2.2 Web 与 HTTP#
2.2 The Web and HTTP
直到 20 世纪 90 年代初,互联网主要被研究人员、学者和大学生用于登录远程主机、在本地主机与远程主机之间传输文件、接收和发送新闻,以及接收和发送电子邮件。虽然这些应用非常有用(而且至今仍然如此),但互联网在学术和研究界之外基本上是默默无闻的。随后,在 90 年代初,一个全新的重要应用出现在大众面前——万维网(World Wide Web) [Berners-Lee 1994]。Web 是第一个真正吸引公众眼球的互联网应用。它极大地改变了并持续改变着人们在工作和生活中互动的方式。它使互联网从众多数据网络中的一个跃升为几乎是唯一的数据网络。
Web 最吸引用户的一点,也许是它支持 按需服务。用户可以在他们想要的时候获取他们想要的内容。这与传统的广播电台和电视不同,后者要求用户在内容提供者提供内容的时间收听或观看。除了按需获取内容,Web 还有许多其他受人喜爱的特性。任何人都可以非常容易地通过 Web 发布信息——每个人都可以以极低的成本成为发布者。超链接和搜索引擎帮助我们在信息海洋中导航。照片和视频刺激我们的感官。表单、JavaScript、Java 小程序以及许多其他技术手段让我们可以与页面和网站交互。而 Web 及其协议则为 YouTube、基于 Web 的电子邮件(如 Gmail)以及包括 Instagram 和 Google 地图在内的大多数移动互联网应用提供了平台。
Until the early 1990s the Internet was used primarily by researchers, academics, and university students to log in to remote hosts, to transfer files from local hosts to remote hosts and vice versa, to receive and send news, and to receive and send electronic mail. Although these applications were (and continue to be) extremely useful, the Internet was essentially unknown outside of the academic and research communities. Then, in the early 1990s, a major new application arrived on the scene—the World Wide Web [Berners-Lee 1994]. The Web was the first Internet application that caught the general public’s eye. It dramatically changed, and continues to change, how people interact inside and outside their work environments. It elevated the Internet from just one of many data networks to essentially the one and only data network.
Perhaps what appeals the most to users is that the Web operates on demand. Users receive what they want, when they want it. This is unlike traditional broadcast radio and television, which force users to tune in when the content provider makes the content available. In addition to being available on demand, the Web has many other wonderful features that people love and cherish. It is enormously easy for any individual to make information available over the Web—everyone can become a publisher at extremely low cost. Hyperlinks and search engines help us navigate through an ocean of information. Photos and videos stimulate our senses. Forms, JavaScript, Java applets, and many other devices enable us to interact with pages and sites. And the Web and its protocols serve as a platform for YouTube, Web-based e-mail (such as Gmail), and most mobile Internet applications, including Instagram and Google Maps.
2.2.1 HTTP 概述#
2.2.1 Overview of HTTP
超文本传输协议(HTTP) 是 Web 的应用层协议,是 Web 的核心。它在 [RFC 1945] 和 [RFC 2616] 中进行了定义。HTTP 是通过两个程序实现的:客户端程序和服务器程序。客户端程序和服务器程序在不同的端系统上运行,它们通过交换 HTTP 消息进行通信。HTTP 定义了这些消息的结构以及客户端与服务器之间的消息交换方式。在详细解释 HTTP 之前,我们先回顾一些 Web 术语。
一个 网页 (也称为文档)由多个对象组成。一个 对象 就是一个文件——例如 HTML 文件、JPEG 图像、Java 小程序或视频剪辑——可以通过一个 URL 访问。大多数网页由一个 基础 HTML 文件 和若干引用对象组成。例如,一个包含 HTML 文本和五张 JPEG 图片的网页包含六个对象:一个基础 HTML 文件加五个图像。基础 HTML 文件通过各个对象的 URL 来引用它们。每个 URL 包含两个部分:存放对象的服务器的主机名和对象的路径名。例如,URL
{kind=link}
的主机名是 www.someSchool.edu,路径名是 /someDepartment/picture.gif。由于 Web 浏览器 (如 Internet Explorer 和 Firefox)实现了 HTTP 的客户端,因此在 Web 的上下文中,我们可以互换使用 浏览器 和 客户端 这两个词。 Web 服务器 实现了 HTTP 的服务器端,存放着 Web 对象,每个对象都可以通过一个 URL 访问。常见的 Web 服务器有 Apache 和 Microsoft Internet Information Server。
HTTP 定义了 Web 客户端如何从 Web 服务器请求网页,以及服务器如何将网页传送给客户端。我们稍后将详细讨论客户端与服务器之间的交互,但其基本思路如 图 2.6 所示。当用户请求某个网页(例如点击一个超链接)时,浏览器会向服务器发送该网页中各个对象的 HTTP 请求消息。服务器接收到请求后,回应以包含所请求对象的 HTTP 响应消息。
HTTP 使用 TCP 作为其底层传输协议(而不是运行在 UDP 之上)。HTTP 客户端首先与服务器建立一个 TCP 连接。一旦连接建立,浏览器与服务器进程就通过它们的套接字接口访问 TCP。如 第 2.1 节 所描述,客户端一侧的套接字接口是客户端进程与 TCP 连接之间的门户;服务器一侧也是服务器进程与 TCP 连接之间的门户。客户端通过套接字接口发送 HTTP 请求消息,并通过该接口接收 HTTP 响应消息。同样,HTTP 服务器通过套接字接口接收请求消息,并将响应消息发送出去。一旦客户端将消息发送到其套接字接口,该消息就不再由客户端控制,而是“交到了”TCP 手中。
回顾 第 2.1 节 中的内容,TCP 为 HTTP 提供可靠的数据传输服务。这意味着客户端进程发送的每个 HTTP 请求消息最终都会完整无误地到达服务器;同样,服务器进程发送的每个 HTTP 响应消息也最终会完整无误地到达客户端。这正体现了分层架构的一个巨大优势——HTTP 无需担心数据丢失,也无需关注 TCP 如何从网络中的数据丢失或乱序中恢复。这是 TCP 以及协议栈中较低层协议的职责。
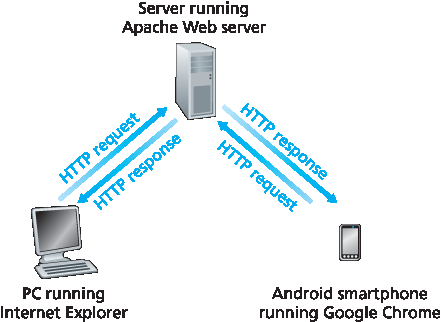
图 2.6 HTTP 请求-响应行为
需要注意的是,服务器向客户端发送所请求的文件时,不会保存任何关于该客户端的状态信息。如果某个客户端在几秒内两次请求同一个对象,服务器不会说它刚刚已经向该客户端发送过该对象,而是会重新发送该对象,因为服务器已经完全忘记了先前做过的事情。由于 HTTP 服务器不维护任何关于客户端的信息,HTTP 被称为一种 无状态协议。我们还要指出,Web 使用了客户端-服务器的应用架构,正如 第 2.1 节 中所描述。Web 服务器始终在线,拥有固定的 IP 地址,可以处理来自可能数以百万计的不同浏览器的请求。
The HyperText Transfer Protocol (HTTP), the Web’s application-layer protocol, is at the heart of the Web. It is defined in [RFC 1945] and [RFC 2616] . HTTP is implemented in two programs: a client program and a server program. The client program and server program, executing on different end systems, talk to each other by exchanging HTTP messages. HTTP defines the structure of these messages and how the client and server exchange the messages. Before explaining HTTP in detail, we should review some Web terminology.
A Web page (also called a document) consists of objects. An object is simply a file—such as an HTML file, a JPEG image, a Java applet, or a video clip—that is addressable by a single URL. Most Web pages consist of a base HTML file and several referenced objects. For example, if a Web page contains HTML text and five JPEG images, then the Web page has six objects: the base HTML file plus the five images. The base HTML file references the other objects in the page with the objects’ URLs. Each URL has two components: the hostname of the server that houses the object and the object’s path name. For example, the URL
has www.someSchool.edu for a hostname and /someDepartment/picture.gif for a path name. Because Web browsers (such as Internet Explorer and Firefox) implement the client side of HTTP, in the context of the Web, we will use the words browser and client interchangeably. Web servers, which implement the server side of HTTP, house Web objects, each addressable by a URL. Popular Web servers include Apache and Microsoft Internet Information Server.
HTTP defines how Web clients request Web pages from Web servers and how servers transfer Web pages to clients. We discuss the interaction between client and server in detail later, but the general idea is illustrated in Figure 2.6 . When a user requests a Web page (for example, clicks on a hyperlink), the browser sends HTTP request messages for the objects in the page to the server. The server receives the requests and responds with HTTP response messages that contain the objects.
HTTP uses TCP as its underlying transport protocol (rather than running on top of UDP). The HTTP client first initiates a TCP connection with the server. Once the connection is established, the browser and the server processes access TCP through their socket interfaces. As described in Section 2.1, on the client side the socket interface is the door between the client process and the TCP connection; on the server side it is the door between the server process and the TCP connection. The client sends HTTP request messages into its socket interface and receives HTTP response messages from its socket interface. Similarly, the HTTP server receives request messages from its socket interface and sends response messages into its socket interface. Once the client sends a message into its socket interface, the message is out of the client’s hands and is “in the hands” of TCP. Recall from Section 2.1 that TCP provides a reliable data transfer service to HTTP. This implies that each HTTP request message sent by a client process eventually arrives intact at the server; similarly, each HTTP response message sent by the server process eventually arrives intact at the client. Here we see one of the great advantages of a layered architecture—HTTP need not worry about lost data or the details of how TCP recovers from loss or reordering of data within the network. That is the job of TCP and the protocols in the lower layers of the protocol stack.
Figure 2.6 HTTP request-response behavior
It is important to note that the server sends requested files to clients without storing any state information about the client. If a particular client asks for the same object twice in a period of a few seconds, the server does not respond by saying that it just served the object to the client; instead, the server resends the object, as it has completely forgotten what it did earlier. Because an HTTP server maintains no information about the clients, HTTP is said to be a stateless protocol. We also remark that the Web uses the client-server application architecture, as described in Section 2.1 . A Web server is always on, with a fixed IP address, and it services requests from potentially millions of different browsers.
2.2.2 非持久连接与持久连接#
2.2.2 Non-Persistent and Persistent Connections
在许多互联网应用中,客户端与服务器之间会持续通信一段时间,客户端会发送一系列请求,服务器对每个请求作出响应。根据应用的不同以及使用方式的差异,请求可能是连续发出的、定期发出的,或是间歇性的。如果这种客户端-服务器交互是通过 TCP 进行的,那么应用开发者需要做出一个重要的决定——每对请求/响应是否应通过 不同的 TCP 连接传输,还是所有请求及其对应的响应都通过 同一个 TCP 连接传输?前者称为使用 非持久连接 的应用,后者则称为使用 持久连接 的应用。为了深入理解这个设计问题,我们将在特定应用(即 HTTP,它可以使用非持久连接也可以使用持久连接)的上下文中,分析持久连接的优缺点。尽管 HTTP 默认使用持久连接,但 HTTP 客户端与服务器也可以配置为使用非持久连接。
In many Internet applications, the client and server communicate for an extended period of time, with the client making a series of requests and the server responding to each of the requests. Depending on the application and on how the application is being used, the series of requests may be made back-to-back, periodically at regular intervals, or intermittently. When this client-server interaction is taking place over TCP, the application developer needs to make an important decision—should each request/response pair be sent over a separate TCP connection, or should all of the requests and their corresponding responses be sent over the same TCP connection? In the former approach, the application is said to use non-persistent connections; and in the latter approach, persistent connections. To gain a deep understanding of this design issue, let’s examine the advantages and disadvantages of persistent connections in the context of a specific application, namely, HTTP, which can use both non-persistent connections and persistent connections. Although HTTP uses persistent connections in its default mode, HTTP clients and servers can be configured to use non-persistent connections instead.
HTTP 使用非持久连接#
HTTP with Non-Persistent Connections
我们以非持久连接的情况,逐步演示从服务器向客户端传输网页的过程。假设该网页由一个基础 HTML 文件和 10 个 JPEG 图像组成,并且这 11 个对象都位于同一个服务器上。进一步假设基础 HTML 文件的 URL 是:
具体过程如下:
HTTP 客户端进程向服务器 www.someSchool.edu 的端口号 80 发起 TCP 连接请求,该端口号是 HTTP 的默认端口。与此 TCP 连接相关联,客户端和服务器将各自拥有一个套接字。
HTTP 客户端通过其套接字向服务器发送一个 HTTP 请求消息。该请求消息包含路径名
/someDepartment/home.index。(我们稍后将详细讨论 HTTP 消息。)HTTP 服务器进程通过其套接字接收到请求消息,从存储器(RAM 或磁盘)中取出对象
/someDepartment/home.index,将该对象封装进 HTTP 响应消息中,并通过其套接字将响应消息发送给客户端。HTTP 服务器进程通知 TCP 关闭该 TCP 连接。(但 TCP 并不会立即终止该连接,直到确定客户端已经完整接收到响应消息为止。)
HTTP 客户端接收到响应消息,TCP 连接终止。该消息表明所封装的对象是一个 HTML 文件。客户端从响应消息中提取出该文件,解析 HTML 文件,发现其中引用了 10 个 JPEG 对象。
对每个被引用的 JPEG 对象,重复前述的前四个步骤。
当浏览器接收到网页时,它会将该页面展示给用户。不同的浏览器可能以略有不同的方式解释(即向用户展示)网页。HTTP 并不涉及客户端如何解释网页。HTTP 规范([RFC 1945] 和 [RFC 2616])仅定义了客户端 HTTP 程序与服务器 HTTP 程序之间的通信协议。
上述步骤展示了非持久连接的使用方式,即服务器在发送完对象后即关闭 TCP 连接——连接不会为其他对象保持。注意每个 TCP 连接仅传输一条请求消息和一条响应消息。因此,在本例中,当用户请求该网页时,总共会建立 11 个 TCP 连接。
在上述描述中,我们有意模糊了客户端是通过 10 个串行 TCP 连接获取 JPEG 图像,还是部分图像通过并行 TCP 连接获取。事实上,用户可以配置现代浏览器以控制并行度。在默认模式下,大多数浏览器会打开 5 到 10 个并行 TCP 连接,每个连接处理一对请求-响应事务。如果用户愿意,也可以将并行连接的最大数量设置为 1,此时 10 个连接将按顺序串行建立。正如我们将在下一章看到的,并行连接的使用可以缩短响应时间。
在继续之前,我们通过一个简易计算来估算从客户端请求基础 HTML 文件到完整接收该文件之间所耗费的时间。为此,我们定义 往返时间(RTT),即一个小数据包从客户端发送到服务器再返回客户端所需的时间。RTT 包括分组传播延迟、中间路由器与交换机的排队延迟,以及分组处理延迟。(这些延迟在 第 1.4 节 中有讨论。)现在考虑当用户点击一个超链接时会发生什么。如 图 2.7 所示,这将促使浏览器与 Web 服务器之间发起 TCP 连接;这涉及一个“三次握手”过程——客户端向服务器发送一个小 TCP 段,服务器确认并响应一个小 TCP 段,最后客户端再向服务器确认。握手的前两个部分消耗一个 RTT。完成这两步后,客户端将 HTTP 请求消息与握手第三步(确认)一起通过 TCP 连接发送出去。一旦请求消息到达服务器,服务器通过 TCP 连接发送 HTML 文件。这个 HTTP 请求/响应过程又消耗一个 RTT。因此,总体响应时间大约为两个 RTT 加上服务器传输 HTML 文件所用的时间。
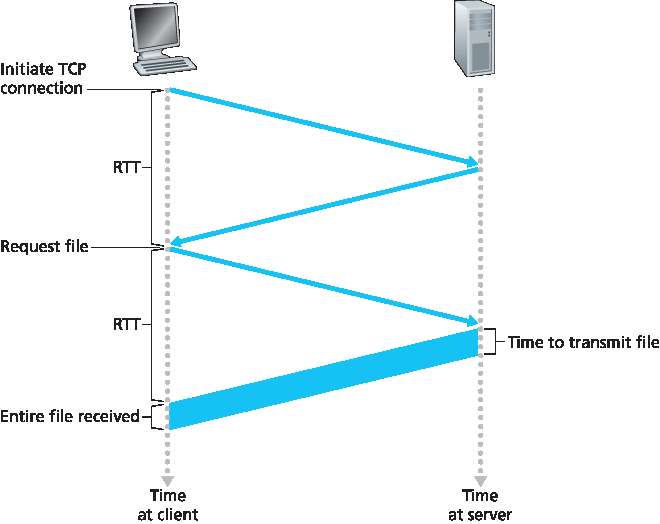
图 2.7 请求并接收 HTML 文件所需时间的简易计算
Let’s walk through the steps of transferring a Web page from server to client for the case of non- persistent connections. Let’s suppose the page consists of a base HTML file and 10 JPEG images, and that all 11 of these objects reside on the same server. Further suppose the URL for the base HTML file is
Here is what happens:
The HTTP client process initiates a TCP connection to the server www.someSchool.edu on port number 80, which is the default port number for HTTP. Associated with the TCP connection, there will be a socket at the client and a socket at the server.
The HTTP client sends an HTTP request message to the server via its socket. The request message includes the path name
/someDepartment/home.index. (We will discuss HTTP messages in some detail below.)The HTTP server process receives the request message via its socket, retrieves the object
/someDepartment/home.indexfrom its storage (RAM or disk), encapsulates the object in an HTTP response message, and sends the response message to the client via its socket.The HTTP server process tells TCP to close the TCP connection. (But TCP doesn’t actually terminate the connection until it knows for sure that the client has received the response message intact.)
5. The HTTP client receives the response message. The TCP connection terminates. The message indicates that the encapsulated object is an HTML file. The client extracts the file from the response message, examines the HTML file, and finds references to the 10 JPEG objects. 6. The first four steps are then repeated for each of the referenced JPEG objects.
As the browser receives the Web page, it displays the page to the user. Two different browsers may interpret (that is, display to the user) a Web page in somewhat different ways. HTTP has nothing to do with how a Web page is interpreted by a client. The HTTP specifications ([RFC 1945] and [RFC 2616]) define only the communication protocol between the client HTTP program and the server HTTP program.
The steps above illustrate the use of non-persistent connections, where each TCP connection is closed after the server sends the object—the connection does not persist for other objects. Note that each TCP connection transports exactly one request message and one response message. Thus, in this example, when a user requests the Web page, 11 TCP connections are generated.
In the steps described above, we were intentionally vague about whether the client obtains the 10 JPEGs over 10 serial TCP connections, or whether some of the JPEGs are obtained over parallel TCP connections. Indeed, users can configure modern browsers to control the degree of parallelism. In their default modes, most browsers open 5 to 10 parallel TCP connections, and each of these connections handles one request-response transaction. If the user prefers, the maximum number of parallel connections can be set to one, in which case the 10 connections are established serially. As we’ll see in the next chapter, the use of parallel connections shortens the response time.
Before continuing, let’s do a back-of-the-envelope calculation to estimate the amount of time that elapses from when a client requests the base HTML file until the entire file is received by the client. To this end, we define the round-trip time (RTT), which is the time it takes for a small packet to travel from client to server and then back to the client. The RTT includes packet-propagation delays, packet- queuing delays in intermediate routers and switches, and packet-processing delays. (These delays were discussed in Section 1.4 .) Now consider what happens when a user clicks on a hyperlink. As shown in Figure 2.7 , this causes the browser to initiate a TCP connection between the browser and the Web server; this involves a “three-way handshake”—the client sends a small TCP segment to the server, the server acknowledges and responds with a small TCP segment, and, finally, the client acknowledges back to the server. The first two parts of the three-way handshake take one RTT. After completing the first two parts of the handshake, the client sends the HTTP request message combined with the third part of the three-way handshake (the acknowledgment) into the TCP connection. Once the request message arrives at the server, the server sends the HTML file into the TCP connection. This HTTP request/response eats up another RTT. Thus, roughly, the total response time is two RTTs plus the transmission time at the server of the HTML file.
- align:
center
Figure 2.7 Back-of-the-envelope calculation for the time needed to request and receive an HTML file
HTTP 使用持久连接#
HTTP with Persistent Connections
非持久连接存在一些缺点。首先, 每个请求的对象都需要建立并维持一个全新的连接。每个连接都需要在客户端和服务器端分配 TCP 缓冲区、维护 TCP 变量。这会对 Web 服务器造成显著负担,特别是在其同时处理数百个客户端请求的情况下。其次,如前所述,每个对象的传输都要经历两个 RTT 的延迟——一个用于建立连接,另一个用于请求与接收对象。
在 HTTP 1.1 的持久连接中,服务器在发送响应后不会立即关闭 TCP 连接。来自同一客户端的后续请求与响应可以复用该连接。特别地,一个完整的网页(在上述示例中即基础 HTML 文件加 10 张图像)可以通过一个持久 TCP 连接传输。此外,多个驻留在同一服务器上的网页也可以通过单个持久 TCP 连接传输给同一客户端。这些对象的请求可以连续发出,无需等待先前请求的响应(称为流水线 pipelining)。通常,HTTP 服务器在连接空闲超过一定时间(可配置的超时间隔)后关闭连接。当服务器接收到连续请求时,会连续发送对象。HTTP 的默认模式使用带流水线的持久连接。最近,HTTP/2 RFC 7540 在 HTTP 1.1 的基础上进一步发展,允许多个请求与响应在同一连接中交错传输,并引入在连接中对 HTTP 消息请求与响应进行优先级排序的机制。我们将在 第 2 章 和 第 3 章 的课后习题中定量比较非持久连接与持久连接的性能表现。也建议你参考 [ Heidemann 1997;Nielsen 1997;RFC 7540 ]。
Non-persistent connections have some shortcomings. First, a brand-new connection must be established and maintained for each requested object. For each of these connections, TCP buffers must be allocated and TCP variables must be kept in both the client and server. This can place a significant burden on the Web server, which may be serving requests from hundreds of different clients simultaneously. Second, as we just described, each object suffers a delivery delay of two RTTs—one RTT to establish the TCP connection and one RTT to request and receive an object.
With HTTP 1.1 persistent connections, the server leaves the TCP connection open after sending a response. Subsequent requests and responses between the same client and server can be sent over the same connection. In particular, an entire Web page (in the example above, the base HTML file and the 10 images) can be sent over a single persistent TCP connection. Moreover, multiple Web pages residing on the same server can be sent from the server to the same client over a single persistent TCP connection. These requests for objects can be made back-to-back, without waiting for replies to pending requests (pipelining). Typically, the HTTP server closes a connection when it isn’t used for a certain time (a configurable timeout interval). When the server receives the back-to-back requests, it sends the objects back-to-back. The default mode of HTTP uses persistent connections with pipelining. Most recently, HTTP/2 [RFC 7540] builds on HTTP 1.1 by allowing multiple requests and replies to be interleaved in the same connection, and a mechanism for prioritizing HTTP message requests and replies within this connection. We’ll quantitatively compare the performance of non-persistent and persistent connections in the homework problems of Chapters 2 and 3 . You are also encouraged to see [ Heidemann 1997 ; Nielsen 1997 ; RFC 7540 ].
2.2.3 HTTP 消息格式#
2.2.3 HTTP Message Format
HTTP 规范 [ RFC 1945 ; RFC 2616 ; RFC 7540 ] 定义了 HTTP 消息格式。HTTP 消息有两种类型:请求消息和响应消息,下面分别进行讨论。
The HTTP specifications [ RFC 1945 ; RFC 2616 ; RFC 7540 ] include the definitions of the HTTP message formats. There are two types of HTTP messages, request messages and response messages, both of which are discussed below.
HTTP 请求消息#
HTTP Request Message
下面是一个典型的 HTTP 请求消息:
GET /somedir/page.html HTTP/1.1
Host: www.someschool.edu
Connection: close
User-agent: Mozilla/5.0
Accept-language: fr
通过仔细观察这个简单的请求消息,我们可以学到很多。首先,这条消息是用普通 ASCII 文本编写的,因此普通具有计算机知识的人类都可以阅读它。其次,我们看到该消息由五行组成,每行后面跟着一个回车和换行。最后一行后面还跟着额外的回车和换行。虽然这个请求消息有五行,但请求消息的行数可以更多,也可以只有一行。HTTP 请求消息的第一行称为 请求行;后续的行称为 首部行。请求行有三个字段:方法字段、URL 字段和 HTTP 版本字段。方法字段可以取多个不同的值,包括 GET、 POST、 HEAD、 PUT 和 DELETE。绝大多数 HTTP 请求消息使用 GET 方法。当浏览器请求一个对象时,使用 GET 方法,请求的对象在 URL 字段中标识。在这个示例中,浏览器请求的是对象 /somedir/page.html。版本字段无需多言;在本例中,浏览器实现的是 HTTP/1.1 版本。
现在我们来看这个示例中的首部行。首部行 Host: www.someschool.edu 指定了对象所在的主机。你可能会认为这个首部行是不必要的,因为已经有一个到主机的 TCP 连接了。但正如我们将在 第 2.2.5 节 中看到的,主机首部行所提供的信息对于 Web 代理缓存是必须的。通过包含 Connection: close 首部行,浏览器告诉服务器它不想使用持久连接;它希望服务器在发送完请求的对象后关闭连接。 User-agent: 首部行指定了用户代理,即向服务器发出请求的浏览器类型。这里的用户代理是 Mozilla/5.0,也就是 Firefox 浏览器。这个首部行很有用,因为服务器实际上可以向不同类型的用户代理发送同一个对象的不同版本。(这些版本由相同的 URL 地址标识。)最后, Accept-language: 首部表示用户希望接收该对象的法语版本,如果服务器中存在该对象的法语版本;否则服务器应发送默认版本。 Accept-language: 首部只是 HTTP 中众多内容协商首部之一。
看完这个示例后,我们再来看请求消息的一般格式,如 图 2.8 所示。我们可以看到一般格式和前面的示例非常相似。不过你可能已经注意到,在首部行(以及额外的回车换行)之后还有一个“实体主体”。使用 GET 方法时实体主体为空,但使用 POST 方法时会使用实体主体。当用户填写表单时,HTTP 客户端通常使用 POST 方法——例如,用户向搜索引擎输入搜索词。使用 POST 消息时,用户仍在请求服务器上的一个网页,但网页的具体内容依赖于用户在表单字段中输入的内容。如果方法字段的值为 POST,则实体主体中包含用户填写的表单字段内容。
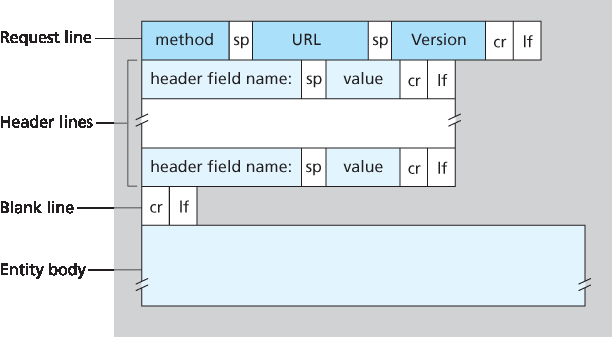
图 2.8 HTTP 请求消息的一般格式
我们如果不提一下表单生成的请求不一定使用 POST 方法,那就不全面了。实际上,HTML 表单经常使用 GET 方法,并在请求的 URL 中包含输入的数据(即表单字段)。例如,如果一个表单使用 GET 方法,有两个字段,用户输入的值为 monkeys 和 bananas,那么 URL 会具有如下结构: www.somesite.com/animalsearch?monkeys&bananas。在你日常的网页浏览中,你可能已经注意到了这种扩展 URL 的形式。
HEAD 方法与 GET 方法类似。当服务器接收到带有 HEAD 方法的请求时,它返回一个 HTTP 消息,但省略了所请求的对象。应用程序开发者通常在调试时使用 HEAD 方法。 PUT 方法通常与 Web 发布工具结合使用。它允许用户将对象上传到特定 Web 服务器的特定路径(目录)。 PUT 方法也被需要上传对象到 Web 服务器的应用程序使用。 DELETE 方法允许用户或应用程序从 Web 服务器上删除对象。
Below we provide a typical HTTP request message:
GET /somedir/page.html HTTP/1.1
Host: www.someschool.edu
Connection: close
User-agent: Mozilla/5.0
Accept-language: fr
We can learn a lot by taking a close look at this simple request message. First of all, we see that the message is written in ordinary ASCII text, so that your ordinary computer-literate human being can read it. Second, we see that the message consists of five lines, each followed by a carriage return and a line feed. The last line is followed by an additional carriage return and line feed. Although this particular request message has five lines, a request message can have many more lines or as few as one line. The first line of an HTTP request message is called the request line; the subsequent lines are called the header lines. The request line has three fields: the method field, the URL field, and the HTTP version field. The method field can take on several different values, including GET, POST, HEAD, PUT, and DELETE. The great majority of HTTP request messages use the GET method. The GET method is used when the browser requests an object, with the requested object identified in the URL field. In this example, the browser is requesting the object /somedir/page.html. The version is self- explanatory; in this example, the browser implements version HTTP/1.1.
Now let’s look at the header lines in the example. The header line Host: www.someschool.edu specifies the host on which the object resides. You might think that this header line is unnecessary, as there is already a TCP connection in place to the host. But, as we’ll see in Section 2.2.5 , the information provided by the host header line is required by Web proxy caches. By including the Connection: close header line, the browser is telling the server that it doesn’t want to bother with persistent connections; it wants the server to close the connection after sending the requested object. The User-agent: header line specifies the user agent, that is, the browser type that is making the request to the server. Here the user agent is Mozilla/5.0, a Firefox browser. This header line is useful because the server can actually send different versions of the same object to different types of user agents. (Each of the versions is addressed by the same URL.) Finally, the Accept-language: header indicates that the user prefers to receive a French version of the object, if such an object exists on the server; otherwise, the server should send its default version. The Accept-language: header is just one of many content negotiation headers available in HTTP.
Having looked at an example, let’s now look at the general format of a request message, as shown in Figure 2.8 . We see that the general format closely follows our earlier example. You may have noticed, however, that after the header lines (and the additional carriage return and line feed) there is an “entity body.” The entity body is empty with the GET method, but is used with the POST method. An HTTP client often uses the POST method when the user fills out a form—for example, when a user provides search words to a search engine. With a POST message, the user is still requesting a Web page from the server, but the specific contents of the Web page depend on what the user entered into the form fields. If the value of the method field is POST, then the entity body contains what the user entered into the form fields.
- align:
center
Figure 2.8 General format of an HTTP request message
We would be remiss if we didn’t mention that a request generated with a form does not necessarily use the POST method. Instead, HTML forms often use the GET method and include the inputted data (in the form fields) in the requested URL. For example, if a form uses the GET method, has two fields, and the inputs to the two fields are monkeys and bananas, then the URL will have the structure www.somesite.com/animalsearch?monkeys&bananas. In your day-to-day Web surfing, you have probably noticed extended URLs of this sort.
The HEAD method is similar to the GET method. When a server receives a request with the HEAD method, it responds with an HTTP message but it leaves out the requested object. Application developers often use the HEAD method for debugging. The PUT method is often used in conjunction with Web publishing tools. It allows a user to upload an object to a specific path (directory) on a specific Web server. The PUT method is also used by applications that need to upload objects to Web servers. The DELETE method allows a user, or an application, to delete an object on a Web server.
HTTP 响应消息#
HTTP Response Message
下面是一个典型的 HTTP 响应消息。该响应消息可能就是前面讨论的示例请求消息的响应。
HTTP/1.1 200 OK
Connection: close
Date: Tue, 18 Aug 2015 15:44:04 GMT
Server: Apache/2.2.3 (CentOS)
Last-Modified: Tue, 18 Aug 2015 15:11:03 GMT
Content-Length: 6821
Content-Type: text/html
(data data data data data ...)
让我们仔细看看这个响应消息。它有三个部分:一个初始的 状态行、六个 首部行,然后是 实体主体。实体主体是消息的“实质”——它包含请求的对象本身(用 data data data data data ... 表示)。状态行有三个字段:协议版本字段、状态码和对应的状态短语。在本例中,状态行表明服务器使用的是 HTTP/1.1,且一切正常(即服务器已找到并正在发送请求的对象)。
现在来看首部行。服务器使用 Connection: close 首部行告诉客户端它将在发送消息后关闭 TCP 连接。 Date: 首部行表示服务器创建并发送该 HTTP 响应的时间和日期。注意,这不是对象的创建或最后修改时间;而是服务器从其文件系统中检索对象、将其插入响应消息并发送响应的时间。 Server: 首部行表示该消息是由 Apache Web 服务器生成的;它类似于 HTTP 请求消息中的 User-agent: 首部行。 Last-Modified: 首部行表示该对象的创建或最后修改时间和日期。我们很快会更详细地讨论 Last-Modified: 首部;它对于对象缓存(无论是在本地客户端还是在网络缓存服务器中,也称为代理服务器)至关重要。 Content-Length: 首部行表示正在发送的对象的字节数。 Content-Type: 首部行表示实体主体中的对象是 HTML 文本。(对象类型是通过 Content-Type: 首部正式指定的,而不是通过文件扩展名。)
看完一个示例后,我们来看响应消息的一般格式,如 图 2.9 所示。该响应消息的一般格式与前面示例的响应消息一致。我们再简单讲几句关于状态码及其短语。状态码及其短语表明请求的结果。一些常见的状态码及其短语包括:
200 OK:请求成功,信息已在响应中返回。301 Moved Permanently:请求的对象已被永久移动;新 URL 会在响应消息的 Location: 首部中给出。客户端软件会自动获取新的 URL。400 Bad Request:这是一个通用错误码,表示服务器无法理解该请求。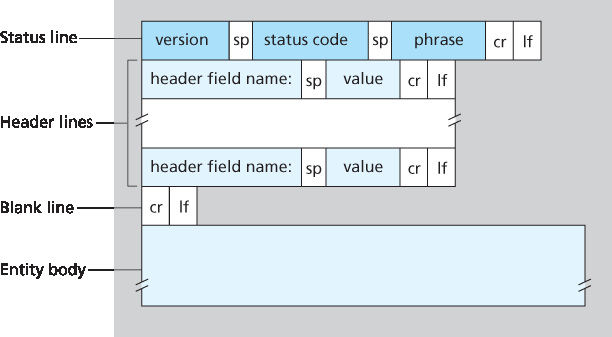
图 2.9 HTTP 响应消息的一般格式
404 Not Found:所请求的文档在服务器上不存在。505 HTTP Version Not Supported:服务器不支持所请求的 HTTP 协议版本。
你想看看真实的 HTTP 响应消息吗?强烈推荐这样做,而且非常简单!首先 Telnet 到你喜欢的 Web 服务器。然后为服务器上托管的某个对象键入一行请求消息。例如,如果你可以访问命令行提示符,请键入:

使用 Wireshark 研究 HTTP 协议
telnet gaia.cs.umass.edu 80
GET /kurose_ross/interactive/index.php HTTP/1.1
Host: gaia.cs.umass.edu
(在输入最后一行后按两次回车。)这会打开一个到主机 gaia.cs.umass.edu 的 80 端口的 TCP 连接,然后发送 HTTP 请求消息。你应该会看到一个响应消息,其中包含本教材交互式作业问题的基础 HTML 文件。如果你只想看到 HTTP 消息行而不接收对象本身,可以将 GET 替换为 HEAD。
在本节中,我们讨论了一些可以在 HTTP 请求和响应消息中使用的首部行。HTTP 规范定义了许多其他首部行,浏览器、Web 服务器和网络缓存服务器都可以插入这些首部。我们只覆盖了全部首部行中的一小部分。稍后我们会再介绍一些首部行,在 第 2.2.5 节 中讨论网络 Web 缓存时还会介绍一小部分。[Krishnamurthy 2001] 对 HTTP 协议,包括其首部和状态码,提供了一个易读而全面的讨论。
浏览器如何决定在请求消息中包含哪些首部行?Web 服务器又是如何决定在响应消息中包含哪些首部行的?浏览器会根据其类型和版本(例如 HTTP/1.0 浏览器不会生成任何 1.1 的首部行)、用户对浏览器的配置(例如偏好语言),以及浏览器是否已经缓存了该对象的过期版本,来生成首部行。Web 服务器的行为也类似:有不同的产品、版本和配置,这些都会影响响应消息中包含哪些首部行。
Below we provide a typical HTTP response message. This response message could be the response to the example request message just discussed.
HTTP/1.1 200 OK
Connection: close
Date: Tue, 18 Aug 2015 15:44:04 GMT
Server: Apache/2.2.3 (CentOS)
Last-Modified: Tue, 18 Aug 2015 15:11:03 GMT
Content-Length: 6821
Content-Type: text/html
(data data data data data ...)
Let’s take a careful look at this response message. It has three sections: an initial status line, six header lines, and then the entity body. The entity body is the meat of the message—it contains the
requested object itself (represented by data data data data data ...). The status line has three fields: the protocol version field, a status code, and a corresponding status message. In this example, the status line indicates that the server is using HTTP/1.1 and that everything is OK (that is, the server has found, and is sending, the requested object).
Now let’s look at the header lines. The server uses the Connection: close header line to tell the
client that it is going to close the TCP connection after sending the message. The Date: header line indicates the time and date when the HTTP response was created and sent by the server. Note that this is not the time when the object was created or last modified; it is the time when the server retrieves the object from its file system, inserts the object into the response message, and sends the response message. The Server: header line indicates that the message was generated by an Apache Web server; it is analogous to the User-agent: header line in the HTTP request message. The Last-Modified: header line indicates the time and date when the object was created or last modified. The Last-Modified: header, which we will soon cover in more detail, is critical for object caching, both in the local client and in network cache servers (also known as proxy servers). The Content-Length: header line indicates the number of bytes in the object being sent. The Content-Type: header line indicates that the object in the entity body is HTML text. (The object type is officially indicated by the Content-Type: header and not by the file extension.)
Having looked at an example, let’s now examine the general format of a response message, which is shown in Figure 2.9. This general format of the response message matches the previous example of a response message. Let’s say a few additional words about status codes and their phrases. The status code and associated phrase indicate the result of the request. Some common status codes and associated phrases include:
200 OK: Request succeeded and the information is returned in the response.301 Moved Permanently: Requested object has been permanently moved; the new URL is specified in Location: header of the response message. The client software will automatically retrieve the new URL.400 Bad Request: This is a generic error code indicating that the request could not be understood by the server.
Figure 2.9 General format of an HTTP response message
404 Not Found: The requested document does not exist on this server.505 HTTP Version Not Supported: The requested HTTP protocol version is not supported by the server.
How would you like to see a real HTTP response message? This is highly recommended and very easy to do! First Telnet into your favorite Web server. Then type in a one-line request message for some object that is housed on the server. For example, if you have access to a command prompt, type:
Using Wireshark to investigate the HTTP protocol
telnet gaia.cs.umass.edu 80
GET /kurose_ross/interactive/index.php HTTP/1.1
Host: gaia.cs.umass.edu
(Press the carriage return twice after typing the last line.) This opens a TCP connection to port 80 of the host gaia.cs.umass.edu and then sends the HTTP request message. You should see a response message that includes the base HTML file for the interactive homework problems for this textbook. If you’d rather just see the HTTP message lines and not receive the object itself, replace GET with HEAD.
In this section we discussed a number of header lines that can be used within HTTP request and response messages. The HTTP specification defines many, many more header lines that can be inserted by browsers, Web servers, and network cache servers. We have covered only a small number of the totality of header lines. We’ll cover a few more below and another small number when we discuss network Web caching in Section 2.2.5. A highly readable and comprehensive discussion of the HTTP protocol, including its headers and status codes, is given in [Krishnamurthy 2001].
How does a browser decide which header lines to include in a request message? How does a Web server decide which header lines to include in a response message? A browser will generate header lines as a function of the browser type and version (for example, an HTTP/1.0 browser will not generate any 1.1 header lines), the user configuration of the browser (for example, preferred language), and whether the browser currently has a cached, but possibly out-of-date, version of the object. Web servers behave similarly: There are different products, versions, and configurations, all of which influence which header lines are included in response messages.
2.2.4 用户-服务器交互:Cookie#
2.2.4 User-Server Interaction: Cookies
我们在前面提到过,HTTP 服务器是无状态的。这简化了服务器的设计,使工程师得以开发出能够处理数千个并发 TCP 连接的高性能 Web 服务器。然而,Web 站点通常希望识别用户,原因可能是服务器希望限制用户访问,或希望根据用户身份提供内容。为了实现这些目的,HTTP 使用了 cookie。Cookie 的定义见 RFC 6265,它允许网站跟踪用户。目前,大多数大型商业网站都在使用 cookie。
如 图 2.10 所示,cookie 技术包含四个组成部分:(1)HTTP 响应消息中的 cookie 首部行;(2)HTTP 请求消息中的 cookie 首部行;(3)保存在用户端系统中、由用户浏览器管理的 cookie 文件;以及(4)网站上的后端数据库。使用 图 2.10,我们来看一个 cookie 工作流程的示例。假设 Susan 总是使用她家中的 PC 和 Internet Explorer 浏览网页,她第一次访问 Amazon.com。我们再假设她过去访问过 eBay 站点。当请求到达 Amazon 的 Web 服务器时,服务器创建一个唯一的识别号,并在其后端数据库中创建一个以该识别号为索引的条目。然后,Amazon 的 Web 服务器响应 Susan 的浏览器,并在 HTTP 响应中包含一个 Set-cookie: 首部,其内容为该识别号。例如,该首部行可能是:
Set-cookie: 1678
当 Susan 的浏览器接收到 HTTP 响应消息时,它会看到 Set-cookie: 首部。浏览器随后在其管理的专用 cookie 文件中添加一行。该行包含服务器的主机名以及 Set-cookie: 首部中的识别号。请注意,由于 Susan 过去访问过 eBay,cookie 文件中已经有了 eBay 的一个条目。随着 Susan 继续浏览 Amazon 网站,每次她请求一个网页时,浏览器都会查阅其 cookie 文件,提取出该站点的识别号,并在 HTTP 请求中加入一个包含该识别号的 cookie 首部行。具体来说,她发送给 Amazon 服务器的每个 HTTP 请求中都包含如下首部行:
Set-cookie: 1678
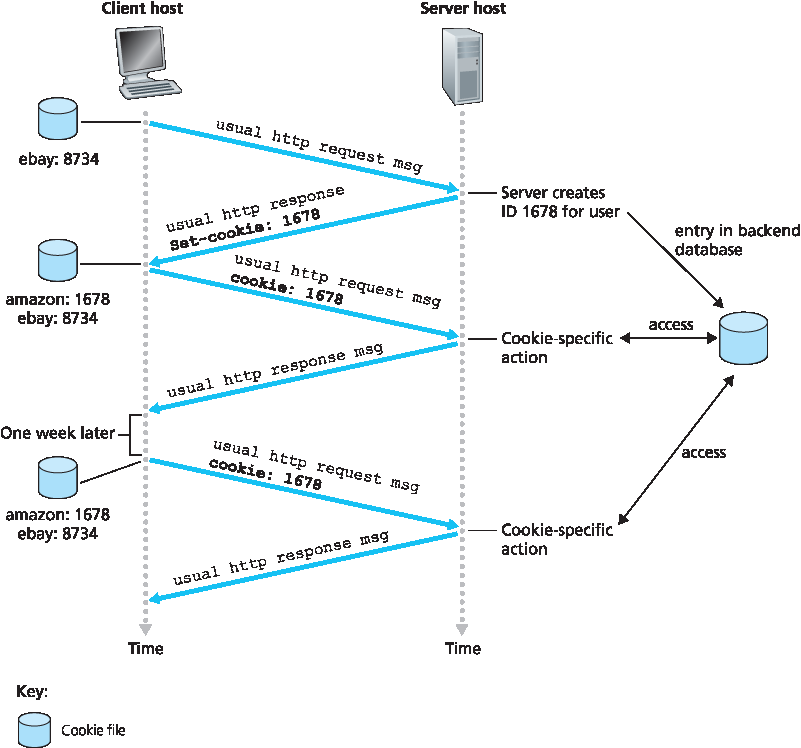
图 2.10 使用 cookie 维持用户状态
通过这种方式,Amazon 服务器能够跟踪 Susan 在 Amazon 网站上的行为。虽然 Amazon 网站不一定知道 Susan 的名字,但它清楚地知道识别号为 1678 的用户访问了哪些页面、访问顺序及访问时间!Amazon 使用 cookie 来提供其购物车服务——Amazon 可以维护一个包含 Susan 所有意向购买商品的列表,以便她可以在会话结束时统一付款。
如果 Susan 在一周后再次访问 Amazon 网站,她的浏览器仍会在请求消息中加入 Cookie: 1678 这一首部行。Amazon 还会根据她过去在 Amazon 浏览过的页面为她推荐商品。如果 Susan 在 Amazon 上注册——提供全名、电子邮件地址、邮寄地址和信用卡信息——Amazon 就可以将这些信息加入其数据库中,从而将 Susan 的姓名与其识别号(以及她过去访问的所有页面)关联起来。这就是 Amazon 和其他电子商务网站提供“一键购物”功能的方式——当 Susan 在后续访问中选择购买某商品时,无需再次输入姓名、信用卡号或地址。
从上述讨论可以看出,cookie 可用于识别用户。用户首次访问某站点时,可以提供一个用户身份(可能是姓名)。在之后的会话中,浏览器会向服务器发送一个包含 cookie 的首部,从而将用户身份传递给服务器。因而,cookie 可用于在无状态的 HTTP 之上创建用户会话层。例如,当用户登录基于 Web 的电子邮件应用(如 Hotmail)时,浏览器会将 cookie 信息发送给服务器,使服务器能够在整个用户会话期间识别该用户。
虽然 cookie 经常简化了用户的网上购物体验,但它们也引发了争议,因为 cookie 也可能被视为对隐私的侵犯。正如我们刚才看到的,通过 cookie 与用户提供的账户信息结合使用,网站可以了解很多关于用户的信息,甚至可能将这些信息出售给第三方。Cookie Central [Cookie Central 2016] 提供了关于 cookie 争议的丰富信息。
We mentioned above that an HTTP server is stateless. This simplifies server design and has permitted engineers to develop high-performance Web servers that can handle thousands of simultaneous TCP connections. However, it is often desirable for a Web site to identify users, either because the server wishes to restrict user access or because it wants to serve content as a function of the user identity. For these purposes, HTTP uses cookies. Cookies, defined in [RFC 6265], allow sites to keep track of users. Most major commercial Web sites use cookies today.
As shown in Figure 2.10 , cookie technology has four components: (1) a cookie header line in the HTTP response message; (2) a cookie header line in the HTTP request message; (3) a cookie file kept on the
user’s end system and managed by the user’s browser; and (4) a back-end database at the Web site. Using Figure 2.10 , let’s walk through an example of how cookies work. Suppose Susan, who always
accesses the Web using Internet Explorer from her home PC, contacts Amazon.com for the first time. Let us suppose that in the past she has already visited the eBay site. When the request comes into the
Amazon Web server, the server creates a unique identification number and creates an entry in its back- end database that is indexed by the identification number. The Amazon Web server then responds to
Susan’s browser, including in the HTTP response a Set-cookie: header, which contains the identification number. For example, the header line might be:
Set-cookie: 1678
When Susan’s browser receives the HTTP response message, it sees the Set-cookie: header. The browser then appends a line to the special cookie file that it manages. This line includes the hostname
of the server and the identification number in the Set-cookie: header. Note that the cookie file already has an entry for eBay, since Susan has visited that site in the past. As Susan continues to browse the Amazon site, each time she requests a Web page, her browser consults her cookie file, extracts her identification number for this site, and puts a cookie header line that includes the identification number in the HTTP request. Specifically, each of her HTTP requests to the Amazon server includes the header line:
Set-cookie: 1678
- align:
center
Figure 2.10 Keeping user state with cookies
In this manner, the Amazon server is able to track Susan’s activity at the Amazon site. Although the Amazon Web site does not necessarily know Susan’s name, it knows exactly which pages user 1678 visited, in which order, and at what times! Amazon uses cookies to provide its shopping cart service— Amazon can maintain a list of all of Susan’s intended purchases, so that she can pay for them collectively at the end of the session.
If Susan returns to Amazon’s site, say, one week later, her browser will continue to put the header line Cookie: 1678 in the request messages. Amazon also recommends products to Susan based on Web pages she has visited at Amazon in the past. If Susan also registers herself with Amazon— providing full name, e-mail address, postal address, and credit card information—Amazon can then include this information in its database, thereby associating Susan’s name with her identification number (and all of the pages she has visited at the site in the past!). This is how Amazon and other e-commerce sites provide “one-click shopping”—when Susan chooses to purchase an item during a subsequent visit, she doesn’t need to re-enter her name, credit card number, or address.
From this discussion we see that cookies can be used to identify a user. The first time a user visits a site, the user can provide a user identification (possibly his or her name). During the subsequent sessions, the browser passes a cookie header to the server, thereby identifying the user to the server. Cookies can thus be used to create a user session layer on top of stateless HTTP. For example, when a user logs in to a Web-based e-mail application (such as Hotmail), the browser sends cookie information to the server, permitting the server to identify the user throughout the user’s session with the application.
Although cookies often simplify the Internet shopping experience for the user, they are controversial because they can also be considered as an invasion of privacy. As we just saw, using a combination of cookies and user-supplied account information, a Web site can learn a lot about a user and potentially sell this information to a third party. Cookie Central [Cookie Central 2016] includes extensive information on the cookie controversy.
2.2.5 Web 缓存#
2.2.5 Web Caching
Web 缓存 (也称为 代理服务器)是一个网络实体,代表源 Web 服务器处理 HTTP 请求。Web 缓存拥有自己的磁盘存储,并在此存储中保留最近请求对象的副本。如 图 2.11 所示,用户的浏览器可以配置为使所有 HTTP 请求都首先被定向到 Web 缓存。一旦浏览器配置完成,每个浏览器对对象的请求就会首先发送到 Web 缓存。例如,假设浏览器请求对象 http://www.someschool.edu/campus.gif,其处理过程如下:
{kind=link}
浏览器建立到 Web 缓存的 TCP 连接,并将对象的 HTTP 请求发送到 Web 缓存。
Web 缓存检查它是否本地存有该对象的副本。如果有,Web 缓存通过 HTTP 响应消息将对象返回给客户端浏览器。

图 2.11 客户端通过 Web 缓存请求对象
如果 Web 缓存没有该对象,它会与源服务器(即
www.someschool.edu)建立一个 TCP 连接。然后 Web 缓存在该连接上向服务器发送对象的 HTTP 请求。收到请求后,源服务器通过 HTTP 响应将对象发送给 Web 缓存。Web 缓存收到对象后,会在其本地存储中保存一份副本,并通过现有的客户端浏览器与 Web 缓存之间的 TCP 连接,在 HTTP 响应消息中将副本发送给客户端浏览器。
注意,缓存同时是服务器和客户端:当它接收来自浏览器的请求并发送响应时,它是服务器;当它向源服务器发送请求并接收响应时,它是客户端。
Web 缓存通常由 ISP 购买并安装。例如,一所大学可能会在其校园网络中安装一个缓存,并配置校园内所有浏览器指向该缓存。又如,一个大型住宅 ISP(如 Comcast)可能会在其网络中安装一个或多个缓存,并预先配置其出厂浏览器指向已安装的缓存。
Web 缓存在互联网中被广泛部署有两个原因。首先,当客户端与源服务器之间的瓶颈带宽远小于客户端与缓存之间的瓶颈带宽时,Web 缓存可以显著减少客户端请求的响应时间。如果客户端与缓存之间是高速连接,且缓存中已有所请求对象,缓存可以快速将其交付给客户端。其次,正如我们稍后将通过示例说明的,Web 缓存可以大大减少机构访问互联网链路上的流量。通过降低流量,机构(例如公司或大学)可以延迟带宽升级,从而降低成本。此外,Web 缓存还能显著减少整个互联网中的 Web 流量,从而提高所有应用的性能。
为了更深入理解缓存的好处,我们来看 图 2.12 中的示例。该图显示两个网络 —— 一个是机构网络,一个是公共互联网的其余部分。机构网络是一个高速 LAN。机构网络中的一个路由器与互联网中的另一个路由器通过一个 15 Mbps 的链路连接。源服务器连接到互联网,分布在全球各地。假设平均对象大小为 1 Mbits,机构浏览器向源服务器的平均请求速率为每秒 15 个请求。假设 HTTP 请求消息非常小,在网络和接入链路中不产生任何流量。此外,假设如 图 2.12 中,从互联网侧路由器转发 HTTP 请求(在 IP 数据报中)到收到响应(通常是多个 IP 数据报)平均需要 2 秒钟。我们将这个延迟非正式地称为“互联网延迟”。
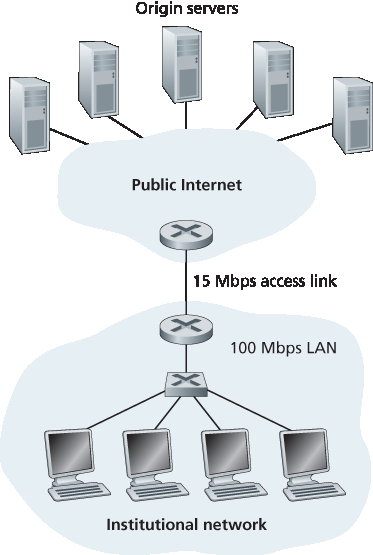
图 2.12 机构网络与互联网之间的瓶颈
总响应时间 —— 即从浏览器请求对象到接收对象的时间 —— 等于 LAN 延迟、接入延迟(即两个路由器之间的延迟)和互联网延迟之和。我们现在来做一个粗略计算以估计这个延迟。LAN 上的流量强度(参见 第 1.4.2 节)为:
(15 请求/秒) ⋅ (1 Mbits/请求) / (100 Mbps) = 0.15
而接入链路(从互联网路由器到机构路由器)的流量强度为:
(15 请求/秒) ⋅ (1 Mbits/请求) / (15 Mbps) = 1
LAN 上的流量强度为 0.15,通常导致的延迟最多为几十毫秒,因此我们可以忽略 LAN 延迟。然而,如 第 1.4.2 节 所述,当流量强度接近 1 时(如 图 2.12 中的接入链路),该链路的延迟会非常大,并趋于无穷。因此,满足请求的平均响应时间将达到数分钟,甚至更长,这对于机构用户是不可接受的。显然必须采取措施。
一种可能的解决方案是将接入速率从 15 Mbps 提升到 100 Mbps。这将使接入链路的流量强度降低到 0.15,从而将两个路由器之间的延迟降至可忽略的水平。在这种情况下,总响应时间大约为 2 秒,即互联网延迟。但这种解决方案要求机构将接入链路从 15 Mbps 升级到 100 Mbps,代价昂贵。
现在考虑另一种解决方案:不升级接入链路,而是在机构网络中安装 Web 缓存。该解决方案如 图 2.13 所示。命中率 —— 即缓存满足的请求占比 —— 在实际中通常为 0.2 到 0.7。为了举例,假设该机构的缓存命中率为 0.4。由于客户端与缓存连接在同一个高速 LAN 上,40% 的请求将几乎立即(例如在 10 毫秒内)被缓存满足。然而,剩下的 60% 请求仍需由源服务器满足。但由于只有 60% 的对象经过接入链路,接入链路的流量强度将从 1.0 降至 0.6。通常,低于 0.8 的流量强度意味着在 15 Mbps 链路上延迟较小,例如几十毫秒。与 2 秒的互联网延迟相比,这种延迟可以忽略。因此,平均延迟为:
0.4 ⋅ (0.01 秒) + 0.6 ⋅ (2.01 秒)
约为 1.2 秒,略低于第一种方案,而且无需将机构链路升级至互联网。当然,机构必须购买并安装 Web 缓存。但这一成本较低 —— 许多缓存使用运行在廉价 PC 上的公共领域软件。
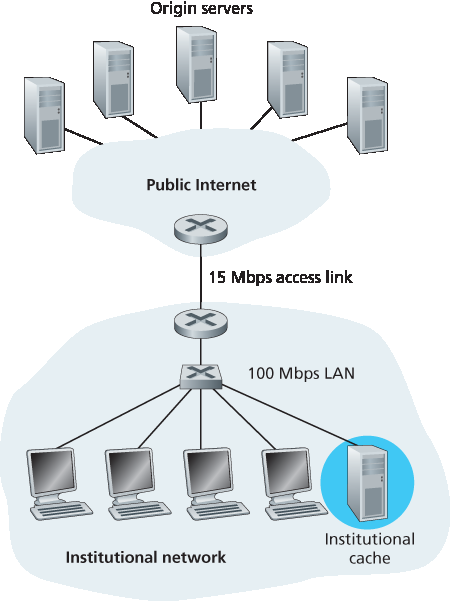
图 2.13 向机构网络添加缓存
通过使用 内容分发网络(CDN),Web 缓存在互联网中的作用越来越重要。CDN 公司在互联网中广泛分布地部署了大量缓存,从而实现流量本地化。CDN 分为共享 CDN(如 Akamai 和 Limelight)和专用 CDN(如 Google 和 Netflix)。我们将在 第 2.6 节 中更详细地讨论 CDN。
A Web cache — also called a proxy server — is a network entity that satisfies HTTP requests on the behalf of an origin Web server. The Web cache has its own disk storage and keeps copies of recently requested objects in this storage. As shown in Figure 2.11 , a user’s browser can be configured so that all of the user’s HTTP requests are first directed to the Web cache. Once a browser is configured, each browser request for an object is first directed to the Web cache. As an example, suppose a browser is requesting the object http://www.someschool.edu/campus.gif. Here is what happens:
The browser establishes a TCP connection to the Web cache and sends an HTTP request for the object to the Web cache.
The Web cache checks to see if it has a copy of the object stored locally. If it does, the Web cache returns the object within an HTTP response message to the client browser.
Figure 2.11 Clients requesting objects through a Web cache
If the Web cache does not have the object, the Web cache opens a TCP connection to the origin server, that is, to www.someschool.edu <http://www.someschool.edu> . The Web cache then sends an HTTP request for the object into the cache-to-server TCP connection. After receiving this request, the origin server sends the object within an HTTP response to the Web cache.
When the Web cache receives the object, it stores a copy in its local storage and sends a copy, within an HTTP response message, to the client browser (over the existing TCP connection between the client browser and the Web cache).
Note that a cache is both a server and a client at the same time. When it receives requests from and sends responses to a browser, it is a server. When it sends requests to and receives responses from an origin server, it is a client.
Typically a Web cache is purchased and installed by an ISP. For example, a university might install a cache on its campus network and configure all of the campus browsers to point to the cache. Or a major residential ISP (such as Comcast) might install one or more caches in its network and preconfigure its shipped browsers to point to the installed caches.
Web caching has seen deployment in the Internet for two reasons. First, a Web cache can substantially reduce the response time for a client request, particularly if the bottleneck bandwidth between the client and the origin server is much less than the bottleneck bandwidth between the client and the cache. If there is a high-speed connection between the client and the cache, as there often is, and if the cache has the requested object, then the cache will be able to deliver the object rapidly to the client. Second, as we will soon illustrate with an example, Web caches can substantially reduce traffic on an institution’s access link to the Internet. By reducing traffic, the institution (for example, a company or a university) does not have to upgrade bandwidth as quickly, thereby reducing costs. Furthermore, Web caches can substantially reduce Web traffic in the Internet as a whole, thereby improving performance for all applications.
To gain a deeper understanding of the benefits of caches, let’s consider an example in the context of Figure 2.12 . This figure shows two networks—the institutional network and the rest of the public Internet. The institutional network is a high-speed LAN. A router in the institutional network and a router in the Internet are connected by a 15 Mbps link. The origin servers are attached to the Internet but are located all over the globe. Suppose that the average object size is 1 Mbits and that the average request rate from the institution’s browsers to the origin servers is 15 requests per second. Suppose that the HTTP request messages are negligibly small and thus create no traffic in the networks or in the access link (from institutional router to Internet router). Also suppose that the amount of time it takes from when the router on the Internet side of the access link in Figure 2.12 forwards an HTTP request (within an IP datagram) until it receives the response (typically within many IP datagrams) is two seconds on average. Informally, we refer to this last delay as the “Internet delay.”
Figure 2.12 Bottleneck between an institutional network and the Internet
The total response time—that is, the time from the browser’s request of an object until its receipt of the object—is the sum of the LAN delay, the access delay (that is, the delay between the two routers), and the Internet delay. Let’s now do a very crude calculation to estimate this delay. The traffic intensity on the LAN (see Section 1.4.2 ) is
(15 requests/sec)⋅(1 Mbits/request)/(100 Mbps)=0.15
whereas the traffic intensity on the access link (from the Internet router to institution router) is
(15 requests/sec)⋅(1 Mbits/request)/(15 Mbps)=1
A traffic intensity of 0.15 on a LAN typically results in, at most, tens of milliseconds of delay; hence, we can neglect the LAN delay. However, as discussed in Section 1.4.2 , as the traffic intensity approaches 1 (as is the case of the access link in Figure 2.12), the delay on a link becomes very large and grows without bound. Thus, the average response time to satisfy requests is going to be on the order of minutes, if not more, which is unacceptable for the institution’s users. Clearly something must be done.
One possible solution is to increase the access rate from 15 Mbps to, say, 100 Mbps. This will lower the traffic intensity on the access link to 0.15, which translates to negligible delays between the two routers. In this case, the total response time will roughly be two seconds, that is, the Internet delay. But this solution also means that the institution must upgrade its access link from 15 Mbps to 100 Mbps, a costly proposition.
Now consider the alternative solution of not upgrading the access link but instead installing a Web cache in the institutional network. This solution is illustrated in Figure 2.13. Hit rates—the fraction of requests that are satisfied by a cache— typically range from 0.2 to 0.7 in practice. For illustrative purposes, let’s suppose that the cache provides a hit rate of 0.4 for this institution. Because the clients and the cache are connected to the same high-speed LAN, 40 percent of the requests will be satisfied almost immediately, say, within 10 milliseconds, by the cache. Nevertheless, the remaining 60 percent of the requests still need to be satisfied by the origin servers. But with only 60 percent of the requested objects passing through the access link, the traffic intensity on the access link is reduced from 1.0 to 0.6. Typically, a traffic intensity less than 0.8 corresponds to a small delay, say, tens of milliseconds, on a 15 Mbps link. This delay is negligible compared with the two-second Internet delay. Given these considerations, average delay therefore is
0.4⋅(0.01 seconds)+0.6⋅(2.01 seconds)
which is just slightly greater than 1.2 seconds. Thus, this second solution provides an even lower response time than the first solution, and it doesn’t require the institution to upgrade its link to the Internet. The institution does, of course, have to purchase and install a Web cache. But this cost is low—many caches use public-domain software that runs on inexpensive PCs.
Figure 2.13 Adding a cache to the institutional network
Through the use of Content Distribution Networks (CDNs), Web caches are increasingly playing an important role in the Internet. A CDN company installs many geographically distributed caches throughout the Internet, thereby localizing much of the traffic. There are shared CDNs (such as Akamai and Limelight) and dedicated CDNs (such as Google and Netflix). We will discuss CDNs in more detail in Section 2.6.
条件 GET#
The Conditional GET
尽管缓存可以减少用户感知的响应时间,但它引入了一个新问题 —— 缓存中的对象副本可能是过期的。换句话说,Web 服务器上的对象可能在客户端缓存该副本后已被修改。幸运的是,HTTP 提供了一种机制,允许缓存验证其对象是否是最新的。该机制称为 条件 GET(conditional GET)。
如果一个 HTTP 请求消息同时满足以下两点,则称其为条件 GET 消息:(1)请求方法为 GET;(2)请求消息包含 If-Modified-Since: 首部行。
我们通过一个示例说明条件 GET 的工作过程。首先,代理缓存代表请求的浏览器向 Web 服务器发送请求消息:
GET /fruit/kiwi.gif HTTP/1.1
Host: www.exotiquecuisine.com
接着,Web 服务器将所请求对象连同响应消息发送给缓存:
HTTP/1.1 200 OK
Date: Sat, 3 Oct 2015 15:39:29
Server: Apache/1.3.0 (Unix)
Last-Modified: Wed, 9 Sep 2015 09:23:24
Content-Type: image/gif
(data data data data data ...)
缓存将对象转发给请求浏览器,并在本地缓存该对象。重要的是,缓存还将该对象的 last-modified 日期一同存储。一周后,另一浏览器通过缓存请求相同对象,且该对象仍在缓存中。由于该对象可能在过去一周中已被修改,缓存通过发出条件 GET 检查其是否仍是最新的。具体来说,缓存发送如下请求:
GET /fruit/kiwi.gif HTTP/1.1
Host: www.exotiquecuisine.com
If-modified-since: Wed, 9 Sep 2015 09:23:24
注意,If-modified-since: 首部行的值与服务器一周前发送的 Last-Modified: 首部行值完全一致。该条件 GET 意思是:仅当对象自指定日期以来被修改过,才将其发送。假设该对象自 2015 年 9 月 9 日 09:23:24 以来未被修改,则 Web 服务器将向缓存发送如下响应消息:
HTTP/1.1 304 Not Modified
Date: Sat, 10 Oct 2015 15:39:29
Server: Apache/1.3.0 (Unix)
(空实体主体)
可见,响应条件 GET 时,Web 服务器仍发送响应消息,但不包含所请求对象。包含该对象只会浪费带宽,并增加用户感知的响应时间,特别是对象较大时。注意,该响应消息状态行为 304 Not Modified,表示缓存可以直接将其本地副本发送给请求浏览器。
本节是我们对 HTTP 的讨论的结尾。HTTP 是我们深入学习的第一个互联网协议(应用层协议)。我们了解了 HTTP 消息的格式,以及 Web 客户端与服务器在发送和接收这些消息时所执行的操作。我们还研究了一些 Web 应用基础架构内容,包括缓存、cookie 和后端数据库,这些都与 HTTP 协议密切相关。
Although caching can reduce user-perceived response times, it introduces a new problem—the copy of an object residing in the cache may be stale. In other words, the object housed in the Web server may have been modified since the copy was cached at the client. Fortunately, HTTP has a mechanism that allows a cache to verify that its objects are up to date. This mechanism is called the conditional GET.
An HTTP request message is a so-called conditional GET message if (1) the request message uses the GET method and (2) the request message includes an If-Modified-Since: header line.
To illustrate how the conditional GET operates, let’s walk through an example. First, on the behalf of a requesting browser, a proxy cache sends a request message to a Web server:
GET /fruit/kiwi.gif HTTP/1.1
Host: www.exotiquecuisine.com
Second, the Web server sends a response message with the requested object to the cache:
HTTP/1.1 200 OK
Date: Sat, 3 Oct 2015 15:39:29
Server: Apache/1.3.0 (Unix)
Last-Modified: Wed, 9 Sep 2015 09:23:24
Content-Type: image/gif
(data data data data data ...)
The cache forwards the object to the requesting browser but also caches the object locally. Importantly, the cache also stores the last-modified date along with the object. Third, one week later, another browser requests the same object via the cache, and the object is still in the cache. Since this object may have been modified at the Web server in the past week, the cache performs an up-to-date check by issuing a conditional GET. Specifically, the cache sends:
GET /fruit/kiwi.gif HTTP/1.1
Host: www.exotiquecuisine.com
If-modified-since: Wed, 9 Sep 2015 09:23:24
Note that the value of the If-modified-since: header line is exactly equal to the value of the
Last-Modified: header line that was sent by the server one week ago. This conditional GET is telling the server to send the object only if the object has been modified since the specified date. Suppose the object has not been modified since 9 Sep 2015 09:23:24. Then, fourth, the Web server sends a response message to the cache:
HTTP/1.1 304 Not Modified
Date: Sat, 10 Oct 2015 15:39:29
Server: Apache/1.3.0 (Unix)
(empty entity body)
We see that in response to the conditional GET, the Web server still sends a response message but does not include the requested object in the response message. Including the requested object would only waste bandwidth and increase user-perceived response time, particularly if the object is large. Note
that this last response message has 304 Not Modified in the status line, which tells the cache that it can go ahead and forward its (the proxy cache’s) cached copy of the object to the requesting browser.
This ends our discussion of HTTP, the first Internet protocol (an application-layer protocol) that we’ve studied in detail. We’ve seen the format of HTTP messages and the actions taken by the Web client and server as these messages are sent and received. We’ve also studied a bit of the Web’s application infrastructure, including caches, cookies, and back-end databases, all of which are tied in some way to the HTTP protocol.