3.4 可靠数据传输的原理#
3.4 Principles of Reliable Data Transfer
在本节中,我们将以通用的上下文来讨论可靠数据传输的问题。这是合适的方式,因为实现可靠数据传输的问题不仅出现在传输层,也出现在链路层以及应用层。因此,这一通用性问题在网络中具有核心的重要性。实际上,如果要列出网络中“十个最基本的重要问题”的清单,可靠数据传输问题很可能名列前茅。在下一节中,我们将考察 TCP,并特别指出,TCP 利用了我们即将描述的许多原理。
图 3.8 展示了我们研究可靠数据传输的框架。传输层向上层实体提供的服务抽象是一个可靠信道(reliable channel),用于传输数据。在这个可靠信道中,传输的数据位不会被破坏(不会从 0 翻转成 1,或相反),也不会丢失,并且它们按发送顺序被交付。这正是 TCP 向调用它的 Internet 应用程序所提供的服务模型。
可靠数据传输协议 的责任是实现这种服务抽象。这一任务之所以困难,是因为可靠数据传输协议之下的层可能并不可靠。例如,TCP 是建立在不可靠(IP)端到端网络层之上的可靠数据传输协议。更一般地说,两个可靠通信端点之间的下层可能是一个物理链路(如链路层数据传输协议的情况),也可能是一个全球互联网络(如传输层协议的情况)。但就我们的目的而言,我们可以将该下层简单地视为一个不可靠的点对点信道。
在本节中,我们将逐步构建一个可靠数据传输协议的发送方与接收方逻辑,实现对底层信道模型复杂度递增的应对。例如,我们将考虑在底层信道可能破坏位或丢失整个分组的情况下,需要哪些协议机制。在本节讨论中,我们始终假设分组按发送顺序到达(即底层信道不重排序),但可能有些分组会丢失。图 3.8(b) 展示了我们数据传输协议的接口。数据传输协议的发送方将通过调用 rdt_send() 来从上层接收数据。该协议随后将在接收端将这些数据传递给上层。(这里 rdt 代表可靠数据传输协议,“_send”表示调用的是 rdt 的发送端函数。设计任何协议的第一步是选择一个好名字!)在接收端,当一个分组从信道到达时,将调用 rdt_rcv()。当 rdt 协议想要将数据交付给上层时,将通过调用 deliver_data() 来实现。在以下讨论中,我们使用术语“packet(分组)”而不是传输层的“segment(报文段)”。这是因为本节中发展出的理论适用于整个计算机网络,而不仅仅是 Internet 的传输层,因此使用更通用的术语“分组”在这里更合适。
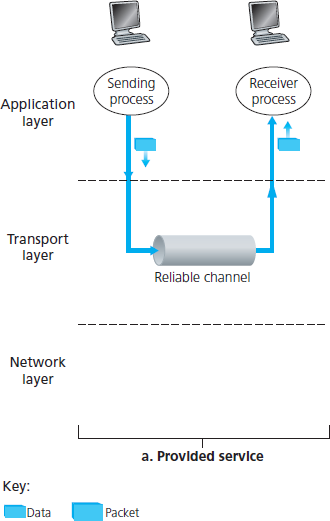
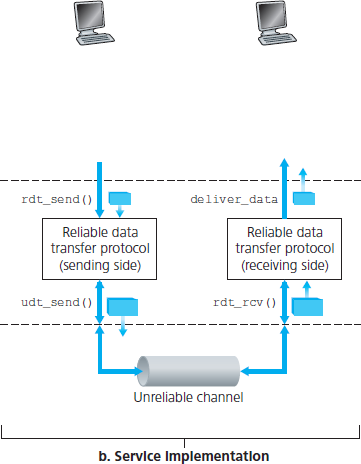
图 3.8 可靠数据传输:服务模型与服务实现
在本节中,我们仅考虑 单向数据传输 的情况,即从发送方到接收方的数据传输。可靠的 双向 (即全双工) 数据传输 的实现在概念上并不更复杂,但解释起来要繁琐得多。尽管我们仅讨论单向数据传输,但需要注意的是,协议的发送方与接收方仍然需要双向发送分组,如 图 3.8 所示。我们很快将看到,除了交换包含实际要传输的数据的分组外, rdt 协议的发送方与接收方还需要来回交换控制分组。 rdt 的发送方与接收方都通过调用 udt_send() 向对方发送分组(其中 udt 表示不可靠数据传输)。
In this section, we consider the problem of reliable data transfer in a general context. This is appropriate since the problem of implementing reliable data transfer occurs not only at the transport layer, but also at the link layer and the application layer as well. The general problem is thus of central importance to networking. Indeed, if one had to identify a “top-ten” list of fundamentally important problems in all of networking, this would be a candidate to lead the list. In the next section we’ll examine TCP and show, in particular, that TCP exploits many of the principles that we are about to describe.
Figure 3.8 illustrates the framework for our study of reliable data transfer. The service abstraction provided to the upper-layer entities is that of a reliable channel through which data can be transferred. With a reliable channel, no transferred data bits are corrupted (flipped from 0 to 1, or vice versa) or lost, and all are delivered in the order in which they were sent. This is precisely the service model offered by TCP to the Internet applications that invoke it.
It is the responsibility of a reliable data transfer protocol to implement this service abstraction. This task is made difficult by the fact that the layer below the reliable data transfer protocol may be unreliable. For example, TCP is a reliable data transfer protocol that is implemented on top of an unreliable (IP) end-to-end network layer. More generally, the layer beneath the two reliably communicating end points might consist of a single physical link (as in the case of a link-level data transfer protocol) or a global internetwork (as in the case of a transport-level protocol). For our purposes, however, we can view this lower layer simply as an unreliable point-to-point channel.
In this section, we will incrementally develop the sender and receiver sides of a reliable data transfer protocol, considering increasingly complex models of the underlying channel. For example, we’ll consider what protocol mechanisms are needed when the underlying channel can corrupt bits or lose entire packets. One assumption we’ll adopt throughout our discussion here is that packets will be delivered in the order in which they were sent, with some packets possibly being lost; that is, the underlying channel will not reorder packets. Figure 3.8(b) illustrates the interfaces for our data transfer protocol. The sending side of the data transfer protocol will be invoked from above by a call to rdt_send(). It will pass the data to be delivered to the upper layer at the receiving side. (Here rdt stands for reliable data transfer protocol and _send indicates that the sending side of rdt is being called. The first step in developing any protocol is to choose a good name!) On the receiving side, rdt_rcv() will be called when a packet arrives from the receiving side of the channel. When the rdt protocol wants to deliver data to the upper layer, it will do so by calling deliver_data(). In the following we use the terminology “packet” rather than transport-layer “segment.” Because the theory developed in this section applies to computer networks in general and not just to the Internet transport layer, the generic term “packet” is perhaps more appropriate here.
Figure 3.8 Reliable data transfer: Service model and service implementation
In this section we consider only the case of unidirectional data transfer, that is, data transfer from the sending to the receiving side. The case of reliable bidirectional (that is, full-duplex) data transfer is conceptually no more difficult but considerably more tedious to explain. Although we consider only unidirectional data transfer, it is important to note that the sending and receiving sides of our protocol will nonetheless need to transmit packets in both directions, as indicated in Figure 3.8. We will see shortly that, in addition to exchanging packets containing the data to be transferred, the sending and receiving sides of rdt will also need to exchange control packets back and forth. Both the send and receive sides of rdt send packets to the other side by a call to udt_send() (where udt stands for unreliable data transfer).
3.4.1 构建一个可靠数据传输协议#
3.4.1 Building a Reliable Data Transfer Protocol
我们现在逐步介绍一系列协议,每个协议的复杂度逐步提升,最终达到一个完美无缺的可靠数据传输协议。
We now step through a series of protocols, each one becoming more complex, arriving at a flawless, reliable data transfer protocol.
在完全可靠信道上的可靠数据传输:rdt1.0#
Reliable Data Transfer over a Perfectly Reliable Channel: rdt1.0
我们首先考虑最简单的情况,即底层信道是完全可靠的。这个协议本身,我们称之为 rdt1.0,是非常简单的。图 3.9 展示了 rdt1.0 发送方与接收方的 有限状态机(FSM) 定义。图 3.9(a) 中的 FSM 定义了发送方的操作,而 图 3.9(b) 中的 FSM 定义了接收方的操作。需要注意的是,发送方与接收方拥有各自独立的 FSM。在 图 3.9 中,发送方与接收方的 FSM 都仅包含一个状态。FSM 描述中的箭头表示协议从一个状态到另一个状态的转换。(由于 图 3.9 中的每个 FSM 仅有一个状态,因此状态转换必然是从该状态回到自身;稍后我们将看到更复杂的状态图。)触发状态转换的事件显示在转换标注的水平线上方,而事件发生时执行的动作则显示在水平线下方。当事件发生但无动作,或无事件但有动作时,我们分别在水平线上下使用符号 Λ 显式表示“无动作”或“无事件”。FSM 的初始状态由虚线箭头表示。尽管 图 3.9 中的 FSM 仅有一个状态,但我们即将看到的 FSM 拥有多个状态,因此标明每个 FSM 的初始状态很重要。
rdt 的发送端通过 rdt_send(data) 事件从上层接收数据,创建一个包含该数据的分组(通过动作 make_pkt(data)),并将该分组发送到信道中。实际上,rdt_send(data) 事件通常是由上层应用通过过程调用(例如 rdt_send())触发的。
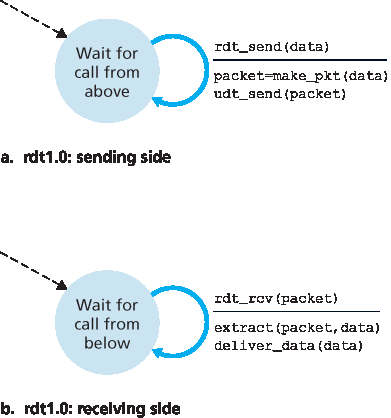
图 3.9 rdt1.0 – 用于完全可靠信道的协议
在接收端,rdt 通过 rdt_rcv(packet) 事件从底层信道接收到一个分组,从分组中提取出数据(通过动作 extract (packet, data)),并将数据传递给上层(通过动作 deliver_data(data))。实际上, rdt_rcv(packet) 事件通常是由下层协议通过过程调用(例如 rdt_rcv())触发的。
在这个简单的协议中,数据单元与分组之间没有区别。此外,所有分组的流动方向都是从发送方到接收方;由于信道是完全可靠的,接收方无需向发送方提供任何反馈,因为不会发生错误!需要注意的是,我们还假设接收方能够以不低于发送方的速率接收数据。因此,接收方也无需要求发送方减速!
We first consider the simplest case, in which the underlying channel is completely reliable. The protocol itself, which we’ll call rdt1.0, is trivial. The finite-state machine (FSM) definitions for the rdt1.0 sender and receiver are shown in Figure 3.9. The FSM in Figure 3.9(a) defines the operation of the sender, while the FSM in Figure 3.9(b) defines the operation of the receiver. It is important to note that there are separate FSMs for the sender and for the receiver. The sender and receiver FSMs in Figure 3.9 each have just one state. The arrows in the FSM description indicate the transition of the protocol
from one state to another. (Since each FSM in Figure 3.9 has just one state, a transition is necessarily from the one state back to itself; we’ll see more complicated state diagrams shortly.) The event causing the transition is shown above the horizontal line labeling the transition, and the actions taken when the event occurs are shown below the horizontal line. When no action is taken on an event, or no event occurs and an action is taken, we’ll use the symbol Λ below or above the horizontal, respectively, to explicitly denote the lack of an action or event. The initial state of the FSM is indicated by the dashed
arrow. Although the FSMs in Figure 3.9 have but one state, the FSMs we will see shortly have multiple states, so it will be important to identify the initial state of each FSM.
The sending side of rdt simply accepts data from the upper layer via the rdt_send(data) event, creates a packet containing the data (via the action make_pkt(data)) and sends the packet into the channel. In practice, the rdt_send(data) event would result from a procedure call (for example, to
rdt_send()) by the upper-layer application.
Figure 3.9 rdt1.0 – A protocol for a completely reliable channel
On the receiving side, rdt receives a packet from the underlying channel via the rdt_rcv(packet) event, removes the data from the packet (via the action extract (packet, data)) and passes the data up to the upper layer (via the action deliver_data(data)). In practice, the rdt_rcv(packet) event would result from a procedure call (for example, to rdt_rcv()) from the lower-layer protocol.
In this simple protocol, there is no difference between a unit of data and a packet. Also, all packet flow is from the sender to receiver; with a perfectly reliable channel there is no need for the receiver side to provide any feedback to the sender since nothing can go wrong! Note that we have also assumed that the receiver is able to receive data as fast as the sender happens to send data. Thus, there is no need for the receiver to ask the sender to slow down!
在存在比特错误的信道上的可靠数据传输:rdt2.0#
Reliable Data Transfer over a Channel with Bit Errors: rdt2.0
一个更现实的底层信道模型是分组中的比特可能会被损坏。这类比特错误通常发生在网络的物理组件中,例如分组在传输、传播或缓冲的过程中。我们暂且继续假设所有传输的分组都会被接收(尽管其比特可能已被损坏),并且按照发送的顺序被接收。
在为这种信道开发可靠通信协议之前,先思考人们在面对类似情况时可能的应对方式。设想你自己通过电话口述一段较长的信息。在典型的场景中,记录者可能在每听完并理解、记录一整句话后说“OK”。如果记录者听到一句模糊不清的话,他会请你重复这句话。这个口述协议使用了 正确认可 (“OK”)和 否认可 (“请重复一遍”)。这些控制消息让接收方能告知发送方哪些内容被正确接收,哪些内容出现了错误需要重传。在计算机网络中,基于这种重传机制的可靠数据传输协议被称为 ARQ(Automatic Repeat reQuest,自动重传请求)协议。
从根本上说,为了应对比特错误,ARQ 协议需要具备三项附加协议能力:
错误检测。首先,需要一种机制使接收方能够检测出比特错误是否发生。回忆前一节中提到的,UDP 使用 Internet 校验和字段正是为此目的。在 第 6 章 中我们将更详细地探讨错误检测与纠正技术;这些技术使接收方能够检测并可能纠正分组比特错误。目前,我们只需知道这些技术要求从发送方向接收方发送额外的比特(即除了原始数据之外的比特);这些比特会被收集到
rdt2.0数据分组的校验和字段中。接收方反馈。由于发送方与接收方通常运行在不同的端系统上,可能相距数千英里,发送方要了解接收方对分组的看法(即是否正确接收分组)的唯一方式是由接收方显式反馈信息给发送方。在口述场景中的“OK”和“请重复一遍”就是这类反馈的例子。我们的
rdt2.0协议也将从接收方向发送方发送 ACK 和 NAK 分组。从原理上讲,这些分组只需要一个比特的长度;例如,0 表示 NAK,1 表示 ACK。重传机制。接收方收到的错误分组将由发送方重新传输。
图 3.10 展示了 rdt2.0 的 FSM 表示,该协议使用了错误检测、确认和否认机制。
rdt2.0 的发送方有两个状态。在最左边的状态中,发送方协议正在等待从上层传来的数据。当 rdt_send(data) 事件发生时,发送方会创建一个包含要发送数据和校验和的分组(sndpkt,例如如 第 3.3.2 节 中 UDP 段的情况所述),然后通过 udt_send(sndpkt) 操作发送该分组。在最右边的状态中,发送方协议正在等待来自接收方的 ACK 或 NAK 分组。如果收到 ACK 分组(图 3.10 中的 rdt_rcv(rcvpkt) && isACK (rcvpkt) 表示此事件),发送方知道最近发送的分组已被正确接收,因此协议返回到等待上层数据的状态。如果收到 NAK,协议将重传上一个分组,并等待接收方对重传分组的响应 ACK 或 NAK。需要注意的是,当发送方处于等待 ACK 或 NAK 的状态时,它不能从上层获取更多数据;也就是说, rdt_send() 事件不会发生;只有在收到 ACK 并离开该状态后才会发生。因此,发送方在确认接收方已正确接收当前分组之前,不会发送新的数据。由于这种行为,这类协议被称为 停等(stop-and-wait)协议。
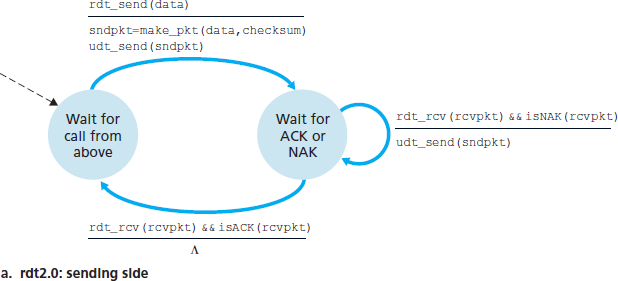

图 3.10 rdt2.0 – 用于具有比特错误信道的协议
rdt2.0 的接收方 FSM 仍然只有一个状态。在分组到达时,根据接收到的分组是否损坏,接收方会回复 ACK 或 NAK。在 图 3.10 中, rdt_rcv(rcvpkt) && corrupt(rcvpkt) 表示接收到一个有错误的分组事件。
协议 rdt2.0 看起来似乎是可行的,但不幸的是它存在一个致命缺陷。特别是我们没有考虑 ACK 或 NAK 分组本身也可能被损坏!(在继续之前,你可以先思考一下该如何修复这个问题。)不幸的是,我们这个小小的疏忽并不像看上去那么无害。最起码,我们需要为 ACK/NAK 分组添加校验和位以检测此类错误。更困难的问题是协议该如何从 ACK 或 NAK 分组的错误中恢复。困难在于如果 ACK 或 NAK 被损坏,发送方就无法知道接收方是否正确接收了最后一份数据。
考虑处理损坏 ACK 或 NAK 的三种可能方式:
第一种可能性,设想人在口述场景中的做法。如果讲话者听不清接收方回复的“OK”或“请重复一遍”,讲话者可能会问:“你说什么?”(这会在我们的协议中引入一种新的从发送方向接收方的分组类型)。然后接收方会重复他的回复。但如果讲话者的“你说什么?”也被损坏了呢?接收方无法判断这个模糊的句子是口述内容的一部分还是要求重发最后一次回复,他可能也会回复“你说什么?”。当然,这个回复也可能是模糊的。显然,这是一条困难的道路。
第二种替代方案是添加足够的校验和位,使发送方不仅能检测出比特错误,还能从中恢复。这解决了信道会损坏但不会丢包的情形下的直接问题。
第三种方法是当发送方收到损坏的 ACK 或 NAK 分组时,简单地重新发送当前的数据分组。然而,这种方法会在发送方到接收方的信道中引入 重复分组。重复分组的根本问题在于接收方无法知道它上次发送的 ACK 或 NAK 是否被发送方正确接收。因此,接收方事先无法知道一个到达的分组是新数据还是重传的数据!
解决这个新问题的一个简单方法(几乎所有现有的数据传输协议都采用,包括 TCP)是向数据分组添加一个新字段,让发送方通过该字段为数据分组编号,也就是加入一个 序列号(sequence number)。接收方只需检查这个序列号即可判断接收到的分组是否是重传。在这种简单的停等协议情况下,一个 1 比特的序列号就足够了,因为它允许接收方判断发送方是在重传(接收到的分组序列号与最近接收到的分组相同),还是发送一个新分组(序列号发生变化,在模 2 算术中“前进”)。由于我们目前假设信道不会丢包,因此 ACK 和 NAK 分组本身无需指明其确认的是哪个分组。发送方知道任何一个收到的 ACK 或 NAK 分组(无论是否损坏)都是对其最近一次发送数据分组的响应。
图 3.11 与 3.12 展示了我们对 rdt2.0 修复后的版本 rdt2.1 的 FSM 描述。 rdt2.1 的发送方和接收方 FSM 数量都变为之前的两倍。这是因为协议状态现在必须反映出当前正在发送(发送方)或期望接收(接收方)的分组是否具有序列号 0 或 1。注意,那些发送或期望接收编号为 0 的分组状态中的动作与发送或期望接收编号为 1 的分组状态是镜像的;唯一的差异在于序列号的处理。
协议 rdt2.1 使用从接收方向发送方发送的正确认可和否认可。当接收到一个乱序分组时,接收方会发送对其所接收到分组的正确认可;当接收到一个损坏分组时,接收方发送否认可。如果我们不发送 NAK,而是对最后一个正确接收的分组发送 ACK,也能达到与 NAK 相同的效果。发送方若收到两个针对同一分组的 ACK(即,收到 重复 ACK ),便知道接收方没有正确接收到 ACK 所确认的分组之后的那个分组。我们用于带比特错误信道的无 NAK 的可靠数据传输协议是 rdt2.2,见 图 3.13 与 3.14。在 rdt2.1 与 rdt2.2 之间的一个细微变化是,接收方现在必须在 ACK 消息中包含被确认分组的序列号(通过在接收方 FSM 中的 make_pkt() 加入 ACK, 0 或 ACK, 1 参数实现),而发送方现在必须检查 ACK 消息所确认分组的序列号(通过在发送方 FSM 的 isACK() 中加入 0 或 1 参数实现)。
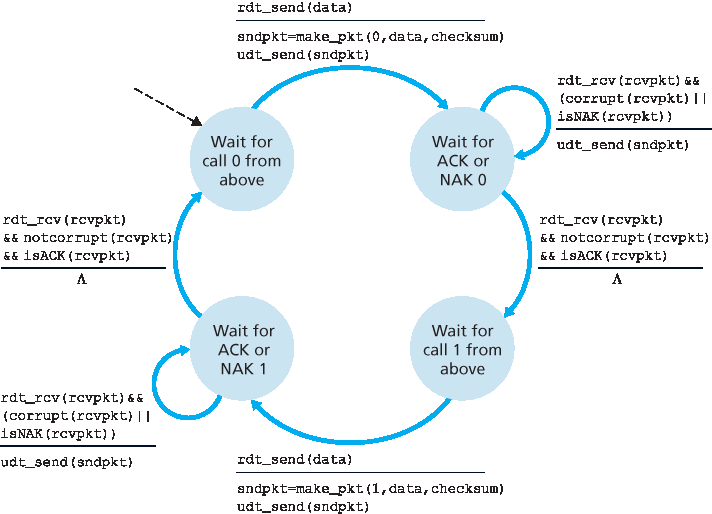
图 3.11 rdt2.1 发送方
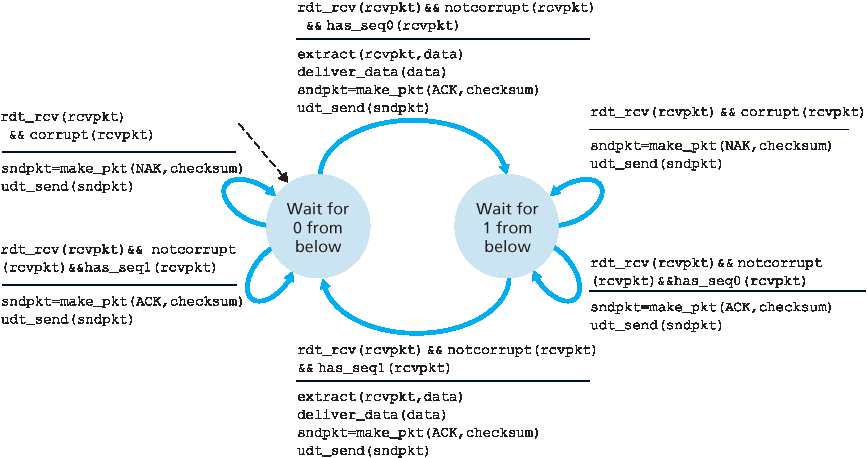
图 3.12 rdt2.1 接收方
A more realistic model of the underlying channel is one in which bits in a packet may be corrupted. Such bit errors typically occur in the physical components of a network as a packet is transmitted, propagates, or is buffered. We’ll continue to assume for the moment that all transmitted packets are received (although their bits may be corrupted) in the order in which they were sent.
Before developing a protocol for reliably communicating over such a channel, first consider how people might deal with such a situation. Consider how you yourself might dictate a long message over the phone. In a typical scenario, the message taker might say “OK” after each sentence has been heard, understood, and recorded. If the message taker hears a garbled sentence, you’re asked to repeat the garbled sentence. This message-dictation protocol uses both positive acknowledgments (“OK”) and negative acknowledgments (“Please repeat that.”). These control messages allow the receiver to let the sender know what has been received correctly, and what has been received in error and thus requires repeating. In a computer network setting, reliable data transfer protocols based on such retransmission are known as ARQ (Automatic Repeat reQuest) protocols.
Fundamentally, three additional protocol capabilities are required in ARQ protocols to handle the presence of bit errors:
Error detection. First, a mechanism is needed to allow the receiver to detect when bit errors have occurred. Recall from the previous section that UDP uses the Internet checksum field for exactly this purpose. In Chapter 6 we’ll examine error-detection and -correction techniques in greater detail; these techniques allow the receiver to detect and possibly correct packet bit errors. For now, we need only know that these techniques require that extra bits (beyond the bits of original data to be transferred) be sent from the sender to the receiver; these bits will be gathered into the packet
checksum field of the rdt2.0 data packet.
- Receiver feedback. Since the sender and receiver are typically executing on different end systems,
possibly separated by thousands of miles, the only way for the sender to learn of the receiver’s view of the world (in this case, whether or not a packet was received correctly) is for the receiver to provide explicit feedback to the sender. The positive (ACK) and negative (NAK) acknowledgment
replies in the message-dictation scenario are examples of such feedback. Our rdt2.0 protocol will similarly send ACK and NAK packets back from the receiver to the sender. In principle, these packets need only be one bit long; for example, a 0 value could indicate a NAK and a value of 1 could indicate an ACK.
- Retransmission. A packet that is received in error at the receiver will be retransmitted by the sender.
Figure 3.10 shows the FSM representation of rdt2.0, a data transfer protocol employing error detection, positive acknowledgments, and negative acknowledgments.
The send side of rdt2.0 has two states. In the leftmost state, the send-side protocol is waiting for data to be passed down from the upper layer. When the rdt_send(data) event occurs, the sender will create a packet (sndpkt) containing the data to be sent, along with a packet checksum (for example, as discussed in Section 3.3.2 for the case of a UDP segment), and then send the packet via the udt_send(sndpkt) operation. In the rightmost state, the sender protocol is waiting for an ACK or a NAK packet from the receiver. If an ACK packet is received (the notation rdt_rcv(rcvpkt) && isACK (rcvpkt) in Figure 3.10 corresponds to this event), the sender knows that the most recently transmitted packet has been received correctly and thus the protocol returns to the state of waiting for data from the upper layer. If a NAK is received, the protocol retransmits the last packet and waits for an ACK or NAK to be returned by the receiver in response to the retransmitted data packet. It is important to note that when the sender is in the wait-for-ACK-or-NAK
state, it cannot get more data from the upper layer; that is, the rdt_send() event can not occur; that will happen only after the sender receives an ACK and leaves this state. Thus, the sender will not send a new piece of data until it is sure that the receiver has correctly received the current packet. Because of
this behavior, protocols such as rdt2.0 are known as stop-and-wait protocols.
Figure 3.10 rdt2.0 – A protocol for a channel with bit errors
The receiver-side FSM for rdt2.0 still has a single state. On packet arrival, the receiver replies with either an ACK or a NAK, depending on whether or not the received packet is corrupted. In Figure 3.10, the notation rdt_rcv(rcvpkt) && corrupt(rcvpkt) corresponds to the event in which a packet is received and is found to be in error.
Protocol rdt2.0 may look as if it works but, unfortunately, it has a fatal flaw. In particular, we haven’t accounted for the possibility that the ACK or NAK packet could be corrupted! (Before proceeding on, you should think about how this problem may be fixed.) Unfortunately, our slight oversight is not as innocuous as it may seem. Minimally, we will need to add checksum bits to ACK/NAK packets in order to detect such errors. The more difficult question is how the protocol should recover from errors in ACK or NAK packets. The difficulty here is that if an ACK or NAK is corrupted, the sender has no way of knowing whether or not the receiver has correctly received the last piece of transmitted data.
Consider three possibilities for handling corrupted ACKs or NAKs:
For the first possibility, consider what a human might do in the message-dictation scenario. If the speaker didn’t understand the “OK” or “Please repeat that” reply from the receiver, the speaker would probably ask, “What did you say?” (thus introducing a new type of sender-to-receiver packet to our protocol). The receiver would then repeat the reply. But what if the speaker’s “What did you say?” is corrupted? The receiver, having no idea whether the garbled sentence was part of the dictation or a request to repeat the last reply, would probably then respond with “What did you say?” And then, of course, that response might be garbled. Clearly, we’re heading down a difficult path.
A second alternative is to add enough checksum bits to allow the sender not only to detect, but also to recover from, bit errors. This solves the immediate problem for a channel that can corrupt packets but not lose them.
A third approach is for the sender simply to resend the current data packet when it receives a garbled ACK or NAK packet. This approach, however, introduces duplicate packets into the sender-to-receiver channel. The fundamental difficulty with duplicate packets is that the receiver doesn’t know whether the ACK or NAK it last sent was received correctly at the sender. Thus, it cannot know a priori whether an arriving packet contains new data or is a retransmission!
A simple solution to this new problem (and one adopted in almost all existing data transfer protocols, including TCP) is to add a new field to the data packet and have the sender number its data packets by putting a sequence number into this field. The receiver then need only check this sequence number to determine whether or not the received packet is a retransmission. For this simple case of a stop-and- wait protocol, a 1-bit sequence number will suffice, since it will allow the receiver to know whether the sender is resending the previously transmitted packet (the sequence number of the received packet has the same sequence number as the most recently received packet) or a new packet (the sequence number changes, moving “forward” in modulo-2 arithmetic). Since we are currently assuming a channel that does not lose packets, ACK and NAK packets do not themselves need to indicate the sequence number of the packet they are acknowledging. The sender knows that a received ACK or NAK packet (whether garbled or not) was generated in response to its most recently transmitted data packet.
Figures 3.11 and 3.12 show the FSM description for rdt2.1, our fixed version of rdt2.0. The
rdt2.1 sender and receiver FSMs each now have twice as many states as before. This is because the protocol state must now reflect whether the packet currently being sent (by the sender) or expected (at the receiver) should have a sequence number of 0 or 1. Note that the actions in those states where a 0- numbered packet is being sent or expected are mirror images of those where a 1-numbered packet is being sent or expected; the only differences have to do with the handling of the sequence number.
Protocol rdt2.1 uses both positive and negative acknowledgments from the receiver to the sender. When an out-of-order packet is received, the receiver sends a positive acknowledgment for the packet it has received. When a corrupted packet is received, the receiver sends a negative acknowledgment. We can accomplish the same effect as a NAK if, instead of sending a NAK, we send an ACK for the last correctly received packet. A sender that receives two ACKs for the same packet (that is, receives duplicate ACKs) knows that the receiver did not correctly receive the packet following the packet that is being ACKed twice. Our NAK-free reliable
data transfer protocol for a channel with bit errors is rdt2.2, shown in Figures 3.13 and 3.14. One
subtle change between rtdt2.1 and rdt2.2 is that the receiver must now include the sequence
number of the packet being acknowledged by an ACK message (this is done by including the ACK, 0
or ACK, 1 argument in make_pkt() in the receiver FSM), and the sender must now check the sequence number of the packet being acknowledged by a received ACK message (this is done by including the 0 or 1 argument in isACK() in the sender FSM).
Figure 3.11 rdt2.1 sender
Figure 3.12 rdt2.1 receiver
在具有比特错误的丢包信道上的可靠数据传输:rdt3.0#
Reliable Data Transfer over a Lossy Channel with Bit Errors: rdt3.0
现在假设底层信道不仅会损坏比特,还可能会丢失分组,这是当前计算机网络(包括 Internet)中并不罕见的现象。协议现在必须应对两个新增的问题:如何检测分组丢失以及在分组丢失时应采取什么措施。使用 rdt2.2 中已经开发出的技术——校验和、序列号、ACK 分组和重传——可以帮助我们解决后一个问题。处理第一个问题则需要添加新的协议机制。
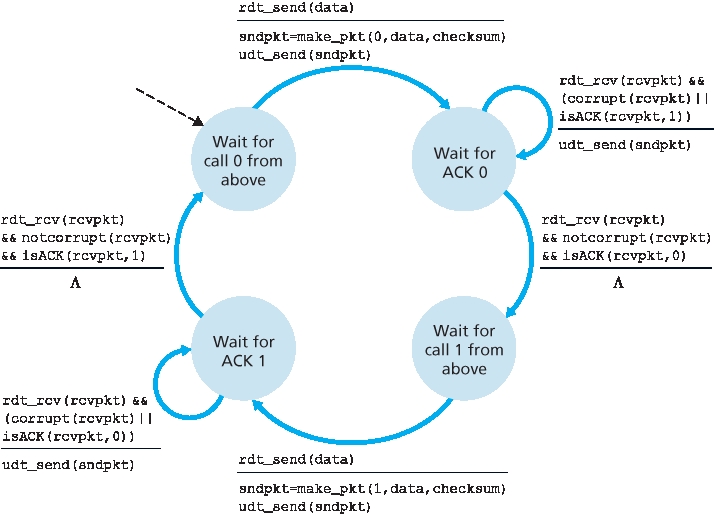
图 3.13 rdt2.2 发送方
处理分组丢失有多种可能的方法(其中一些将在本章末尾的习题中探讨)。在这里,我们将检测和恢复丢包的负担放在发送方。假设发送方发送了一个数据分组,而该分组或接收方对该分组的 ACK 被丢失。在任一情况下,发送方都收不到来自接收方的回应。如果发送方愿意等待足够长的时间,以确信某个分组已经丢失,那么它可以简单地重传该数据分组。你应当确信这个协议确实是可行的。
但是发送方需要等待多久,才能确信某件事情确实丢失了呢?显然,发送方至少需要等待一次发送方与接收方之间的往返延迟(可能包括中间路由器的缓冲延迟)加上接收方处理分组所需的时间。在许多网络中,这种最坏情况下的最大延迟很难估计,更不用说准确知道了。此外,协议理想情况下应尽快从分组丢失中恢复;等待最坏延迟可能意味着在错误恢复启动前会有很长的等待。因此,实际中采用的方法是发送方谨慎地选择一个时间值,使得在该时间内丢包“很可能”已经发生(尽管不能保证)。如果在此时间内未收到 ACK,则重传该分组。注意,如果某个分组遇到特别大的延迟,即使数据分组和 ACK 实际上都未丢失,发送方仍可能重传该分组。这就引入了 重复数据分组 的可能性。幸运的是,协议 rdt2.2 已经具备处理重复分组的功能(即,使用序列号)。
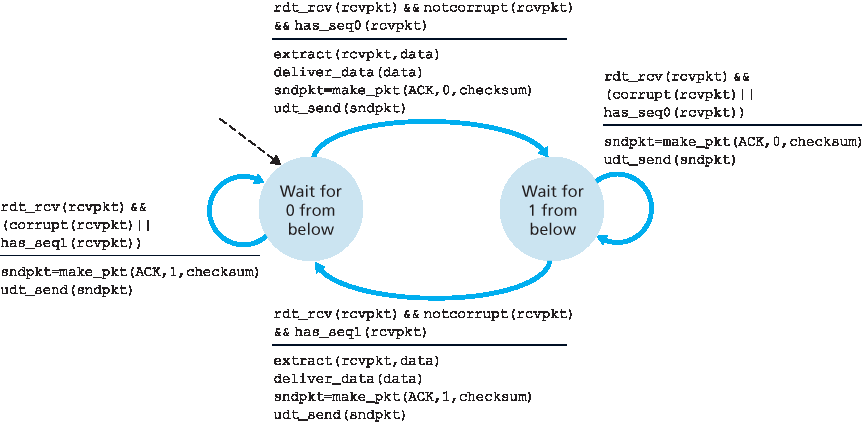
图 3.14 rdt2.2 接收方
从发送方的视角来看,重传是万能药。发送方无法知道是数据分组丢失了,还是 ACK 丢失了,或者只是数据分组或 ACK 被严重延迟。在所有情况下,处理动作都是相同的:重传。实现基于时间的重传机制需要一个 倒计时定时器,它可以在给定时间过后中断发送方。因此发送方需要能够:(1)在每次发送分组(无论是首次还是重传)时启动定时器;(2)响应定时器中断(采取相应措施);(3)停止定时器。
图 3.15 显示了 rdt3.0 的发送方 FSM,该协议能够在可能出现分组损坏或丢失的信道上可靠地传输数据;在习题中,你将被要求给出 rdt3.0 的接收方 FSM。图 3.16 展示了协议在没有丢失或延迟的情况下的操作方式,以及它如何处理丢失的数据分组。在 图 3.16 中,时间从图的顶部向下推进;注意,由于传输和传播延迟,分组的接收时间必然晚于发送时间。在 图 3.16(b) – (d) 中,发送端的方括号表示设置定时器和超时的时间点。本章结尾的习题探讨了该协议中一些更为微妙的方面。由于分组序列号在 0 和 1 之间交替变化,协议 rdt3.0 有时也被称为 交替比特协议(alternating-bit protocol)。
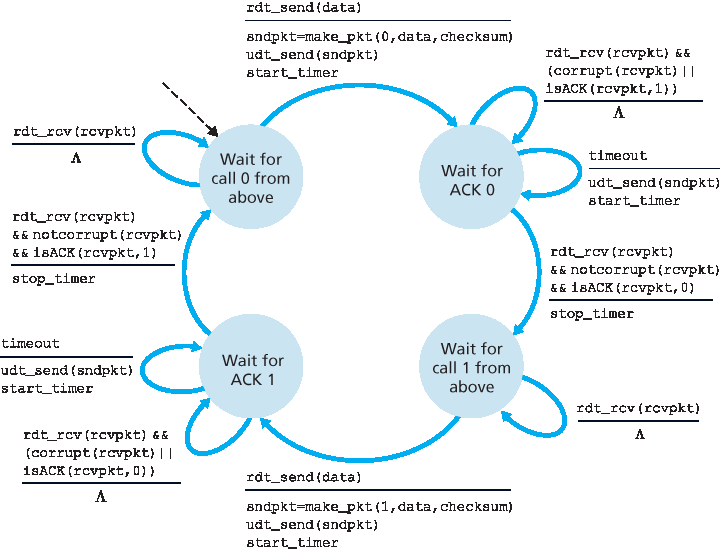
图 3.15 rdt3.0 发送方
我们现在已经组合出了一个数据传输协议的关键元素。校验和、序列号、定时器以及正负确认分组在协议的运行中都发挥着至关重要且必不可少的作用。我们现在拥有一个可以工作的可靠数据传输协议!

为一个简单的应用层协议开发协议与 FSM 表示
Suppose now that in addition to corrupting bits, the underlying channel can lose packets as well, a not- uncommon event in today’s computer networks (including the Internet). Two additional concerns must now be addressed by the protocol: how to detect packet loss and what to do when packet loss occurs. The use of checksumming, sequence numbers, ACK packets, and retransmissions—the techniques already developed in rdt2.2 —will allow us to answer the latter concern. Handling the first concern will require adding a new protocol mechanism.
Figure 3.13 rdt2.2 sender
There are many possible approaches toward dealing with packet loss (several more of which are explored in the exercises at the end of the chapter). Here, we’ll put the burden of detecting and recovering from lost packets on the sender. Suppose that the sender transmits a data packet and either that packet, or the receiver’s ACK of that packet, gets lost. In either case, no reply is forthcoming at the sender from the receiver. If the sender is willing to wait long enough so that it is certain that a packet has been lost, it can simply retransmit the data packet. You should convince yourself that this protocol does indeed work.
But how long must the sender wait to be certain that something has been lost? The sender must clearly wait at least as long as a round-trip delay between the sender and receiver (which may include buffering at intermediate routers) plus whatever amount of time is needed to process a packet at the receiver. In many networks, this worst-case maximum delay is very difficult even to estimate, much less know with certainty. Moreover, the protocol should ideally recover from packet loss as soon as possible; waiting for a worst-case delay could mean a long wait until error recovery is initiated. The approach thus adopted in practice is for the sender to judiciously choose a time value such that packet loss is likely, although not guaranteed, to have happened. If an ACK is not received within this time, the packet is retransmitted. Note that if a packet experiences a particularly large delay, the sender may retransmit the packet even though neither the data packet nor its ACK have been lost. This introduces the possibility of duplicate data packets in the sender-to-receiver channel. Happily, protocol rdt2.2 already has enough functionality (that is, sequence numbers) to handle the case of duplicate packets.
Figure 3.14 rdt2.2 receiver
From the sender’s viewpoint, retransmission is a panacea. The sender does not know whether a data packet was lost, an ACK was lost, or if the packet or ACK was simply overly delayed. In all cases, the action is the same: retransmit. Implementing a time-based retransmission mechanism requires a countdown timer that can interrupt the sender after a given amount of time has expired. The sender will thus need to be able to (1) start the timer each time a packet (either a first-time packet or a retransmission) is sent, (2) respond to a timer interrupt (taking appropriate actions), and (3) stop the timer.
Figure 3.15 shows the sender FSM for rdt3.0, a protocol that reliably transfers data over a channel that can corrupt or lose packets; in the homework problems, you’ll be asked to provide the receiver FSM for rdt3.0. Figure 3.16 shows how the protocol operates with no lost or delayed packets and how it handles lost data packets. In Figure 3.16, time moves forward from the top of the diagram toward the bottom of the diagram; note that a receive time for a packet is necessarily later than the send time for a packet as a result of transmission and propagation delays. In Figures 3.16(b) – (d), the send-side brackets indicate the times at which a timer is set and later times out. Several of the more subtle aspects of this protocol are explored in the exercises at the end of this chapter. Because packet sequence numbers alternate between 0 and 1, protocol rdt3.0 is sometimes known as the alternating-bit protocol.
Figure 3.15 rdt3.0 sender
We have now assembled the key elements of a data transfer protocol. Checksums, sequence numbers, timers, and positive and negative acknowledgment packets each play a crucial and necessary role in the operation of the protocol. We now have a working reliable data transfer protocol!
Developing a protocol and FSM representation for a simple application-layer protocol
3.4.2 流水线式可靠数据传输协议#
3.4.2 Pipelined Reliable Data Transfer Protocols
协议 rdt3.0 是功能上正确的协议,但在性能上恐怕难以令人满意,尤其是在当今的高速网络中。 rdt3.0 性能问题的根本在于它是一个停等协议(stop-and-wait protocol)。
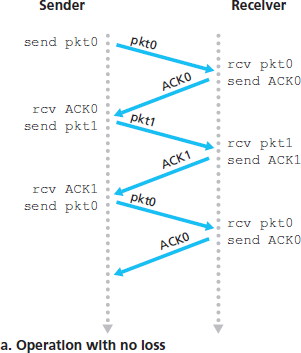
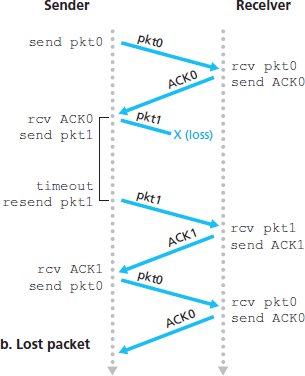
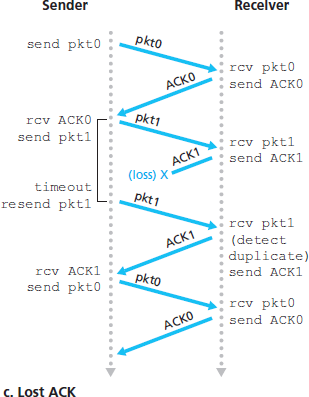
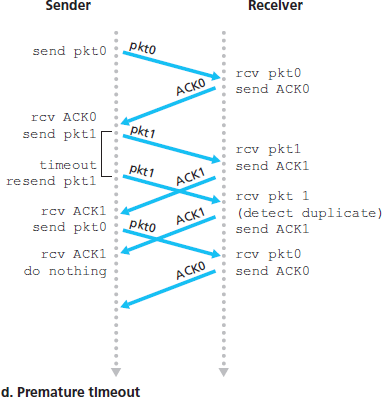
图 3.16 rdt3.0(交替比特协议)的操作过程
图 3.17 停等协议与流水线协议的对比
为了理解这种停等行为对性能的影响,请考虑一个理想化的场景,其中两个主机分别位于美国的西海岸和东海岸,如 图 3.17 所示。这两个端系统之间的光速往返传播延迟(RTT)大约为 30 毫秒。假设它们之间通过一个传输速率为 1 Gbps(\(10^9\) 位每秒)的信道连接。假设每个分组大小为 1,000 字节(8,000 位),包含报头字段和数据,那么将分组传入 1 Gbps 链路所需的时间为:
dtrans = L/R = 8000 bits / 10^9 bits/sec = 8 微秒
图 3.18(a) 显示,使用我们的停等协议时,如果发送方在 t=0 时开始发送分组,则在 t=L/R=8 微秒时,最后一位进入发送方信道。随后该分组开始其 15 毫秒的跨国旅程,在 t=RTT/2 + L/R = 15.008 毫秒时,最后一位从接收方接收器中发出。为了简化分析,假设 ACK 分组非常小(可忽略其传输时间),且接收方在收到数据分组的最后一位时立即发送 ACK,那么该 ACK 会在 t=RTT + L/R = 30.008 毫秒时回到发送方。此时,发送方可以发送下一个消息。因此,在 30.008 毫秒内,发送方实际传输的时间只有 0.008 毫秒。如果我们将发送方(或信道)的 利用率 定义为发送方真正忙于将比特发送到信道中的时间比例,那么 图 3.18(a) 中的分析表明,停等协议的发送方利用率 \(U_{sender}\) 为:
Usender = L/R / (RTT + L/R) = 0.008 / 30.008 = 0.00027
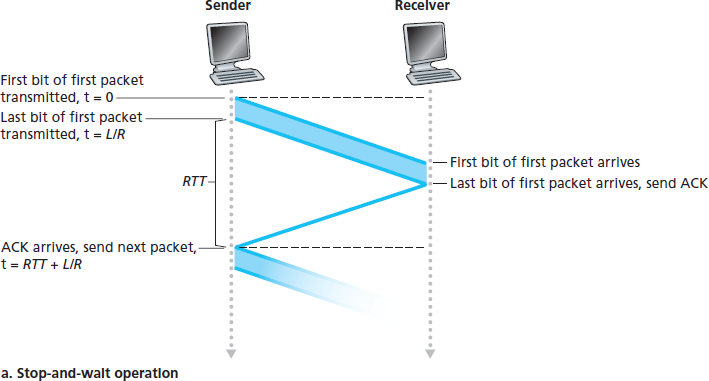
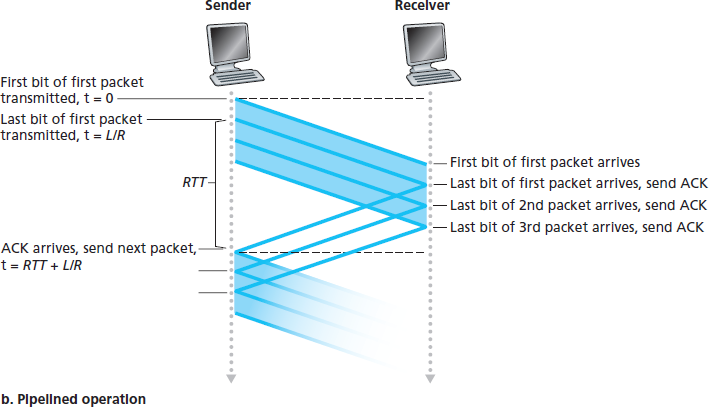
图 3.18 停等发送与流水线发送
也就是说,发送方只有 0.027% 的时间在真正忙碌地工作!换种角度看,发送方在 30.008 毫秒内仅发送了 1,000 字节,有效吞吐量只有 267 kbps——尽管有一个 1 Gbps 的链路可用!想象一下网络管理员花费巨资购买了一条千兆链路,但却只能得到每秒 267 千位的吞吐量,他该有多沮丧!这是网络协议限制底层网络硬件能力的直观示例。同时我们还忽略了发送方与接收方在低层协议中的处理时间,以及在它们之间任意中间路由器上的处理与排队延迟。若将这些因素计入,只会进一步加大延迟并加剧性能不佳的问题。
解决这个性能问题的方法其实很简单:与其采用停等方式,不如允许发送方在等待确认之前发送多个分组,如 图 3.17(b) 所示。图 3.18 显示,如果允许发送方在等待确认前发送三个分组,则发送方利用率本质上提升了三倍。由于多个从发送方向接收方在途的分组可以想象为填满一条流水线,这种技术被称为 流水线(pipelining) 。流水线机制对可靠数据传输协议带来如下影响:
必须增加序列号的范围,因为每个在途分组(不含重传)必须有唯一的序列号,并且可能存在多个在途但尚未确认的分组。
协议的发送方与接收方都可能需要缓存多个分组。至少,发送方必须缓存那些已发送但尚未被确认的分组。接收方可能也需要缓存正确接收的分组,详见后文。
所需序列号的范围及缓存需求将取决于数据传输协议应对丢失、损坏和严重延迟分组的方式。可识别出两种基本的流水线错误恢复机制: 回退 N(Go-Back-N) 和 选择重传(Selective Repeat)。
Protocol rdt3.0 is a functionally correct protocol, but it is unlikely that anyone would be happy with its performance, particularly in today’s high-speed networks. At the heart of rdt3.0’s performance problem is the fact that it is a stop-and-wait protocol.
Figure 3.16 Operation of rdt3.0, the alternating-bit protocol
Figure 3.17 Stop-and-wait versus pipelined protocol
To appreciate the performance impact of this stop-and-wait behavior, consider an idealized case of two hosts, one located on the West Coast of the United States and the other located on the East Coast, as shown in Figure 3.17. The speed-of-light round-trip propagation delay between these two end systems, RTT, is approximately 30 milliseconds. Suppose that they are connected by a channel with a transmission rate, R, of 1 Gbps (\(10^9\) bits per second). With a packet size, L, of 1,000 bytes (8,000 bits) per packet, including both header fields and data, the time needed to actually transmit the packet into the 1 Gbps link is
dtrans=LR=8000 bits/packet109 bits/sec=8 microseconds
Figure 3.18(a) shows that with our stop-and-wait protocol, if the sender begins sending the packet at t=0, then at t=L/R=8 microseconds, the last bit enters the channel at the sender side. The packet then makes its 15-msec cross-country journey, with the last bit of the packet emerging at the receiver at t=RTT/2+L/R= 15.008 msec. Assuming for simplicity that ACK packets are extremely small (so that we can ignore their transmission time) and that the receiver can send an ACK as soon as the last bit of a data packet is received, the ACK emerges back at the sender at t=RTT+L/R=30.008 msec. At this point, the sender can now transmit the next message. Thus, in 30.008 msec, the sender was sending for only 0.008 msec. If we define the utilization of the sender (or the channel) as the fraction of time the sender is actually busy sending bits into the channel, the analysis in Figure 3.18(a) shows that the stop-and- wait protocol has a rather dismal sender utilization, \(U_{sender}\), of
Usender=L/RRTT+L/R =.00830.008=0.00027
Figure 3.18 Stop-and-wait and pipelined sending
That is, the sender was busy only 2.7 hundredths of one percent of the time! Viewed another way, the sender was able to send only 1,000 bytes in 30.008 milliseconds, an effective throughput of only 267 kbps—even though a 1 Gbps link was available! Imagine the unhappy network manager who just paid a fortune for a gigabit capacity link but manages to get a throughput of only 267 kilobits per second! This is a graphic example of how network protocols can limit the capabilities provided by the underlying network hardware. Also, we have neglected lower-layer protocol-processing times at the sender and receiver, as well as the processing and queuing delays that would occur at any intermediate routers between the sender and receiver. Including these effects would serve only to further increase the delay and further accentuate the poor performance.
The solution to this particular performance problem is simple: Rather than operate in a stop-and-wait manner, the sender is allowed to send multiple packets without waiting for acknowledgments, as illustrated in Figure 3.17(b). Figure 3.18 shows that if the sender is allowed to transmit three packets before having to wait for acknowledgments, the utilization of the sender is essentially tripled. Since the many in-transit sender-to-receiver packets can be visualized as filling a pipeline, this technique is known as pipelining. Pipelining has the following consequences for reliable data transfer protocols:
The range of sequence numbers must be increased, since each in-transit packet (not counting retransmissions) must have a unique sequence number and there may be multiple, in-transit, unacknowledged packets.
The sender and receiver sides of the protocols may have to buffer more than one packet. Minimally, the sender will have to buffer packets that have been transmitted but not yet acknowledged. Buffering of correctly received packets may also be needed at the receiver, as discussed below.
The range of sequence numbers needed and the buffering requirements will depend on the manner in which a data transfer protocol responds to lost, corrupted, and overly delayed packets. Two basic approaches toward pipelined error recovery can be identified: Go-Back-N and selective repeat.
3.4.3 回退 N(GBN)#
3.4.3 Go-Back-N (GBN)
在 回退 N(Go-Back-N, GBN)协议 中,发送方被允许在不等待确认的情况下发送多个分组(如果有可用分组),但必须保证在流水线中未被确认的分组不超过某个最大允许数 N。本节我们将较为详细地描述 GBN 协议。但在继续阅读之前,建议你可以先玩一玩配套网站上的 GBN 小程序(这是一个很棒的小程序!)。

图 3.19 回退 N 中发送方对序列号的视图
图 3.19 展示了 GBN 协议中发送方对序列号范围的理解。如果我们定义 base 为最老的未被确认分组的序列号, nextseqnum 为当前尚未使用的最小序列号(即下一个将要发送的分组的序列号),那么可以识别出序列号范围中的四个区间。序列号位于 [0, base-1] 区间的分组已被发送并得到确认;[base, nextseqnum-1] 区间表示已发送但尚未被确认的分组; [nextseqnum, base+N-1] 区间表示若上层有数据到达,可以立即发送的分组;而序列号大于等于 base+N 的分组在流水线中有分组尚未确认(特别是序列号为 base 的分组)之前是不能发送的。
正如 图 3.19 所示,已发送但尚未被确认的分组序列号范围可被视为在序列号空间上的一个大小为 N 的窗口。随着协议的运行,这个窗口会沿着序列号空间向前滑动。因此,N 窗口大小,而 GBN 协议则称为 滑动窗口协议。你可能会疑惑,为什么一开始我们要对未确认分组的数量设置上限 N?为什么不允许无限数量的这类分组?我们将在 第 3.5 节 看到,流量控制是限制发送方的一个原因。而在 第 3.7 节 研究 TCP 拥塞控制时将看到另一个原因。
实际中,分组的序列号会被携带在报文头中的一个定长字段中。如果该字段为 k 位,则序列号范围为 [0, 2^k-1]。由于序列号范围有限,所有与序列号有关的算术运算必须使用模 2^k 算法(也就是说,序列号空间可以被看作是一个大小为 2^k 的环,其中序列号 2^k-1 紧跟着序列号 0)。回忆一下 rdt3.0 中的 1 比特序列号,其范围为 [0,1]。本章末尾的一些问题将探索序列号范围有限的后果。我们将在 第 3.5 节 中看到,TCP 使用 32 位序列号字段,且其序列号是对字节流中的字节进行计数,而不是对分组计数。
图 3.20 和 图 3.21 给出了 ACK 驱动、无 NAK 的 GBN 协议中发送方与接收方的扩展 FSM 表示。我们将此 FSM 表示称为扩展 FSM,因为其中增加了变量(类似于编程语言中的变量)如 base 和 nextseqnum,并添加了对这些变量的操作以及与这些变量有关的条件动作。注意,这个扩展 FSM 说明看起来已经开始有点像编程语言的形式了。[Bochman 1984] 提供了对 FSM 技术进一步扩展以及其他基于编程语言的协议描述技术的精彩综述。
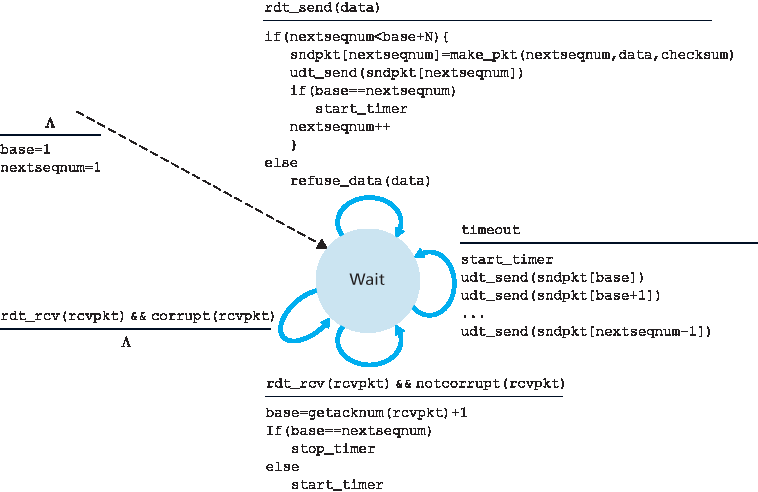
图 3.20 GBN 发送方的扩展 FSM 描述
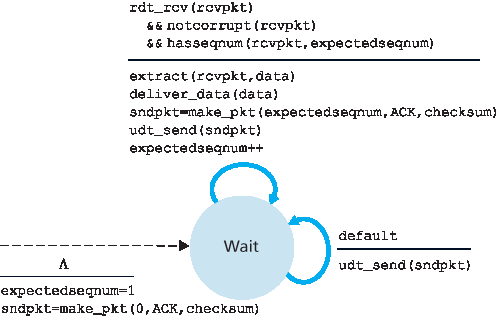
图 3.21 GBN 接收方的扩展 FSM 描述
GBN 发送方必须响应三种类型的事件:
来自上层的调用。当
rdt_send()被上层调用时,发送方首先检查窗口是否已满,即当前是否已有 N 个未确认分组在途。如果窗口未满,则创建并发送一个分组,并更新相应变量;如果窗口已满,则将数据返回上层,隐式表明窗口已满。上层此时应稍后再试。在实际实现中,发送方更可能会缓存(但暂不发送)这条数据,或提供一种同步机制(如信号量或标志位),允许上层仅在窗口未满时调用rdt_send()。收到 ACK。在 GBN 协议中,某个序号为 n 的 ACK 被视为 累计确认 ,表示所有序号不大于 n 的分组都已被接收方正确接收。稍后在讨论 GBN 接收方时,我们会再次提到这一点。
超时事件。协议名称 “Go-Back-N” 来源于当出现丢失或严重延迟的分组时发送方的行为。与停等协议类似,GBN 也使用定时器来恢复丢失的数据或确认分组。如果发生超时事件,发送方将重传所有已发送但尚未被确认的分组。图 3.20 中的发送方只使用一个定时器,可视为针对最早发送但尚未确认分组的定时器。如果收到一个 ACK 且仍有其它未确认分组存在,则重新启动定时器;若所有分组均已确认,则停止定时器。
GBN 接收方的行为也很简单。如果收到一个序号为 n 的分组,且该分组正确无误且按序(即上一次交付给上层的数据来自序号为 n-1 的分组),则发送 ACK(n),并将该分组中的数据交付上层。否则,接收方将丢弃该分组,并重新发送最近一个按序接收分组的 ACK。注意由于分组是一条条交付给上层的,如果分组 k 已被接收并交付,则所有序号小于 k 的分组也必然已被交付。因此使用累计确认对 GBN 是一种自然选择。
在 GBN 协议中,接收方会丢弃乱序的分组。虽然丢弃一个正确接收但乱序的分组看似愚蠢和浪费,但这种做法也有一定合理性。回忆一下接收方必须按序将数据交付给上层。假设现在期望接收分组 n,却收到了分组 n+1。由于必须按序交付数据,接收方 可以 先缓冲分组 n+1,然后在后续收到并交付分组 n 后再将其交付上层。但如果分组 n 丢失,根据 GBN 的重传规则,发送方最终将重发分组 n 和 n+1。因此接收方可以直接丢弃分组 n+1。这种做法的优点在于接收方的缓冲机制简单——无需缓存任何乱序分组。因此发送方需要维护其窗口的上下边界及 nextseqnum 在窗口中的位置,而接收方只需维护一个信息:下一个按序分组的序列号。该值存储在接收方 FSM 中变量 expectedseqnum 中,如 图 3.21 所示。当然,丢弃一个正确接收的分组的缺点在于后续该分组的重传可能也会丢失或损坏,从而需要更多的重传。
图 3.22 展示了窗口大小为 4 的 GBN 协议运行过程。由于窗口大小受限,发送方可以发送分组 0 到 3,但必须在收到这些分组中的至少一个确认之后才能继续发送。每当收到一个新的 ACK(例如 ACK0 和 ACK1),窗口就向前滑动一次,发送方就可以发送一个新的分组(分别为 pkt4 和 pkt5)。在接收方,分组 2 丢失,因此分组 3、4 和 5 被判断为乱序并被丢弃。
在结束 GBN 协议的讨论之前,值得注意的是该协议在协议栈中实现时,其结构很可能与 图 3.20 中的扩展 FSM 类似。其实现形式也很可能是多个过程,分别用于处理可能发生的各种事件。在这种**事件驱动编程**中,各个过程要么由协议栈中的其他过程调用,要么作为中断的响应被调用。在发送方,这些事件包括:(1)上层实体调用 rdt_send();(2)定时器中断;(3)底层收到分组后调用 rdt_rcv()。本章末尾的编程练习将让你有机会在模拟但真实的网络环境中实际实现这些函数。
我们在此指出,GBN 协议几乎包含了我们在 第 3.5 节 中学习 TCP 可靠数据传输组件时会遇到的所有技术。这些技术包括使用序列号、累计确认、校验和以及超时/重传操作。
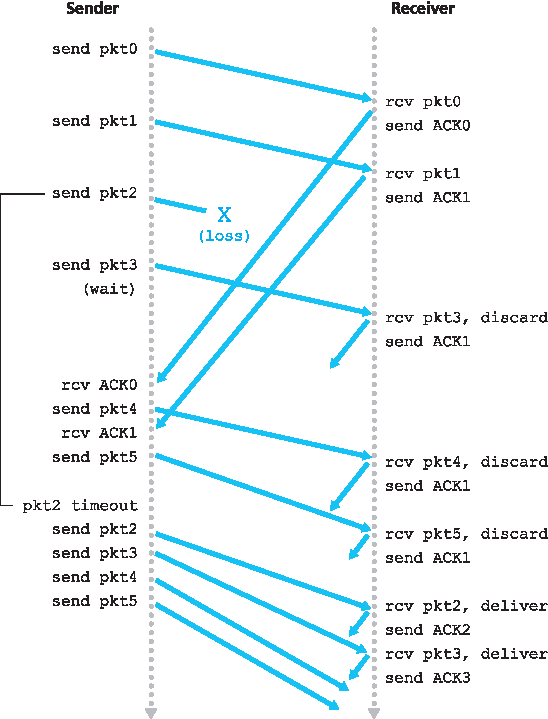
图 3.22 回退 N 的运行过程
In a Go-Back-N (GBN) protocol, the sender is allowed to transmit multiple packets (when available) without waiting for an acknowledgment, but is constrained to have no more than some maximum allowable number, N, of unacknowledged packets in the pipeline. We describe the GBN protocol in some detail in this section. But before reading on, you are encouraged to play with the GBN applet (an awesome applet!) at the companion Web site.
Figure 3.19 Sender’s view of sequence numbers in Go-Back-N
Figure 3.19 shows the sender’s view of the range of sequence numbers in a GBN protocol. If we define base to be the sequence number of the oldest unacknowledged packet and nextseqnum to be the smallest unused sequence number (that is, the sequence number of the next packet to be sent), then four intervals in the range of sequence numbers can be identified. Sequence numbers in the interval [0, base-1] correspond to packets that have already been transmitted and acknowledged. The interval [base, nextseqnum-1] corresponds to packets that have been sent but not yet acknowledged. Sequence numbers in the interval [nextseqnum, base+N-1] can be used for packets that can be sent immediately, should data arrive from the upper layer. Finally, sequence numbers greater than or equal to base+N cannot be used until an unacknowledged packet currently in the pipeline (specifically, the packet with sequence number base) has been acknowledged.
As suggested by Figure 3.19, the range of permissible sequence numbers for transmitted but not yet acknowledged packets can be viewed as a window of size N over the range of sequence numbers. As the protocol operates, this window slides forward over the sequence number space. For this reason, N is often referred to as the window size and the GBN protocol itself as a sliding-window protocol. You might be wondering why we would even limit the number of outstanding, unacknowledged packets to a value of N in the first place. Why not allow an unlimited number of such packets? We’ll see in Section 3.5 that flow control is one reason to impose a limit on the sender. We’ll examine another reason to do so in Section 3.7, when we study TCP congestion control.
In practice, a packet’s sequence number is carried in a fixed-length field in the packet header. If k is the number of bits in the packet sequence number field, the range of sequence numbers is thus [0,2k−1]. With a finite range of sequence numbers, all arithmetic involving sequence numbers must then be done using modulo 2k arithmetic. (That is, the sequence number space can be thought of as a ring of size 2k, where sequence number 2k−1 is immediately followed by sequence number 0.) Recall that rdt3.0 had a 1-bit sequence number and a range of sequence numbers of [0,1]. Several of the problems at the end of this chapter explore the consequences of a finite range of sequence numbers. We will see in Section 3.5 that TCP has a 32-bit sequence number field, where TCP sequence numbers count bytes in the byte stream rather than packets.
Figures 3.20 and 3.21 give an extended FSM description of the sender and receiver sides of an ACK- based, NAK-free, GBN protocol. We refer to this FSM description as an extended FSM because we have added variables (similar to programming-language variables) for base and nextseqnum, and added operations on these variables and conditional actions involving these variables. Note that the extended FSM specification is now beginning to look somewhat like a programming-language specification. [Bochman 1984] provides an excellent survey of additional extensions to FSM techniques as well as other programming-language-based techniques for specifying protocols.
Figure 3.20 Extended FSM description of the GBN sender
Figure 3.21 Extended FSM description of the GBN receiver
The GBN sender must respond to three types of events:
Invocation from above. When
rdt_send()is called from above, the sender first checks to see if the window is full, that is, whether there are N outstanding, unacknowledged packets. If the window is not full, a packet is created and sent, and variables are appropriately updated. If the window is full, the sender simply returns the data back to the upper layer, an implicit indication that the window is full. The upper layer would presumably then have to try again later. In a real implementation, the sender would more likely have either buffered (but not immediately sent) this data, or would have a synchronization mechanism (for example, a semaphore or a flag) that would allow the upper layer to callrdt_send()only when the window is not full.Receipt of an ACK. In our GBN protocol, an acknowledgment for a packet with sequence number n will be taken to be a cumulative acknowledgment, indicating that all packets with a sequence number up to and including n have been correctly received at the receiver. We’ll come back to this issue shortly when we examine the receiver side of GBN.
A timeout event. The protocol’s name, “Go-Back-N,” is derived from the sender’s behavior in the presence of lost or overly delayed packets. As in the stop-and-wait protocol, a timer will again be used to recover from lost data or acknowledgment packets. If a timeout occurs, the sender resends all packets that have been previously sent but that have not yet been acknowledged. Our sender in Figure 3.20 uses only a single timer, which can be thought of as a timer for the oldest transmitted but not yet acknowledged packet. If an ACK is received but there are still additional transmitted but not yet acknowledged packets, the timer is restarted. If there are no outstanding, unacknowledged packets, the timer is stopped.
The receiver’s actions in GBN are also simple. If a packet with sequence number n is received correctly and is in order (that is, the data last delivered to the upper layer came from a packet with sequence number n−1), the receiver sends an ACK for packet n and delivers the data portion of the packet to the upper layer. In all other cases, the receiver discards the packet and resends an ACK for the most recently received in-order packet. Note that since packets are delivered one at a time to the upper layer, if packet k has been received and delivered, then all packets with a sequence number lower than k have also been delivered. Thus, the use of cumulative acknowledgments is a natural choice for GBN.
In our GBN protocol, the receiver discards out-of-order packets. Although it may seem silly and wasteful to discard a correctly received (but out-of-order) packet, there is some justification for doing so. Recall that the receiver must deliver data in order to the upper layer. Suppose now that packet n is expected, but packet n+1 arrives. Because data must be delivered in order, the receiver could buffer (save) packet n+1 and then deliver this packet to the upper layer after it had later received and delivered packet n. However, if packet n is lost, both it and packet n+1 will eventually be retransmitted as a result of the GBN retransmission rule at the sender. Thus, the receiver can simply discard packet n+1. The advantage of this approach is the simplicity of receiver buffering—the receiver need not buffer any out- of-order packets. Thus, while the sender must maintain the upper and lower bounds of its window and the position of nextseqnum within this window, the only piece of information the receiver need maintain is the sequence number of the next in-order packet. This value is held in the variable expectedseqnum, shown in the receiver FSM in Figure 3.21. Of course, the disadvantage of throwing away a correctly received packet is that the subsequent retransmission of that packet might be lost or garbled and thus even more retransmissions would be required.
Figure 3.22 shows the operation of the GBN protocol for the case of a window size of four packets. Because of this window size limitation, the sender sends packets 0 through 3 but then must wait for one
or more of these packets to be acknowledged before proceeding. As each successive ACK (for
example, ACK0 and ACK1) is received, the window slides forward and the sender can transmit one new packet (pkt4 and pkt5, respectively). On the receiver side, packet 2 is lost and thus packets 3, 4, and 5 are found to be out of order and are discarded.
Before closing our discussion of GBN, it is worth noting that an implementation of this protocol in a protocol stack would likely have a structure similar to that of the extended FSM in Figure 3.20. The implementation would also likely be in the form of various procedures that implement the actions to be taken in response to the various events that can occur. In such event-based programming, the various procedures are called (invoked) either by other procedures in the protocol stack, or as the result of an interrupt. In the sender, these events would be (1) a call from the upper-layer entity to invoke rdt_send(), (2) a timer interrupt, and (3) a call from the lower layer to invoke rdt_rcv() when a packet arrives. The programming exercises at the end of this chapter will give you a chance to actually implement these routines in a simulated, but realistic, network setting.
We note here that the GBN protocol incorporates almost all of the techniques that we will encounter when we study the reliable data transfer components of TCP in Section 3.5. These techniques include the use of sequence numbers, cumulative acknowledgments, checksums, and a timeout/retransmit operation.
Figure 3.22 Go-Back-N in operation
3.4.4 选择性重传(SR)#
3.4.4 Selective Repeat (SR)
GBN 协议允许发送方在 图 3.17 中将多个分组“填满流水线”,从而避免了停等协议中我们指出的信道利用率问题。然而,GBN 本身在某些场景下也会遭遇性能问题。特别地,当窗口大小和带宽-时延积都很大时,流水线中可能存在大量分组。此时,单个分组的错误可能会导致 GBN 重传大量分组,其中许多实际上并不需要重传。随着信道错误概率的增加,流水线可能会被这些不必要的重传填满。想象一下,在口述文本的场景中,每当一个词语被听错时,周围的 1,000 个词语(例如,窗口大小为 1,000)都必须重新朗读一遍。整个口述过程将因重复内容而变得极为缓慢。
顾名思义,选择性重传协议通过仅对发送方怀疑接收方未正确接收(即丢失或损坏)的分组进行重传,从而避免不必要的重传。这种按需、逐个分组的重传要求接收方对每个正确接收的分组单独确认。仍然使用大小为 N 的窗口来限制流水线中未确认分组的数量。但与 GBN 不同,发送方可能已经收到窗口内部分分组的 ACK。图 3.23 展示了 SR 发送方对序列号空间的视图。图 3.24 详细列出了 SR 发送方所采取的各种操作。
SR 接收方将对每一个正确接收的分组发送确认,无论该分组是否按序。乱序分组会被缓存在接收方,直到所有丢失的(即序号较小的)分组被接收到,此时一批按序分组将被交付给上层。图 3.25 枚举了 SR 接收方所采取的各种操作。图 3.26 展示了在存在分组丢失的情况下 SR 的运行过程。注意,在 图 3.26 中,接收方最初缓存了分组 3、4 和 5,并在最终收到分组 2 后,将这些分组与分组 2 一起交付给上层。
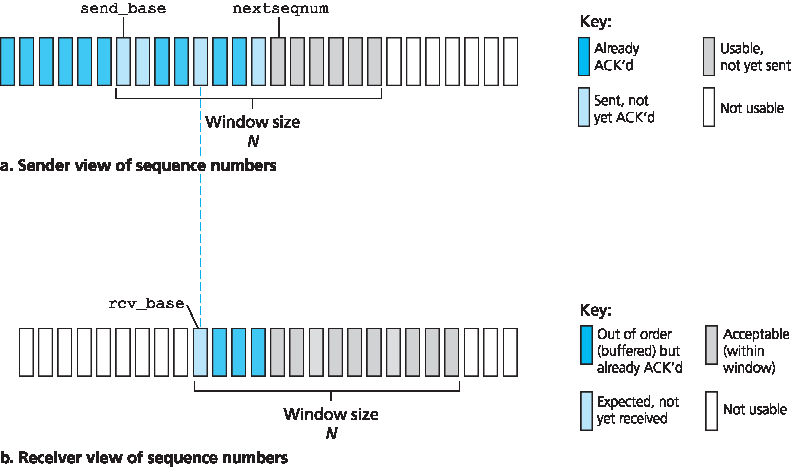
图 3.23 选择性重传(SR)发送方与接收方对序列号空间的视图
来自上层的数据被接收。当来自上层的数据到达时,SR 发送方会检查用于该分组的下一个可用序列号。如果该序列号位于发送窗口之内,则将数据封装成分组并发送;否则,和 GBN 中一样,要么将其缓存在本地,要么返回给上层以待稍后发送。
超时。定时器仍用于防止分组丢失。然而,现在每个分组必须拥有自己独立的逻辑定时器,因为超时后只会重新发送一个分组。一个硬件定时器可以用来模拟多个逻辑定时器的操作 [Varghese 1997]。
ACK 被接收。如果接收到 ACK,SR 发送方会将该分组标记为已接收,前提是它位于发送窗口之内。如果该分组的序列号等于
send_base,则将窗口基准移动到尚未确认的、序列号最小的分组处。如果窗口因此向前移动,并且有一些尚未发送的分组,其序列号现在已落入窗口范围,则立即发送这些分组。

图 3.24 SR 发送方的事件与操作
序列号在 [
rcv_base,rcv_base+N-1] 范围内的分组被正确接收。在这种情况下,接收到的分组位于接收方的窗口之内,接收方会向发送方返回一个选择性确认(selective ACK)分组。如果该分组此前未被接收过,则将其缓存在接收方。如果该分组的序列号等于接收窗口的起始值(图 3.22 中的rcv_base),则该分组以及从rcv_base开始按序号连续的、已缓存在接收方的分组将一并交付给上层。随后,接收窗口向前移动已交付给上层的分组数量。例如,参见 图 3.26。当序列号为rcv_base=2的分组被接收时,它以及分组 3、4 和 5 可以一并交付给上层。序列号在 [
rcv_base-N,rcv_base-1] 范围内的分组被正确接收。在这种情况下,即使该分组此前已被接收方确认过,仍必须生成一个 ACK。否则,忽略该分组。

图 3.25 SR 接收方的事件与操作
需要特别注意的是,在 图 3.25 中的第 2 步中,接收方会对窗口基线以下某些序列号的已接收分组重新确认(而非忽略它们)。你应该确信这种重新确认确实是必要的。以 图 3.23 中的发送方与接收方的序列号空间为例,如果发送方未能收到来自接收方的 send_base 分组的 ACK,发送方最终将重传该分组 send_base,尽管我们(但不是发送方)清楚接收方已经收到该分组。如果接收方不去确认这个分组,那么发送方的窗口将永远无法前移!这个例子说明了 SR 协议(以及许多其他协议)中的一个重要方面:发送方和接收方对哪些分组已被正确接收、哪些未被正确接收的理解可能并不一致。对于 SR 协议来说,这意味着发送方与接收方的窗口不会总是重合。
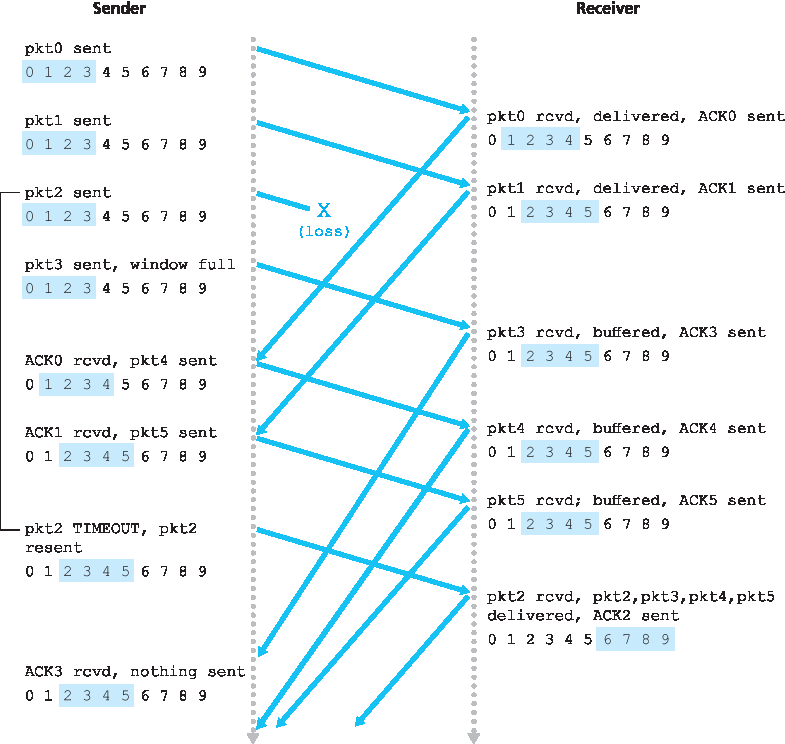
图 3.26 SR 的运行过程
发送方与接收方窗口之间缺乏同步的现实在面对有限序列号空间时具有重要影响。举个例子,假设序列号空间有限,仅有四个分组序列号 0、1、2、3,窗口大小为 3。设想发送方传输了分组 0 到 2,并且接收方成功接收并确认了这三个分组。此时,接收方的窗口已滑动至第 4、5、6 个分组,序列号分别为 3、0 和 1。现在考虑两种情况:在第一种情况下,如 图 3.27(a) 所示,前面三个分组的 ACK 丢失,发送方重传这些分组。因此,接收方接收到一个序列号为 0 的分组——即第一个分组的副本。
在第二种情况中,如 图 3.27(b) 所示,前三个分组的 ACK 均成功到达发送方。发送方因此前移其窗口,并发送第 4、5、6 个分组,序列号分别为 3、0 和 1。分组 3 丢失,但序列号为 0 的分组到达了接收方——这个分组包含的是 新 数据。
现在考虑接收方在 图 3.27 中的视角,其视野中有一层“幕布”,因为接收方无法“看到”发送方的动作。接收方只能观察到它从信道接收到的消息序列以及它发送到信道中的消息序列。就接收方而言,这两种场景在观察结果上是一样的。它无法区分是第一个分组的重传,还是第五个分组的原始传输。显然,窗口大小若为序列号空间大小减一是不可行的。那么窗口必须多小才可以?本章结尾的一个问题要求你证明,对于 SR 协议,窗口大小必须小于或等于序列号空间的一半。
在配套网站上,你将找到一个动画展示 SR 协议运行过程的小程序。可以尝试进行与 GBN 小程序中相同的实验。实验结果是否与你的预期一致?
这就完成了我们对可靠数据传输协议的讨论。我们涵盖了大量内容,并介绍了多个机制,它们共同实现了可靠数据传输。表 3.1 总结了这些机制。现在你已经看到所有机制如何协同工作,并形成“完整图景”,我们鼓励你重新阅读本节,以体会这些机制是如何逐步添加的,从而适应越来越复杂(更现实)的发送方与接收方之间信道模型,或是提升协议性能。
让我们通过讨论底层信道模型中一个剩余假设来结束可靠数据传输协议的内容。回忆我们曾假设发送方与接收方之间的信道不会对分组重新排序。当发送方与接收方通过单根物理线路连接时,这通常是合理的假设。然而,当两者之间的“信道”是网络时,分组重新排序就有可能发生。重新排序的一种表现是:某个序列号或确认号为 x 的旧分组副本可能重新出现,即使发送方与接收方的窗口中都已不再包含 x。在发生重新排序的情况下,信道可以被认为是在缓冲分组,并可在未来任意时刻自发释放这些分组。由于序列号可能被复用,因此必须采取一些措施防止这些重复分组。在实际中常用的做法是确保在发送方“确信”之前发送的序列号为 x 的分组已不再存在于网络中之前,不会再次使用该序列号。这通常通过假设一个分组在网络中不会“存活”超过某个最大时间值来实现。在高速网络的 TCP 扩展 [RFC 1323] 中,最大分组生存时间约为三分钟。[Sunshine 1978] 描述了一种使用序列号的方法,可完全避免重新排序问题。
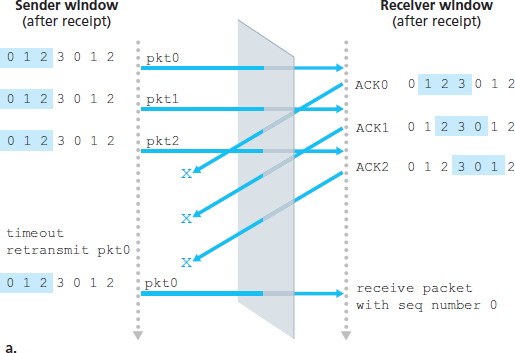
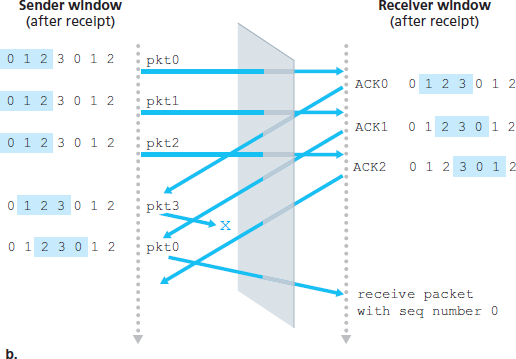
图 3.27 当窗口过大时 SR 接收方的困境:这是新分组,还是重传?
表 3.1 可靠数据传输机制及其用途概览
机制 |
用途与说明 |
校验和 |
用于检测传输分组中的比特错误。 |
定时器 |
用于超时/重传分组,可能是因为分组(或其 ACK)在信道中丢失。由于定时器可能在分组只是延迟但未丢失时触发(称为提前超时),或在分组已被接收但 ACK 丢失时触发,因此接收方可能会收到分组的重复副本。 |
序列号 |
用于对从发送方到接收方的数据分组进行顺序编号。接收方可以通过检测序列号中的间隙来识别丢失分组。接收到具有重复序列号的分组时,可以识别出分组副本。 |
确认(ACK) |
接收方用于告知发送方分组或一组分组已正确接收。确认通常包含被确认的分组的序列号。确认可以是单个确认,也可以是累计确认,具体取决于协议。 |
否认(NAK) |
接收方用于告知发送方某个分组未被正确接收。否认通常包含未被正确接收的分组的序列号。 |
窗口、流水线 |
发送方可能被限制为只能发送序列号位于某个范围内的分组。通过允许多个分组被发送而尚未确认,可提升发送方在相对于停等模式下的利用率。稍后我们将看到,窗口大小可以根据接收方接收与缓存消息的能力、网络中的拥塞程度,或两者的结合来设定。 |
The GBN protocol allows the sender to potentially “fill the pipeline” in Figure 3.17 with packets, thus avoiding the channel utilization problems we noted with stop-and-wait protocols. There are, however, scenarios in which GBN itself suffers from performance problems. In particular, when the window size and bandwidth-delay product are both large, many packets can be in the pipeline. A single packet error can thus cause GBN to retransmit a large number of packets, many unnecessarily. As the probability of channel errors increases, the pipeline can become filled with these unnecessary retransmissions. Imagine, in our message-dictation scenario, that if every time a word was garbled, the surrounding 1,000 words (for example, a window size of 1,000 words) had to be repeated. The dictation would be slowed by all of the reiterated words.
As the name suggests, selective-repeat protocols avoid unnecessary retransmissions by having the sender retransmit only those packets that it suspects were received in error (that is, were lost or corrupted) at the receiver. This individual, as-needed, retransmission will require that the receiver individually acknowledge correctly received packets. A window size of N will again be used to limit the number of outstanding, unacknowledged packets in the pipeline. However, unlike GBN, the sender will have already received ACKs for some of the packets in the window. Figure 3.23 shows the SR sender’s view of the sequence number space. Figure 3.24 details the various actions taken by the SR sender.
The SR receiver will acknowledge a correctly received packet whether or not it is in order. Out-of-order packets are buffered until any missing packets (that is, packets with lower sequence numbers) are received, at which point a batch of packets can be delivered in order to the upper layer. Figure 3.25 itemizes the various actions taken by the SR receiver. Figure 3.26 shows an example of SR operation in the presence of lost packets. Note that in Figure 3.26, the receiver initially buffers packets 3, 4, and 5, and delivers them together with packet 2 to the upper layer when packet 2 is finally received.
Figure 3.23 Selective-repeat (SR) sender and receiver views of sequence-number space
Figure 3.24 SR sender events and actions
Figure 3.25 SR receiver events and actions
It is important to note that in Step 2 in Figure 3.25, the receiver reacknowledges (rather than ignores) already received packets with certain sequence numbers below the current window base. You should convince yourself that this reacknowledgment is indeed needed. Given the sender and receiver sequence number spaces in Figure 3.23, for example, if there is no ACK for packet send_base propagating from the receiver to the sender, the sender will eventually retransmit packet send_base, even though it is clear (to us, not the sender!) that the receiver has already received that packet. If the receiver were not to acknowledge this packet, the sender’s window would never move forward! This example illustrates an important aspect of SR protocols (and many other protocols as well). The sender and receiver will not always have an identical view of what has been received correctly and what has not. For SR protocols, this means that the sender and receiver windows will not always coincide.
Figure 3.26 SR operation
The lack of synchronization between sender and receiver windows has important consequences when we are faced with the reality of a finite range of sequence numbers. Consider what could happen, for example, with a finite range of four packet sequence numbers, 0, 1, 2, 3, and a window size of three. Suppose packets 0 through 2 are transmitted and correctly received and acknowledged at the receiver. At this point, the receiver’s window is over the fourth, fifth, and sixth packets, which have sequence numbers 3, 0, and 1, respectively. Now consider two scenarios. In the first scenario, shown in Figure 3.27(a), the ACKs for the first three packets are lost and the sender retransmits these packets. The receiver thus next receives a packet with sequence number 0—a copy of the first packet sent.
In the second scenario, shown in Figure 3.27(b), the ACKs for the first three packets are all delivered correctly. The sender thus moves its window forward and sends the fourth, fifth, and sixth packets, with sequence numbers 3, 0, and 1, respectively. The packet with sequence number 3 is lost, but the packet with sequence number 0 arrives—a packet containing new data.
Now consider the receiver’s viewpoint in Figure 3.27, which has a figurative curtain between the sender and the receiver, since the receiver cannot “see” the actions taken by the sender. All the receiver observes is the sequence of messages it receives from the channel and sends into the channel. As far as it is concerned, the two scenarios in Figure 3.27 are identical. There is no way of distinguishing the retransmission of the first packet from an original transmission of the fifth packet. Clearly, a window size that is 1 less than the size of the sequence number space won’t work. But how small must the window size be? A problem at the end of the chapter asks you to show that the window size must be less than or equal to half the size of the sequence number space for SR protocols.
At the companion Web site, you will find an applet that animates the operation of the SR protocol. Try performing the same experiments that you did with the GBN applet. Do the results agree with what you expect?
This completes our discussion of reliable data transfer protocols. We’ve covered a lot of ground and introduced numerous mechanisms that together provide for reliable data transfer. Table 3.1 summarizes these mechanisms. Now that we have seen all of these mechanisms in operation and can see the “big picture,” we encourage you to review this section again to see how these mechanisms were incrementally added to cover increasingly complex (and realistic) models of the channel connecting the sender and receiver, or to improve the performance of the protocols.
Let’s conclude our discussion of reliable data transfer protocols by considering one remaining assumption in our underlying channel model. Recall that we have assumed that packets cannot be reordered within the channel between the sender and receiver. This is generally a reasonable assumption when the sender and receiver are connected by a single physical wire. However, when the “channel” connecting the two is a network, packet reordering can occur. One manifestation of packet reordering is that old copies of a packet with a sequence or acknowledgment number of x can appear, even though neither the sender’s nor the receiver’s window contains x. With packet reordering, the channel can be thought of as essentially buffering packets and spontaneously emitting these packets at any point in the future. Because sequence numbers may be reused, some care must be taken to guard against such duplicate packets. The approach taken in practice is to ensure that a sequence number is not reused until the sender is “sure” that any previously sent packets with sequence number x are no longer in the network. This is done by assuming that a packet cannot “live” in the network for longer than some fixed maximum amount of time. A maximum packet lifetime of approximately three minutes is assumed in the TCP extensions for high-speed networks [RFC 1323]. [Sunshine 1978] describes a method for using sequence numbers such that reordering problems can be completely avoided.
Figure 3.27 SR receiver dilemma with too-large windows: A new packet or a retransmission?
Table 3.1 Summary of reliable data transfer mechanisms and their use