrateOperation 结构。
- 更改
alembic revision命令生成修订脚本的方式的能力,包括支持一次生成的多个修订脚本。 - 向自动生成添加新操作指令的能力,包括自定义模式/模型比较功能和修订脚本渲染。
Getting Diffs
The simplest API autogenerate provides is the “schema comparison” API; these are simple functions that will run all registered “comparison” functions between a MetaData object and a database backend to produce a structure showing how they differ. The two functions provided are compare_metadata(), which is more of the “legacy” function that produces diff tuples, and produce_migrations(), which produces a structure consisting of operation directives detailed in Operation Directives.
自动生成提供的最简单的 API 是“模式比较”API; 这些是简单的函数,它们将在 MetaData 对象和数据库后端之间运行所有已注册的“比较”函数,以生成显示它们之间差异的结构。 提供的两个函数是 compare_metadata(),它更像是产生差异元组的“遗留”函数,以及产生由 操作指令 中详述的操作指令组成的结构的 produce_migrations()。
-
class alembic.autogenerate.compare_metadata(context: MigrationContext, metadata: MetaData) → Any
Compare a database schema to that given in a MetaData instance.
将 数据库schema 与 MetaData 实例中给出的 schema 进行比较。
The database connection is presented in the context of a MigrationContext object, which provides database connectivity as well as optional comparison functions to use for datatypes and server defaults - see the “autogenerate” arguments at EnvironmentContext.configure() for details on these.
数据库连接在 MigrationContext 对象的上下文中呈现,该对象提供数据库连接以及用于数据类型和服务器默认值的可选比较函数 - 有关这些详细信息,请参阅 EnvironmentContext.configure() 中的 “autogenerate” 参数。
The return format is a list of “diff” directives, each representing individual differences:
返回格式是 “diff” 指令列表,每个指令代表个体差异:
from alembic.migration import MigrationContext from alembic.autogenerate import compare_metadata from sqlalchemy.schema import SchemaItem from sqlalchemy.types import TypeEngine from sqlalchemy import (create_engine, MetaData, Column, Integer, String, Table, text) import pprint engine = create_engine("sqlite://") with engine.begin() as conn: conn.execute(text(''' create table foo ( id integer not null primary key, old_data varchar, x integer )''')) conn.execute(text(''' create table bar ( data varchar )''')) metadata = MetaData() Table('foo', metadata, Column('id', Integer, primary_key=True), Column('data', Integer), Column('x', Integer, nullable=False) ) Table('bat', metadata, Column('info', String) ) mc = MigrationContext.configure(engine.connect()) diff = compare_metadata(mc, metadata) pprint.pprint(diff, indent=2, width=20)Output:
[ ( 'add_table', Table('bat', MetaData(bind=None), Column('info', String(), table=<bat>), schema=None)), ( 'remove_table', Table(u'bar', MetaData(bind=None), Column(u'data', VARCHAR(), table=<bar>), schema=None)), ( 'add_column', None, 'foo', Column('data', Integer(), table=<foo>)), ( 'remove_column', None, 'foo', Column(u'old_data', VARCHAR(), table=None)), [ ( 'modify_nullable', None, 'foo', u'x', { 'existing_server_default': None, 'existing_type': INTEGER()}, True, False)]]Parameters:
-
context – 一个 MigrationContext 实例.
-
metadata – 一个 MetaData 实例.
同样参考: produce_migrations() - 生成基于 metadata (元数据) 比较的 MigrationScript 结构。
-
-
class alembic.autogenerate.produce_migrations(context: MigrationContext, metadata: MetaData) → MigrationScript
根据 schema 比较生成 MigrationScript 的结构。
这个函数本质上是 compare_metadata() 所做的,但随后会运行结果列表来生成完整的 MigrationScript 对象。 有关其外观的示例,请参阅自定义修订生成中的示例。
同样参考: compare_metadata() - 通过比较
schema返回更基本的 “diff” 数据。
Customizing Revision Generation
自定义修订生成
alembic revision 命令,也可以通过 command.revision() 以编程方式使用,在运行后本质上会生成一个迁移脚本。 是否指定了 --autogenerate 选项基本上决定了该脚本是具有空的 upgrade() 和 downgrade() 函数的空白修订脚本,还是使用 alembic 操作指令作为自动生成的结果生成的。
在任何一种情况下,系统都会以 MigrateOperation 结构的形式创建一个完整的计划,然后用于生成脚本。
例如,假设我们运行了alembic revision --autogenerate,最终结果是它生成了一个新的修订版'eced083f5df',其内容如下:
"""create the organization table."""
# revision identifiers, used by Alembic.
revision = 'eced083f5df'
down_revision = 'beafc7d709f'
from alembic import op
import sqlalchemy as sa
def upgrade():
op.create_table(
'organization',
sa.Column('id', sa.Integer(), primary_key=True),
sa.Column('name', sa.String(50), nullable=False)
)
op.add_column(
'user',
sa.Column('organization_id', sa.Integer())
)
op.create_foreign_key(
'org_fk', 'user', 'organization', ['organization_id'], ['id']
)
def downgrade():
op.drop_constraint('org_fk', 'user')
op.drop_column('user', 'organization_id')
op.drop_table('organization')
上面的脚本由一个 MigrateOperation 结构生成,如下所示:
from alembic.operations import ops
import sqlalchemy as sa
migration_script = ops.MigrationScript(
'eced083f5df',
ops.UpgradeOps(
ops=[
ops.CreateTableOp(
'organization',
[
sa.Column('id', sa.Integer(), primary_key=True),
sa.Column('name', sa.String(50), nullable=False)
]
),
ops.ModifyTableOps(
'user',
ops=[
ops.AddColumnOp(
'user',
sa.Column('organization_id', sa.Integer())
),
ops.CreateForeignKeyOp(
'org_fk', 'user', 'organization',
['organization_id'], ['id']
)
]
)
]
),
ops.DowngradeOps(
ops=[
ops.ModifyTableOps(
'user',
ops=[
ops.DropConstraintOp('org_fk', 'user'),
ops.DropColumnOp('user', 'organization_id')
]
),
ops.DropTableOp('organization')
]
),
message='create the organization table.'
)
当我们处理 MigrationScript 结构时,我们可以使用 render_python_code() 辅助函数将 upgrade/downgrade 部分渲染为字符串以进行调试:
from alembic.autogenerate import render_python_code
print(render_python_code(migration_script.upgrade_ops))
渲染为:
### commands auto generated by Alembic - please adjust! ###
op.create_table('organization',
sa.Column('id', sa.Integer(), nullable=False),
sa.Column('name', sa.String(length=50), nullable=False),
sa.PrimaryKeyConstraint('id')
)
op.add_column('user', sa.Column('organization_id', sa.Integer(), nullable=True))
op.create_foreign_key('org_fk', 'user', 'organization', ['organization_id'], ['id'])
### end Alembic commands ###
鉴于上述结构用于生成新的修订文件,并且我们希望能够在创建这些文件时对其进行更改,因此我们需要一个系统来访问此结构,当 [command.revision()] 命令被使用时, [EnvironmentContext.configure.process_revision_directives] 参数为我们提供了一种改变它的方法。 这是一个通过 Alembic 生成的上述结构传递的函数,让我们有机会改变它。 例如,如果我们想将所有 “upgrade” 操作放到某个分支中,并且我们希望我们的脚本根本没有任何 “downgrade” 操作,我们可以构建一个扩展,如下所示,在 env.py脚本:
def process_revision_directives(context, revision, directives):
script = directives[0]
# set specific branch
script.head = "mybranch@head"
# erase downgrade operations
script.downgrade_ops.ops[:] = []
# ...
def run_migrations_online():
# ...
with engine.connect() as connection:
context.configure(
connection=connection,
target_metadata=target_metadata,
process_revision_directives=process_revision_directives)
with context.begin_transaction():
context.run_migrations()
上面,directives 参数是一个 Python 列表。 我们可以就地更改此列表中的给定结构,或将其替换为由零个或多个 MigrationScript directives 组成的新结构。 然后 command.revision() 命令将生成与此列表中的任何内容相对应的脚本。
同样参考: 更多关于使用 EnvironmentContext.configure.process_revision_directives 的样例
-
alembic.autogenerate.render_python_code(up_or_down_op: UpgradeOps, sqlalchemy_module_prefix: str = 'sa.', alembic_module_prefix: str = 'op.', render_as_batch: bool = False, imports: Tuple[str, ...] = (), render_item: None = None, migration_context: Optional[MigrationContext] = None) → str
在给定 UpgradeOps 或 DowngradeOps 对象的情况下渲染 Python 代码。
这是一个方便的函数,可用于测试用户定义的 MigrationScript 结构的自动生成输出。
Fine-Grained Autogenerate Generation with Rewriters
带有重写器的细粒度自动生成
前面的示例说明了我们如何对操作指令的结构进行简单的更改以生成新的自动生成输出。 对于我们想要影响自动生成流的非常特定部分的情况,我们可以为 EnvironmentContext.configure.process_revision_directives 创建一个函数,该函数遍历整个 MigrationScript 结构,定位我们关心的元素并根据需要就地修改它们。 但是,为了减少与此任务相关的样板,我们可以使用 Rewriter 对象来简化此操作。 Rewriter 为我们提供了一个可以直接传递给 EnvironmentContext.configure.process_revision_directives 的对象,我们还可以将处理程序函数附加到该对象上,以特定类型为键值。
下面是我们重写 ops.AddColumnOp 指令的示例; 根据新列是否为“可空”,我们要么返回现有指令,要么返回现有指令并更改可空标志,在带有第二个指令的列表内,以在第二步中更改可空标志:
# ... fragmented env.py script ....
from alembic.autogenerate import rewriter
from alembic.operations import ops
writer = rewriter.Rewriter()
@writer.rewrites(ops.AddColumnOp)
def add_column(context, revision, op):
if op.column.nullable:
return op
else:
op.column.nullable = True
return [
op,
ops.AlterColumnOp(
op.table_name,
op.column.name,
modify_nullable=False,
existing_type=op.column.type,
)
]
# ... later ...
def run_migrations_online():
# ...
with connectable.connect() as connection:
context.configure(
connection=connection,
target_metadata=target_metadata,
process_revision_directives=writer
)
with context.begin_transaction():
context.run_migrations()
上面,在完整的 ops.MigrationScript 结构中,AddColumn 指令将出现在 MigrationScript->UpgradeOps->ModifyTableOps 和 MigrationScript->DowngradeOps->ModifyTableOps 路径中 . Rewriter 处理遍历这些结构以及根据需要重写它们,以便我们只需要为我们关心的特定对象编写代码。
-
class alembic.autogenerate.rewriter.Rewriter
一个帮助对象,允许轻松 ‘rewriting’ 操作流。
Rewriter 对象旨在传递给
env.py脚本中的 EnvironmentContext.configure.process_revision_directives 参数。 一旦构建,任何数量的“重写”函数都可以与之关联,这将有机会修改结构,而无需明确了解整体结构。该函数传递了通常传递给
Environment Context.configure.process_revision_directives函数的**MigrationContext**对象和revision元组,第三个参数是装饰器中注明的类型的单个指令。 该函数可以选择返回单个操作指令,通常可以是实际传递的指令,或者替换它的新指令,或者替换它的零个或多个指令列表。同样参考: [Fine-Grained Autogenerate Generation with Rewriters - usage example]
-
chain(other: [alembic.autogenerate.rewriter.Rewriter]) → [alembic.autogenerate.rewriter.Rewriter]
生成一个 Rewriter 到另一个的 “chain”。
这允许两个重写器在一个流上串行操作,例如:
writer1 = autogenerate.Rewriter() writer2 = autogenerate.Rewriter() @writer1.rewrites(ops.AddColumnOp) def add_column_nullable(context, revision, op): op.column.nullable = True return op @writer2.rewrites(ops.AddColumnOp) def add_column_idx(context, revision, op): idx_op = ops.CreateIndexOp( 'ixc', op.table_name, [op.column.name]) return [ op, idx_op ] writer = writer1.chain(writer2)Parameters: other – 一个 Rewriter 实例
Returns: 一个新的 Rewriter 将依次运行这个 writer 的操作,然后是 “other” writer。
-
rewrites(operator: Union[Type[AddColumnOp], Type[MigrateOperation], Type[AlterColumnOp], Type[CreateTableOp], Type[ModifyTableOps]]) → Callable
将函数注册为给定类型的重写器。
该函数应该接收三个参数,它们是 MigrationContext、一个
revision元组和一个指定类型的 op 指令。 例如。:@writer1.rewrites(ops.AddColumnOp) def add_column_nullable(context, revision, op): op.column.nullable = True return op
-
Revision Generation with Multiple Engines / run_migrations() calls
提供的“multidb”模板中说明了一种较少使用的技术,它允许自动生成的迁移同时针对多个数据库后端运行,将更改生成到单个迁移脚本中。 此模板具有一个特殊的 env.py,它遍历多个 Engine 实例并为每个实例调用 MigrationContext.run_migrations():
for name, rec in engines.items():
logger.info("Migrating database %s" % name)
context.configure(
connection=rec['connection'],
upgrade_token="%s_upgrades" % name,
downgrade_token="%s_downgrades" % name,
target_metadata=target_metadata.get(name)
)
context.run_migrations(engine_name=name)
如上所示,MigrationContext.run_migrations() 运行多次,每个引擎运行一次。 在自动生成的上下文中,每次调用方法时都会更改 upgrade_token 和 downgrade_token 参数,以便模板变量的集合为每个引擎获得不同的条目,然后引用 在 script.py.mako 中明确显示。
就 EnvironmentContext.configure.process_revision_directives 钩子而言,这里的行为是多次调用 process_revision_directives 钩子,每次调用 [context.run_migrations()] 一次。 这意味着如果要将 multi-run_migrations() 方法与 process_revision_directives 钩子结合使用,则必须注意适当地使用钩子。
首先要注意的是,当 第二次 调用 run_migrations() 时,.upgrade_ops 和 .downgrade_ops 属性被 转换为 Python 列表,并且新的 UpgradeOps 和 DowngradeOps 对象附加到这些列表中。 每个 UpgradeOps 和 DowngradeOps 对象分别维护一个 .upgrade_token 和一个 .downgrade_token 属性,用于将其内容渲染到适当的模板令牌中。
例如,引擎名称为 engine1 和 engine2 的多引擎运行将在运行时生成 engine1_upgrades、engine1_downgrades、engine2_upgrades和engine2_downgrades标记。 生成的迁移结构如下所示:
from alembic.operations import ops
import sqlalchemy as sa
migration_script = ops.MigrationScript(
'eced083f5df',
[
ops.UpgradeOps(
ops=[
# upgrade operations for "engine1"
],
upgrade_token="engine1_upgrades"
),
ops.UpgradeOps(
ops=[
# upgrade operations for "engine2"
],
upgrade_token="engine2_upgrades"
),
],
[
ops.DowngradeOps(
ops=[
# downgrade operations for "engine1"
],
downgrade_token="engine1_downgrades"
),
ops.DowngradeOps(
ops=[
# downgrade operations for "engine2"
],
downgrade_token="engine2_downgrades"
)
],
message='migration message'
)
鉴于上述情况,当 env.py 脚本在运行自动生成时多次调用 MigrationContext.run_migrations() 时,应考虑以下准则:
- 如果
process_revision_directives钩子旨在根据当前数据库/连接的检查添加元素,它应该在每次迭代中执行其操作。 这样每次钩子运行时,数据库都是可用的。 - 或者,如果
process_revision_directives钩子旨在修改适当的迁移指令列表,则应仅在最后一次迭代时调用。 这样一来,钩子每次都不会被赋予一个不断增长的结构,而它之前已经修改过。 - Rewriter 对象,如果使用的话,应该在最后一次迭代时调用,因为它每次都会传递所有指令,所以再次避免双重/三重/等。 指令的处理只有在结构完成时才应该调用它。
- 在引用 UpgradeOps 和 DowngradeOps 对象的集合时,应参考 MigrationScript.upgrade_ops_list 和 MigrationScript.downgrade_ops_list 属性。
Autogenerating Custom Operation Directives
在 Operation Plugins 部分中,我们讨论了添加 MigrateOperation 的新子类以添加新的 op. 指令。 在上一节**[自定义修订生成]** 中,我们还了解到,这些相同的**MigrateOperation** 结构是自动生成系统如何知道要呈现哪些 Python 代码的基础。 利用这些知识,我们可以创建插入自动生成系统的附加函数,以便在运行 alembic revision --autogenerate 时将我们的新操作生成到迁移脚本中。
以下部分将详细介绍使用我们在 Operation Plugins 中创建的 CreateSequenceOp 和 DropSequenceOp 指令的示例,它们对应于 SQLAlchemy Sequence 结构。
Tracking our Object with the Model
The basic job of an autogenerate comparison function is to inspect a series of objects in the database and compare them against a series of objects defined in our model. By “in our model”, we mean anything defined in Python code that we want to track, however most commonly we’re talking about a series of Table objects present in a MetaData collection.
Let’s propose a simple way of seeing what Sequence objects we want to ensure exist in the database when autogenerate runs. While these objects do have some integrations with Table and MetaData already, let’s assume they don’t, as the example here intends to illustrate how we would do this for most any kind of custom construct. We associate the object with the info collection of MetaData, which is a dictionary we can use for anything, which we also know will be passed to the autogenerate process:
from sqlalchemy.schema import Sequence
def add_sequence_to_model(sequence, metadata):
metadata.info.setdefault("sequences", set()).add(
(sequence.schema, sequence.name)
)
my_seq = Sequence("my_sequence")
add_sequence_to_model(my_seq, model_metadata)
The info dictionary is a good place to put things that we want our autogeneration routines to be able to locate, which can include any object such as custom DDL objects representing views, triggers, special constraints, or anything else we want to support.
Registering a Comparison Function
We now need to register a comparison hook, which will be used to compare the database to our model and produce CreateSequenceOp and DropSequenceOp directives to be included in our migration script. Note that we are assuming a Postgresql backend:
from alembic.autogenerate import comparators
@comparators.dispatch_for("schema")
def compare_sequences(autogen_context, upgrade_ops, schemas):
all_conn_sequences = set()
for sch in schemas:
all_conn_sequences.update([
(sch, row[0]) for row in
autogen_context.connection.execute(
"SELECT relname FROM pg_class c join "
"pg_namespace n on n.oid=c.relnamespace where "
"relkind='S' and n.nspname=%(nspname)s",
# note that we consider a schema of 'None' in our
# model to be the "default" name in the PG database;
# this usually is the name 'public'
nspname=autogen_context.dialect.default_schema_name
if sch is None else sch
)
])
# get the collection of Sequence objects we're storing with
# our MetaData
metadata_sequences = autogen_context.metadata.info.setdefault(
"sequences", set())
# for new names, produce CreateSequenceOp directives
for sch, name in metadata_sequences.difference(all_conn_sequences):
upgrade_ops.ops.append(
CreateSequenceOp(name, schema=sch)
)
# for names that are going away, produce DropSequenceOp
# directives
for sch, name in all_conn_sequences.difference(metadata_sequences):
upgrade_ops.ops.append(
DropSequenceOp(name, schema=sch)
)
Above, we’ve built a new function compare_sequences() and registered it as a “schema” level comparison function with autogenerate. The job that it performs is that it compares the list of sequence names present in each database schema with that of a list of sequence names that we are maintaining in our MetaData object.
When autogenerate completes, it will have a series of CreateSequenceOp and DropSequenceOp directives in the list of “upgrade” operations; the list of “downgrade” operations is generated directly from these using the CreateSequenceOp.reverse() and DropSequenceOp.reverse() methods that we’ve implemented on these objects.
The registration of our function at the scope of “schema” means our autogenerate comparison function is called outside of the context of any specific table or column. The three available scopes are “schema”, “table”, and “column”, summarized as follows:
-
Schema level - these hooks are passed a AutogenContext, an UpgradeOps collection, and a collection of string schema names to be operated upon. If the UpgradeOps collection contains changes after all hooks are run, it is included in the migration script:
@comparators.dispatch_for("schema") def compare_schema_level(autogen_context, upgrade_ops, schemas): pass -
Table level - these hooks are passed a AutogenContext, a ModifyTableOps collection, a schema name, table name, a Table reflected from the database if any or
None, and a Table present in the local MetaData. If the ModifyTableOps collection contains changes after all hooks are run, it is included in the migration script:@comparators.dispatch_for("table") def compare_table_level(autogen_context, modify_ops, schemaname, tablename, conn_table, metadata_table): pass -
Column level - these hooks are passed a AutogenContext, an AlterColumnOp object, a schema name, table name, column name, a Column reflected from the database and a Column present in the local table. If the AlterColumnOp contains changes after all hooks are run, it is included in the migration script; a “change” is considered to be present if any of the
modify_attributes are set to a non-default value, or there are any keys in the.kwcollection with the prefix"modify_":@comparators.dispatch_for("column") def compare_column_level(autogen_context, alter_column_op, schemaname, tname, cname, conn_col, metadata_col): pass
The AutogenContext passed to these hooks is documented below.
-
class alembic.autogenerate.api.AutogenContext(migration_context: MigrationContext, metadata: OptionalMetaData = None, opts: Optional[dict] = None, autogenerate: bool = True)
Maintains configuration and state that’s specific to an autogenerate operation.
-
connection: Optional[Connection] = None
The Connection object currently connected to the database backend being compared.
This is obtained from the MigrationContext.bind and is ultimately set up in the
env.pyscript. -
dialect: Optional[Dialect] = None
The Dialect object currently in use.
This is normally obtained from the
dialectattribute. -
A
set()which contains string Python import directives.The directives are to be rendered into the
${imports}section of a script template. The set is normally empty and can be modified within hooks such as the EnvironmentContext.configure.render_item hook. -
metadata: Optional[MetaData] = None
The MetaData object representing the destination.
This object is the one that is passed within
env.pyto the EnvironmentContext.configure.target_metadata parameter. It represents the structure ofTableand other objects as stated in the current database model, and represents the destination structure for the database being examined.While the MetaData object is primarily known as a collection of Table objects, it also has an
infodictionary that may be used by end-user schemes to store additional schema-level objects that are to be compared in custom autogeneration schemes. -
migration_context: MigrationContext = None
The MigrationContext established by the
env.pyscript. -
run_filters(object_: Union[Table, Index, Column, UniqueConstraint, ForeignKeyConstraint], name: Optional[[str]], type_: [str], reflected: [bool], compare_to: Optional[Union[Table, Index, Column, UniqueConstraint]]) → [bool]
Run the context’s object filters and return True if the targets should be part of the autogenerate operation.
This method should be run for every kind of object encountered within an autogenerate operation, giving the environment the chance to filter what objects should be included in the comparison. The filters here are produced directly via the EnvironmentContext.configure.include_object parameter.
-
run_name_filters(name: Optional[[str]], type_: [str], parent_names: Dict[str, Optional[[str]]]) → [bool]
Run the context’s name filters and return True if the targets should be part of the autogenerate operation.
This method should be run for every kind of name encountered within the reflection side of an autogenerate operation, giving the environment the chance to filter what names should be reflected as database objects. The filters here are produced directly via the EnvironmentContext.configure.include_name parameter.
-
run_object_filters(object_: Union[Table, Index, Column, UniqueConstraint, ForeignKeyConstraint], name: Optional[str], type_: [str], reflected: [bool], compare_to: Optional[Union[Table, Index, Column, UniqueConstraint]]) → [bool]
Run the context’s object filters and return True if the targets should be part of the autogenerate operation.
This method should be run for every kind of object encountered within an autogenerate operation, giving the environment the chance to filter what objects should be included in the comparison. The filters here are produced directly via the EnvironmentContext.configure.include_object parameter.
-
sorted_tables
Return an aggregate of the
MetaData.sorted_tablescollection(s).For a sequence of
MetaDataobjects, this concatenates theMetaData.sorted_tables collection for each individualMetaDatain the order of the sequence. It does not collate the sorted tables collections. -
table_key_to_table
Return an aggregate of the
MetaData.tablesdictionaries.The
MetaData.tablescollection is a dictionary of table key to Table; this method aggregates the dictionary across multipleMetaDataobjects into one dictionary.Duplicate table keys are not supported; if two
MetaDataobjects contain the same table key, an exception is raised.
-
Creating a Render Function
The second autogenerate integration hook is to provide a “render” function; since the autogenerate system renders Python code, we need to build a function that renders the correct “op” instructions for our directive:
from alembic.autogenerate import renderers
@renderers.dispatch_for(CreateSequenceOp)
def render_create_sequence(autogen_context, op):
return "op.create_sequence(%r, **%r)" % (
op.sequence_name,
{"schema": op.schema}
)
@renderers.dispatch_for(DropSequenceOp)
def render_drop_sequence(autogen_context, op):
return "op.drop_sequence(%r, **%r)" % (
op.sequence_name,
{"schema": op.schema}
)
The above functions will render Python code corresponding to the presence of CreateSequenceOp and DropSequenceOp instructions in the list that our comparison function generates.
Running It
All the above code can be organized however the developer sees fit; the only thing that needs to make it work is that when the Alembic environment env.py is invoked, it either imports modules which contain all the above routines, or they are locally present, or some combination thereof.
If we then have code in our model (which of course also needs to be invoked when env.py runs!) like this:
from sqlalchemy.schema import Sequence
my_seq_1 = Sequence("my_sequence_1")
add_sequence_to_model(my_seq_1, target_metadata)
When we first run alembic revision --autogenerate, we’ll see this in our migration file:
def upgrade():
### commands auto generated by Alembic - please adjust! ###
op.create_sequence('my_sequence_1', **{'schema': None})
### end Alembic commands ###
def downgrade():
### commands auto generated by Alembic - please adjust! ###
op.drop_sequence('my_sequence_1', **{'schema': None})
### end Alembic commands ###
These are our custom directives that will invoke when alembic upgrade or alembic downgrade is run.
Script Directory
The ScriptDirectory object provides programmatic accessto the Alembic version files present in the filesystem.
-
class alembic.script. Script (module: module, rev_id: str, path: str)
Represent a single revision file in a directory.
The Script instance is returned by methodssuch as ScriptDirectory.iterate_revisions() .
-
class alembic.script. ScriptDirectory (dir: str, file_template: str = '%(rev)s_%(slug)s', truncate_slug_length: Optional[int] = 40, version_locations: Optional[List[str]] = None, sourceless: bool = False, output_encoding: str = 'utf-8', timezone: Optional[str] = None, hook_config: Optional[Dict[str, str]] = None)
Provides operations upon an Alembic script directory.
This object is useful to get information as to current revisions, most notably being able to get at the “head” revision, for schemes that want to test if the current revision in the database is the most recent:
from alembic.script import ScriptDirectory from alembic.config import Config config = Config() config.set_main_option("script_location", "myapp:migrations") script = ScriptDirectory.from_config(config) head_revision = script.get_current_head()-
classmethod from_config (config: Config) → ScriptDirectory
Produce a new ScriptDirectory given a Config instance.
The Config need only have the
script_locationkey present. -
generate_revision (revid: str, message: Optional[str], head: Optional[str] = None, refresh: bool = False, splice: Optional[bool] = False, branch_labels: Optional[str] = None, version_path: Optional[str] = None, depends_on: Optional[Union[str, Sequence[str]]] = None, **kw: Any) → Optional[alembic.script.base.Script]
Generate a new revision file.
This runs the template, giventemplate arguments, and creates a new file.
Parameters
- [revid] - String revision id. Typically thiscomes from
alembic.util.rev_id(). - [message] - the revision message, the one passedby the -m argument to the
revisioncommand. - [head] - the head revision to generate against. Defaultsto the current âheadâ if True, allow the âheadâ deprecated.
- [revid] - String revision id. Typically thiscomes from
-
get_base () → Optional[str]
Return the âbaseâbaseâversioned headâll get nothing back.
The iterator yields Script objects.
-
run_env () → None
Run the script environment.
This basically runs the
env.pyscript presentin the migration environment. It is called exclusivelyby the command functions in alembic.command . -
walk_revisions (base: str = 'base', head: str = 'heads') → Iterator[alembic.script.base.Script]
Iterate through all revisions.
Parameters
- [base] - the base revision, or âbaseâ the head revision; defaults to âheadsâheadâs branch
- [head] â the head revision; defaults to “heads” to indicateall head revisions. May also be “heads” to indicate a singlehead revision.
-
Revision
The RevisionMap object serves as the basis for revisionmanagement, used exclusively by ScriptDirectory .
-
exception alembic.script.revision. CycleDetected (revisions: Sequence[str])
-
exception alembic.script.revision. DependencyCycleDetected (revisions: Sequence[str])
-
exception alembic.script.revision. DependencyLoopDetected (revision: Sequence[str])
-
exception alembic.script.revision. LoopDetected (revision: str)
-
exception alembic.script.revision. MultipleHeads (heads: Sequence[str], argument: Optional[str])
-
exception alembic.script.revision. RangeNotAncestorError (lower: Optional[Union[str, Tuple[str, ...]]], upper: Optional[Union[str, Tuple[str, ...]]])
-
exception alembic.script.revision. ResolutionError (message: str, argument: str)
-
class alembic.script.revision. Revision (revision: str, down_revision: Optional[Union[str, Tuple[str, ...]]], dependencies: Optional[Tuple[str, ...]] = None, branch_labels: Optional[Tuple[str, ...]] = None)
Base class for revisioned objects.
The Revision class is the base of the more public-facing Script object, which represents a migration script.The mechanics of revision management and traversal are encapsulatedwithin Revision , while Script applies this logicto Python files in a version directory.
-
branch_labels : Set[str] = None
Optional string/tuple of symbolic names to apply to thisrevision"s branch
-
dependencies : Optional[Union[str, Sequence[str]]] = None
Additional revisions which this revision is dependent on.
From a migration standpoint, these dependencies are added to thedown_revision to form the full iteration. However, the separationof down_revision from “dependencies” is to assist in navigatinga history that contains many branches, typically a multi-root scenario.
-
down_revision : Optional[Union[str, Sequence[str]]] = None
The
down_revisionidentifier(s) within the migration script.Note that the total set of "down" revisions isdown_revision + dependencies.
-
property is_base : bool
Return True if this Revision is a "base" revision.
-
property is_branch_point : bool
Return True if this Script is a branch point.
A branchpoint is defined as a Script which is referredto by more than one succeeding Script , that is morethan one Script has a identifier pointinghere.
-
property is_head : bool
Return True if this Revision is a "head" revision.
This is determined based on whether any other Script within the ScriptDirectory refers to this Script . Multiple heads can be present.
-
property is_merge_point : bool
Return True if this Script is a merge point.
-
nextrev : FrozenSet[str] = frozenset({})
following revisions, based on down_revision only.
-
revision : str = None
The string revision number.
-
-
exception alembic.script.revision. RevisionError
-
class alembic.script.revision. RevisionMap (generator: Callable[[], Iterator[alembic.script.revision.Revision]])
Maintains a map of Revision objects.
RevisionMap is used by ScriptDirectory to maintainand traverse the collection of Script objects, which arethemselves instances of Revision .
Construct a new RevisionMap .
Parameters:
-
add_revision (revision: alembic.script.revision.Revision, _replace: bool = False) → None
add a single revision to an existing map.
This method is for single-revision use cases, it"s notappropriate for fully populating an entire revision map.
-
bases
All ”base“ revisions as strings.
These are revisions that have a
down_revisionof None,or empty tuple.Returns:
- a tuple of string revision numbers.
-
get_current_head (branch_label: Optional[str] = None) → Optional[str]
Return the current head revision.
If the script directory has multiple headsdue to branching, an error is raised; ScriptDirectory.get_heads() should bepreferred.
Parameters:
- branch_label " optional branch name which will limit theheads considered to those which include that branch_label.
Returns: a string revision number.
See also: ScriptDirectory.get_heads()
-
get_revision (id_: Optional[str]) → alembic.script.revision.Revision
Return the Revision instance with the given rev id.
If a symbolic name such as "head" or "base" is given, resolvesthe identifier into the current head or base revision. If the symbolicname refers to multiples, MultipleHeads is raised.
Supports partial identifiers, where the given identifieris matched against all identifiers that start with the givencharacters; if there is exactly one match, that determines thefull revision.
-
get_revisions (id_: Optional[Union[str, Collection[str]]]) → Tuple[alembic.script.revision.Revision, ...]
Return the Revision instances with the given rev idor identifiers.
May be given a single identifier, a sequence of identifiers, or thespecial symbols "head" or "base". The result is a tuple of oneor more identifiers, or an empty tuple in the case of "base".
In the cases where "head", "heads" is requested and therevision map is empty, returns an empty tuple.
Supports partial identifiers, where the given identifieris matched against all identifiers that start with the givencharacters; if there is exactly one match, that determines thefull revision.
-
heads
All "head" revisions as strings.
This is normally a tuple of length one,unless unmerged branches are present.
Returns: a tuple of string revision numbers.
-
iterate_revisions (upper: Optional[Union[str, Tuple[str, ...]]], lower: Optional[Union[str, Tuple[str, ...]]], implicit_base: bool = False, inclusive: bool = False, assert_relative_length: bool = True, select_for_downgrade: bool = False) → Iterator[alembic.script.revision.Revision]
Iterate through script revisions, starting at the givenupper revision identifier and ending at the lower.
The traversal uses strictly the marker inside each migration script, soit is a requirement that upper >= lower,else you"ll get nothing back.
The iterator yields Revision objects.
-
Write Hooks
alembic.script.write_hooks. register (name: str) → Callable
A function decorator that will register that function as a write hook.
See the documentation linked below for an example.
DDL Internals
These are some of the constructs used to generate migrationinstructions. The APIs here build off of the sqlalchemy.schema.DDLElement and Custom SQL Constructs and Compilation Extension systems.
For programmatic usage of Alembicâs migration directives, the easiestroute is to use the higher level functions given by Operation Directives .
-
class alembic.ddl.base. AddColumn (name: str, column: sqlalchemy.sql.schema.Column, schema: Optional[Union[sqlalchemy.sql.elements.quoted_name, str]] = None)
-
class alembic.ddl.base. AlterColumn (name: str, column_name: str, schema: Optional[str] = None, existing_type: Optional[TypeEngine] = None, existing_nullable: Optional[bool] = None, existing_server_default: Optional[Union[TextClause, FetchedValue, Function, str]] = None, existing_comment: Optional[str] = None)
-
class alembic.ddl.base. AlterTable (table_name: str, schema: Optional[Union[sqlalchemy.sql.elements.quoted_name, str]] = None)
Represent an ALTER TABLE statement.
Only the string name and optional schema name of the tableis required, not a full Table object.
-
class alembic.ddl.base. ColumnComment (name: str, column_name: str, comment: Optional[str], **kw)
-
class alembic.ddl.base. ColumnDefault (name: str, column_name: str, default: Optional[Union[TextClause, FetchedValue, Function, str]], **kw)
-
class alembic.ddl.base. ColumnName (name: str, column_name: str, newname: str, **kw)
-
class alembic.ddl.base. ColumnNullable (name: str, column_name: str, nullable: bool, **kw)
-
class alembic.ddl.base. ColumnType (name: str, column_name: str, type_: TypeEngine, **kw)
-
class alembic.ddl.base. ComputedColumnDefault (name: str, column_name: str, default: Optional[Computed], **kw)
-
class alembic.ddl.base. DropColumn (name: str, column: sqlalchemy.sql.schema.Column, schema: Optional[str] = None)
-
class alembic.ddl.base. IdentityColumnDefault (name: str, column_name: str, default: Optional[Identity], impl: DefaultImpl, **kw)
-
class alembic.ddl.base. RenameTable (old_table_name: str, new_table_name: Union[sqlalchemy.sql.elements.quoted_name, str], schema: Optional[Union[sqlalchemy.sql.elements.quoted_name, str]] = None)
-
alembic.ddl.base. add_column (compiler: DDLCompiler, column: Column, **kw) → str
-
alembic.ddl.base. alter_column (compiler: DDLCompiler, name: str) → str
-
alembic.ddl.base. alter_table (compiler: DDLCompiler, name: str, schema: Optional[str]) → str
-
alembic.ddl.base. drop_column (compiler: DDLCompiler, name: str, **kw) → str
-
alembic.ddl.base. format_column_name (compiler: DDLCompiler, name: Optional[Union[quoted_name, str]]) → Union[quoted_name, str]
-
alembic.ddl.base. format_server_default (compiler: DDLCompiler, default: Optional[Union[TextClause, FetchedValue, Function, str]]) → str
-
alembic.ddl.base. format_table_name (compiler: Compiled, name: Union[quoted_name, str], schema: Optional[Union[quoted_name, str]]) → Union[quoted_name, str]
-
alembic.ddl.base. format_type (compiler: DDLCompiler, type_: TypeEngine) → str
-
alembic.ddl.base. quote_dotted (name: Union[sqlalchemy.sql.elements.quoted_name, str], quote: functools.partial) → Union[sqlalchemy.sql.elements.quoted_name, str]
quote the elements of a dotted name
-
alembic.ddl.base. visit_add_column (element: AddColumn, compiler: DDLCompiler, **kw) → str
-
alembic.ddl.base. visit_column_default (element: ColumnDefault, compiler: DDLCompiler, **kw) → str
-
alembic.ddl.base. visit_column_name (element: ColumnName, compiler: DDLCompiler, **kw) → str
-
alembic.ddl.base. visit_column_nullable (element: ColumnNullable, compiler: DDLCompiler, **kw) → str
-
alembic.ddl.base. visit_column_type (element: ColumnType, compiler: DDLCompiler, **kw) → str
-
alembic.ddl.base. visit_computed_column (element: ComputedColumnDefault, compiler: DDLCompiler, **kw)
-
alembic.ddl.base. visit_drop_column (element: DropColumn, compiler: DDLCompiler, **kw) → str
-
alembic.ddl.base. visit_identity_column (element: IdentityColumnDefault, compiler: DDLCompiler, **kw)
-
alembic.ddl.base. visit_rename_table (element: RenameTable, compiler: DDLCompiler, **kw) → str
-
class alembic.ddl.impl. DefaultImpl (dialect: Dialect, connection: Optional[Connection], as_sql: bool, transactional_ddl: Optional[bool], output_buffer: Optional[StringIO], context_opts: Dict[str, Any])
Provide the entrypoint for major migration operations,including database-specific behavioral variances.
While individual SQL/DDL constructs already providefor database-specific implementations, variances hereallow for entirely different sequences of operationsto take place for a particular migration, such asSQL Serverâs special âIDENTITY INSERTâ step forbulk inserts.
-
add_column (table_name: str, column: Column, schema: Optional[Union[quoted_name, str]] = None) → None
-
add_constraint (const: Any) → None
-
alter_column (table_name: str, column_name: str, nullable: Optional[bool] = None, server_default: Union[_ServerDefault, Literal[False]] = False, name: Optional[str] = None, type_: Optional[TypeEngine] = None, schema: Optional[str] = None, autoincrement: Optional[bool] = None, comment: Optional[Union[str, Literal[False]]] = False, existing_comment: Optional[str] = None, existing_type: Optional[TypeEngine] = None, existing_server_default: Optional[_ServerDefault] = None, existing_nullable: Optional[bool] = None, existing_autoincrement: Optional[bool] = None, **kw: Any) → None
-
autogen_column_reflect (inspector, table, column_info)
A hook that is attached to the âcolumn_reflectâ event for whena Table is reflected from the database during the autogenerateprocess.
Dialects can elect to modify the information gathered here.
-
property bind : Optional[Connection]
-
bulk_insert (table: Union[TableClause, Table], rows: List[dict], multiinsert: bool = True) → None
-
cast_for_batch_migrate (existing, existing_transfer, new_type)
-
command_terminator = ';'
-
compare_server_default (inspector_column, metadata_column, rendered_metadata_default, rendered_inspector_default)
-
compare_type (inspector_column: Column, metadata_column: Column) → bool
Returns True if there ARE differences between the types of the twocolumns. Takes impl.type_synonyms into account between retrospectedand metadata types
-
correct_for_autogen_constraints (conn_uniques: Set[UniqueConstraint], conn_indexes: Set[Index], metadata_unique_constraints: Set[UniqueConstraint], metadata_indexes: Set[Index]) → None
-
correct_for_autogen_foreignkeys (conn_fks: Set[ForeignKeyConstraint], metadata_fks: Set[ForeignKeyConstraint]) → None
-
create_column_comment (column: ColumnElement) → None
-
create_index (index: Index) → None
-
create_table (table: Table) → None
-
create_table_comment (table: Table) → None
-
drop_column (table_name: str, column: Column, schema: Optional[str] = None, **kw) → None
-
drop_constraint (const: Constraint) → None
-
drop_index (index: Index) → None
-
drop_table (table: Table) → None
-
drop_table_comment (table: Table) → None
-
emit_begin () → None
Emit the string
BEGIN, or the backend-specificequivalent, on the current connection context.This is used in offline mode and typicallyvia EnvironmentContext.begin_transaction() .
-
emit_commit () → None
Emit the string
COMMIT, or the backend-specificequivalent, on the current connection context.This is used in offline mode and typicallyvia EnvironmentContext.begin_transaction() .
-
execute (sql: Union[Update, TextClause, str], execution_options: None = None) → None
-
classmethod get_by_dialect (dialect: Dialect) → Any
-
identity_attrs_ignore : Tuple[str, ...] = ('on_null',)
-
prep_table_for_batch (batch_impl: ApplyBatchImpl, table: Table) → None
perform any operations needed on a table before a newone is created to replace it in batch mode.
the PG dialect uses this to drop constraints on the tablebefore the new one uses those same names.
-
rename_table (old_table_name: str, new_table_name: Union[str, quoted_name], schema: Optional[Union[quoted_name, str]] = None) → None
-
render_ddl_sql_expr (expr: ClauseElement, is_server_default: bool = False, **kw) → str
Render a SQL expression that is typically a server default,index expression, etc.
New in version 1.0.11.
-
render_type (type_obj: TypeEngine, autogen_context: AutogenContext) → Union[str, Literal[False]]
-
requires_recreate_in_batch (batch_op: BatchOperationsImpl) → bool
Return True if the given
BatchOperationsImplwould need the table to be recreated and copied in order toproceed.Normally, only returns True on SQLite when operations otherthan add_column are present.
-
start_migrations () → None
A hook called when EnvironmentContext.run_migrations() is called.
Implementations can set up per-migration-run state here.
-
transactional_ddl = False
-
type_arg_extract : Sequence[str] = ()
-
type_synonyms : Tuple[Set[str], ...] = ({'DECIMAL', 'NUMERIC'},)
-
-
class alembic.ddl.impl. ImplMeta (classname: str, bases: Tuple[Type[alembic.ddl.impl.DefaultImpl]], dict_: Dict[str, Any])
-
class alembic.ddl.impl. Params (token0, tokens, args, kwargs)
Create new instance of Params(token0, tokens, args, kwargs)
-
property args
Alias for field number 2
-
property kwargs
Alias for field number 3
-
property token0
Alias for field number 0
-
property tokens
Alias for field number 1
-
MySQL
-
class alembic.ddl.mysql. MariaDBImpl (dialect: Dialect, connection: Optional[Connection], as_sql: bool, transactional_ddl: Optional[bool], output_buffer: Optional[StringIO], context_opts: Dict[str, Any])
Bases: alembic.ddl.mysql.MySQLImpl
- memo : dict
-
class alembic.ddl.mysql. MySQLAlterDefault (name: str, column_name: str, default: _ServerDefault, schema: Optional[str] = None)
Bases: alembic.ddl.base.AlterColumn
-
class alembic.ddl.mysql. MySQLChangeColumn (name: str, column_name: str, schema: Optional[str] = None, newname: Optional[str] = None, type_: Optional[TypeEngine] = None, nullable: Optional[bool] = None, default: Optional[Union[_ServerDefault, Literal[False]]] = False, autoincrement: Optional[bool] = None, comment: Optional[Union[str, Literal[False]]] = False)
Bases: alembic.ddl.base.AlterColumn
-
class alembic.ddl.mysql. MySQLImpl (dialect: Dialect, connection: Optional[Connection], as_sql: bool, transactional_ddl: Optional[bool], output_buffer: Optional[StringIO], context_opts: Dict[str, Any])
Bases: alembic.ddl.impl.DefaultImpl
-
alter_column (table_name: str, column_name: str, nullable: Optional[bool] = None, server_default: Union[_ServerDefault, Literal[False]] = False, name: Optional[str] = None, type_: Optional[TypeEngine] = None, schema: Optional[str] = None, existing_type: Optional[TypeEngine] = None, existing_server_default: Optional[_ServerDefault] = None, existing_nullable: Optional[bool] = None, autoincrement: Optional[bool] = None, existing_autoincrement: Optional[bool] = None, comment: Optional[Union[str, Literal[False]]] = False, existing_comment: Optional[str] = None, **kw: Any) → None
-
compare_server_default (inspector_column, metadata_column, rendered_metadata_default, rendered_inspector_default)
-
correct_for_autogen_constraints (conn_unique_constraints, conn_indexes, metadata_unique_constraints, metadata_indexes)
-
correct_for_autogen_foreignkeys (conn_fks, metadata_fks)
-
drop_constraint (const: Constraint) → None
-
memo : dict
-
transactional_ddl = False
-
type_arg_extract : Sequence[str] = ['character set ([\w\-]+)', 'collate ([\w\-]+)']
-
type_synonyms : Tuple[Set[str], ...] = ({'DECIMAL', 'NUMERIC'}, {'BOOL', 'TINYINT'}, {'LONGTEXT', 'JSON'})
-
-
class alembic.ddl.mysql. MySQLModifyColumn (name: str, column_name: str, schema: Optional[str] = None, newname: Optional[str] = None, type_: Optional[TypeEngine] = None, nullable: Optional[bool] = None, default: Optional[Union[_ServerDefault, Literal[False]]] = False, autoincrement: Optional[bool] = None, comment: Optional[Union[str, Literal[False]]] = False)
MS-SQL
-
class alembic.ddl.mssql. MSSQLImpl (*arg, **kw)
Bases: alembic.ddl.impl.DefaultImpl
-
alter_column (table_name: str, column_name: str, nullable: Optional[bool] = None, server_default: Optional[Union[_ServerDefault, Literal[False]]] = False, name: Optional[str] = None, type_: Optional[TypeEngine] = None, schema: Optional[str] = None, existing_type: Optional[TypeEngine] = None, existing_server_default: Optional[_ServerDefault] = None, existing_nullable: Optional[bool] = None, **kw: Any) → None
-
batch_separator = 'GO'
-
bulk_insert (table: Union[TableClause, Table], rows: List[dict], **kw: Any) → None
-
compare_server_default (inspector_column, metadata_column, rendered_metadata_default, rendered_inspector_default)
-
create_index (index: Index) → None
-
drop_column (table_name: str, column: sqlalchemy.sql.schema.Column, schema: Optional[str] = None, **kw) → None
-
emit_begin () → None
Emit the string
BEGIN, or the backend-specificequivalent, on the current connection context.This is used in offline mode and typicallyvia EnvironmentContext.begin_transaction() .
-
emit_commit () → None
Emit the string
COMMIT, or the backend-specificequivalent, on the current connection context.This is used in offline mode and typicallyvia EnvironmentContext.begin_transaction() .
-
identity_attrs_ignore : Tuple[str, ...] = ('minvalue', 'maxvalue', 'nominvalue', 'nomaxvalue', 'cycle', 'cache', 'order', 'on_null', 'order')
-
memo : dict
-
transactional_ddl = True
-
type_synonyms : Tuple[Set[str], ...] = ({'DECIMAL', 'NUMERIC'}, {'NVARCHAR', 'VARCHAR'})
-
-
alembic.ddl.mssql. mssql_add_column (compiler: MSDDLCompiler, column: Column, **kw) → str
-
alembic.ddl.mssql. visit_add_column (element: AddColumn, compiler: MSDDLCompiler, **kw) → str
-
alembic.ddl.mssql. visit_column_default (element: ColumnDefault, compiler: MSDDLCompiler, **kw) → str
-
alembic.ddl.mssql. visit_column_nullable (element: ColumnNullable, compiler: MSDDLCompiler, **kw) → str
-
alembic.ddl.mssql. visit_column_type (element: ColumnType, compiler: MSDDLCompiler, **kw) → str
-
alembic.ddl.mssql. visit_rename_column (element: ColumnName, compiler: MSDDLCompiler, **kw) → str
-
alembic.ddl.mssql. visit_rename_table (element: RenameTable, compiler: MSDDLCompiler, **kw) → str
Postgresql
-
class alembic.ddl.postgresql. CreateExcludeConstraintOp (constraint_name: Optional[str], table_name: Union[str, quoted_name], elements: Union[Sequence[Tuple[str, str]], Sequence[Tuple[ColumnClause, str]]], where: Optional[Union[BinaryExpression, str]] = None, schema: Optional[str] = None, _orig_constraint: Optional[ExcludeConstraint] = None, **kw)
Bases: alembic.operations.ops.AddConstraintOp
Represent a create exclude constraint operation.
-
classmethod batch_create_exclude_constraint (operations, constraint_name, *elements, **kw)
This method is proxied on the BatchOperations class, via the BatchOperations.create_exclude_constraint() method.
-
constraint_type = 'exclude'
-
classmethod create_exclude_constraint (operations: Operations, constraint_name: str, table_name: str, *elements: Any, **kw: Any) → Optional[Table]
This method is proxied on the Operations class, via the Operations.create_exclude_constraint() method.
-
classmethod from_constraint (constraint: sqlalchemy.dialects.postgresql.ext.ExcludeConstraint) → alembic.ddl.postgresql.CreateExcludeConstraintOp
-
to_constraint (migration_context: Optional[MigrationContext] = None) → ExcludeConstraint
-
-
class alembic.ddl.postgresql. PostgresqlColumnType (name: str, column_name: str, type_: TypeEngine, **kw)
Bases: alembic.ddl.base.AlterColumn
-
class alembic.ddl.postgresql. PostgresqlImpl (dialect: Dialect, connection: Optional[Connection], as_sql: bool, transactional_ddl: Optional[bool], output_buffer: Optional[StringIO], context_opts: Dict[str, Any])
Bases: alembic.ddl.impl.DefaultImpl
-
alter_column (table_name: str, column_name: str, nullable: Optional[bool] = None, server_default: Union[_ServerDefault, Literal[False]] = False, name: Optional[str] = None, type_: Optional[TypeEngine] = None, schema: Optional[str] = None, autoincrement: Optional[bool] = None, existing_type: Optional[TypeEngine] = None, existing_server_default: Optional[_ServerDefault] = None, existing_nullable: Optional[bool] = None, existing_autoincrement: Optional[bool] = None, **kw: Any) → None
-
autogen_column_reflect (inspector, table, column_info)
A hook that is attached to the âcolumn_reflectâ event for whena Table is reflected from the database during the autogenerateprocess.
Dialects can elect to modify the information gathered here.
-
compare_server_default (inspector_column, metadata_column, rendered_metadata_default, rendered_inspector_default)
-
correct_for_autogen_constraints (conn_unique_constraints, conn_indexes, metadata_unique_constraints, metadata_indexes)
-
create_index (index)
-
identity_attrs_ignore : Tuple[str, ...] = ('on_null', 'order')
-
memo : dict
-
prep_table_for_batch (batch_impl, table)
perform any operations needed on a table before a newone is created to replace it in batch mode.
the PG dialect uses this to drop constraints on the tablebefore the new one uses those same names.
-
render_type (type_: TypeEngine, autogen_context: AutogenContext) → Union[str, Literal[False]]
-
transactional_ddl = True
-
type_synonyms : Tuple[Set[str], ...] = ({'DECIMAL', 'NUMERIC'}, {'DOUBLE PRECISION', 'FLOAT'})
-
-
alembic.ddl.postgresql. visit_column_comment (element: ColumnComment, compiler: PGDDLCompiler, **kw) → str
-
alembic.ddl.postgresql. visit_column_type (element: alembic.ddl.postgresql.PostgresqlColumnType, compiler: PGDDLCompiler, **kw) → str
-
alembic.ddl.postgresql. visit_identity_column (element: IdentityColumnDefault, compiler: PGDDLCompiler, **kw)
-
alembic.ddl.postgresql. visit_rename_table (element: alembic.ddl.base.RenameTable, compiler: PGDDLCompiler, **kw) → str
SQLite
-
class alembic.ddl.sqlite. SQLiteImpl (dialect: Dialect, connection: Optional[Connection], as_sql: bool, transactional_ddl: Optional[bool], output_buffer: Optional[StringIO], context_opts: Dict[str, Any])
Bases: alembic.ddl.impl.DefaultImpl
-
add_constraint (const: Constraint)
-
autogen_column_reflect (inspector: Inspector, table: Table, column_info: Dict[str, Any]) → None
A hook that is attached to the âcolumn_reflectâ event for whena Table is reflected from the database during the autogenerateprocess.
Dialects can elect to modify the information gathered here.
-
cast_for_batch_migrate (existing: Column, existing_transfer: Dict[str, Union[TypeEngine, Cast]], new_type: TypeEngine) → None
-
compare_server_default (inspector_column: Column, metadata_column: Column, rendered_metadata_default: Optional[str], rendered_inspector_default: Optional[str]) → bool
-
drop_constraint (const: Constraint)
-
memo : dict
-
render_ddl_sql_expr (expr: ClauseElement, is_server_default: bool = False, **kw) → str
Render a SQL expression that is typically a server default,index expression, etc.
-
requires_recreate_in_batch (batch_op: BatchOperationsImpl) → bool
Return True if the given
BatchOperationsImplwould need the table to be recreated and copied in order toproceed.Normally, only returns True on SQLite when operations otherthan add_column are present.
-
transactional_ddl = False
SQLite supports transactional DDL, but pysqlite does not:see: http://bugs.python.org/issue10740
-
Changelog
更新历史
参考原文: Changelog
<div class="document">
<div class="documentwrapper">
<div class="bodywrapper">
<div class="body" role="main">
Index
Symbols
|
A
|
|
B
C
D
E
F
G
H
|
I
K
L
M
N
|
|
O
|
|
P
|
|
Q
R
S
T
U
|
V
W
<div class="clearer"></div>
</div>
</div>
</div>
<div class="sphinxsidebar" role="navigation" aria-label="main navigation">
<div class="sphinxsidebarwrapper"><script async type="text/javascript" src="//cdn.carbonads.com/carbon.js?serve=CKYIL23W&placement=alembiczzzcomputingcom" id="_carbonads_js"></script>
