5.4 ISP 之间的路由:BGP#
5.4 Routing Among the ISPs: BGP
我们刚刚了解到 OSPF 是一种域内(intra-AS)路由协议的示例。当在同一个自治系统(AS)内部对一个数据包进行路由时,该数据包所遵循的路径完全由域内路由协议决定。然而,要在多个 AS 之间路由一个数据包,例如从廷巴克图的智能手机发送到硅谷数据中心的一台服务器,就需要一种 域间(inter-autonomous system)路由协议。由于域间路由协议涉及多个 AS 之间的协调,通信的 AS 必须运行相同的域间路由协议。事实上,在互联网中,所有 AS 都运行相同的域间路由协议,即边界网关协议,通常称为 BGP [RFC 4271;Stewart 1999]。
BGP 可以说是所有互联网协议中最重要的协议(唯一可与之竞争的是我们在 第 4.3 节 中学习的 IP 协议),因为它是将互联网中成千上万的 ISP 粘合在一起的协议。正如我们很快将看到的,BGP 是一种分散的、异步的协议,其风格类似于 第 5.2.2 节 中描述的距离向量路由。尽管 BGP 是一种复杂且具有挑战性的协议,但若想深入理解互联网,就必须熟悉其基础和运行机制。我们投入时间学习 BGP 是非常值得的。
We just learned that OSPF is an example of an intra-AS routing protocol. When routing a packet between a source and destination within the same AS, the route the packet follows is entirely determined by the intra-AS routing protocol. However, to route a packet across multiple ASs, say from a smartphone in Timbuktu to a server in a datacenter in Silicon Valley, we need an inter-autonomous system routing protocol. Since an inter-AS routing protocol involves coordination among multiple ASs, communicating ASs must run the same inter-AS routing protocol. In fact, in the Internet, all ASs run the same inter-AS routing protocol, called the Border Gateway Protocol, more commonly known as BGP [RFC 4271; Stewart 1999].
BGP is arguably the most important of all the Internet protocols (the only other contender would be the IP protocol that we studied in Section 4.3), as it is the protocol that glues the thousands of ISPs in the Internet together. As we will soon see, BGP is a decentralized and asynchronous protocol in the vein of distance-vector routing described in Section 5.2.2. Although BGP is a complex and challenging protocol, to understand the Internet on a deep level, we need to become familiar with its underpinnings and operation. The time we devote to learning BGP will be well worth the effort.
5.4.1 BGP 的角色#
5.4.1 The Role of BGP
为了理解 BGP 的职责,考虑一个 AS 和该 AS 中任意一个路由器。回顾一下,每个路由器都有一个转发表,在将接收到的数据包转发到外发链路的过程中起着核心作用。如我们所知,对于位于同一 AS 内的目的地,路由器转发表中的条目由该 AS 的域内路由协议决定。那么,对于位于 AS 之外的目的地又如何处理呢?这正是 BGP 派上用场的地方。
在 BGP 中,数据包并不是被路由到一个具体的目的地址,而是被路由到经过 CIDR 表示的前缀,每个前缀代表一个子网或一组子网。在 BGP 的世界中,目的地可能的形式是 138.16.68/22,在这个例子中表示包含 1,024 个 IP 地址。因此,路由器的转发表将包含形如 (x, I) 的条目,其中 x 是一个前缀(如 138.16.68/22),而 I 是该路由器的某个接口编号。
作为一种域间路由协议,BGP 为每个路由器提供了以下功能:
从邻近的 AS 获取前缀可达性信息。特别地,BGP 允许每个子网向整个互联网通告其存在。一个子网会大声“喊叫”:“我存在,我在这里”,而 BGP 会确保互联网中的所有路由器都知道该子网的存在。若没有 BGP,每个子网都将成为一个孤立的孤岛 —— 孤独、未知、对互联网的其余部分不可达。
确定到这些前缀的“最佳”路由。一个路由器可能会学到多个到达同一前缀的不同路由。为了确定最佳路径,路由器将本地运行一个 BGP 路由选择过程(使用其通过邻接路由器获得的前缀可达性信息)。最佳路由将依据策略以及可达性信息确定。
接下来我们将深入探讨 BGP 如何完成这两个任务。
To understand the responsibilities of BGP, consider an AS and an arbitrary router in that AS. Recall that every router has a forwarding table, which plays the central role in the process of forwarding arriving packets to outbound router links. As we have learned, for destinations that are within the same AS, the entries in the router’s forwarding table are determined by the AS’s intra-AS routing protocol. But what about destinations that are outside of the AS? This is precisely where BGP comes to the rescue.
In BGP, packets are not routed to a specific destination address, but instead to CIDRized prefixes, with each prefix representing a subnet or a collection of subnets. In the world of BGP, a destination may take the form 138.16.68/22, which for this example includes 1,024 IP addresses. Thus, a router’s forwarding table will have entries of the form (x, I), where x is a prefix (such as 138.16.68/22) and I is an interface number for one of the router’s interfaces.
As an inter-AS routing protocol, BGP provides each router a means to:
Obtain prefix reachability information from neighboring ASs. In particular, BGP allows each subnet to advertise its existence to the rest of the Internet. A subnet screams, “I exist and I am here,” and BGP makes sure that all the routers in the Internet know about this subnet. If it weren’t for BGP, each subnet would be an isolated island—alone, unknown and unreachable by the rest of the Internet.
Determine the “best” routes to the prefixes. A router may learn about two or more different routes to a specific prefix. To determine the best route, the router will locally run a BGP route-selection procedure (using the prefix reachability information it obtained via neighboring routers). The best route will be determined based on policy as well as the reachability information.
Let us now delve into how BGP carries out these two tasks.
5.4.2 宣告 BGP 路由信息#
5.4.2 Advertising BGP Route Information
请参考 图 5.8 中所示的网络。如图所示,这个简单网络有三个自治系统:AS1、AS2 和 AS3。如图所示,AS3 包含一个前缀为 x 的子网。对于每个 AS,每个路由器要么是一个 网关路由器,要么是一个 内部路由器。网关路由器是处于 AS 边缘、直接连接到其他 AS 中一个或多个路由器的路由器。内部路由器 只连接到其自身 AS 中的主机和其他路由器。例如,在 AS1 中,路由器 1c 是一个网关路由器;路由器 1a、1b 和 1d 是内部路由器。
让我们考虑将前缀 x 的可达性信息宣告给 图 5.8 中所有路由器的任务。从高层次上来看,这一过程是简单的。首先,AS3 向 AS2 发送一个 BGP 消息,说明 x 存在并且位于 AS3;我们将这个消息表示为 “AS3 x”。然后 AS2 向 AS1 发送一个 BGP 消息,说明 x 存在,并且可以通过先经过 AS2 再到达 AS3 来到达 x;我们将这个消息表示为 “AS2 AS3 x”。通过这种方式,每个自治系统不仅能够了解 x 的存在,还能获知通向 x 的自治系统路径。
虽然上面关于宣告 BGP 可达性信息的描述表达了基本思想,但并不精确,因为自治系统并不会彼此发送消息,而是由路由器发送。为了理解这一点,让我们重新查看 图 5.8 中的示例。在 BGP 中,路由器对通过端口 179 建立的半永久 TCP 连接交换路由信息。每个这样的 TCP 连接以及通过该连接发送的所有 BGP 消息,称为一个 BGP 连接。此外,跨越两个 AS 的 BGP 连接称为 外部 BGP(eBGP) 连接,同一 AS 中路由器之间的 BGP 会话称为 内部 BGP(iBGP) 连接。图 5.9 显示了该网络中的 BGP 连接示例。通常,对于每一条直接连接不同 AS 中网关路由器的链路,都有一个 eBGP 连接;因此,在 图 5.9 中,网关路由器 1c 和 2a 之间有一个 eBGP 连接,网关路由器 2c 和 3a 之间也有一个 eBGP 连接。
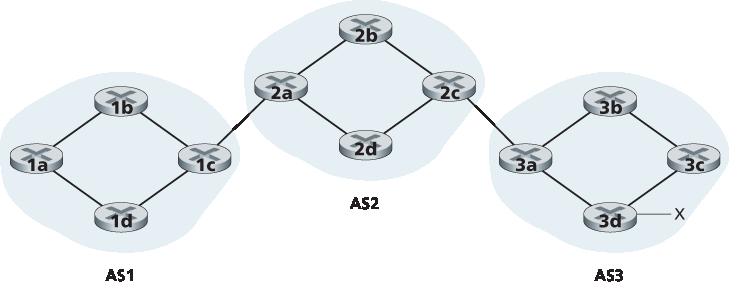
图 5.8 拥有三个自治系统的网络。AS3 包含一个前缀为 x 的子网
每个 AS 内部的路由器之间也存在 iBGP 连接。特别地,图 5.9 显示了每对 AS 内部路由器之间都有一个 BGP 连接的常见配置,在每个 AS 内形成一个 TCP 连接的网状结构。在 图 5.9 中,eBGP 连接用长虚线表示;iBGP 连接用短虚线表示。注意,iBGP 连接不一定对应于物理链路。
为了传播可达性信息,iBGP 和 eBGP 会话都会被使用。再次考虑将前缀 x 的可达性信息宣告给 AS1 和 AS2 中的所有路由器的过程。在这个过程中,网关路由器 3a 首先向网关路由器 2c 发送一个 eBGP 消息 “AS3 x”。网关路由器 2c 然后将 iBGP 消息 “AS3 x” 发送给 AS2 中所有其他路由器,包括网关路由器 2a。接着,网关路由器 2a 向网关路由器 1c 发送 eBGP 消息 “AS2 AS3 x”。
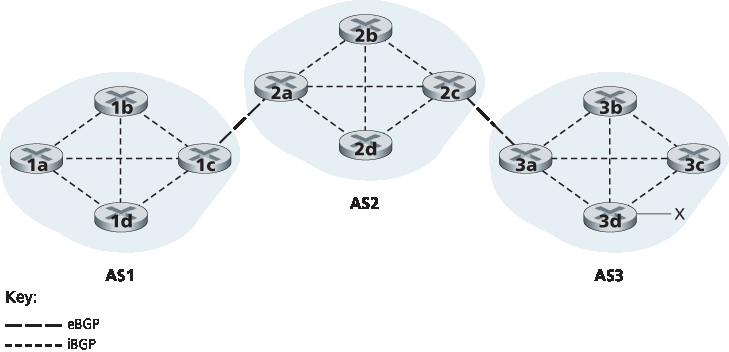
图 5.9 eBGP 和 iBGP 连接
最后,网关路由器 1c 使用 iBGP 向 AS1 中所有路由器发送消息 “AS2 AS3 x”。完成这一过程后,AS1 和 AS2 中的每个路由器都能获知 x 的存在,并知道一条通向 x 的 AS 路径。
当然,在实际网络中,从一个给定路由器出发,可能存在多条通向某一目的地的路径,每条路径经过不同的 AS 序列。例如,考虑 图 5.10 所示的网络,该图是 图 5.8 中的原始网络,增加了一条从路由器 1d 到路由器 3d 的物理链路。在这种情况下,从 AS1 到 x 存在两条路径:通过路由器 1c 的路径 “AS2 AS3 x”;以及通过路由器 1d 的新路径 “AS3 x”。
Consider the network shown in Figure 5.8. As we can see, this simple network has three autonomous systems: AS1, AS2, and AS3. As shown, AS3 includes a subnet with prefix x. For each AS, each router is either a gateway router or an internal router. A gateway router is a router on the edge of an AS that directly connects to one or more routers in other ASs. An internal router connects only to hosts and routers within its own AS. In AS1, for example, router 1c is a gateway router; routers 1a, 1b, and 1d are internal routers.
Let’s consider the task of advertising reachability information for prefix x to all of the routers shown in Figure 5.8 . At a high level, this is straightforward. First, AS3 sends a BGP message to AS2, saying that x exists and is in AS3; let’s denote this message as “AS3 x”. Then AS2 sends a BGP message to AS1, saying that x exists and that you can get to x by first passing through AS2 and then going to AS3; let’s denote that message as “AS2 AS3 x”. In this manner, each of the autonomous systems will not only learn about the existence of x, but also learn about a path of autonomous systems that leads to x.
Although the discussion in the above paragraph about advertising BGP reachability information should get the general idea across, it is not precise in the sense that autonomous systems do not actually send messages to each other, but instead routers do. To understand this, let’s now re-examine the example in Figure 5.8. In BGP, pairs of routers exchange routing information over semi-permanent TCP connections using port 179. Each such TCP connection, along with all the BGP messages sent over the connection, is called a BGP connection. Furthermore, a BGP connection that spans two ASs is called an external BGP (eBGP) connection, and a BGP session between routers in the same AS is called an internal BGP (iBGP) connection. Examples of BGP connections for the network in Figure 5.8 are shown in Figure 5.9. There is typically one eBGP connection for each link that directly connects gateway routers in different ASs; thus, in Figure 5.9 , there is an eBGP connection between gateway routers 1c and 2a and an eBGP connection between gateway routers 2c and 3a.
Figure 5.8 Network with three autonomous systems. AS3 includes a subnet with prefix x
There are also iBGP connections between routers within each of the ASs. In particular, Figure 5.9 displays a common configuration of one BGP connection for each pair of routers internal to an AS, creating a mesh of TCP connections within each AS. In Figure 5.9, the eBGP connections are shown with the long dashes; the iBGP connections are shown with the short dashes. Note that iBGP connections do not always correspond to physical links.
In order to propagate the reachability information, both iBGP and eBGP sessions are used. Consider again advertising the reachability information for prefix x to all routers in AS1 and AS2. In this process, gateway router 3a first sends an eBGP message “AS3 x” to gateway router 2c. Gateway router 2c then sends the iBGP message “AS3 x” to all of the other routers in AS2, including to gateway router 2a. Gateway router 2a then sends the eBGP message “AS2 AS3 x” to gateway router 1c.
Figure 5.9 eBGP and iBGP connections
Finally, gateway router 1c uses iBGP to send the message “AS2 AS3 x” to all the routers in AS1. After this process is complete, each router in AS1 and AS2 is aware of the existence of x and is also aware of an AS path that leads to x.
Of course, in a real network, from a given router there may be many different paths to a given destination, each through a different sequence of ASs. For example, consider the network in Figure 5.10, which is the original network in Figure 5.8, with an additional physical link from router 1d to router 3d. In this case, there are two paths from AS1 to x: the path “AS2 AS3 x” via router 1c; and the new path “AS3 x” via the router 1d.
5.4.3 确定最佳路由#
5.4.3 Determining the Best Routes
正如我们刚刚了解到的,从一个给定的路由器到某个目的子网可能存在多条路径。实际上,在互联网中,路由器通常会接收到关于几十条可能路径的可达性信息。路由器如何在这些路径中做出选择(并据此配置其转发表)?
在讨论这个关键问题之前,我们需要介绍一些 BGP 的术语。当一个路由器在 BGP 连接上传播一个前缀时,它会将多个 BGP 属性 与该前缀一并包含在内。在 BGP 术语中,一个带有属性的前缀被称为一个 路由。两个更重要的属性是 AS-PATH 和 NEXT-HOP。AS-PATH 属性包含了该通告所经过的 AS 列表,正如我们在前面的示例中看到的那样。为了生成 AS-PATH 值,当一个前缀传递到一个 AS 时,该 AS 会将其 ASN 添加到 AS-PATH 的现有列表中。例如,在 图 5.10 中,从 AS1 到子网 x 存在两条路径:一条使用 AS-PATH “AS2 AS3”;另一条使用 AS-PATH “AS3”。BGP 路由器还使用 AS-PATH 属性来检测并防止循环的通告;具体来说,如果某个路由器在路径列表中看到自身 AS 已出现,则会拒绝该通告。
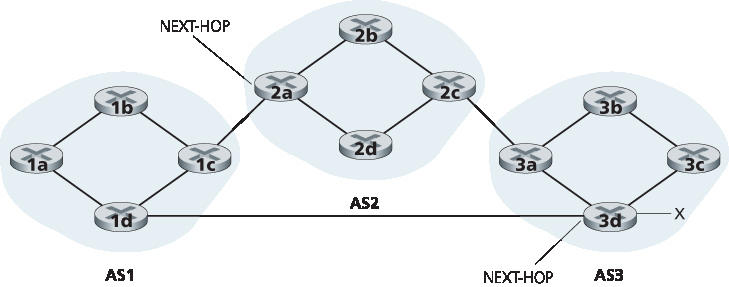
图 5.10 增加 AS1 和 AS3 对等连接的网络
NEXT-HOP 属性在域间和域内路由协议之间提供了关键的连接,其用途微妙却十分重要。NEXT-HOP 是开始 AS-PATH 的那个路由器接口的 IP 地址。为了更好地理解该属性,让我们再次参考 图 5.10。如图所示,从 AS1 到 x 的路径 “AS2 AS3 x” 中,NEXT-HOP 是路由器 2a 的左侧接口的 IP 地址。而绕过 AS2 的路径 “AS3 x” 的 NEXT-HOP 是路由器 3d 最左侧接口的 IP 地址。总结一下,在这个玩具示例中,AS1 中的每个路由器都能得知前缀 x 的两个 BGP 路由:
路由器 2a 最左侧接口的 IP 地址;AS2 AS3;x
路由器 3d 最左侧接口的 IP 地址;AS3;x
这里,每条 BGP 路由都以三部分组成的列表形式表示:NEXT-HOP;AS-PATH;目的前缀。在实际中,BGP 路由包含更多属性,但这里暂且忽略。注意,NEXT-HOP 属性是一个不属于 AS1 的路由器的 IP 地址;然而,包含该 IP 地址的子网直接连接到 AS1。
As we have just learned, there may be many paths from a given router to a destination subnet. In fact, in the Internet, routers often receive reachability information about dozens of different possible paths. How does a router choose among these paths (and then configure its forwarding table accordingly)?
Before addressing this critical question, we need to introduce a little more BGP terminology. When a router advertises a prefix across a BGP connection, it includes with the prefix several BGP attributes. In BGP jargon, a prefix along with its attributes is called a route. Two of the more important attributes are AS-PATH and NEXT-HOP. The AS-PATH attribute contains the list of ASs through which the advertisement has passed, as we’ve seen in our examples above. To generate the AS-PATH value, when a prefix is passed to an AS, the AS adds its ASN to the existing list in the AS-PATH. For example, in Figure 5.10, there are two routes from AS1 to subnet x: one which uses the AS-PATH “AS2 AS3”; and another that uses the AS-PATH “A3”. BGP routers also use the AS-PATH attribute to detect and prevent looping advertisements; specifically, if a router sees that its own AS is contained in the path list, it will reject the advertisement.
Figure 5.10 Network augmented with peering link between AS1 and AS3
Providing the critical link between the inter-AS and intra-AS routing protocols, the NEXT-HOP attribute has a subtle but important use. The NEXT-HOP is the IP address of the router interface that begins the AS-PATH. To gain insight into this attribute, let’s again refer to Figure 5.10. As indicated in Figure 5.10, the NEXT-HOP attribute for the route “AS2 AS3 x” from AS1 to x that passes through AS2 is the IP address of the left interface on router 2a. The NEXT-HOP attribute for the route “AS3 x” from AS1 to x that bypasses AS2 is the IP address of the leftmost interface of router 3d. In summary, in this toy example, each router in AS1 becomes aware of two BGP routes to prefix x:
IP address of leftmost interface for router 2a; AS2 AS3; x
IP address of leftmost interface of router 3d; AS3; x
Here, each BGP route is written as a list with three components: NEXT-HOP; AS-PATH; destination prefix. In practice, a BGP route includes additional attributes, which we will ignore for the time being. Note that the NEXT-HOP attribute is an IP address of a router that does not belong to AS1; however, the subnet that contains this IP address directly attaches to AS1.
烫手山芋路由#
Hot Potato Routing
我们现在终于可以准确地讨论 BGP 路由算法了。我们将从最简单的路由算法之一—— 烫手山芋路由(hot potato routing) 开始。
考虑 图 5.10 中的路由器 1b。如前所述,该路由器将了解到通向前缀 x 的两条可能的 BGP 路由。在烫手山芋路由中,从所有可能的路由中选择的路由是那条到该路由起始处 NEXT-HOP 路由器代价最小的路由。在此示例中,路由器 1b 将查阅其域内路由信息,找出通向 NEXT-HOP 路由器 2a 的最小代价路径,以及通向 NEXT-HOP 路由器 3d 的最小代价路径,然后选择其中代价更小的一条路径。例如,假设代价定义为经过链路的数量。那么从路由器 1b 到路由器 2a 的最小代价为 2,到路由器 2d 的最小代价为 3,因此将选择路由器 2a。接着,路由器 1b 将查阅其由域内路由算法配置的转发表,并找到通向路由器 2a 最小代价路径上的接口 I。然后,它将 (x, I) 加入其转发表中。
将外部 AS 的前缀添加到路由器转发表中的步骤总结如 图 5.11 所示。需要注意的是,在将外部 AS 前缀添加到转发表中时,既使用了域间路由协议(BGP),也使用了域内路由协议(例如 OSPF)。
烫手山芋路由背后的思想是让路由器 1b 尽可能快地(更准确地说是以最小代价)将数据包移出其 AS,而不去考虑其 AS 之外的路径代价。在“烫手山芋路由”这个名字中,一个数据包就像一个烫手的山芋,在你手中灼热难耐,因此你想尽快将它传给另一个人(另一个 AS)。因此,烫手山芋路由是一种自私的算法 —— 它试图减少自身 AS 内的代价,而无视 AS 外端到端路径的其他部分代价。注意,在烫手山芋路由中,同一个 AS 内的两个路由器可能会选择两条不同的 AS 路径通往相同的前缀。例如,我们刚刚看到,路由器 1b 会通过 AS2 向前缀 x 发送数据包。然而,路由器 1d 会绕过 AS2,直接将数据包发送到 AS3 以到达前缀 x。

图 5.11 将外部 AS 目的地添加到路由器转发表的步骤
We are now finally in position to talk about BGP routing algorithms in a precise manner. We will begin with one of the simplest routing algorithms, namely, hot potato routing.
Consider router 1b in the network in Figure 5.10. As just described, this router will learn about two possible BGP routes to prefix x. In hot potato routing, the route chosen (from among all possible routes) is that route with the least cost to the NEXT-HOP router beginning that route. In this example, router 1b will consult its intra-AS routing information to find the least-cost intra-AS path to NEXT-HOP router 2a and the least-cost intra-AS path to NEXT-HOP router 3d, and then select the route with the smallest of these least-cost paths. For example, suppose that cost is defined as the number of links traversed. Then the least cost from router 1b to router 2a is 2, the least cost from router 1b to router 2d is 3, and router 2a would therefore be selected. Router 1b would then consult its forwarding table (configured by its intra-AS algorithm) and find the interface I that is on the least-cost path to router 2a. It then adds (x, I) to its forwarding table.
The steps for adding an outside-AS prefix in a router’s forwarding table for hot potato routing are summarized in Figure 5.11. It is important to note that when adding an outside-AS prefix into a forwarding table, both the inter-AS routing protocol (BGP) and the intra-AS routing protocol (e.g., OSPF) are used.
The idea behind hot-potato routing is for router 1b to get packets out of its AS as quickly as possible (more specifically, with the least cost possible) without worrying about the cost of the remaining portions of the path outside of its AS to the destination. In the name “hot potato routing,” a packet is analogous to a hot potato that is burning in your hands. Because it is burning hot, you want to pass it off to another person (another AS) as quickly as possible. Hot potato routing is thus a selfish algorithm—it tries to reduce the cost in its own AS while ignoring the other components of the end-to-end costs outside its AS. Note that with hot potato routing, two routers in the same AS may choose two different AS paths to the same prefix. For example, we just saw that router 1b would send packets through AS2 to reach x. However, router 1d would bypass AS2 and send packets directly to AS3 to reach x.
Figure 5.11 Steps in adding outside-AS destination in a router’s forwarding table
路由选择算法#
Route-Selection Algorithm
在实际中,BGP 使用的算法比烫手山芋路由更为复杂,但它仍然包含了烫手山芋路由的机制。对于任意给定的目的前缀,BGP 路由选择算法的输入是一组所有已被该路由器学习并接受的通往该前缀的路由。如果只有一条这样的路由,那么 BGP 显然选择该路由。如果存在两条或更多通往相同前缀的路由,那么 BGP 将依次应用以下排除规则,直到只剩下一条路由:
一条路由会被赋予一个 本地优先级(local preference) 属性(除了 AS-PATH 和 NEXT-HOP 属性之外)。路由的本地优先级可以由该路由器设置,也可以从同一 AS 中的其他路由器学习而来。local preference 属性的数值是一个策略决策,完全由该 AS 的网络管理员决定。(我们将在后面详细讨论 BGP 策略问题。)具有最高 local preference 值的路由将被保留。
在剩下的路由中(所有具有相同的最高 local preference 值),选择 AS-PATH 最短的路由。如果这个规则是唯一的路由选择规则,那么 BGP 将像距离向量算法那样选择路径,其中距离度量使用的是 AS 跳数而不是路由器跳数。
在剩下的路由中(具有相同的最高 local preference 值和相同的 AS-PATH 长度),使用烫手山芋路由,即选择到 NEXT-HOP 路由器代价最小的那条路由。
如果仍然存在多条路由,路由器将使用 BGP 标识符来选择路由;见 [Stewart 1999]。
举个例子,再次考虑 图 5.10 中的路由器 1b。回顾一下,该路由器存在通向前缀 x 的两条 BGP 路由,一条经过 AS2,另一条绕过 AS2。还记得如果只使用烫手山芋路由,那么 BGP 会通过 AS2 将数据包路由到前缀 x。但在上述路由选择算法中,规则 2 先于规则 3 被应用,这将导致 BGP 选择绕过 AS2 的那条路由,因为它的 AS PATH 更短。因此,我们看到,在上述路由选择算法中,BGP 不再是一个自私的算法 —— 它首先会寻找 AS 路径更短的路由(从而可能减少端到端的时延)。
如前所述,BGP 是互联网中事实上的标准域间路由协议。要查看从一级 ISP 路由器中提取的各种 BGP 路由表(非常大!)的内容,请访问 http://www.routeviews.org。BGP 路由表通常包含超过 50 万条路由(即前缀及其对应属性)。关于 BGP 路由表大小和特征的统计数据见 [Potaroo 2016]。
In practice, BGP uses an algorithm that is more complicated than hot potato routing, but nevertheless incorporates hot potato routing. For any given destination prefix, the input into BGP’s route-selection algorithm is the set of all routes to that prefix that have been learned and accepted by the router. If there is only one such route, then BGP obviously selects that route. If there are two or more routes to the same prefix, then BGP sequentially invokes the following elimination rules until one route remains:
A route is assigned a local preference value as one of its attributes (in addition to the AS-PATH and NEXT-HOP attributes). The local preference of a route could have been set by the router or could have been learned from another router in the same AS. The value of the local preference attribute is a policy decision that is left entirely up to the AS’s network administrator. (We will shortly discuss BGP policy issues in some detail.) The routes with the highest local preference values are selected.
From the remaining routes (all with the same highest local preference value), the route with the shortest AS-PATH is selected. If this rule were the only rule for route selection, then BGP would be using a DV algorithm for path determination, where the distance metric uses the number of AS hops rather than the number of router hops.
From the remaining routes (all with the same highest local preference value and the same AS- PATH length), hot potato routing is used, that is, the route with the closest NEXT-HOP router is selected.
If more than one route still remains, the router uses BGP identifiers to select the route; see [Stewart 1999].
As an example, let’s again consider router 1b in Figure 5.10. Recall that there are exactly two BGP routes to prefix x, one that passes through AS2 and one that bypasses AS2. Also recall that if hot potato routing on its own were used, then BGP would route packets through AS2 to prefix x. But in the above route-selection algorithm, rule 2 is applied before rule 3, causing BGP to select the route that bypasses AS2, since that route has a shorter AS PATH. So we see that with the above route-selection algorithm, BGP is no longer a selfish algorithm—it first looks for routes with short AS paths (thereby likely reducing end-to-end delay).
As noted above, BGP is the de facto standard for inter-AS routing for the Internet. To see the contents of various BGP routing tables (large!) extracted from routers in tier-1 ISPs, see http://www.routeviews.org. BGP routing tables often contain over half a million routes (that is, prefixes and corresponding attributes). Statistics about the size and characteristics of BGP routing tables are presented in [Potaroo 2016].
5.4.4 IP 任播#
5.4.4 IP-Anycast
除了作为互联网的域间路由协议外,BGP 还常被用来实现 IP-anycast 服务 [RFC 1546, RFC 7094],该服务在 DNS 中被广泛使用。为了说明 IP-anycast 的动机,考虑以下情景:在许多应用中,我们希望 (1) 在多个地理位置分散的服务器上复制相同的内容,以及 (2) 让每个用户从距离其最近的服务器访问内容。例如,CDN 可能会在不同国家的服务器上复制视频和其他对象。同样,DNS 系统也可以在全球的 DNS 服务器上复制 DNS 记录。当用户希望访问这些复制的内容时,最好将用户引导至具有复制内容的“最近”服务器。BGP 的路由选择算法提供了一个简单且自然的机制来实现这一点。
为了使我们的讨论具体化,我们描述一个 CDN 如何使用 IP-anycast。如 图 5.12 所示,在 IP-anycast 配置阶段,CDN 公司为其每个服务器分配相同的 IP 地址,并使用标准的 BGP 从每个服务器处通告该 IP 地址。当 BGP 路由器接收到多个关于该 IP 地址的路由通告时,它将这些通告视为通往相同物理位置的不同路径(尽管实际上是通往不同物理位置的不同路径)。在配置其路由表时,每个路由器将本地使用 BGP 路由选择算法,选择通往该 IP 地址的“最佳”(例如,按照 AS 跳数确定的最短)路径。例如,如果某条 BGP 路由(对应于某个位置)距离该路由器仅一跳,而所有其他 BGP 路由(对应于其他位置)均为两跳或以上,则 BGP 路由器会选择将数据包路由到该一跳的位置。在这个初始的 BGP 地址通告阶段完成后,CDN 就可以执行其主要任务——分发内容。当客户端请求视频时,无论客户端位于何处,CDN 都会返回由多个地理分散的服务器共用的那个 IP 地址。当客户端向该 IP 地址发送请求时,互联网路由器会将该请求数据包转发至“最近”的服务器,即由 BGP 路由选择算法定义的服务器。
尽管上述 CDN 示例很好地说明了 IP-anycast 的用途,但在实践中,CDN 通常选择不使用 IP-anycast,因为 BGP 路由的变动可能导致同一个 TCP 连接的数据包到达不同的 Web 服务器实例。然而,IP-anycast 被 DNS 系统广泛使用,用于将 DNS 查询引导至最近的根 DNS 服务器。如 第 2.4 节 所述,目前根 DNS 服务器共有 13 个 IP 地址。但对应于这些地址,每个地址下有多个 DNS 根服务器,其中一些地址下的服务器数量超过 100 台,遍布全球各地。当 DNS 查询发送到这 13 个 IP 地址中的某一个时,IP-anycast 会将该查询路由到负责该地址的最近的 DNS 根服务器。
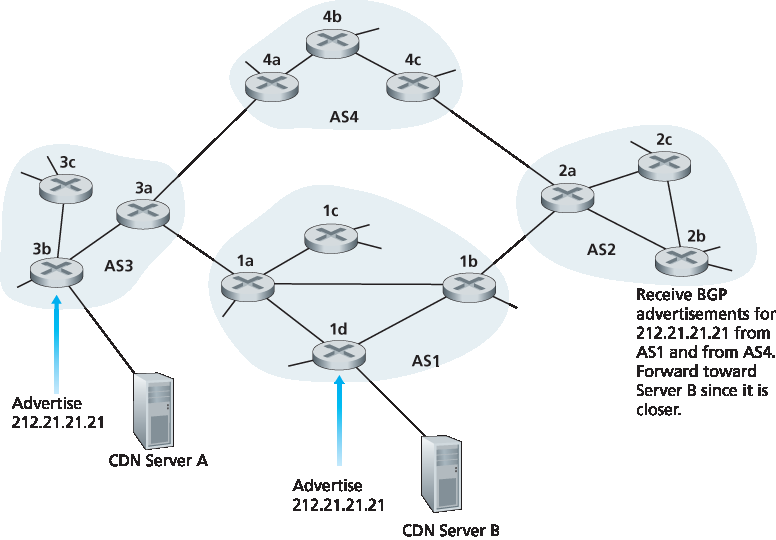
图 5.12 使用 IP-anycast 将用户引导至最近的 CDN 服务器
In addition to being the Internet’s inter-AS routing protocol, BGP is often used to implement the IP- anycast service [RFC 1546, RFC 7094], which is commonly used in DNS. To motivate IP-anycast, consider that in many applications, we are interested in (1) replicating the same content on different servers in many different dispersed geographical locations, and (2) having each user access the content from the server that is closest. For example, a CDN may replicate videos and other objects on servers in different countries. Similarly, the DNS system can replicate DNS records on DNS servers throughout the world. When a user wants to access this replicated content, it is desirable to point the user to the “nearest” server with the replicated content. BGP’s route-selection algorithm provides an easy and natural mechanism for doing so.
To make our discussion concrete, let’s describe how a CDN might use IP-anycast. As shown in Figure 5.12, during the IP-anycast configuration stage, the CDN company assigns the same IP address to each of its servers, and uses standard BGP to advertise this IP address from each of the servers. When a BGP router receives multiple route advertisements for this IP address, it treats these advertisements as providing different paths to the same physical location (when, in fact, the advertisements are for different paths to different physical locations). When configuring its routing table, each router will locally use the BGP route-selection algorithm to pick the “best” (for example, closest, as determined by AS-hop counts) route to that IP address. For example, if one BGP route (corresponding to one location) is only one AS hop away from the router, and all other BGP routes (corresponding to other locations) are two or more AS hops away, then the BGP router would choose to route packets to the location that is one hop away. After this initial BGP address-advertisement phase, the CDN can do its main job of distributing content. When a client requests the video, the CDN returns to the client the common IP address used by the geographically dispersed servers, no matter where the client is located. When the client sends a request to that IP address, Internet routers then forward the request packet to the “closest” server, as defined by the BGP route-selection algorithm.
Although the above CDN example nicely illustrates how IP-anycast can be used, in practice CDNs generally choose not to use IP-anycast because BGP routing changes can result in different packets of the same TCP connection arriving at different instances of the Web server. But IP-anycast is extensively used by the DNS system to direct DNS queries to the closest root DNS server. Recall from Section 2.4, there are currently 13 IP addresses for root DNS servers. But corresponding to each of these addresses, there are multiple DNS root servers, with some of these addresses having over 100 DNS root servers scattered over all corners of the world. When a DNS query is sent to one of these 13 IP addresses, IP anycast is used to route the query to the nearest of the DNS root servers that is responsible for that address.
Figure 5.12 Using IP-anycast to bring users to the closest CDN server
5.4.5 路由策略#
5.4.5 Routing Policy
当路由器选择通往某个目的地的路径时,AS 的路由策略可以凌驾于所有其他因素之上,例如最短 AS 路径或烫手山芋路由。实际上,在路由选择算法中,路由首先是根据 local-preference 属性选择的,该属性的值由本地 AS 的策略决定。
我们用一个简单示例来说明 BGP 路由策略的一些基本概念。图 5.13 展示了六个互联的自治系统:A、B、C、W、X 和 Y。请注意,A、B、C、W、X 和 Y 是 AS,而不是路由器。假设自治系统 W、X 和 Y 是接入 ISP,而 A、B 和 C 是骨干提供商网络。我们还假设 A、B 和 C 之间直接交换流量,并向其客户网络提供完整的 BGP 信息。进入 ISP 接入网络的所有流量必须以该网络为目的地,离开 ISP 接入网络的所有流量必须以该网络为源。W 和 Y 显然是接入 ISP。X 是一个 多宿主接入 ISP,因为它通过两个不同的提供商连接至其余网络(在实际中这种情形越来越常见)。但是,和 W 与 Y 一样,X 自身也必须是所有离开/进入 X 的流量的源/目的地。那么,这种存根网络行为将如何被实现与强制执行呢?如何防止 X 在 B 与 C 之间转发流量?这可以通过控制 BGP 路由的通告方式轻松实现。特别是,如果 X 向其邻居 B 和 C 通告称它除了自己外没有通向其他目的地的路径,那么它就会充当接入 ISP 网络。也就是说,尽管 X 可能知道一条通往网络 Y 的路径,比如 XCY,但它不会将这条路径通告给 B。由于 B 并不知道 X 有通往 Y 的路径,因此它绝不会将目的地为 Y(或 C)的流量通过 X 转发。这个简单示例说明了选择性路由通告策略如何用于实现客户/提供商路由关系。
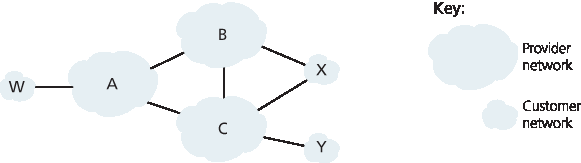
图 5.13 一个简单的 BGP 策略场景
我们接下来关注提供商网络,比如 AS B。假设 B 从 A 学到 A 有一条通往 W 的路径 AW。因此,B 可以将路径 AW 安装到其路由信息库中。显然,B 也希望将路径 BAW 通告给其客户 X,这样 X 就知道它可以通过 B 向 W 发送流量。但 B 是否应该将路径 BAW 通告给 C 呢?如果它这样做了,那么 C 就可以通过 BAW 向 W 发送流量。如果 A、B 和 C 都是骨干提供商,那么 B 可能会理直气壮地认为它不应该承担(且不应支付)在 A 与 C 之间传递转发流量的责任。B 可能会认为,A 与 C 有责任(并应承担费用)确保 C 能够通过 A 与其客户通信。目前尚无正式标准规范骨干 ISP 之间的路由方式。然而,商业 ISP 遵循的经验法则是:任何穿越 ISP 骨干网络的流量必须具有该 ISP 客户网络中的源或目的地(或两者);否则,这些流量就在该 ISP 网络中“搭了便车”。单独的对等协议(例如处理上述问题的协议)通常由成对的 ISP 之间协商,并常为保密;[Huston 1999a] 提供了对对等协议的有趣讨论。关于路由策略如何反映 ISP 之间的商业关系的详细描述,见 [Gao 2001; Dmitiropoulos 2007]。关于从 ISP 角度探讨 BGP 路由策略,见 [Caesar 2005b]。
实践中的原则
为什么存在不同的域间和域内路由协议?
现在我们已经研究了当今互联网中部署的具体域间和域内路由协议的细节,让我们以一个也许是我们对这些协议最根本的问题作为结尾(希望你一直在思考这个问题,没有见树不见林!):为什么使用不同的域间和域内路由协议?
对该问题的回答直指路由在 AS 内部与 AS 之间目标差异的核心:
策略。在 AS 之间,策略问题占主导地位。例如,重要的是,一个 AS 可能不希望其流量穿越另一个特定的 AS。同样,一个 AS 可能希望控制其转发哪些 AS 之间的中转流量。我们已经看到 BGP 携带路径属性并提供路由信息的受控分发机制,从而可以做出基于策略的路由决策。而在 AS 内部,一切通常由同一管理实体控制,因此策略问题在选择路由时并不那么重要。
规模。路由算法及其数据结构扩展至处理大量网络的能力是域间路由中的关键问题。而在 AS 内,扩展性则不那么关键。首先,如果一个 ISP 变得过于庞大,总是可以将其划分为两个 AS,并在新建的两个 AS 之间执行域间路由。(回忆一下,OSPF 允许通过将 AS 拆分为多个区域来构建这样的层次结构。)
性能。由于域间路由过于偏重策略,所使用路径的质量(例如性能)通常是次要问题(也就是说,为满足某些策略要求,可能会选择更长或代价更高的路径,而不是较短但不满足策略的路径)。事实上,我们看到,在 AS 之间,甚至不存在代价(除了 AS 跳数)这一概念。而在单个 AS 内部,这些策略问题影响较小,因此可以将更多关注放在路径的实际性能上。
至此,我们对 BGP 的简要介绍就结束了。理解 BGP 很重要,因为它在互联网中起着核心作用。我们鼓励你参考文献 [Griffin 2012; Stewart 1999; Labovitz 1997; Halabi 2000; Huitema 1998; Gao 2001; Feamster 2004; Caesar 2005b; Li 2007] 进一步学习 BGP。
When a router selects a route to a destination, the AS routing policy can trump all other considerations, such as shortest AS path or hot potato routing. Indeed, in the route-selection algorithm, routes are first selected according to the local-preference attribute, whose value is fixed by the policy of the local AS.
Let’s illustrate some of the basic concepts of BGP routing policy with a simple example. Figure 5.13 shows six interconnected autonomous systems: A, B, C, W, X, and Y. It is important to note that A, B, C, W, X, and Y are ASs, not routers. Let’s assume that autonomous systems W, X, and Y are access ISPs and that A, B, and C are backbone provider networks. We’ll also assume that A, B, and C, directly send traffic to each other, and provide full BGP information to their customer networks. All traffic entering an ISP access network must be destined for that network, and all traffic leaving an ISP access network must have originated in that network. W and Y are clearly access ISPs. X is a multi-homed access ISP, since it is connected to the rest of the network via two different providers (a scenario that is becoming increasingly common in practice). However, like W and Y, X itself must be the source/destination of all traffic leaving/entering X. But how will this stub network behavior be implemented and enforced? How will X be prevented from forwarding traffic between B and C? This can easily be accomplished by controlling the manner in which BGP routes are advertised. In particular X will function as an access ISP network if it advertises (to its neighbors B and C) that it has no paths to any other destinations except itself. That is, even though X may know of a path, say XCY, that reaches network Y, it will not advertise this path to B. Since B is unaware that X has a path to Y, B would never forward traffic destined to Y (or C) via X. This simple example illustrates how a selective route advertisement policy can be used to implement customer/provider routing relationships.
Figure 5.13 A simple BGP policy scenario
Let’s next focus on a provider network, say AS B. Suppose that B has learned (from A) that A has a path AW to W. B can thus install the route AW into its routing information base. Clearly, B also wants to advertise the path BAW to its customer, X, so that X knows that it can route to W via B. But should B advertise the path BAW to C? If it does so, then C could route traffic to W via BAW. If A, B, and C are all backbone providers, than B might rightly feel that it should not have to shoulder the burden (and cost!) of carrying transit traffic between A and C. B might rightly feel that it is A’s and C’s job (and cost!) to make sure that C can route to/from A’s customers via a direct connection between A and C. There are currently no official standards that govern how backbone ISPs route among themselves. However, a rule of thumb followed by commercial ISPs is that any traffic flowing across an ISP’s backbone network must have either a source or a destination (or both) in a network that is a customer of that ISP; otherwise the traffic would be getting a free ride on the ISP’s network. Individual peering agreements (that would govern questions such as those raised above) are typically negotiated between pairs of ISPs and are often confidential; [Huston 1999a] provides an interesting discussion of peering agreements. For a detailed description of how routing policy reflects commercial relationships among ISPs, see [Gao 2001; Dmitiropoulos 2007]. For a discussion of BGP routing polices from an ISP standpoint, see [Caesar 2005b].
PRINCIPLES IN PRACTICE
WHY ARE THERE DIFFERENT INTER-AS AND INTRA-AS ROUTING PROTOCOLS?
Having now studied the details of specific inter-AS and intra-AS routing protocols deployed in today’s Internet, let’s conclude by considering perhaps the most fundamental question we could ask about these protocols in the first place (hopefully, you have been wondering this all along, and have not lost the forest for the trees!): Why are different inter-AS and intra-AS routing protocols used?
The answer to this question gets at the heart of the differences between the goals of routing within an AS and among ASs:
Policy. Among ASs, policy issues dominate. It may well be important that traffic originating in a given AS not be able to pass through another specific AS. Similarly, a given AS may well want to control what transit traffic it carries between other ASs. We have seen that BGP carries path attributes and provides for controlled distribution of routing information so that such policy-based routing decisions can be made. Within an AS, everything is nominally under the same administrative control, and thus policy issues play a much less important role in choosing routes within the AS.
Scale. The ability of a routing algorithm and its data structures to scale to handle routing to/among large numbers of networks is a critical issue in inter-AS routing. Within an AS, scalability is less of a concern. For one thing, if a single ISP becomes too large, it is always possible to divide it into two ASs and perform inter-AS routing between the two new ASs. (Recall that OSPF allows such a hierarchy to be built by splitting an AS into areas.)
Performance. Because inter-AS routing is so policy oriented, the quality (for example, performance) of the routes used is often of secondary concern (that is, a longer or more costly route that satisfies certain policy criteria may well be taken over a route that is shorter but does not meet that criteria). Indeed, we saw that among ASs, there is not even the notion of cost (other than AS hop count) associated with routes. Within a single AS, however, such policy concerns are of less importance, allowing routing to focus more on the level of performance realized on a route.
This completes our brief introduction to BGP. Understanding BGP is important because it plays a central role in the Internet. We encourage you to see the references [Griffin 2012; Stewart 1999; Labovitz 1997; Halabi 2000; Huitema 1998; Gao 2001; Feamster 2004; Caesar 2005b; Li 2007] to learn more about BGP.
5.4.6 综合应用:获得互联网存在#
5.4.6 Putting the Pieces Together: Obtaining Internet Presence
虽然本小节并不专门讨论 BGP,但它将我们迄今为止看到的许多协议和概念结合在一起,包括 IP 地址分配、DNS 和 BGP。
假设你刚刚创办了一家小公司,拥有多台服务器,其中包括一个用于介绍公司产品和服务的公共 Web 服务器、一个供员工收发电子邮件的邮件服务器,以及一个 DNS 服务器。自然地,你希望全世界的人都能访问你的网站,以了解你激动人心的产品和服务。此外,你还希望你的员工能够与全球潜在客户收发电子邮件。
为了实现这些目标,你首先需要获得互联网连接,这通常是通过与本地 ISP 签订合同并建立连接来实现的。你的公司将拥有一个网关路由器,该路由器连接到你本地 ISP 的路由器。这个连接可能是通过现有电话基础设施的 DSL 连接、租用线路连接到 ISP 的路由器,或者是 第 1 章 中描述的多种其他接入方案之一。你的本地 ISP 还会为你分配一个 IP 地址段,例如一个 /24 地址段,共包含 256 个地址。一旦你拥有了物理连接和 IP 地址段,你就可以将其中一个 IP 地址(在你的地址范围内)分配给你的 Web 服务器,一个分配给邮件服务器,一个给 DNS 服务器,一个给网关路由器,其余地址分配给公司网络中的其他服务器和网络设备。
除了与 ISP 签约外,你还需要与互联网注册机构签约,以为你的公司注册一个域名,如 第 2 章 所述。例如,如果你的公司名为 Xanadu Inc.,你自然会尝试获得域名 xanadu.com。你的公司还必须在 DNS 系统中获得“存在”。具体来说,由于外部用户需要联系你的 DNS 服务器以获取你服务器的 IP 地址,你需要向注册机构提供你的 DNS 服务器的 IP 地址。注册机构随后会将你 DNS 服务器的条目(域名和相应的 IP 地址)添加到 .com 顶级域名服务器中,如 第 2 章 所述。完成这一步之后,任何知道你域名(如 xanadu.com)的用户都可以通过 DNS 系统获取你 DNS 服务器的 IP 地址。
为了让人们能够发现你的 Web 服务器的 IP 地址,你需要在 DNS 服务器中添加条目,将 Web 服务器的主机名(如 xanadu.com)映射到其 IP 地址。你还需要为公司中其他对外公开的服务器添加类似条目,包括你的邮件服务器。通过这种方式,如果 Alice 想访问你的 Web 服务器,DNS 系统将联系你的 DNS 服务器,找到 Web 服务器的 IP 地址并返回给 Alice。随后,Alice 就可以直接与你的 Web 服务器建立 TCP 连接。
然而,还有一个必要且关键的步骤必须完成,才能让全球用户访问你的 Web 服务器。考虑当 Alice 知道你 Web 服务器的 IP 地址后,向该地址发送一个 IP 数据报(例如,一个 TCP SYN 段)时会发生什么。该数据报将经由互联网进行路由,途径多个自治系统中的一系列路由器,最终到达你的 Web 服务器。当其中任何一个路由器收到该数据报时,它会查找其转发表中的条目,以确定应将该数据报转发到哪个出口端口。因此,每个路由器都需要知道你公司的 /24 前缀(或某个包含该前缀的聚合项)的存在。路由器是如何知道你公司前缀的存在的?正如我们刚刚看到的,它是通过 BGP 得知的!具体而言,当你公司与本地 ISP 签约并获得前缀(即地址范围)后,你的本地 ISP 会使用 BGP 向其所连接的 ISP 通告你的前缀。这些 ISP 随后也会使用 BGP 继续传播这一通告。最终,所有互联网路由器都会知道你的前缀(或包含你前缀的某个聚合项),从而能够将发往你 Web 和邮件服务器的数据报正确地转发出去。
Although this subsection is not about BGP per se, it brings together many of the protocols and concepts we’ve seen thus far, including IP addressing, DNS, and BGP.
Suppose you have just created a small company that has a number of servers, including a public Web server that describes your company’s products and services, a mail server from which your employees obtain their e-mail messages, and a DNS server. Naturally, you would like the entire world to be able to visit your Web site in order to learn about your exciting products and services. Moreover, you would like your employees to be able to send and receive e-mail to potential customers throughout the world.
To meet these goals, you first need to obtain Internet connectivity, which is done by contracting with, and connecting to, a local ISP. Your company will have a gateway router, which will be connected to a router in your local ISP. This connection might be a DSL connection through the existing telephone infrastructure, a leased line to the ISP’s router, or one of the many other access solutions described in Chapter 1. Your local ISP will also provide you with an IP address range, e.g., a /24 address range consisting of 256 addresses. Once you have your physical connectivity and your IP address range, you will assign one of the IP addresses (in your address range) to your Web server, one to your mail server, one to your DNS server, one to your gateway router, and other IP addresses to other servers and networking devices in your company’s network.
In addition to contracting with an ISP, you will also need to contract with an Internet registrar to obtain a domain name for your company, as described in Chapter 2. For example, if your company’s name is, say, Xanadu Inc., you will naturally try to obtain the domain name xanadu.com. Your company must also obtain presence in the DNS system. Specifically, because outsiders will want to contact your DNS server to obtain the IP addresses of your servers, you will also need to provide your registrar with the IP address of your DNS server. Your registrar will then put an entry for your DNS server (domain name and corresponding IP address) in the .com top-level-domain servers, as described in Chapter 2. After this step is completed, any user who knows your domain name (e.g., xanadu.com ) will be able to obtain the IP address of your DNS server via the DNS system.
So that people can discover the IP addresses of your Web server, in your DNS server you will need to include entries that map the host name of your Web server (e.g., xanadu.com) to its IP address. You will want to have similar entries for other publicly available servers in your company, including your mail server. In this manner, if Alice wants to browse your Web server, the DNS system will contact your DNS server, find the IP address of your Web server, and give it to Alice. Alice can then establish a TCP connection directly with your Web server.
However, there still remains one other necessary and crucial step to allow outsiders from around the world to access your Web server. Consider what happens when Alice, who knows the IP address of your Web server, sends an IP datagram (e.g., a TCP SYN segment) to that IP address. This datagram will be routed through the Internet, visiting a series of routers in many different ASs, and eventually reach your Web server. When any one of the routers receives the datagram, it is going to look for an entry in its forwarding table to determine on which outgoing port it should forward the datagram. Therefore, each of the routers needs to know about the existence of your company’s /24 prefix (or some aggregate entry). How does a router become aware of your company’s prefix? As we have just seen, it becomes aware of it from BGP! Specifically, when your company contracts with a local ISP and gets assigned a prefix (i.e., an address range), your local ISP will use BGP to advertise your prefix to the ISPs to which it connects. Those ISPs will then, in turn, use BGP to propagate the advertisement. Eventually, all Internet routers will know about your prefix (or about some aggregate that includes your prefix) and thus be able to appropriately forward datagrams destined to your Web and mail servers.