2.6 视频流与内容分发#
2.6 Video Streaming and Content Distribu
2.6.1 互联网视频#
2.6.1 Internet Video
流式传输预录制视频如今已占据北美住宅 ISP 流量的主要部分。特别是,Netflix 和 YouTube 两项服务在 2015 年分别消耗了住宅 ISP 流量的惊人比例——37% 和 16% [Sandvine 2015]。在本节中,我们将概述当前互联网上流行的视频流媒体服务的实现方式。我们将看到,它们是使用应用层协议和在某些方面类似于缓存的服务器来实现的。在专门讨论多媒体网络的 第 9 章 中,我们将进一步研究互联网视频及其他互联网多媒体服务。
在流式传输存储视频的应用中,其底层介质是预录制的视频,如电影、电视节目、预录制的体育赛事或用户生成的预录制视频(例如 YouTube 上常见的视频)。这些预录制视频被放置在服务器上,用户向服务器发送请求以按需观看这些视频。如今许多互联网公司都提供视频流服务,包括 Netflix、YouTube(Google)、Amazon 和优酷等。
但在讨论视频流之前,我们应首先快速了解视频媒介本身。视频是一系列图像,通常以恒定速率显示,例如每秒 24 或 30 帧。未压缩的、数字编码的图像由像素数组构成,每个像素被编码为若干比特以表示亮度和颜色。视频的一个重要特性是其可被压缩,从而在视频质量和比特率之间进行权衡。如今的现成压缩算法可以将视频压缩到几乎任意的比特率。当然,比特率越高,图像质量越好,整体观看体验也越佳。
从网络角度看,视频最显著的特征也许就是其高比特率。压缩后的互联网视频通常从低质量视频的 100 kbps 到高清电影流的 3 Mbps 以上不等;4K 流媒体设想的比特率超过 10 Mbps。这可能转化为巨大流量和存储开销,尤其对于高端视频而言。例如,一段时长为 67 分钟、比特率为 2 Mbps 的视频将消耗 1 GB 的存储空间和流量。对视频流而言,最重要的性能指标是平均端到端吞吐量。为了实现连续播放,网络必须为流媒体应用提供至少与压缩视频比特率相当的平均吞吐量。
我们还可以使用压缩技术创建同一视频的多个版本,每个版本对应不同的质量等级。例如,我们可以使用压缩创建三个版本,分别为 300 kbps、1 Mbps 和 3 Mbps。用户可以根据当前可用带宽选择希望观看的版本。网络连接速度较快的用户可能选择 3 Mbps 版本;使用 3G 网络观看的智能手机用户可能选择 300 kbps 版本。
Streaming prerecorded video now accounts for the majority of the traffic in residential ISPs in North America. In particular, the Netflix and YouTube services alone consumed a whopping 37% and 16%, respectively, of residential ISP traffic in 2015 [Sandvine 2015]. In this section we will provide an overview of how popular video streaming services are implemented in today’s Internet. We will see they are implemented using application-level protocols and servers that function in some ways like a cache. In Chapter 9, devoted to multimedia networking, we will further examine Internet video as well as other Internet multimedia services.
In streaming stored video applications, the underlying medium is prerecorded video, such as a movie, a television show, a prerecorded sporting event, or a prerecorded user-generated video (such as those commonly seen on YouTube). These prerecorded videos are placed on servers, and users send requests to the servers to view the videos on demand. Many Internet companies today provide streaming video, including, Netflix, YouTube (Google), Amazon, and Youku. But before launching into a discussion of video streaming, we should first get a quick feel for the video medium itself. A video is a sequence of images, typically being displayed at a constant rate, for example, at 24 or 30 images per second. An uncompressed, digitally encoded image consists of an array of pixels, with each pixel encoded into a number of bits to represent luminance and color. An important characteristic of video is that it can be compressed, thereby trading off video quality with bit rate. Today’s off-the-shelf compression algorithms can compress a video to essentially any bit rate desired. Of course, the higher the bit rate, the better the image quality and the better the overall user viewing experience.
From a networking perspective, perhaps the most salient characteristic of video is its high bit rate. Compressed Internet video typically ranges from 100 kbps for low-quality video to over 3 Mbps for streaming high-definition movies; 4K streaming envisions a bitrate of more than 10 Mbps. This can translate to huge amount of traffic and storage, particularly for high-end video. For example, a single 2 Mbps video with a duration of 67 minutes will consume 1 gigabyte of storage and traffic. By far, the most important performance measure for streaming video is average end-to-end throughput. In order to provide continuous playout, the network must provide an average throughput to the streaming application that is at least as large as the bit rate of the compressed video.
We can also use compression to create multiple versions of the same video, each at a different quality level. For example, we can use compression to create, say, three versions of the same video, at rates of 300 kbps, 1 Mbps, and 3 Mbps. Users can then decide which version they want to watch as a function of their current available bandwidth. Users with high-speed Internet connections might choose the 3 Mbps version; users watching the video over 3G with a smartphone might choose the 300 kbps version.
2.6.2 HTTP 流媒体与 DASH#
2.6.2 HTTP Streaming and DASH
在 HTTP 流媒体中,视频只是作为带有特定 URL 的普通文件存储在 HTTP 服务器上。当用户想要观看视频时,客户端会与服务器建立 TCP 连接,并对该 URL 发出 HTTP GET 请求。然后,服务器在 HTTP 响应消息中尽可能快地发送视频文件,具体速度受底层网络协议和网络拥塞情况限制。在客户端,字节被收集到一个客户端应用程序缓冲区中。一旦该缓冲区中的字节数量超过预设阈值,客户端应用程序就开始播放——具体地,流媒体视频应用周期性地从缓冲区中抓取视频帧、解压这些帧,并将其显示在用户屏幕上。因此,视频流应用在接收和缓冲后续帧的同时播放视频。
尽管上述 HTTP 流媒体在实践中被广泛部署(例如 YouTube 自诞生以来一直使用该方式),但它存在一个主要缺陷:所有客户端接收到的视频编码版本相同,尽管不同客户端之间以及同一客户端在不同时间的可用带宽差异巨大。为了解决这个问题,发展出一种基于 HTTP 的新型流媒体方式,通常被称为 基于 HTTP 的动态自适应流媒体(DASH)。在 DASH 中,视频被编码为多个版本,每个版本具有不同的比特率,相应地也具有不同的质量等级。客户端动态请求时长为几秒的视频分段块。当可用带宽较高时,客户端自然选择高比特率版本的块;当可用带宽较低时,客户端自然选择低比特率版本的块。客户端通过 HTTP GET 请求消息一次请求一个不同的块 [Akhshabi 2011]。
DASH 允许拥有不同互联网接入速率的客户端以不同编码速率观看视频。使用低速 3G 网络连接的客户端可以接收低比特率(低质量)版本,而使用光纤连接的客户端则可以接收高质量版本。如果在会话期间可用的端到端带宽发生变化,DASH 也允许客户端进行自适应调整。该特性对移动用户尤为重要,因为他们的可用带宽通常会随其与基站的位置变化而波动。
在 DASH 中,每个视频版本都以不同的 URL 存储在 HTTP 服务器中。HTTP 服务器还包含一个 清单文件(manifest file),其中包含每个版本的 URL 及其比特率。客户端首先请求清单文件,从中了解各个版本的信息。然后,客户端通过在每次 HTTP GET 请求中指定 URL 和字节范围来一次选择一个块。在下载块的同时,客户端还会测量接收带宽,并运行速率决策算法,以确定下一次要请求的块。显然,如果客户端已缓冲大量视频并且测得的接收带宽较高,则会选择高比特率版本的块;反之,如果客户端缓冲较少且接收带宽较低,则会选择低比特率版本的块。因此,DASH 允许客户端在不同质量等级之间自由切换。
In HTTP streaming, the video is simply stored at an HTTP server as an ordinary file with a specific URL. When a user wants to see the video, the client establishes a TCP connection with the server and issues an HTTP GET request for that URL. The server then sends the video file, within an HTTP response message, as quickly as the underlying network protocols and traffic conditions will allow. On the client side, the bytes are collected in a client application buffer. Once the number of bytes in this buffer exceeds a predetermined threshold, the client application begins playback—specifically, the streaming video application periodically grabs video frames from the client application buffer, decompresses the frames, and displays them on the user’s screen. Thus, the video streaming application is displaying video as it is receiving and buffering frames corresponding to latter parts of the video.
Although HTTP streaming, as described in the previous paragraph, has been extensively deployed in practice (for example, by YouTube since its inception), it has a major shortcoming: All clients receive the same encoding of the video, despite the large variations in the amount of bandwidth available to a client, both across different clients and also over time for the same client. This has led to the development of a new type of HTTP-based streaming, often referred to as Dynamic Adaptive Streaming over HTTP (DASH). In DASH, the video is encoded into several different versions, with each version having a different bit rate and, correspondingly, a different quality level. The client dynamically requests chunks of video segments of a few seconds in length. When the amount of available bandwidth is high, the client naturally selects chunks from a high-rate version; and when the available bandwidth is low, it naturally selects from a low-rate version. The client selects different chunks one at a time with HTTP GET request messages [Akhshabi 2011].
DASH allows clients with different Internet access rates to stream in video at different encoding rates. Clients with low-speed 3G connections can receive a low bit-rate (and low-quality) version, and clients with fiber connections can receive a high-quality version. DASH also allows a client to adapt to the available bandwidth if the available end-to-end bandwidth changes during the session. This feature is particularly important for mobile users, who typically see their bandwidth availability fluctuate as they move with respect to the base stations.
With DASH, each video version is stored in the HTTP server, each with a different URL. The HTTP server also has a manifest file, which provides a URL for each version along with its bit rate. The client first requests the manifest file and learns about the various versions. The client then selects one chunk at a time by specifying a URL and a byte range in an HTTP GET request message for each chunk. While downloading chunks, the client also measures the received bandwidth and runs a rate determination algorithm to select the chunk to request next. Naturally, if the client has a lot of video buffered and if the measured receive bandwidth is high, it will choose a chunk from a high-bitrate version. And naturally if the client has little video buffered and the measured received bandwidth is low, it will choose a chunk from a low-bitrate version. DASH therefore allows the client to freely switch among different quality levels.
2.6.3 内容分发网络#
2.6.3 Content Distribution Networks
如今,许多互联网视频公司每天都向数百万用户分发按需多 Mbps 的流。以 YouTube 为例,它拥有数亿个视频,每天向全球用户分发数亿个视频流。将如此庞大的流量传送到世界各地,同时确保连续播放和高交互性,无疑是一项挑战性任务。
对于互联网视频公司来说,或许最直接的流媒体服务提供方式是建立一个超大型数据中心,将所有视频存储在该数据中心中,并直接从数据中心向全球客户端进行视频流传输。但该方式存在三大主要问题。首先,如果客户端离数据中心较远,服务器到客户端的数据包将跨越许多通信链路,并可能穿越多个 ISP,其中一些 ISP 甚至位于不同的大洲。如果这些链路中有一条的吞吐量低于视频消费速率,那么端到端吞吐量也会低于消费速率,导致用户观看过程中出现令人恼火的卡顿(回顾 第 1 章 所述,流的端到端吞吐量受限于瓶颈链路的吞吐量)。端到端路径中链路数量越多,发生此类问题的可能性就越大。第二个缺点是,一段热门视频可能会在同一通信链路上传输多次。这不仅浪费网络带宽,而且互联网视频公司还需向其接入 ISP(连接至数据中心)反复支付相同字节的传输费用。第三个问题是单个数据中心构成了单点故障——如果数据中心或其与互联网的连接发生故障,将无法分发任何视频流。
为了应对向全球分布的用户分发海量视频数据的挑战,几乎所有主流视频流公司都采用了 内容分发网络(CDN)。CDN 在多个地理位置分布式部署服务器,存储视频副本(以及其他类型的 Web 内容,包括文档、图像和音频),并尝试将每个用户请求定向到能提供最佳用户体验的 CDN 节点。CDN 可能是 私有 CDN,即由内容提供方自行拥有;例如,Google 的 CDN 分发 YouTube 视频及其他内容。CDN 也可能是 第三方 CDN,代表多个内容提供方分发内容;Akamai、Limelight 和 Level-3 都运营第三方 CDN。关于现代 CDN 的概述,请参考 [ Leighton 2009;Nygren 2010]。
CDN 通常采取两种不同的服务器部署策略 [Huang 2008]:
深入接入网(Enter Deep)。这一策略由 Akamai 首创,即深入互联网服务提供商的接入网络,在全球的接入 ISP 中部署服务器集群。(接入网络的相关内容见 第 1.3 节。)Akamai 采用这一策略,在大约 1,700 个地点部署集群。其目标是靠近终端用户,从而通过减少用户与 CDN 服务器之间的链路和路由器数量来提升用户感知的延迟和吞吐量。由于其高度分布式的设计,维护和管理这些集群的任务变得极具挑战性。
集中核心(Bring Home)。第二种策略由 Limelight 及其他 CDN 公司采用,即通过在较少(例如几十个)地点构建大型集群,将 ISP “集中到家”。这些 CDN 并不进入接入 ISP,而是通常将集群部署在互联网交换点(IXPs)(参见 第 1.3 节)。与“深入接入网”策略相比,“集中核心”策略通常具有更低的维护和管理开销,但可能会带来更高的延迟和更低的终端用户吞吐量。
一旦集群部署完成,CDN 会在各个集群之间复制内容。CDN 并不一定将每个视频副本放置到所有集群中,因为有些视频几乎无人观看,或仅在某些国家/地区受欢迎。实际上,许多 CDN 并不会主动将视频推送到集群,而是采用简单的拉取策略:如果客户端向一个未存储该视频的集群请求视频,该集群会从中央仓库或其他集群中获取该视频,同时一边将视频流传输给客户端,一边在本地存储一份副本。类似于 Web 缓存机制(参见 第 2.2.5 节),当集群存储空间已满时,它会移除不常请求的视频。
Today, many Internet video companies are distributing on-demand multi-Mbps streams to millions of users on a daily basis. YouTube, for example, with a library of hundreds of millions of videos, distributes hundreds of millions of video streams to users around the world every day. Streaming all this traffic to locations all over the world while providing continuous playout and high interactivity is clearly a challenging task.
For an Internet video company, perhaps the most straightforward approach to providing streaming video service is to build a single massive data center, store all of its videos in the data center, and stream the videos directly from the data center to clients worldwide. But there are three major problems with this approach. First, if the client is far from the data center, server-to-client packets will cross many communication links and likely pass through many ISPs, with some of the ISPs possibly located on different continents. If one of these links provides a throughput that is less than the video consumption rate, the end-to-end throughput will also be below the consumption rate, resulting in annoying freezing delays for the user. (Recall from Chapter 1 that the end-to-end throughput of a stream is governed by the throughput at the bottleneck link.) The likelihood of this happening increases as the number of links in the end-to-end path increases. A second drawback is that a popular video will likely be sent many times over the same communication links. Not only does this waste network bandwidth, but the Internet video company itself will be paying its provider ISP (connected to the data center) for sending the same bytes into the Internet over and over again. A third problem with this solution is that a single data center represents a single point of failure—if the data center or its links to the Internet goes down, it would not be able to distribute any video streams.
In order to meet the challenge of distributing massive amounts of video data to users distributed around the world, almost all major video-streaming companies make use of Content Distribution Networks (CDNs). A CDN manages servers in multiple geographically distributed locations, stores copies of the videos (and other types of Web content, including documents, images, and audio) in its servers, and attempts to direct each user request to a CDN location that will provide the best user experience. The CDN may be a private CDN, that is, owned by the content provider itself; for example, Google’s CDN distributes YouTube videos and other types of content. The CDN may alternatively be a third-party CDN that distributes content on behalf of multiple content providers; Akamai, Limelight and Level-3 all operate third-party CDNs. A very readable overview of modern CDNs is [ Leighton 2009; Nygren 2010].
CDNs typically adopt one of two different server placement philosophies [Huang 2008]:
Enter Deep. One philosophy, pioneered by Akamai, is to enter deep into the access networks of Internet Service Providers, by deploying server clusters in access ISPs all over the world. (Access networks are described in Section 1.3.) Akamai takes this approach with clusters in approximately 1,700 locations. The goal is to get close to end users, thereby improving user-perceived delay and throughput by decreasing the number of links and routers between the end user and the CDN server from which it receives content. Because of this highly distributed design, the task of maintaining and managing the clusters becomes challenging.
Bring Home. A second design philosophy, taken by Limelight and many other CDN companies, is to bring the ISPs home by building large clusters at a smaller number (for example, tens) of sites. Instead of getting inside the access ISPs, these CDNs typically place their clusters in Internet Exchange Points (IXPs) (see Section 1.3). Compared with the enter-deep design philosophy, the bring-home design typically results in lower maintenance and management overhead, possibly at the expense of higher delay and lower throughput to end users.
Once its clusters are in place, the CDN replicates content across its clusters. The CDN may not want to place a copy of every video in each cluster, since some videos are rarely viewed or are only popular in some countries. In fact, many CDNs do not push videos to their clusters but instead use a simple pull strategy: If a client requests a video from a cluster that is not storing the video, then the cluster retrieves the video (from a central repository or from another cluster) and stores a copy locally while streaming the video to the client at the same time. Similar Web caching (see Section 2.2.5), when a cluster’s storage becomes full, it removes videos that are not frequently requested.
CDN 的运行#
CDN Operation
在介绍了 CDN 部署的两种主要策略之后,我们来深入了解 CDN 是如何运行的。当用户主机中的浏览器被指示获取某个特定视频(通过 URL 标识)时,CDN 必须拦截该请求,以便(1)为该客户端在当前时间点选择一个合适的 CDN 服务器集群,并(2)将客户端请求重定向至该集群中的服务器。我们稍后将讨论 CDN 如何选择合适的集群。但首先我们先来看如何拦截并重定向请求的具体机制。
案例研究
GOOGLE 的网络基础设施
为了支撑其庞大的云服务阵列——包括搜索、Gmail、日历、YouTube 视频、地图、文档和社交网络等——Google 部署了广泛的私有网络和 CDN 基础设施。Google 的 CDN 基础设施由三层服务器集群组成:
十四个“超级数据中心”,其中北美有八个,欧洲四个,亚洲两个 [Google Locations 2016],每个数据中心大约有 100,000 台服务器。这些超级数据中心负责提供动态(通常是个性化的)内容,如搜索结果和 Gmail 消息。
约 50 个部署在全球各地 IXPs 的集群,每个集群包含约 100–500 台服务器 [Adhikari 2011a]。这些集群负责提供静态内容,包括 YouTube 视频 [Adhikari 2011a]。
数百个部署在接入 ISP 内部的“深入接入”集群,每个集群通常是一个机架中的数十台服务器。这些服务器执行 TCP 分流(参见 第 3.7 节),并提供静态内容 [Chen 2011],例如包含搜索结果的网页静态部分。
所有这些数据中心和集群节点都通过 Google 的私有网络连接。当用户发起搜索查询时,该查询通常首先通过本地 ISP 被发送至附近的“深入接入”缓存节点,从该节点检索静态内容;同时,该缓存节点还将查询通过 Google 私有网络转发至某个超级数据中心,从那里检索个性化搜索结果。对于 YouTube 视频,视频内容可能来自某个“集中核心”缓存节点,而包围视频的网页部分可能来自本地“深入接入”缓存节点,而视频周围的广告来自数据中心。总之,除了本地 ISP,Google 的云服务基本上依赖于一套独立于公共互联网的网络基础设施。
大多数 CDN 利用 DNS 来拦截和重定向请求;关于此类 DNS 用法的一个有趣讨论见 [Vixie 2009]。下面我们用一个简单示例说明 DNS 通常如何参与其中。假设内容提供商 NetCinema 雇用了第三方 CDN 公司 KingCDN 来向其用户分发视频。在 NetCinema 的网页中,每个视频被分配一个包含字符串 “video” 和视频唯一标识符的 URL;例如,《变形金刚 7》的 URL 可能是 http://video.netcinema.com/6Y7B23V。如 图 2.25 所示,过程包括以下六步:
用户访问 NetCinema 的网页。
当用户点击链接 http://video.netcinema.com/6Y7B23V 时,用户主机会对 video.netcinema.com 发起 DNS 查询。
用户的本地 DNS 服务器(LDNS)将查询转发至 NetCinema 的权威 DNS 服务器,该服务器发现主机名中包含字符串 “video”。为将 DNS 查询“转交”给 KingCDN,NetCinema 的权威 DNS 服务器不返回 IP 地址,而是向 LDNS 返回一个属于 KingCDN 域名的主机名,例如 a1105.kingcdn.com。
从此处起,DNS 查询进入 KingCDN 的私有 DNS 基础设施。用户的 LDNS 对 a1105.kingcdn.com 发起第二次查询,KingCDN 的 DNS 系统最终向 LDNS 返回某个 KingCDN 内容服务器的 IP 地址。在此过程中,客户端将从哪个 CDN 服务器接收内容便被确定下来。
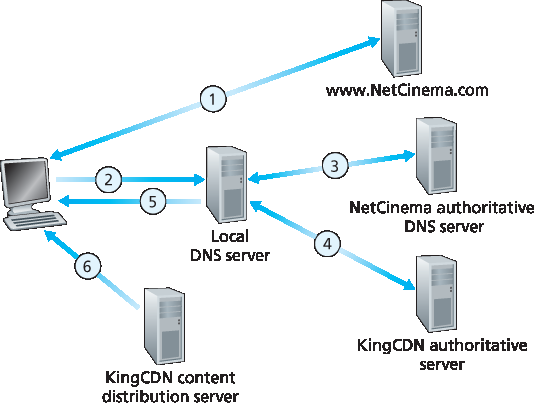
图 2.25 DNS 将用户请求重定向至 CDN 服务器
LDNS 将该 CDN 节点的 IP 地址转发给用户主机。
一旦客户端获得了 KingCDN 内容服务器的 IP 地址,它便与该地址建立 TCP 连接,并对视频发起 HTTP GET 请求。如果使用了 DASH,服务器首先会向客户端发送一个包含每个版本视频 URL 的清单文件,客户端将动态选择不同版本的视频块进行请求。
Having identified the two major approaches toward deploying a CDN, let’s now dive down into the nuts and bolts of how a CDN operates. When a browser in a user’s host is instructed to retrieve a specific video (identified by a URL), the CDN must intercept the request so that it can (1) determine a suitable CDN server cluster for that client at that time, and (2) redirect the client’s request to a server in that cluster. We’ll shortly discuss how a CDN can determine a suitable cluster. But first let’s examine the mechanics behind intercepting and redirecting a request.
CASE STUDY
GOOGLE’S NETWORK INFRASTRUCTURE
To support its vast array of cloud services—including search, Gmail, calendar, YouTube video, maps, documents, and social networks—Google has deployed an extensive private network and CDN infrastructure. Google’s CDN infrastructure has three tiers of server clusters:
Fourteen “mega data centers,” with eight in North America, four in Europe, and two in Asia [Google Locations 2016], with each data center having on the order of 100,000 servers. These mega data centers are responsible for serving dynamic (and often personalized) content, including search results and Gmail messages.
An estimated 50 clusters in IXPs scattered throughout the world, with each cluster consisting on the order of 100–500 servers [Adhikari 2011a]. These clusters are responsible for serving static content, including YouTube videos [Adhikari 2011a].
Many hundreds of “enter-deep” clusters located within an access ISP. Here a cluster typically consists of tens of servers within a single rack. These enter-deep servers perform TCP splitting (see Section 3.7) and serve static content [Chen 2011], including the static portions of Web pages that embody search results.
All of these data centers and cluster locations are networked together with Google’s own private network. When a user makes a search query, often the query is first sent over the local ISP to a nearby enter-deep cache, from where the static content is retrieved; while providing the static content to the client, the nearby cache also forwards the query over Google’s private network to one of the mega data centers, from where the personalized search results are retrieved. For a YouTube video, the video itself may come from one of the bring-home caches, whereas portions of the Web page surrounding the video may come from the nearby enter-deep cache, and the advertisements surrounding the video come from the data centers. In summary, except for the local ISPs, the Google cloud services are largely provided by a network infrastructure that is independent of the public Internet.
Most CDNs take advantage of DNS to intercept and redirect requests; an interesting discussion of such a use of the DNS is [Vixie 2009]. Let’s consider a simple example to illustrate how the DNS is typically involved. Suppose a content provider, NetCinema, employs the third-party CDN company, KingCDN, to distribute its videos to its customers. On the NetCinema Web pages, each of its videos is assigned a URL that includes the string “video” and a unique identifier for the video itself; for example, Transformers 7 might be assigned http://video.netcinema.com/6Y7B23V. Six steps then occur, as shown in Figure 2.25:
The user visits the Web page at NetCinema.
When the user clicks on the link http://video.netcinema.com/6Y7B23V, the user’s host sends a DNS query for video.netcinema.com.
The user’s Local DNS Server (LDNS) relays the DNS query to an authoritative DNS server for NetCinema, which observes the string “video” in the hostname video.netcinema.com. To “hand over” the DNS query to KingCDN, instead of returning an IP address, the NetCinema authoritative DNS server returns to the LDNS a hostname in the KingCDN’s domain, for example, a1105.kingcdn.com.
From this point on, the DNS query enters into KingCDN’s private DNS infrastructure. The user’s LDNS then sends a second query, now for a1105.kingcdn.com, and KingCDN’s DNS system eventually returns the IP addresses of a KingCDN content server to the LDNS. It is thus here, within the KingCDN’s DNS system, that the CDN server from which the client will receive its content is specified.
Figure 2.25 DNS redirects a user’s request to a CDN server
The LDNS forwards the IP address of the content-serving CDN node to the user’s host.
Once the client receives the IP address for a KingCDN content server, it establishes a direct TCP connection with the server at that IP address and issues an HTTP GET request for the video. If DASH is used, the server will first send to the client a manifest file with a list of URLs, one for each version of the video, and the client will dynamically select chunks from the different versions.
集群选择策略#
Cluster Selection Strategies
任何 CDN 部署的核心都是一个 集群选择策略,即一种将客户端动态指派到 CDN 中某个服务器集群或数据中心的机制。正如我们刚刚看到的,CDN 通过客户端的 DNS 查询过程了解到客户端 LDNS 服务器的 IP 地址。在获得该地址之后,CDN 需要基于该 IP 地址选择合适的集群。CDN 通常采用专有的集群选择策略。我们下面简要介绍几种常见策略,每种都有其优缺点。
一种简单策略是将客户端指派给 地理上最近的集群。借助商业地理定位数据库(如 Quova [Quova 2016] 和 Max-Mind [MaxMind 2016]),每个 LDNS IP 地址被映射到地理位置。当收到某个 LDNS 的 DNS 请求时,CDN 选择与其距离最近(按直线距离计算)的集群。该策略对大多数客户端来说效果尚可 [Agarwal 2009]。但对于某些客户端,效果可能较差,因为地理上最近的集群在网络路径上可能并不是跳数最少或延迟最小的。此外,所有基于 DNS 的策略都面临一个固有问题,即部分终端用户配置使用远程的 LDNS [ Shaikh 2001;Mao 2002],这种情况下,LDNS 所在位置可能远离客户端所在地。并且,该策略忽略了互联网路径随时间变化的延迟和带宽差异,总是将同一个集群指派给某个客户端。
为了根据当前的网络流量状况为客户端选择最优集群,CDN 也可以定期执行 实时测量,以获取集群与客户端之间的延迟和丢包表现。例如,CDN 可以令每个集群定期向全球各地的 LDNS 发送探测(如 ping 消息或 DNS 查询)。该策略的一个缺点是,许多 LDNS 配置为不响应此类探测。
At the core of any CDN deployment is a cluster selection strategy, that is, a mechanism for dynamically directing clients to a server cluster or a data center within the CDN. As we just saw, the CDN learns the IP address of the client’s LDNS server via the client’s DNS lookup. After learning this IP address, the CDN needs to select an appropriate cluster based on this IP address. CDNs generally employ proprietary cluster selection strategies. We now briefly survey a few approaches, each of which has its own advantages and disadvantages.
One simple strategy is to assign the client to the cluster that is geographically closest. Using commercial geo-location databases (such as Quova [Quova 2016] and Max-Mind [MaxMind 2016]), each LDNS IP address is mapped to a geographic location. When a DNS request is received from a particular LDNS, the CDN chooses the geographically closest cluster, that is, the cluster that is the fewest kilometers from the LDNS “as the bird flies.” Such a solution can work reasonably well for a large fraction of the clients [Agarwal 2009]. However, for some clients, the solution may perform poorly, since the geographically closest cluster may not be the closest cluster in terms of the length or number of hops of the network path. Furthermore, a problem inherent with all DNS-based approaches is that some end-users are configured to use remotely located LDNSs [ Shaikh 2001; Mao 2002], in which case the LDNS location may be far from the client’s location. Moreover, this simple strategy ignores the variation in delay and available bandwidth over time of Internet paths, always assigning the same cluster to a particular client.
In order to determine the best cluster for a client based on the current traffic conditions, CDNs can instead perform periodic real-time measurements of delay and loss performance between their clusters and clients. For instance, a CDN can have each of its clusters periodically send probes (for example, ping messages or DNS queries) to all of the LDNSs around the world. One drawback of this approach is that many LDNSs are configured to not respond to such probes.
2.6.4 案例研究:Netflix、YouTube 和 Kankan#
2.6.4 Case Studies: Netflix, YouTube, and Kankan
我们将通过三个非常成功的大规模部署实例——Netflix、YouTube 和 Kankan——来结束关于存储视频流的讨论。我们将看到,这些系统各自采用了截然不同的方法,但都运用了本节中讨论的许多基本原理。
We conclude our discussion of streaming stored video by taking a look at three highly successful large-scale deployments: Netflix, YouTube, and Kankan. We’ll see that each of these systems take a very different approach, yet employ many of the underlying principles discussed in this section.
Netflix#
在 2015 年,Netflix 产生了北美住宅 ISP 下行流量的 37%,成为美国领先的在线电影和电视剧服务提供商 Sandvine 2015。如下面所述,Netflix 的视频分发由两大组件构成:Amazon 云平台和其自有的 CDN 基础设施。Netflix 拥有一个网站,处理用户注册与登录、计费、电影目录浏览与搜索、电影推荐系统等诸多功能。如 图 2.26 所示,该网站及其关联的后端数据库完全运行于 Amazon 云平台上的服务器上。此外,Amazon 云还处理以下关键功能:
内容采集。在 Netflix 能向客户分发电影之前,必须先获取并处理该影片。Netflix 接收来自制片方的母版电影版本,并将其上传至 Amazon 云中的主机。
内容处理。Amazon 云中的机器会为每部影片创建多种不同格式,以适配运行于桌面电脑、智能手机以及连接电视的游戏主机等各类客户端视频播放器。针对每种格式和多种比特率创建不同版本,从而支持基于 HTTP 的自适应流(DASH)。
上传至其 CDN 的各个版本。一旦所有版本创建完毕,Amazon 云中的主机会将这些版本上传至其 CDN。
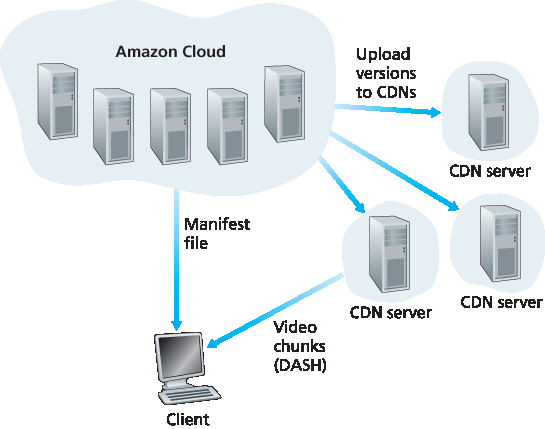
图 2.26 Netflix 视频流平台
当 Netflix 于 2007 年首次推出视频流服务时,采用了三家第三方 CDN 公司来分发其视频内容。此后,Netflix 创建了自己的私有 CDN,目前所有视频均通过该 CDN 传输。(不过 Netflix 仍使用 Akamai 分发其网页内容。)为了构建自有 CDN,Netflix 在 IXPs 和住宅 ISP 内部安装了服务器机架。Netflix 目前在超过 50 个 IXP 部署了服务器机架;详见 Netflix Open Connect 2016 中列出的当前 IXP 清单。此外,还有数百个 ISP 站点部署了 Netflix 机架;同样见 [Netflix Open Connect 2016],Netflix 在其中向潜在 ISP 合作伙伴提供如何为其网络安装(免费的)Netflix 机架的指导。每台服务器配备多个 10 Gbps 以太网口和超过 100 TB 存储。每个机架中的服务器数量不同:IXP 部署的机架通常包含几十台服务器,并包含完整的 Netflix 视频库及其支持 DASH 的多个版本;而本地 IXP 可能仅有一台服务器,并只存储最热门视频。Netflix 不使用拉取缓存(第 2.2.5 节)来填充其位于 IXP 和 ISP 的 CDN 服务器。相反,Netflix 会在非高峰时段将视频主动推送到其 CDN 服务器。对于无法存储完整视频库的位置,Netflix 仅推送每日动态确定的最热门视频。关于 Netflix CDN 设计的更多细节可参考 YouTube 视频 [Netflix Video 1] 与 [Netflix Video 2]。
在介绍了 Netflix 架构组件后,让我们进一步看看客户端与多个参与电影传输的服务器之间的交互。如前所述,浏览 Netflix 视频库的网页由 Amazon 云平台上的服务器提供。当用户选择播放某部影片时,运行于 Amazon 云平台中的 Netflix 软件首先确定哪些 CDN 服务器拥有该影片副本。在拥有该影片的服务器中,软件将进一步为该客户端请求选择“最佳”服务器。如果客户端使用的住宅 ISP 内已安装 Netflix CDN 服务器机架,且该机架中包含请求的影片副本,则通常选择该机架中的服务器;否则,通常选择附近 IXP 中的服务器。
一旦 Netflix 确定用于传输内容的 CDN 服务器,会将该服务器的 IP 地址和一个清单文件(包含该影片不同版本的 URL)发送给客户端。随后,客户端与该 CDN 服务器直接进行交互,采用一种专有的 DASH 版本。如 第 2.6.2 节 所述,客户端在 HTTP GET 请求中使用 byte-range 首部,请求该影片不同版本的分块。Netflix 使用约 4 秒长的分块 [Adhikari 2012]。在下载分块的过程中,客户端会测量接收吞吐量,并运行一个速率决定算法来确定下一个请求分块的质量等级。
Netflix 体现了本节讨论的许多核心原则,包括自适应流和 CDN 分发。然而,由于 Netflix 使用的是仅用于视频(不用于网页)的私有 CDN,因此能够简化并定制其 CDN 设计。特别地,Netflix 无需采用 第 2.6.3 节 中所述的 DNS 重定向来将某客户端连接到某 CDN 服务器;取而代之的是,运行于 Amazon 云中的 Netflix 软件会直接告知客户端应使用哪台 CDN 服务器。此外,Netflix CDN 采用推送缓存而非拉取缓存(第 2.2.5 节):内容在非高峰时段按照计划被推送至服务器,而不是在缓存未命中时动态加载。
Generating 37% of the downstream traffic in residential ISPs in North America in 2015, Netflix has become the leading service provider for online movies and TV series in the United States Sandvine 2015. As we discuss below, Netflix video distribution has two major components: the Amazon cloud and its own private CDN infrastructure. Netflix has a Web site that handles numerous functions, including user registration and login, billing, movie catalogue for browsing and searching, and a movie recommendation system. As shown in Figure 2.26, this Web site (and its associated backend databases) run entirely on Amazon servers in the Amazon cloud. Additionally, the Amazon cloud handles the following critical functions:
Content ingestion. Before Netflix can distribute a movie to its customers, it must first ingest and process the movie. Netflix receives studio master versions of movies and uploads them to hosts in the Amazon cloud.
Content processing. The machines in the Amazon cloud create many different formats for each movie, suitable for a diverse array of client video players running on desktop computers, smartphones, and game consoles connected to televisions. A different version is created for each of these formats and at multiple bit rates, allowing for adaptive streaming over HTTP using DASH.
Uploading versions to its CDN. Once all of the versions of a movie have been created, the hosts in the Amazon cloud upload the versions to its CDN.
Figure 2.26 Netflix video streaming platform
When Netflix first rolled out its video streaming service in 2007, it employed three third-party CDN companies to distribute its video content. Netflix has since created its own private CDN, from which it now streams all of its videos. (Netflix still uses Akamai to distribute its Web pages, however.) To create its own CDN, Netflix has installed server racks both in IXPs and within residential ISPs themselves. Netflix currently has server racks in over 50 IXP locations; see Netflix Open Connect 2016 for a current list of IXPs housing Netflix racks. There are also hundreds of ISP locations housing Netflix racks; also see [Netflix Open Connect 2016], where Netflix provides to potential ISP partners instructions about installing a (free) Netflix rack for their networks. Each server in the rack has several 10 Gbps Ethernet ports and over 100 terabytes of storage. The number of servers in a rack varies: IXP installations often have tens of servers and contain the entire Netflix streaming video library, including multiple versions of the videos to support DASH; local IXPs may only have one server and contain only the most popular videos. Netflix does not use pull-caching (Section 2.2.5) to populate its CDN servers in the IXPs and ISPs. Instead, Netflix distributes by pushing the videos to its CDN servers during off- peak hours. For those locations that cannot hold the entire library, Netflix pushes only the most popular videos, which are determined on a day-to-day basis. The Netflix CDN design is described in some detail in the YouTube videos [Netflix Video 1] and [Netflix Video 2].
Having described the components of the Netflix architecture, let’s take a closer look at the interaction between the client and the various servers that are involved in movie delivery. As indicated earlier, the Web pages for browsing the Netflix video library are served from servers in the Amazon cloud. When a user selects a movie to play, the Netflix software, running in the Amazon cloud, first determines which of its CDN servers have copies of the movie. Among the servers that have the movie, the software then determines the “best” server for that client request. If the client is using a residential ISP that has a Netflix CDN server rack installed in that ISP, and this rack has a copy of the requested movie, then a server in this rack is typically selected. If not, a server at a nearby IXP is typically selected.
Once Netflix determines the CDN server that is to deliver the content, it sends the client the IP address of the specific server as well as a manifest file, which has the URLs for the different versions of the requested movie. The client and that CDN server then directly interact using a proprietary version of DASH. Specifically, as described in Section 2.6.2, the client uses the byte-range header in HTTP GET request messages, to request chunks from the different versions of the movie. Netflix uses chunks that are approximately four-seconds long [Adhikari 2012]. While the chunks are being downloaded, the client measures the received throughput and runs a rate-determination algorithm to determine the quality of the next chunk to request.
Netflix embodies many of the key principles discussed earlier in this section, including adaptive streaming and CDN distribution. However, because Netflix uses its own private CDN, which distributes only video (and not Web pages), Netflix has been able to simplify and tailor its CDN design. In particular, Netflix does not need to employ DNS redirect, as discussed in Section 2.6.3, to connect a particular client to a CDN server; instead, the Netflix software (running in the Amazon cloud) directly tells the client to use a particular CDN server. Furthermore, the Netflix CDN uses push caching rather than pull caching (Section 2.2.5): content is pushed into the servers at scheduled times at off-peak hours, rather than dynamically during cache misses.
YouTube#
每分钟上传至 YouTube 的视频长达 300 小时,每天的视频观看次数达数十亿 [YouTube 2016],YouTube 无可争议地是全球最大的视频分享网站。YouTube 于 2005 年 4 月启动服务,并于 2006 年 11 月被 Google 收购。尽管 Google/YouTube 的架构和协议为专有内容,但通过一些独立测量研究,我们可以对 YouTube 的运作有基本了解 [Zink 2009;Torres 2011;Adhikari 2011a]。与 Netflix 类似,YouTube 广泛采用 CDN 技术分发其视频 [Torres 2011]。与 Netflix 一样,Google 使用自己的私有 CDN 分发 YouTube 视频,在数百个 IXP 和 ISP 站点部署了服务器集群。Google 从这些地点以及其大型数据中心直接分发 YouTube 视频 [Adhikari 2011a]。但与 Netflix 不同的是,Google 使用拉取缓存(参见 第 2.2.5 节)和 DNS 重定向(参见 第 2.6.3 节)。大多数情况下,Google 的集群选择策略将客户端定向至客户端与集群之间 RTT 最小的集群;但为实现集群负载均衡,有时客户端会(通过 DNS)被定向至更远的集群 [Torres 2011]。
YouTube 使用 HTTP 流,通常为每部影片提供少量不同版本,每个版本对应不同比特率和视频质量。YouTube 不采用自适应流(如 DASH),而是要求用户手动选择版本。为节省因跳转或提前结束播放而可能浪费的带宽和服务器资源,YouTube 使用 HTTP 字节范围请求限制传输视频的量,仅在预取目标量的视频之后才继续传输。
每天有数百万视频上传至 YouTube。YouTube 的视频不仅通过 HTTP 从服务器流式传输至客户端,而且上传者也是通过 HTTP 将视频上传至服务器。YouTube 会处理每个接收到的视频,将其转换为 YouTube 视频格式,并创建多个不同比特率版本。此处理工作完全在 Google 数据中心内部完成。(详见 [第 2.6.3 节] 中关于 Google 网络基础设施的案例研究。)
With 300 hours of video uploaded to YouTube every minute and several billion video views per day [YouTube 2016], YouTube is indisputably the world’s largest video-sharing site. YouTube began its service in April 2005 and was acquired by Google in November 2006. Although the Google/YouTube design and protocols are proprietary, through several independent measurement efforts we can gain a basic understanding about how YouTube operates [Zink 2009; Torres 2011; Adhikari 2011a]. As with Netflix, YouTube makes extensive use of CDN technology to distribute its videos [Torres 2011]. Similar to Netflix, Google uses its own private CDN to distribute YouTube videos, and has installed server clusters in many hundreds of different IXP and ISP locations. From these locations and directly from its huge data centers, Google distributes YouTube videos [Adhikari 2011a]. Unlike Netflix, however, Google uses pull caching, as described in Section 2.2.5, and DNS redirect, as described in Section 2.6.3. Most of the time, Google’s cluster-selection strategy directs the client to the cluster for which the RTT between client and cluster is the lowest; however, in order to balance the load across clusters, sometimes the client is directed (via DNS) to a more distant cluster [Torres 2011].
YouTube employs HTTP streaming, often making a small number of different versions available for a video, each with a different bit rate and corresponding quality level. YouTube does not employ adaptive streaming (such as DASH), but instead requires the user to manually select a version. In order to save bandwidth and server resources that would be wasted by repositioning or early termination, YouTube uses the HTTP byte range request to limit the flow of transmitted data after a target amount of video is prefetched.
Several million videos are uploaded to YouTube every day. Not only are YouTube videos streamed from server to client over HTTP, but YouTube uploaders also upload their videos from client to server over HTTP. YouTube processes each video it receives, converting it to a YouTube video format and creating multiple versions at different bit rates. This processing takes place entirely within Google data centers. (See the case study on Google’s network infrastructure in [Section 2.6.3].)
Kankan#
我们刚刚看到,由私有 CDN 运营的专用服务器将 Netflix 和 YouTube 视频流传输给客户端。Netflix 和 YouTube 不仅要承担服务器硬件的成本,还要承担用于分发视频的带宽费用。考虑到这些服务的规模和所消耗的带宽,如此部署 CDN 的成本是相当高昂的。
本节最后介绍一种完全不同的大规模互联网视频点播服务方式——该方式能显著减少服务提供商的基础设施与带宽开销。如你所料,这种方式采用 P2P 传输,而非(或结合)客户端-服务器传输。自 2011 年起,Kankan(由迅雷拥有并运营)开始部署 P2P 视频分发系统并取得巨大成功,每月有数千万用户使用 [Zhang 2015]。
从高层次来看,P2P 视频流与 BitTorrent 文件下载非常相似。当某个对等体希望观看一部视频时,它会联系追踪器以发现系统中拥有该视频副本的其他对等体。该请求节点随后从拥有该视频的其他对等体中并行请求视频分块。但与 BitTorrent 不同的是,请求优先针对即将播放的视频分块,从而确保连续播放 [Dhungel 2012]。
近年来,Kankan 迁移至混合 CDN-P2P 流系统 [Zhang 2015]。具体而言,Kankan 目前在中国部署了数百台服务器,并将视频内容推送至这些服务器。该 Kankan CDN 在视频播放的启动阶段发挥关键作用。在大多数情况下,客户端从 CDN 服务器请求视频起始内容,同时也从其他对等体请求内容。当 P2P 流量足以支撑播放时,客户端便停止从 CDN 流式获取视频,仅从对等体获取。但如果 P2P 流量不足,客户端将重新连接 CDN,并返回至 CDN-P2P 混合传输模式。通过这种方式,Kankan 能确保较短的启动延迟,同时最大限度减少对昂贵基础设施服务器和带宽的依赖。
We just saw that dedicated servers, operated by private CDNs, stream Netflix and YouTube videos to clients. Netflix and YouTube have to pay not only for the server hardware but also for the bandwidth the servers use to distribute the videos. Given the scale of these services and the amount of bandwidth they are consuming, such a CDN deployment can be costly.
We conclude this section by describing an entirely different approach for providing video on demand over the Internet at a large scale—one that allows the service provider to significantly reduce its infrastructure and bandwidth costs. As you might suspect, this approach uses P2P delivery instead of (or along with) client-server delivery. Since 2011, Kankan (owned and operated by Xunlei) has been deploying P2P video delivery with great success, with tens of millions of users every month [Zhang 2015].
At a high level, P2P video streaming is very similar to BitTorrent file downloading. When a peer wants to see a video, it contacts a tracker to discover other peers in the system that have a copy of that video. This requesting peer then requests chunks of the video in parallel from the other peers that have the video. Different from downloading with BitTorrent, however, requests are preferentially made for chunks that are to be played back in the near future in order to ensure continuous playback [Dhungel 2012].
Recently, Kankan has migrated to a hybrid CDN-P2P streaming system [Zhang 2015]. Specifically, Kankan now deploys a few hundred servers within China and pushes video content to these servers. This Kankan CDN plays a major role in the start-up stage of video streaming. In most cases, the client requests the beginning of the content from CDN servers, and in parallel requests content from peers. When the total P2P traffic is sufficient for video playback, the client will cease streaming from the CDN and only stream from peers. But if the P2P streaming traffic becomes insufficient, the client will restart CDN connections and return to the mode of hybrid CDN-P2P streaming. In this manner, Kankan can ensure short initial start-up delays while minimally relying on costly infrastructure servers and bandwidth.